硬核!MySQL数据库面经大全——双非上岸阿里巴巴系列
Posted 来老铁干了这碗代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了硬核!MySQL数据库面经大全——双非上岸阿里巴巴系列相关的知识,希望对你有一定的参考价值。
东北某不知名双非本,四面成功上岸阿里巴巴,在这里把自己整理的面经分享出来,欢迎大家阅读。
| 序号 | 文章名 | 超链接 |
|---|---|---|
| 1 | 操作系统面经大全——双非上岸阿里巴巴系列 | 2021最新版面经——>传送门1 |
| 2 | 计算机网络面经大全——双非上岸阿里巴巴系列 | 2021最新版面经——>传送门2 |
| 3 | Java并发编程面经大全——双非上岸阿里巴巴系列 | 2021最新版面经——>传送门3 |
| 4 | Java虚拟机(JVM)面经大全——双非上岸阿里巴巴系列 | 2021最新版面经——>传送门4 |
| 5 | 面试阿里,你必须知道的背景知识——双非上岸阿里巴巴系列 | 2021最新版面经——>传送门5 |
本博客内容持续维护,如有改进之处,还望各位大佬指出,感激不尽!
mysql
理论篇
1. 数据库基础知识
1. 为什么要使用数据库
数据保存在内存
内存:随机存储器(RAM)、只读存储器(ROM)、高速缓存(CACHE)
优点:存取速度快
缺点:不能永久保存
数据保存在文件
优点:永久保存
缺点:速度慢
数据保存在数据库
永久保存、效率高、管理方便
2. 什么是SQL
结构化查询语言(Structured Query Language)
3. 什么是MySQL
关系型管理数据库,由MySQL AB公司开发,Oracle旗下产品。
4. 数据库三大范式
第一范式:每个列都不可以再拆分
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不是依赖于主键的一部分。(允许传递依赖,不允许部分依赖)
第三范式:在第二范式的基础上,非主键只依赖于主键,不依赖于其他非主键(不允许传递依赖)
5. MySQL有关的权限表
MySQL服务器通过权限表控制用户对数据库的访问。存放在mysql数据库里,由mysql_install_db脚本初始化,权限表:
- user权限表:记录允许连接到服务器的用户账户信息,里面的权限都是全局的。
- db权限表:记录各个账号在各个数据库上的操作权限
- table_priv权限表:记录数据库表级的操作权限
- columns_priv权限表:记录数据库列级的操作权限
- host权限表:配合db权限表对给定主机上数据库级操作权限做更极致的控制。不受GRANT和REVOKE语句的影响。
6. MySQL的binlog录入格式和区别
什么是binlog:记录所有数据库表结构变更(create、alter)以及表数据修改(insert、update、delete)的二进制文件。
binlog分类:包含二进制索引文件(.index),用于记录所有二进制文件;二进制日志文件(.000000*),记录数据库所有DDL和DML(除了数据查询语句)事件。
录入格式:statement、row、mixed
-
statement级别:每一条会修改数据的sql都会记录在binlog中,不需要记录每一行的编号,减少日志量,节约IO,由于SQL执行是有上下文的,因此在保存时需要保存相关信息。使用了函数的语句无法被记录复制。
-
row级别:不记录sql语句上下文相关信息,仅保存哪条记录被修改,记录单元为每一行的改动。保存信息多,日志量大
-
mixed级别:折中方案,普通操作使用statement记录、当无法使用statement时用row
2. 数据类型
1. 整数类型
tinyint: 1字节
smallint: 2字节
mediumint: 3字节
int(integer):4字节
bigint: 8字节
- int(20)中20的含义:指显示字符的长度。但仍为4字节。
- 为什么这么设计? 答:规定一些工具用来显示字符个数
2. 小数
float:单精度浮点数
double:双精度浮点数
decimal(m,d):可以存储大整数或高精度,可以理解为字符串处理
3. *字符串类型
varchar
- 可变、节省空间
- 使用1 or 2字节存储长度,当列长度<255时,使用1字节表 示,否则用2字节表示。
- 若存储内容超过设置长度,内容被截断。
- 存取慢,时间换空间
char
使用策略
- 对于经常变更的数据:char比varchar更好,因为char不易产生碎片
- 对于非常短的列:char高效
4. 枚举类型
把不重复的数据存储为一个预定义的集合。(enum)
5. 日期和类型
datetime、timestamp
-
二者如何选择? 答:尽量使用timestamp,高效
-
为什么不用整数存储时间戳? 答:不方便处理
-
微秒如何存储? 答:bigint
3. 引擎
不同存储引擎的区别
存储引擎Storage engine: MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。
要素:是否提供事务支持、行级锁、外键
主要存储引擎:
- Innodb引擎:MySQL 5.5以后的默认存储引擎。提供了对数据库ACID事务的支持,提供行级锁、外键的约束。处理大容量数据库有优势。
- 总结:速度低、安全性高。
- MyIASM引擎:(原本MySQL默认引擎),不提供事务支持,也不支持行级锁和外键
- 总结:速度快,安全性低
区别
- 存储结构
- 每个InnoDB在磁盘上存储成两个文件
- 每个MyISAM磁盘上存储成三个文件
- 存储空间
- InnoDB:存储空间大,因为它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引
- MyISAM:可以被压缩,存储空间小
- 适用范围
- InnoDB:适合频繁修改以及涉及到安全性较高的应用
- MyISAM:适合查询、插入为主的应用。
4. 索引
1. 索引概念、优缺点
特殊文件,包含着对数据库表里所有记录的引用指针。
索引是一种数据结构。协助更快查询、更新数据,通常以B树or B+树实现。
优点:加快检索速度,提高性能
缺点
- 时间方面:维护and创建需要耗费时间和空间,当对表中数据增加、删除和修改时,索引也要动态的维护,会降低增/改/删的执行效率。
- 空间方面:需要占用物理空间,一般为表大小的1.2倍
2. 使用场景
1. where
当用while作为限定条件执行操作时,一般以建立索引的字段为条件,如主键索引。查询效率有明显提升
2. order by
当使用order by将查询结果按某个字段排序时,若该字段没有建立索引,则执行计划会将查询出的所有数据使用外部排序(先将数据从硬盘中分批读取到内存中使用内部排序,最后合并排序结果),这个操作非常影响性能。 因为需要将查询涉及到的所有数据从磁盘中读到内存。
但度过对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引顺序和映射关系逐条取出数据即可。
3. join(连接方式)
对join语句匹配关系涉及的字段建立索引能够提高效率
3. 索引的几种类型
主键索引:数据列不允许重复,不允许为NULL,一个表只能有一个主键
唯一索引:数据列不允许重复,允许为NULL、一个表允许多个列创建唯一索引
普通索引:基本索引类型,没有唯一性限制,允许为NULL
全文索引:是目前搜索引擎使用的一种关键技术
4. 索引的数据结构
B树 or Hash
原理见B树与B+树
5. 创建索引的原则(重中之重)
- 适合索引的列是出现在where、order by、join子句中的列
- 数据量>300的库建议创建索引
- 查询频繁,但字段不频繁更新建议创建索引(索引提高查询速度,降低更新速度)
- 不能有效区分数据的列不适合做索引(选取离散大的字段)
- 主键和外键的数据列一定要建立索引
- 索引字段越小越好。
- 在进行联合索引创建时,要遵循最左前缀匹配原则,即"带头大哥不能死,中间兄弟不能断"
6. 百万级别或以上的数据如何删除
关于索引:由于对数据的增加、修改、删除都会产生额外对索引的维护,这些操作需要消耗额外的IO。
因此,在删除大量数据时,要先删除索引。
- 先删除索引(3min)
- 删除其中无用数据(<2min)
- 重新创建索引(数据少了,创建索引很快)
不仅更快,而且分段操作防止删除中断。
7. 前缀索引
语法:index(field(10)):使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
前提:前缀标识度高。比如密码就适合建立前缀索引。
实操难度:前缀截取的长度。
解决办法:利用select count(*)/count(distinct left(password,prefixLen));,通过调整prefixLen的值(从1自增)查看不同前缀长度的平均匹配度,接近1就OK
8. 聚簇索引和非聚簇索引
比喻:聚簇索引就好像是拼音查询,每一个字母查询的页面顺序与字母顺序一致,而非聚簇索引则是笔画查询,与页面顺序不一致
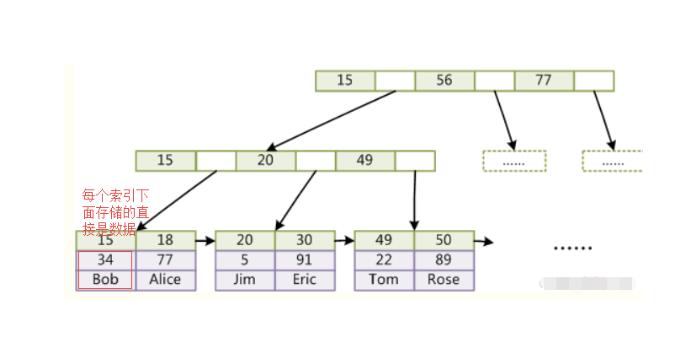
聚簇索引(InnoDB):将数据存储与索引放到了一块,找到索引也就找到了数据。
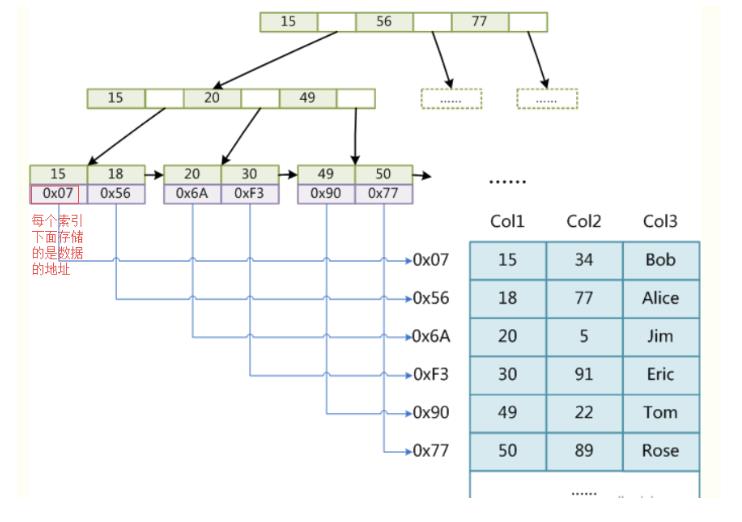
非聚簇索引(MyISAM):将数据存储与索引分开,索引结构的叶子结点指向数据对应行,使用时先把索引缓存到内存中,当需要访问数据时,再搜索索引,进一步从磁盘中找到相应数据。
辅助索引:Innodb中,聚簇索引之上创建的索引叫辅助索引,辅助索引访问一定需要二次查找。非聚簇索引都是辅助索引。辅助索引叶子结点的值不再是行的物理位置,而是主键值。
总结:聚簇索引的叶子结点就是数据节点,因此其为顺序,而非聚簇索引的叶子结点仍然是索引节点,只不过有指向对应数据块(可能指向的是聚簇索引)的指针。
非聚簇索引:
聚簇索引:
9. 非聚簇索引一定会回表查询吗?
不一定,涉及到查询语句所要求的的字段是否全部命中了索引,若全部命中,则不必回表查询。
10. 联合索引是什么?为什么需要注意联合索引的顺序?
核心:带头大哥不能死,中间兄弟不能断
MySQL可以使用多个字段同时建立一个索引,叫做联合索引,在联合索引中,想要命中索引,需要按照建立索引时的字段挨个使用,否则无法命中索引。
具体原因:
若建立了“a, b, c”的联合索引,那么索引排序为:先按a排序,若a相同,则按b排序,否则按c排序。
一般情况下,将查询需求频繁or字段选择性高的列放在最前。
*B树与B+树
1. 储备知识
1. 二叉搜索树
又称为BST。
1)若其左子树不空,则左子树上所有节点值小于根节点值。
2)若其右子树不空,则右子树上所有节点值大于根节点值
3)左右子树各为二叉排序树
注:若输出二叉排序树的中序序列,则该序列为递增的。
2. 二叉平衡树(AVL、B树)
又称为AVL、B(Balanced-Tree)树。
关键词:BST、平衡因子、平衡调整
LL型:即为在原来平衡的二叉树上,在节点的左子树的左子树下,有节点插入,导致节点的左右子树高度差为2。
解决办法:对节点右旋(顺时针90度)
2. 引入
当对磁盘IO时,IO的效率很低,当大量存储时,每个磁盘页对应一个树节点,若平衡二叉树过深,会造 成磁盘IO读写频繁,进而效率低下。
因此,若想减少磁盘IO的次数,就必须降低树的深度,将“瘦高”的树变为“矮胖”。一个基本想法是:
- 每个节点存储多个元素
- 摒弃二叉树结构,采用多叉树
因此引入:多路查找树。一棵平衡多路查找树(B树)自然使得数据查找效率保证在O(logn)的对数级别上。
3. B树
1. 概念描述
注意:B树和B-树为一种树
-
概念
B树和平衡二叉树不同的是B树属于多叉树,又名平衡多路查找树。
-
规则
- 排序方式:递增,左小右大(见图)
- 根节点的子节点个数为[2,M]
- 除根节点外的非叶子节点的子节点个数为[cell(M/2), M]。(cell(1,1) = 2)(防止B树退化成AVL)
- 所有叶子结点都在同一层。
-
一个3阶的B树:
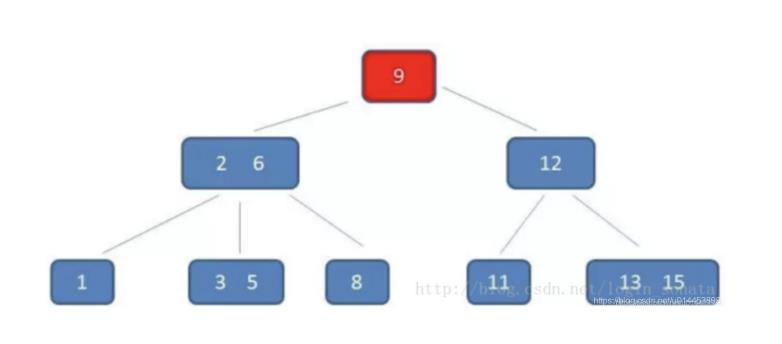
可以看到:
- 除根节点外,所有非叶子结点都至少有cell(3/2)=2个节点
- 每个节点的索引值都是升序的
- 所有叶子结点都在同一层
2. 查找节点过程
查找节点5:
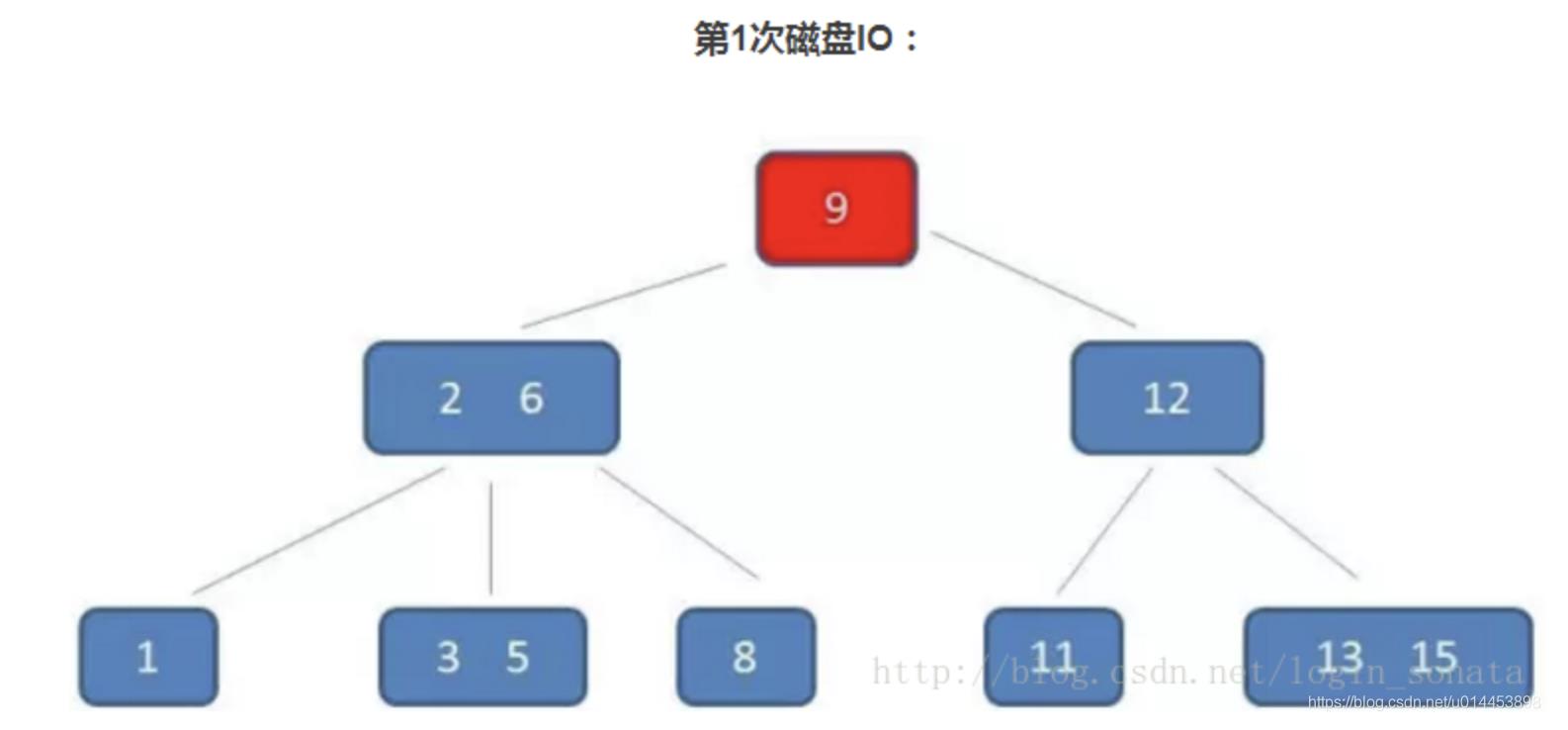
(1)第一次读IO,先把9的节点读到内存,5<9,则往左走。
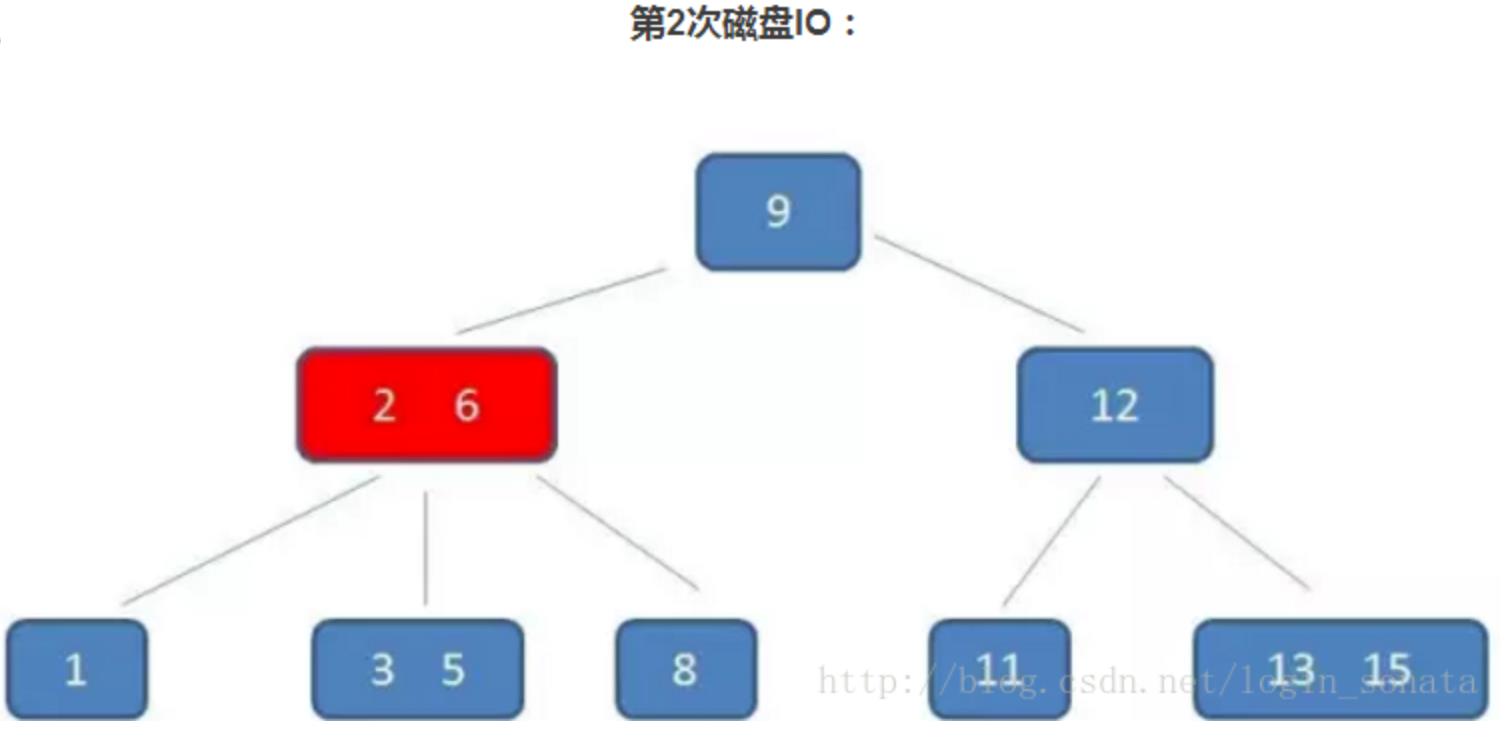
(2)第二次读IO,把节点读入内存,与2和6比较,发现5大于2,小于6,因此往中间路径走
(3)第三次读IO,把节点读入内存,发现有5,结束。
优点:
- 减少查找次数,也就是减少IO,提高效率(当数据量大时,即使是AVL,也一定非常高,读取IO的次数也会多,因此引入B树,B树的一个节点可以装多个值,读取时,把整个节点读到内存,接下来进行处理,在内存中处理一定比在磁盘中快,因此只要IO少,就能提升查询效率)
- B树每个节点都包含key(索引值)和value(对应数据),因此方位离根节点近的元素会更快(相对于B+树)
3. 添加节点过程
以5阶B树为例
5阶B树就是每个节点最多4个元素。原因:要满足每个元素左边比它小,右边比它大,因此最多4个元素的节点可以有5个分支
插入过程:
-
与查找类似,每插入一个新节点,就从根节点开始找,若小于它,则遍历其左子树;若大于它,则遍历其右子树。
-
也就是说,最后都会插入到叶节点中。
-
当叶节点中元素个数大于阈值,则该叶节点分裂,中间节点上升为根节点中的元素。
-
若根节点中元素个数也大于阈值,则根节点分裂,中间节点上升。
-
具体过程见图。
(a)在空树中插入39

此时根节点中只有一个索引值
(b)继续插入22,97和41
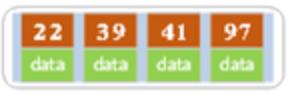
根结点此时有4个索引值。
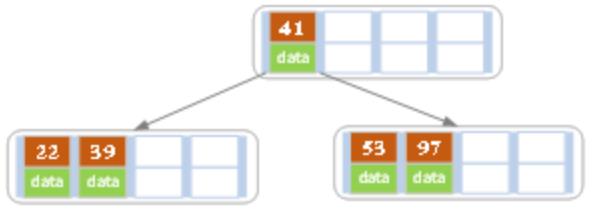
(c)继续插入53:

此时已经超过了最大允许的索引个数4,即4个。所以以其中心(41)分裂。结果如下图所示:
(d)然后在上图的基础上,再依次插入13,21,40,那么41所在结点的左子结点里的值就为13、21、22、39、40,一共五个,所以会以22为中心进行分裂,结果如下图所示:
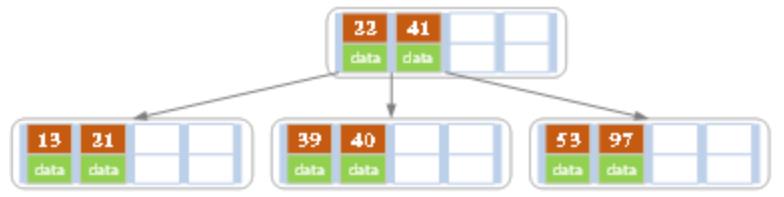
分裂的中心22会进位到上一层的结点中。
(e)再在上图的基础上,插入30,27,33,那么其中有一个结点内的值为27、30、33、39、40,那么就会以33为中心引起一次分裂。
然后再插入36,35,34,那么就又会有一个结点内的值为34、35、36、39、40,那么就会以36为中心分裂。
然后再插入24、29,如下图所示:

此时拥有24、27、29、30的结点只要再插入一个索引值,就又会发生分裂。
(f) 插入26
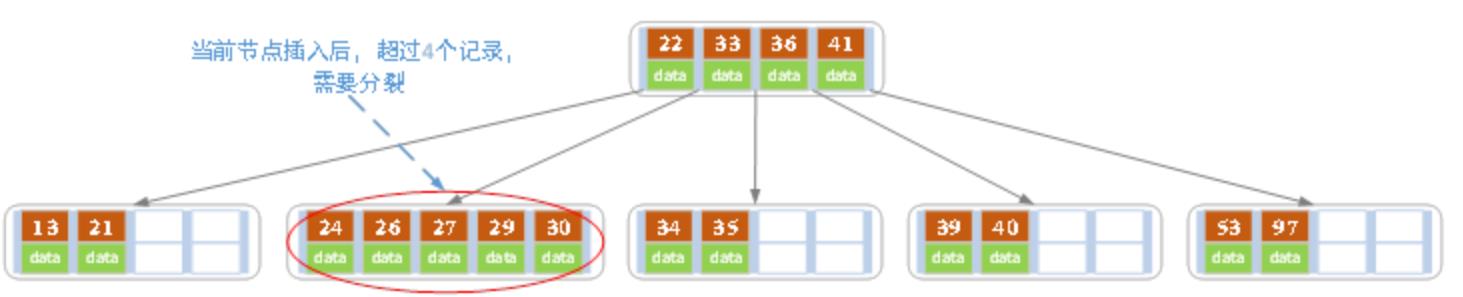
插入26后,结点以27为中心分裂,并且27进位到上一层父结点中。
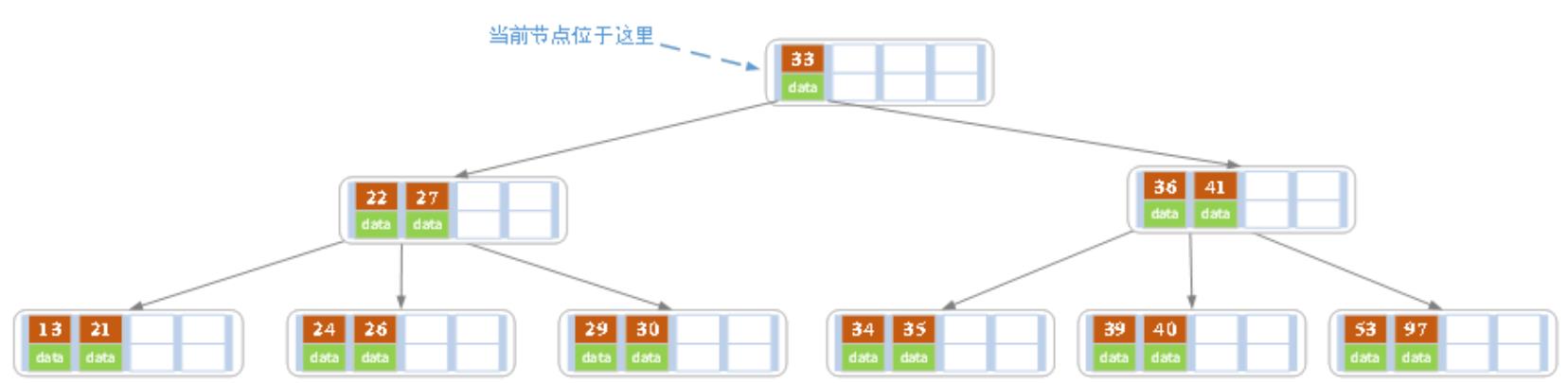
(g)27进位到父节点后,父节点里的索引值也超过了4个,因此也要分裂,分裂后如下:
27进位后的B树:

根结点分裂后的B树:
4. 删除节点过程
删除元素时的原则:节点中的元素个数应>=cell(m/2)
若节点中缺少元素,可行的方法是
- 和兄弟借:下移+上移
- 兄弟不够和爹借:下移
- 如果把爹借没了,就由下一层节点合并出来一个新爹。
(a)原始状态
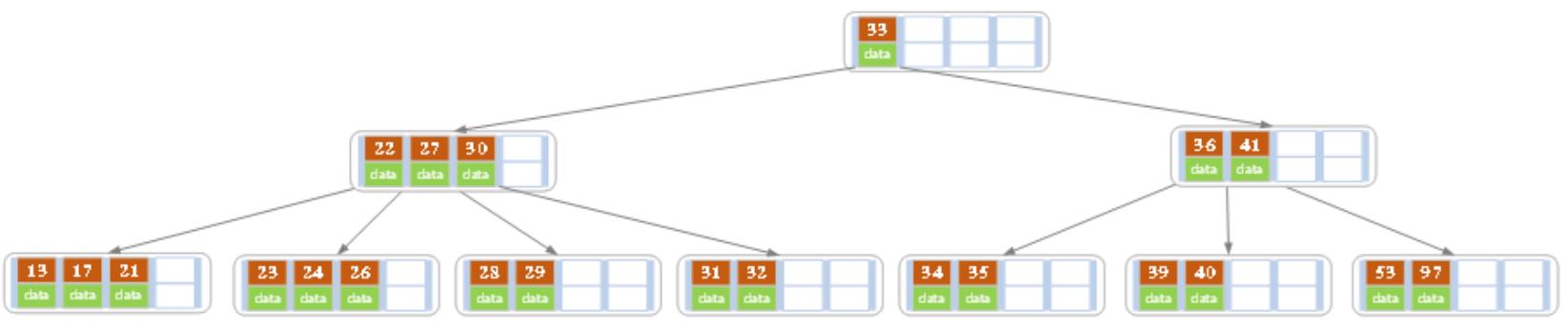
(b)再上图的树中,删除21
由于删除21后的结点的索引值个数仍然大于2(Math.ceil( 5/2 ) -1 =2),因此删除结束。
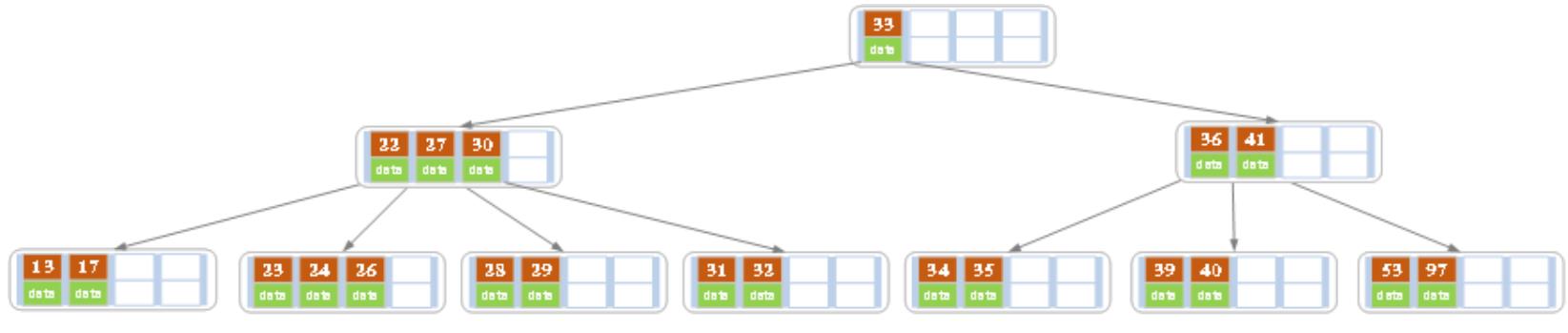
(c)接着删除27
从上图可知,由于27是非叶子结点,所以要删除27的话,需要用27的后继替代它。从上图可以看出,27的后继是28,因此我们用28来替代27,再删除原来的28,如下图:
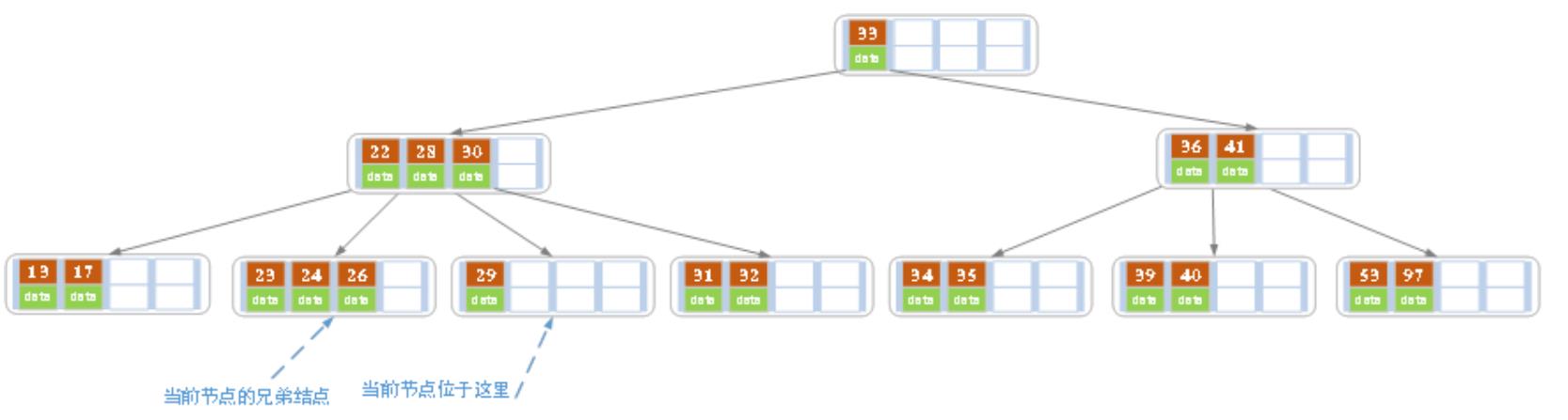
删除后发现,当前结点(当前结点如上图所示)的索引值个数小于2个,而它的兄弟结点有3个索引值(当前结点还有一个右兄弟,选择右兄弟的话,会出现合并结点的情况,不论选哪一个都可以,只是最后的B树形态会不一样而已),那么就向左兄弟借一个索引值,注意这里的借并非直接从左兄弟结点处拿一个索引值过来,如果是这样的话,就破坏了B树父节点左子树比根结点小,右子树比根结点大的特性了。借是 把当前结点的父节点的28下移,然后把左兄弟结点的26上移到父节点,删除结束。如下图:
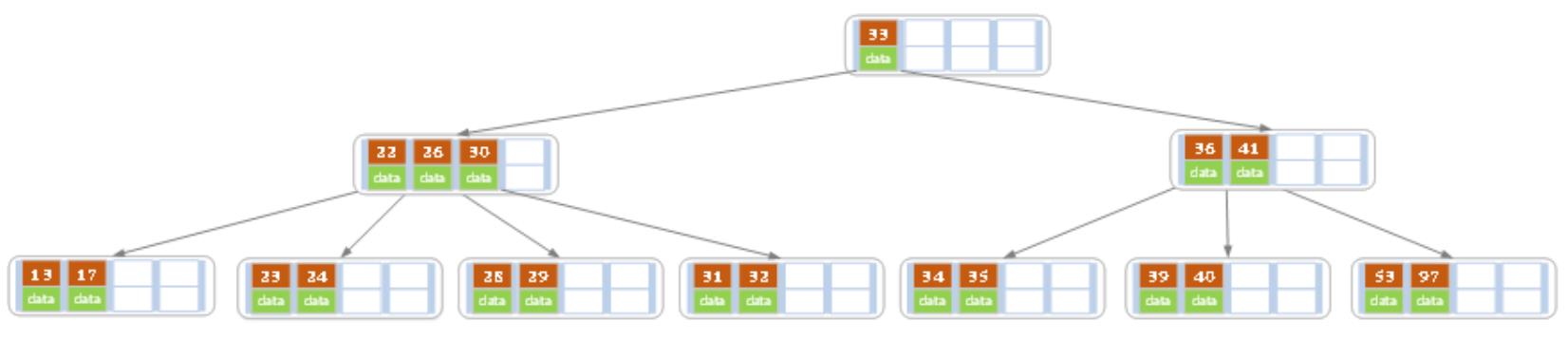
(d)在上述情况接着删除32:如下图
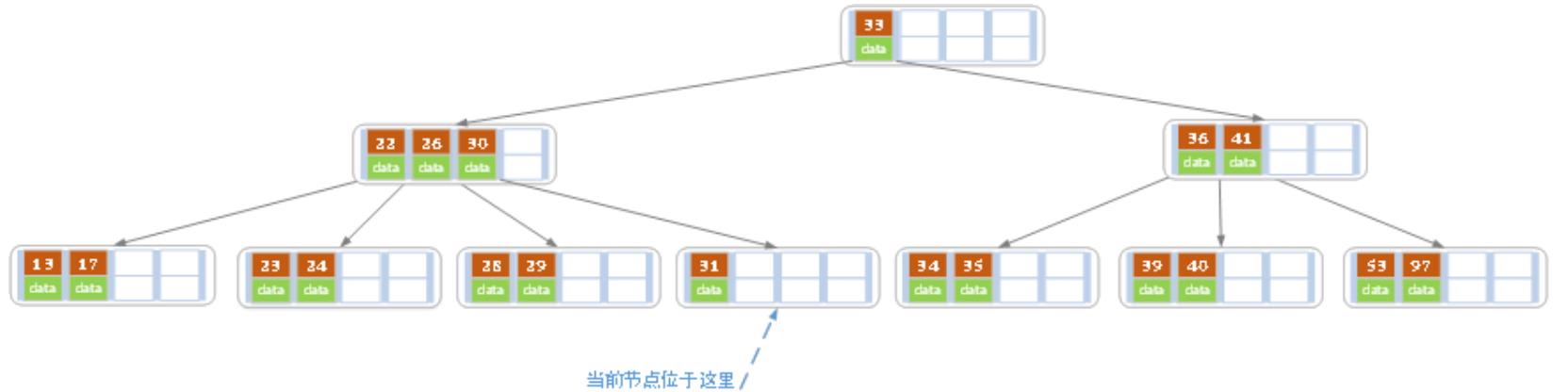
在删除32后,当前结点剩下31,即索引值数目小于2。这时候,它的兄弟结点,也仅仅有2个索引值,所以不能向兄弟结点借。
那只能够让父结点下移一个值(30),并和兄弟结合合并成一个新的结点,如下图:
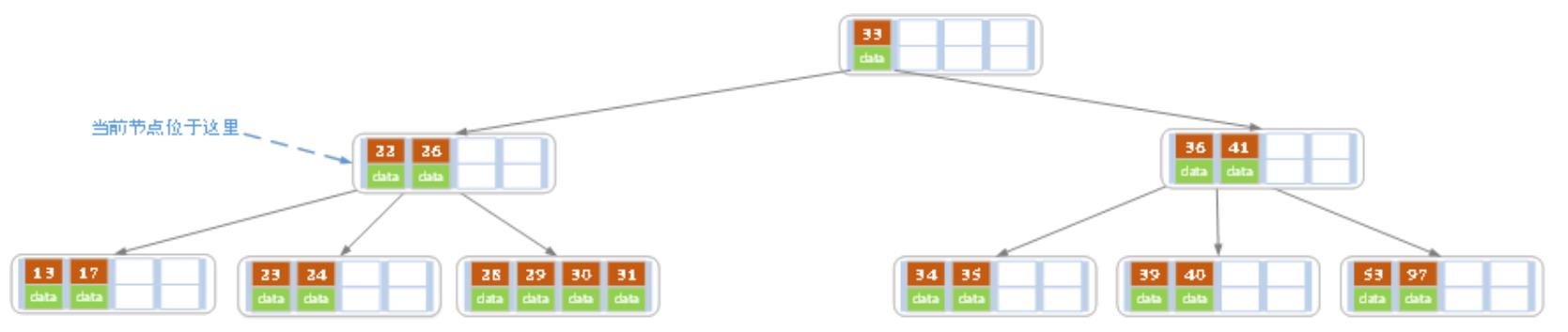
当前结点的索引值个数不小于2 (Math.ceil( 5/2 ) -1 =2),满足条件,删除结束。
(e)接着删除 40:
删除40后,如下图所示:
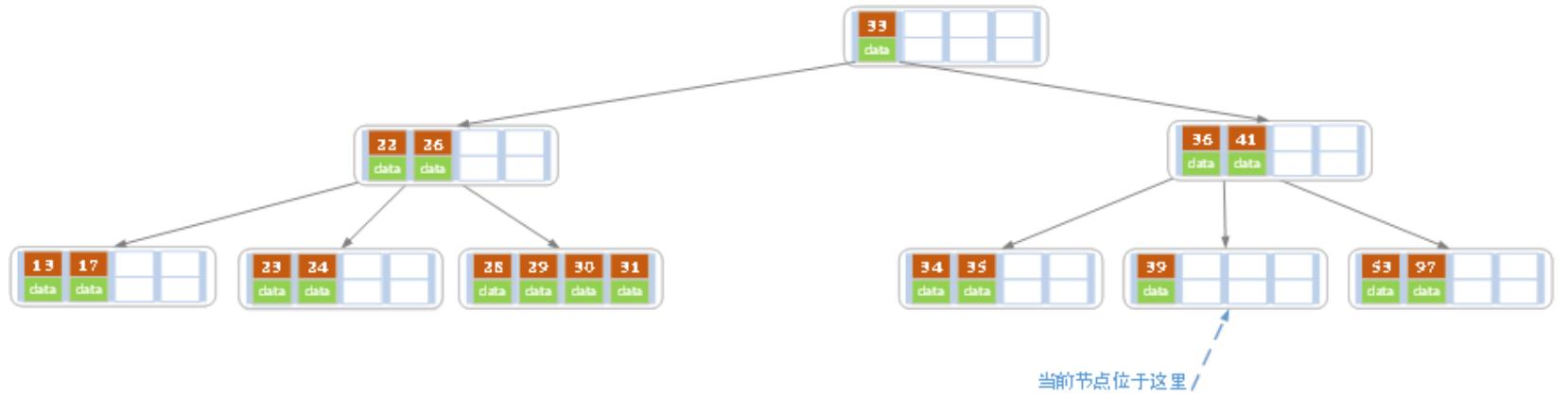
当前结点由于索引值小于2,因此需要像父结点借,父结点下移36到当前结点,然后和兄弟结点合并(选择左兄弟或右兄弟都可以,这里我选择了左兄弟),如下图:
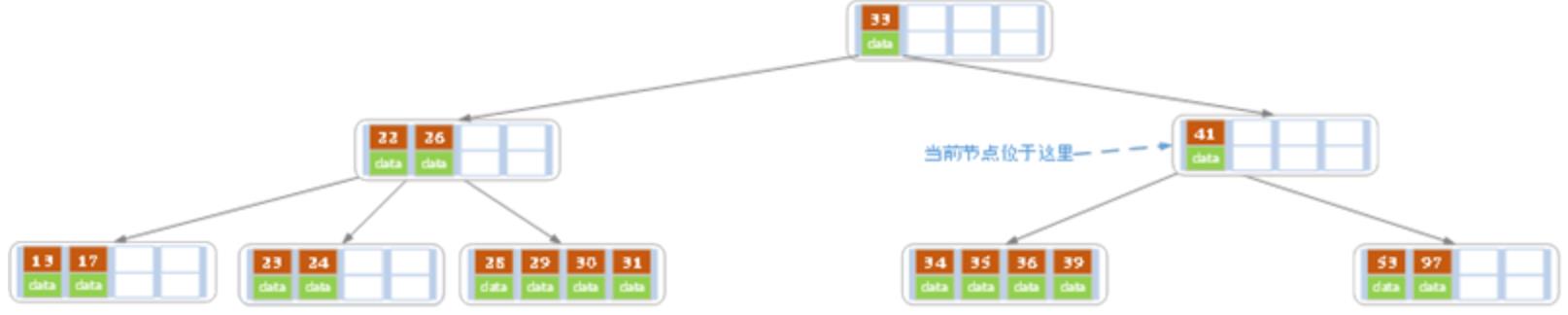
但这时候发现,新的当前结点的索引值个数又小于2了,那么只能向其父结点借了,所以其父结点下移33,然后当前结点和其兄弟结点合并,如下图:

删除结束
4. B+树
1. B+树图示
B+树是基于B树的基础提出的。
下图是一棵4阶B+树:
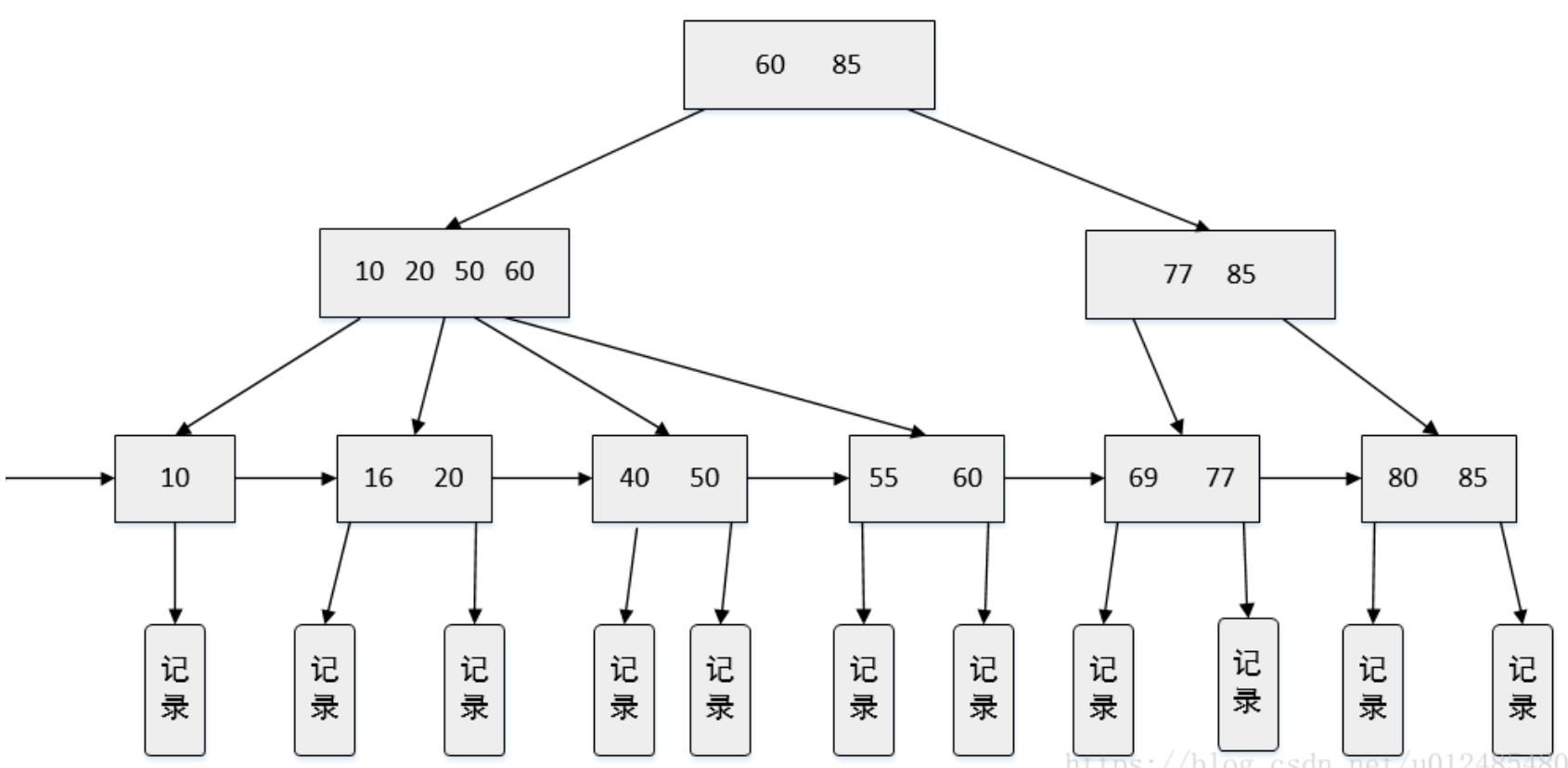
2. 二者区别
- B+树内有两种节点,一种是索引节点,一种是叶子结点
- B+树的索引节点不会保存记录,只用于索引(因此索引的很快),所有数据都保存在B+树的叶子结点中,而B树则是所有节点都会保存数据。
- B+树的叶子结点都会被连成一条链表。叶子本身按索引值的大小从小到大排序。即这条链表是从小到大的。多了条链表方便范围查找数据。
- B树的所有索引值不会重复。而B+树的非叶子节点的索引值,最终一定全部出现在叶子结点中。
3. 为什么要有B+树
B树优势:每一个节点都包含key(索引值)和value(对应数据),因此方位离根节点近的元素会更快速。(相对B+树)
B树不足:不利于范围查找,若想找0~100的索引值,则B树需多次从根节点开始逐个查找。
而B+树可以通过遍历链表实现范围查找。
5. 相关问题
1. Hash和B+树的优劣
核心:Hash函数的不可预测性
-
hash索引等值查询快,但无法范围查询。
-
hash不支持使用索引排序。
-
hash不支持模糊查询、多列索引的最左前缀匹配,因为
-
hash索引无法避免回表查询数据,而B+树在符合某些条件(聚簇索引、覆盖索引等)可只通过索引完成查询
2. 为什么使用B+树而不是B树
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索。
- B+树空间利用率高,减少I/O次数,磁盘读写代价低。由于大部分节点只是作为索引使用,因此内部节点小,一次性读入内存中可以查找的关键词多,IO读写次数降低。
- B+树查询效率更加稳定
核心优势:稳定、节点小、支持顺序检索
5. 事务
1. 什么是数据库事务
事务是一个不可分割的数据库操作序列,是数据库并发控制的基本单位,要么都执行,要么都不执行。
2. 事务的四大特性(ACID)
- 原子性(Atomicity):事务是最小的执行单位,不允许分割,要么全部执行,要么完全不执行
- 一致性(Consistency):指一个事务执行前和执行后数据库必须处于一致性状态
- 隔离性(Isolation):并发的事务是相互隔离的。
- 持久性(Durability):事务对数据库中数据的改变是持久的。
3. 什么是脏读?幻读?不可重复度?
- 脏读(Dirty Read):在事务A更新数据后,还未提交,事务B读取后,事务A才提交,此时事务B发生脏读。
- 不可重复读(Non-repeatable read):一个事务的两次查询中数据不一致,可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读(Phantom Read):在一个事务的两次查询中数据个数不一致。可能是两次查询过程中插入了数据。
4. 事务隔离级别
- read-uncommitted(读未提交):允许读尚未提交的数据。可能导致脏读、不可重复读和幻读。
- read-committed(读已提交):允许读取并发事务已经提交的数据,可以阻止脏读,但无法阻止幻读和不可重复读。
- repeatable-read(可重复读):对同一字段多次读取的结果是一致的。可以组织脏读和不可重复读,无法阻止幻读。
- serializable(可串行化):最高的隔离级别,完全服从ACID的隔离级别,所有事务依次逐个执行,事务之间完全不可能产生干扰。防止幻读、不可重复读和脏读
Mysql默认采用可重复读隔离级别
6. 锁
1. 对MySQL的锁了解吗
当数据库有并发事务时,会产生问题,需要锁。
2. 隔离级别与锁的关系
在读未提交级别下,无需加锁
在读已提交级别下,读操作需加共享锁,语句执行完后可以释放共享锁(因此可防止脏读,也就是防止自己读的时候别人给写了)
在可重复读级别下,读操作需加共享锁,事务执行完可以释放共享锁(因此可防止不可重复读)
在可串行化级别下,锁定整个范围的键,并一直持有锁,直到事务完成
3. 按照锁的粒度对数据库锁分类
按锁的粒度把数据库分为行级锁(Innodb引擎)、表级锁(MyIsam引擎)和页级锁
行级锁:粒度最细,表示只针对当前行操作加锁,大大减少数据库操作冲突,但开销大。分为共享锁和排它锁。
表级锁:MySQL中锁定粒度最大的锁,资源消耗少。同样分为共享锁和排它锁
页级锁:锁定粒度介于行级锁和表级锁中间的一种锁,表级锁速度快,但冲突多,行级锁冲突少,但速度慢,因此采取了折中的页集。
4. 按锁的类别分类
共享锁:读锁,当用户进行数据读取时,对数据加共享锁,可以同时加多个
排它锁:写锁,当用户进行数据写入时,对数据加排它锁,只能加一个。与其他排他锁、共享锁都互斥。
5. 死锁及解决
概念:只两个或多个事务在统一资源上相互占用,并请求锁定对方资源。
解决死锁办法:
- 约定以相同顺序对表操作
- 做到一次锁定所有需要的资源
- 升级锁粒度。
6. 乐观锁和悲观锁?怎么实现?
悲观锁:假设发生并发冲突,屏蔽一切可能违反数据库完整性的操作,直到提交事务。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。一般使用版本号机制或CAS算法实现。
适用场景:乐观锁适用于写比较少的情况下,反之悲观锁
7. 视图
核心:虚拟,逻辑抽象(抽象一部分(安全性)or把几个抽象为一个(简化操作))
1. 视图概念,为什么要用?
为了提高复杂SQL语句的复用性和表操作的安全性。
所谓视图,本质上是虚拟表,在具体引用视图时动态生成。
视图使用户只能看到视图中定义的数据,提高安全性。
2. 视图特点
- 视图列可来自不同表,在不同表的抽象和逻辑意义上建立新关系
- 视图是由基本表产生的虚表
- 视图的建立和删除不影响基本表。
- 但对视图内容的更新直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。
3. 视图使用场景
根本作用:简化SQL、提高开发效率
- 重用SQL语句
- 简化复杂的SQL操作。(编写查询后,可以很方便的重用它而不必知道其基本查询细节)
- 使用表的组成部分而不是整个表
- 保护数据,可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
4. 视图优缺点
优点
- 查询简单化,简化用户操作
- 数据安全性,对机密数据提供安全保护
- 逻辑数据独立性:对重构数据库提供了一定程度的逻辑独立性。
缺点
- 性能低:对视图的查询必须转化为对基本表的查询
- 修改限制:对于多个基本表抽象的视图,是不可修改的
5. 什么是游标?
系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,(是一种能从多条记录集中每次提取一条记录的机制)
8. 存储过程与函数
代码片段核心:效率高(时间+空间)、调试麻烦、移植麻烦、维护麻烦
1. 存储过程及其优缺点
存储过程就是一个预编译的SQL语句,只需创建一次,以后在该程序中可以调用多次,实现复用性
优点:效率高、安全性高、减少工作量
缺点:调试麻烦、移植问题、维护麻烦
9. 触发器
1. 触发器及使用场景
触发器指一段代码,当触发某个事件时,自动执行这些代码。
其他问题
1. drop、delete与truncate的区别
drop:直接删除表
delete:删除表中部分数据,但需逐行删除,速度慢
truncate:删除表中全部数据,但保留表结构
2. UNION与UNION ALL的区别?
若使用union all,不会合并重复的记录航
union效率高于union all
3. SQL生命周期
- 应用服务器与数据库服务器建立连接
- 数据库进程拿到请求sql
- 解析并生成执行计划,执行
- 读取数据到内存并进行逻辑处理
- 通过步骤一的连接,发送结果到客户端
- 关掉连接,释放资源
4. 大表数据查询怎么优化
- 优化SQL语句、索引
- 第二加缓存:redis等。
- 主从复制、读写分离
- 降低耦合度,分布式系统
- 水平切分,将表拆分
以上是关于硬核!MySQL数据库面经大全——双非上岸阿里巴巴系列的主要内容,如果未能解决你的问题,请参考以下文章