可能是最详尽的PyTorch动态图解析
Posted 程序员野客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可能是最详尽的PyTorch动态图解析相关的知识,希望对你有一定的参考价值。

作者丨Gemfield@@知乎
https://zhuanlan.zhihu.com/p/61765561
https://zhuanlan.zhihu.com/p/65822256
PyTorch的动态图(上)
背景
PyTorch的动态图框架主要是由torch/csrc/autograd下的代码实现的。这个目录下定义了3个主要的基类:Variable、Function、Engine,这三个基类及其继承体系共同构成了PyTorch动态图的根基。
为什么叫作动态图呢?图容易理解,Function是nodes/vertices,(Function, input_nr)是edges。那么动态体现在什么地方呢?每一次前向时构建graph,反向时销毁。本文就以torch/csrc/autograd/下的代码为基础,深入讲解PyTorch的动态图系统——这也可能是互联网上关于PyTorch动态图最详尽的文章了。
在专栏文章《PyTorch的初始化》(https://zhuanlan.zhihu.com/p/57571317)中,gemfield描述了PyTorch的初始化流程,在文末提到了THPAutograd_initFunctions()调用:“最后的THPAutograd_initFunctions()则是初始化了torch的自动微分系统,这是PyTorch动态图框架的基础”。而本文将以THPAutograd_initFunctions开始,带你走入到PyTorch的动态图世界中。首先为上篇,主要介绍Function、Variable、Engine的类的继承体系。
autograd初始化
THPAutograd_initFunctions这个函数实现如下:
void THPAutograd_initFunctions()
{
THPObjectPtr module(PyModule_New("torch._C._functions"));
......
generated::initialize_autogenerated_functions();
auto c_module = THPObjectPtr(PyImport_ImportModule("torch._C"));
}
用来初始化cpp_function_types表,这个表维护了从cpp类型的函数到python类型的映射:
static std::unordered_map<std::type_index, THPObjectPtr> cpp_function_types
这个表里存放的都是和autograd相关的函数的映射关系,起什么作用呢?比如我在python中print一个Variable的grad_fn:
>>> gemfield = torch.empty([2,2],requires_grad=True)
>>> syszux = gemfield * gemfield
>>> syszux.grad_fn
<ThMulBackward object at 0x7f111621c350>
grad_fn是一个Function的实例,我们在C++中定义了那么多反向函数(参考下文),但是怎么在python中访问呢?就靠上面这个表的映射。实际上,cpp_function_types这个映射表就是为了在python中打印grad_fn服务的。
Variable
参考:https://zhuanlan.zhihu.com/p/64135058
以下面的代码片段作为例子:
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
需要指出的是,动态图是在前向的时候建立起来的。gemfieldout作为前向的最终输出,在反向传播的时候,却是计算的最初输入—在动态图中,我们称之为root。在下文介绍Engine的时候,你就会看到,我们会使用gemfieldout这个root来构建GraphRoot实例,以此作为Graph的输入。
Function
在开始介绍Function之前,还是以上面的代码为例,在一次前向的过程中,我们会创建出如下的Variable和Function实例:
#Variable实例
gemfield --> grad_fn_ (Function实例)= None
--> grad_accumulator_ (Function实例)= AccumulateGrad实例0x55ca7f304500
--> output_nr_ = 0
#Function实例, 0x55ca7f872e90
AddBackward0实例 --> sequence_nr_ (uint64_t) = 0
--> next_edges_ (edge_list) --> std::vector<Edge> = [(AccumulateGrad实例, 0),(0, 0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu])]
--> alpha (Scalar) = 1
--> apply() --> 使用 AddBackward0 的apply
#Variable实例
syszux --> grad_fn_ (Function实例)= AddBackward0实例0x55ca7f872e90
--> output_nr_ = 0
#Function实例, 0x55ca7ebba2a0
MulBackward0 --> sequence_nr_ (uint64_t) = 1
--> next_edges_ (edge_list) = [(AddBackward0实例0x55ca7f872e90,0),(AddBackward0实例0x55ca7f872e90,0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu])]
--> alpha (Scalar) = 1
--> apply() --> 使用 MulBackward0 的apply
# #Variable实例,syszux * syszux得到的tmp
tmp --> grad_fn_ (Function实例)= MulBackward0实例0x55ca7ebba2a0
--> output_nr_ = 0
#Function实例,0x55ca7fada2f0
MulBackward0 --> sequence_nr_ (uint64_t) = 2 (每个线程内自增)
--> next_edges_ (edge_list) = [(MulBackward0实例0x55ca7ebba2a0,0),(0,0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu])]
--> self_ (SavedVariable) = tmp的浅拷贝
--> other_ (SavedVariable) = 3的浅拷贝
--> apply() --> 使用 MulBackward0 的apply
#Variable实例
civilnet --> grad_fn_ (Function实例)= MulBackward0实例0x55ca7fada2f0 -
#Function实例,0x55ca7eb358b0
MeanBackward0 --> sequence_nr_ (uint64_t) = 3 (每个线程内自增)
--> next_edges_ (edge_list) = [(MulBackward0实例0x55ca7fada2f0,0)]
--> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType|[]|cpu])]
--> self_sizes (std::vector<int64_t>) = (2, 2)
--> self_numel = 4
--> apply() --> 使用 MulBackward0 的apply
#Variable实例
gemfieldout --> grad_fn_ (Function实例)= MeanBackward0实例0x55ca7eb358b0
--> output_nr_ = 0
这些用于反向计算的Function实例之间通过next_edges_连接在一起,因为这些Function的实际运行都是在反向期间,因此,输出输出关系正好和前向期间是反过来的。它们通过next_edges_连接在一起。用一个图来概括,就是下面这样:
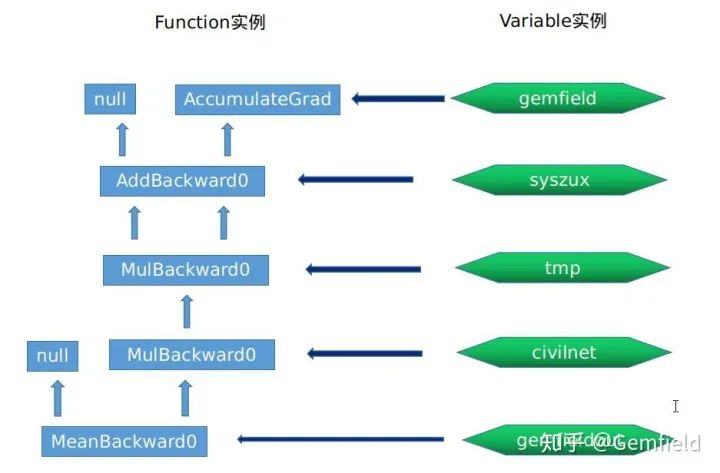
这就引入一个新的话题——Function类是如何抽象出来的。
#Function基类定义
Function的数据成员如下所示:
using edge_list = std::vector<Edge>;
using variable_list = std::vector<Variable>;
struct TORCH_API Function {
...
virtual variable_list apply(variable_list&& inputs) = 0;
...
const uint64_t sequence_nr_;
edge_list next_edges_;
PyObject* pyobj_ = nullptr; // weak reference
std::unique_ptr<AnomalyMetadata> anomaly_metadata_ = nullptr;
std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_;
std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_;
at::SmallVector<InputMetadata, 2> input_metadata_;
};
#Function call
Function类是抽象出来的基类,代表一个op(operation),每个op接收的参数是0个、1个或多个Variable实例(使用std::vector封装),并与此同时输出0个、1个或多个Variable实例。PyTorch中所有用于反向传播计算的函数都继承自Function类,并重写了Function类中的apply纯虚函数。因为Function类中实现了call函数:
variable_list operator()(variable_list&& inputs) {
return apply(std::move(inputs));
}
所以依靠C++的多态,对op的call将转化为自身(子类)的apply调用。Function类中最重要的方法是call函数,call会调用apply,call函数接收vector封装的多个Variable实例,并输出vector封装的多个Variable实例。输入参数的vector长度可以由num_inputs()调用获得,对应的,输出的vector长度则由num_outputs()获得。
#Function的输入
Function成员input_metadata_代表input data的meta信息,界定了一个Function的输入:
struct InputMetadata {
...
const at::Type* type_ = nullptr;
at::DimVector shape_;
at::Device device_ = at::kCPU;
};
#Autograd graph的edge和vertices
如果将PyTorch的autograd系统看作是一个图(graph)的话,那么每个Function实例就是graph中的节点(nodes/vertices),各个Function实例之间则是通过Edge连接的。Edge是个结构体,通过 (Function, input_nr) 的配对来代表graph中的edge:
struct Edge {
...
std::shared_ptr<Function> function;
uint32_t input_nr;
};
Function的成员next_edges_正是一组这样的Edge实例,代表此function实例的返回值要输出到的(另外)function,也即next_edges_是function和function之间的纽带。
Function的输入输出都是Variable实例,因此,当一个graph被执行的时候,Variable实例就在这些edges之间来传输流动。当两个或者多个Edge指向同一个Function的时候(这个节点的入度大于1),这些edges的输出将会隐含的相加起来再送给指向的目标Function。
Function和Function之间通过next_edge接口连接在一起,你可以使用add_next_edge()来向Function添加一个edge, 通过next_edge(index)获取对应的edge,通过next_edges()方法获得迭代edge的迭代器。每一个Function都有一个sequence number,随着Function实例的不断构建而单调增长。你可以通过sequence_nr()方法来或者一个Function的sequence number。
Function继承体系
基类Function直接派生出TraceableFunction和以下这些Function:
CopySlices : public Function
DelayedError : public Function
Error : public Function
Gather : public Function
GraphRoot : public Function
Scatter : public Function
AccumulateGrad : public Function
AliasBackward : public Function
AsStridedBackward : public Function
CopyBackwards : public Function
DiagonalBackward : public Function
ExpandBackward : public Function
IndicesBackward0 : public Function
IndicesBackward1 : public Function
PermuteBackward : public Function
SelectBackward : public Function
SliceBackward : public Function
SqueezeBackward0 : public Function
SqueezeBackward1 : public Function
TBackward : public Function
TransposeBackward0 : public Function
UnbindBackward : public Function
UnfoldBackward : public Function
UnsqueezeBackward0 : public Function
ValuesBackward0 : public Function
ValuesBackward1 : public Function
ViewBackward : public Function
PyFunction : public Function
这其中,从基类Function派生出来的AccumulateGrad、TraceableFunction、GraphRoot是比较关键的类。
#派生类AccumulateGrad
先说说AccumulateGrad,AccumulateGrad正是Variable的grad_accumulator_成员的类型:
struct AccumulateGrad : public Function {
explicit AccumulateGrad(Variable variable_);
variable_list apply(variable_list&& grads) override;
Variable variable;
};
可见一个AccumulateGrad实例必须用一个Variable构建,apply调用接收一个list的Variable的实例——这都是和Variable的grad_accumulator_相关的。
#派生类GraphRoot
对于GraphRoot,前向时候的最终输出——在反向的时候作为最初输入——是由GraphRoot封装的:
struct GraphRoot : public Function {
GraphRoot(edge_list functions, variable_list inputs)
: Function(std::move(functions)),
outputs(std::move(inputs)) {}
variable_list apply(variable_list&& inputs) override {
return outputs;
}
variable_list outputs;
};
GraphRoot——正如Function的灵魂在apply一样——其apply函数仅仅返回它的输入!
#派生类TraceableFunction
再说说TraceableFunction:
struct TraceableFunction : public Function {
using Function::Function;
bool is_traceable() final {
return true;
}
};
TraceableFunction会进一步派生出372个子类(2019年4月),这些子类的名字都含有一个共同的部分:Backward。这说明什么呢?这些函数将只会用在反向传播中:
AbsBackward : public TraceableFunction
AcosBackward : public TraceableFunction
AdaptiveAvgPool2DBackwardBackward : public TraceableFunction
AdaptiveAvgPool2DBackward : public TraceableFunction
AdaptiveAvgPool3DBackwardBackward : public TraceableFunction
AdaptiveAvgPool3DBackward : public TraceableFunction
AdaptiveMaxPool2DBackwardBackward : public TraceableFunction
AdaptiveMaxPool2DBackward : public TraceableFunction
AdaptiveMaxPool3DBackwardBackward : public TraceableFunction
AdaptiveMaxPool3DBackward : public TraceableFunction
AddBackward0 : public TraceableFunction
AddBackward1 : public TraceableFunction
AddbmmBackward : public TraceableFunction
AddcdivBackward : public TraceableFunction
AddcmulBackward : public TraceableFunction
AddmmBackward : public TraceableFunction
AddmvBackward : public TraceableFunction
AddrBackward : public TraceableFunction
......
SoftmaxBackwardDataBackward : public TraceableFunction
SoftmaxBackward : public TraceableFunction
......
UpsampleBicubic2DBackwardBackward : public TraceableFunction
UpsampleBicubic2DBackward : public TraceableFunction
UpsampleBilinear2DBackwardBackward : public TraceableFunction
UpsampleBilinear2DBackward : public TraceableFunction
UpsampleLinear1DBackwardBackward : public TraceableFunction
UpsampleLinear1DBackward : public TraceableFunction
UpsampleNearest1DBackwardBackward : public TraceableFunction
UpsampleNearest1DBackward : public TraceableFunction
UpsampleNearest2DBackwardBackward : public TraceableFunction
UpsampleNearest2DBackward : public TraceableFunction
UpsampleNearest3DBackwardBackward : public TraceableFunction
UpsampleNearest3DBackward : public TraceableFunction
UpsampleTrilinear3DBackwardBackward : public TraceableFunction
UpsampleTrilinear3DBackward : public TraceableFunction
......
这300多个Backward function都重写了apply函数,来实现自己的反向求导算法,比如加法的反向求导函数AddBackward0:
struct AddBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
Scalar alpha;
};
这些apply函数是Function的灵魂,是反向传播计算时候的核心执行逻辑。
Engine
Engine类实现了从输出的variable(以及它的gradients)到root variables(用户创建的并且requires_grad=True)之间的反向传播。
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
还是以上面这个代码片段为例,Engine实现了从gemfieldout到gemfield的反向传播:
1,如何根据gemfieldout构建GraphRoot;
2,如何根据这些Function实例及它们上的metadata构建graph;
3,如何实现Queue来多线程完成反向计算的工作。
#Engine类定义
Engine类的定义如下:
struct Engine {
using ready_queue_type = std::deque<std::pair<std::shared_ptr<Function>, InputBuffer>>;
using dependencies_type = std::unordered_map<Function*, int>;
virtual variable_list execute(const edge_list& roots,const variable_list& inputs,...const edge_list& outputs = {});
void queue_callback(std::function<void()> callback);
protected:
void compute_dependencies(Function* root, GraphTask& task);
void evaluate_function(FunctionTask& task);
void start_threads();
virtual void thread_init(int device);
virtual void thread_main(GraphTask *graph_task);
std::vector<std::shared_ptr<ReadyQueue>> ready_queues;
};
核心就是execute函数,它接收一组Edge——(Function, input number) pairs ——来作为函数的输入,然后通过next_edge不断的找到指向的下一个Edge,最终完成整个Graph的计算。
#派生类PythonEngine
然而我们实际使用的是Engine类的派生类:PythonEngine。PythonEngine子类重写了父类的execute,只不过仅仅提供了把C++异常翻译为Python异常的功能,核心工作还是由Engine基类来完成:
struct PythonEngine : public Engine
整个PyTorch程序全局只维护一个Engine实例,也就是PythonEngine实例。
BP调用栈
既然Engine是用来计算网络反向传播的,我们不妨看下这个调用栈是怎么到达Engine类的。如果我们对gemfieldout进行backward计算,则调用栈如下所示:
#torch/tensor.py,self is gemfieldout
def backward(self, gradient=None, retain_graph=None, create_graph=False)
|
V
#torch.autograd.backward(self, gradient, retain_graph, create_graph)
#torch/autograd/__init__.py
def backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
|
V
Variable._execution_engine.run_backward(tensors, grad_tensors, retain_graph, create_graph,allow_unreachable=True)
#转化为Variable._execution_engine.run_backward((gemfieldout,), (tensor(1.),), False, False,True)
|
V
#torch/csrc/autograd/python_engine.cpp
PyObject *THPEngine_run_backward(THPEngine *self, PyObject *args, PyObject *kwargs)
|
V
#torch/csrc/autograd/python_engine.cpp
variable_list PythonEngine::execute(const edge_list& roots, const variable_list& inputs, bool keep_graph, bool create_graph, const edge_list& outputs)
|
V
#torch/csrc/autograd/engine.cpp
Engine::execute(roots, inputs, keep_graph, create_graph, outputs)
总结
在下段文章中,Gemfield将主要介绍Engine这个类是如何在gemfieldout.backward()中运行PyTorch动态图的。
PyTorch的动态图(下)
背景
在 上文中,我们介绍了PyTorch autograd系统的三个基石:Variable、Function、Engine。
用一句简单的话来概括下,就是Engine使用Function构建的Graph来计算得到Variable上grad。在本文中,Gemfield将以下面的代码片段为例,详细介绍Engine如何构建Graph来进行反向传播计算:
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
BP Engine
BP Engine是一个反向传播计算中用于动态生成计算图的类,目前PyTorch中只定义了一种BP Engine的实现。
1,Engine类定义
用于反向传播计算图动态生成的Engine类的定义如下:
struct Engine {
using ready_queue_type = std::deque<std::pair<std::shared_ptr<Function>, InputBuffer>>;
using dependencies_type = std::unordered_map<Function*, int>;
virtual variable_list execute(const edge_list& roots,const variable_list& inputs,...const edge_list& outputs = {});
void queue_callback(std::function<void()> callback);
protected:
void compute_dependencies(Function* root, GraphTask& task);
void evaluate_function(FunctionTask& task);
void start_threads();
virtual void thread_init(int device);
virtual void thread_main(GraphTask *graph_task);
std::vector<std::shared_ptr<ReadyQueue>> ready_queues;
};
前向结束输出gemfieldout后,我们使用gemfieldout来作为反向传播的输入。
2,Engine类的start_threads成员
顾名思义,start_threads就是用来启动线程的,根据设备的数量来决定要启动的线程数量。这个函数使用std::call_once(start_threads_flag, &Engine::start_threads, this)的方式进行调用,确保了整个进程周期start_threads成员函数只被调用了一次。该成员函数的主要作用有2点:
1,创建多个ReadyQueue实例,使用ready_queues vector来管理。ReadyQueue的数量和即将要新创建的线程数量一样:
ready_queues = std::vector<std::shared_ptr<ReadyQueue>>(num_threads);
for (auto& queue : ready_queues){
queue.reset(new ReadyQueue());
}
2,创建多个新线程,线程的数量取决于设备的数量。CPU算一个设备,每张GPU卡算一个设备,然后最后再加1。比如该系统上有4个RTX 2080ti显卡,那么这里就会启动5个线程,如果系统上只有cpu而没有GPU,那么这里就会启动2个线程。
该成员函数使用std::thread来启动管理线程,比较重要的一点是,创建线程的时候传递的this指针:
for (int i = 0; i < num_threads; ++i) {
std::thread t(&Engine::thread_init, this, i - 1);
t.detach();
}
this就是当前Engine的实例,整个进程的生命周期内就只有这一个Engine实例。传递this带来的一个惊喜就是,当前进程和新启动的线程之间可以共享同一个Engine实例——不管是数据成员还是函数成员。后面你就会看到,我们的Queue就依靠this的共享来实现线程间的对象传输。
3,Engine类的ready_queues
ready_queues的定义如下:
std::vector<std::shared_ptr<ReadyQueue>> ready_queues;
可见ready_queues使用vector去管理了若干个ReadyQueue实例。这样我们就可以使用device index去vector里索引每个device专属的ReadyQueue了。
ReadyQueue用来传输的是FunctionTask对象(后文会介绍到),ReadyQueue定义如下所示:
struct ReadyQueue {
std::priority_queue<FunctionTask, std::vector<FunctionTask>, CompareFunctionTaskTime> heap;
std::condition_variable not_empty;
std::mutex mutex;
void push(FunctionTask item);
FunctionTask pop();
};
ReadyQueue使用priority_queue作为backend这一事实告诉了我们一点:消费的顺序并不等价于生产的顺序——根据CompareFunctionTaskTime的定义——谁的sequence_nr()越小就谁先消费。
ReadyQueue使用了C++11的condition_variable进行线程间的同步,使用condition_variable的notify_one来通知消费线程,相当于unblock其中一个消费线程(notify_all则是所有消费线程)。与此对应,消费线程则使用condition_variable的wait来接收同步信息。ReadyQueue类上定义了push和pop方法,分别代表生产者的生产行为和消费者的消费行为:
auto ReadyQueue::push(FunctionTask item) -> void {
{
std::lock_guard<std::mutex> lock(mutex);
++item.base->outstanding_tasks;
heap.push(std::move(item));
}
not_empty.notify_one();
}
auto ReadyQueue::pop() -> FunctionTask {
std::unique_lock<std::mutex> lock(mutex);
not_empty.wait(lock, [this]{ return !heap.empty(); });
auto task = std::move(const_cast<FunctionTask&>(heap.top()));
heap.pop();
return task;
}
//wait相当于下面,防止异常情况退出
while(heap.empty()){
not_empty.wait(lock);
}
4,Engine类的thread_init成员
thread_init会执行start_threads启动的线程的初始化工作。
auto Engine::thread_init(int device) -> void {
at::init_num_threads();
std::array<c10::OptionalDeviceGuard,static_cast<size_t>(c10::DeviceType::COMPILE_TIME_MAX_DEVICE_TYPES)> guards;
if (device != -1) {
for (size_t i = 0; i < static_cast<size_t>(c10::DeviceType::COMPILE_TIME_MAX_DEVICE_TYPES); i++) {
auto* impl = c10::impl::device_guard_impl_registry[i].load();
if (impl && device < impl->deviceCount()) {
guards[i].reset_device(at::Device(static_cast<c10::DeviceType>(i), device));
}
}
}
worker_device = device;
thread_main(nullptr);
}
设置每个线程自己的worker_device的值,值为device num-1,因此是从-1开始的。如果系统上只有1个cpu设备,那么start_threads会启动2个线程。那么这里的device号就分别是-1、0。另外,主进程里的worker_device的值为NO_DEVICE(-2)。初始化工作除了设置这个worker_device,主要是从第2个worker thread开始来设置guards中的divice。线程初始化完毕后,将会进行真正的线程执行逻辑调用。
5,Engine类中的GraphTask
Engine中使用的GraphTask:
struct GraphTask {
std::atomic<uint64_t> outstanding_tasks;
bool keep_graph;
bool grad_mode;
std::mutex mutex;
std::condition_variable not_done;
std::unordered_map<Function*, InputBuffer> not_ready;
std::unordered_map<Function*, int> dependencies;
struct ExecInfo {
bool needed = false;
};
std::unordered_map<Function*, ExecInfo> exec_info;
int owner;
GraphTask(bool keep_graph, bool grad_mode): has_error(false), \\
outstanding_tasks(0), keep_graph(keep_graph), grad_mode(grad_mode), owner(NO_DEVICE) {}
};
在Engine的execute函数执行中,我们会定义一个graph_task实例:
GraphTask graph_task(keep_graph, create_graph);
GraphTask的重要成员有:
成员1:outstanding_tasks,是个数字,当一个GraphTask实例创建出来的时候,outstanding_tasks被初始化为0;当其随后被送入ReadyQueue的时候,outstanding_tasks自增1;然后在worker线程每执行一次evaluate_function(task)后,outstanding_tasks的值减1。并且在主进程中,会有一个线程的同步逻辑依赖这个值:
while(graph_task.outstanding_tasks.load() != 0){
graph_task.not_done.wait(lock);
}
可见这个graph_task实例上的function没有被evaluate完成之前,主进程就一直在这里等待。
成员2:keep_graph,是个bool值,用来指定一次反向计算后是否释放资源。什么资源呢?前向过程中建立起来的资源。keep_graph如果是False的话,则会在fn执行完毕后调用release_variables:
if (!task.base->keep_graph) {
fn.release_variables();
}
我们在上文提到过,那几百个反向计算的Function里都有一个灵魂函数——apply,其实,还有一个回收资源的灵魂函数——release_variables。比如
struct MulBackward0 : public TraceableFunction {
void release_variables() override {
self_.reset_data();
self_.reset_grad_function();
other_.reset_data();
other_.reset_grad_function();
}
SavedVariable self_;
SavedVariable other_;
};
成员3:grad_mode,这是个bool值,用来指示当前的上下文是否是要计算grad。
bool GradMode::is_enabled() {
return GradMode_enabled;
}
void GradMode::set_enabled(bool enabled) {
GradMode_enabled = enabled;
}
整个反向计算期间执行的代码逻辑中,都是靠GradMode::is_enabled()来判断当前是否是要计算grad的。
成员4:mutex,类型为std::mutex。这是线程之间的同步原语,多个线程中只有一个可以持有同一个mutex,其它的线程只能在此等待。但是为了防止死锁等情况出现,我们借助RAII来智能管理mutex,典型的代表就是std::lock_guard和std::unique_lock。默认情况下用std::lock_guard,在一个函数执行完毕后(其实是一个block作用域),std::lock_guard的析构会自动释放这个mutex;不过,std::lock_guard只能靠构造函数和析构函数来获得和释放mutex,std::unique_lock则在此基础上更近一步,除了拥有上述功能之外,还可以通过std::unique_lock的lock和unlock来主动加锁和解锁,提供更精细粒度的控制——增加代码并行的区域。
成员5:not_done,std::condition_variable类型。线程间通信。还记得吧,在主进程中,我们将一个FunctionTask对象送往Queue后,主进程就开始等待:
while(graph_task.outstanding_tasks.load() != 0){
graph_task.not_done.wait(lock);
}
while循环就是防止异常退出的,核心是not_done这个condition。not_done.wait(lock)就是在这里阻塞——等待worker thread里的not_done.notify_all()。
成员6:not_ready,类型为std::unordered_map<Function*, InputBuffer>。用来暂存not ready的function及其输入。
**成员7:dependencies,**类型为std::unordered_map<Function*, int> 。
这个实例的dependencies成员在compute_dependencies调用中被初始化,只要一个grad_fn函数在别人的next_edges()中出现过一次,那么dependencies[this_grad_fn] 就自增1。
成员8:exec_info,类型为std::unordered_map<Function*, ExecInfo> 。如果exec_info这个map为空的话,说明这个task是默认的模式——所有我们在next_edges中遇到的函数都将被执行。如果exec_info不为空的话,只有含有entry的Function并且这个entry
has needed == True 的情况下才会被执行。
成员9:owner,int类型。GraphTask是在哪个线程中创建的,该值就是那个线程中的worker_device的值。
6,Engine类中的FunctionTask
Engine中使用的FunctionTask:
struct FunctionTask {
GraphTask* base;
std::shared_ptr<Function> fn;
InputBuffer inputs;
FunctionTask(GraphTask* base, std::shared_ptr<Function> fn, InputBuffer inputs): \\
base(base), fn(std::move(fn)), inputs(std::move(inputs)) {}
};
这个类的对象正是在queue中传输的东西,从上面的定义可以看到,我们使用GraphTask、Function、InputBuffer来构建一个FunctionTask实例。实际上,在主进程中,我们只需要将一个FunctionTask实例送入queue即可。这个FunctionTask正是由上述的GraphTask实例、graph_root、0构建的:
#主进程中
FunctionTask(&graph_task, std::move(graph_root), InputBuffer(0)
graph_root初始化很简单,由roots和inputs构建,roots就是将gemfieldout的gradient_edge()——也即grad_fn——也即MeanBackward0实例和output_nr_——也即(MeanBackward0实例,0);而inputs也即tensor(1.)。生产端往queue发送了FunctionTask实例后,在消费端的worker thread中,我们则通过task.base来访问到这个GraphTask实例、通过task.fn访问到这个roots实例、通过task.inputs来访问这个InputBuffer实例。
而在worker thread中,我们也可能使用如下的方式来构建新的FunctionTask实例,然后添加到queue中:
#work thread
FunctionTask(task.base, nullptr, InputBuffer(0)
#evaluate function
FunctionTask(task.base, next.function, std::move(input_buffer))
7,Engine类中的compute_dependencies
还记得5中定义的那个graph_task实例吗?还记得graph_task中有个成员是dependencies吗?还记得dependencies是std::unordered_map<Function*, int>吗?对,只要一个grad_fn函数在别人的next_edges()中出现过一次,那么dependencies[this_grad_fn] 就自增1。
对,这个函数就只干了这么一件事。
8,Engine类中的execute
这是Engine的灵魂函数,也是Engine的执行逻辑的主体,在一次反向中,该函数会被执行一次。该函数主要做了如下的工作:
1,调用Engine::start_threads,启动多个worker线程;注意,start_threads在整个进程周期只会被执行一次;
2,实例化一个graph_task的实例;
3,使用上述graph_task的mutex,初始化一个execute函数中局部的mutex;
4,构建GraphRoot;
5,执行compute_dependencies;
6,向队列中传输一个FunctionTask实例;
7,等待worker thread计算完毕后结束。
9,Engine类的thread_main成员
thread_main会作为start_threads启动的线程的执行实体:
auto Engine::thread_main(GraphTask *graph_task) -> void {
auto queue = ready_queues[worker_device + 1];
while (!graph_task || graph_task->outstanding_tasks > 0) {
FunctionTask task = queue->pop();
if (task.fn && !task.base->has_error.load()) {
GradMode::set_enabled(task.base->grad_mode);
evaluate_function(task);
}
auto base_owner = task.base->owner;
if (base_owner == NO_DEVICE) {
if (--task.base->outstanding_tasks == 0) {
std::lock_guard<std::mutex> lock(task.base->mutex);
task.base->not_done.notify_all();
}
} else {
if (base_owner == worker_device) {
--task.base->outstanding_tasks;
} else if (base_owner != worker_device) {
if (--task.base->outstanding_tasks == 0) {
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(base_owner).push(FunctionTask(task.base, nullptr, InputBuffer(0)));
}
}
}
}
}
主体就是一个while循环,不断的从专属queue中取出FunctionTask实例,然后执行evaluate_function——这是主体逻辑。evaluate_function完毕后,如果:
1,这个task是来自主进程的,并且task的outstanding_tasks已经降为0了(注意outstanding_tasks在evaluate_function中还会不断的被改变),那么就通知主进程上的wait同步原语,准备结束反向计算;
2,如果这个task是来自当前work thread,那么outstanding_tasks就自减1;
3,如果这个task是来自其它work thread,那么outstanding_tasks就自减1,并且如果降为0的话,则向那个worker thread的queue发送一个dummy function task。
10,Engine类的evaluate_function
这个函数的核心就是看一个函数在GraphTask的dependencies的计数是否降为0——也即是否ready(通常是因为有多个input),如果ready就送往queue去计算;如果没有就放入GraphTask的not_ready中,每次设置好对应的一个InputBuffer输入。送往Queue的task和之前GraphRoot不一样,因为它的owner不是主进程——是在worker thread中创建的。
1,一个node的input variable的device是多少,那么这个node组成的FunctionTask对象将被送往那个device对应的worker thread的queue;
2,准备一个node的时候,如果is_ready是True,说明这个node不会被未来的计算所依赖了,这个node组成的FunctionTask就会被送往上述的queue,并且信息会从Graph(GraphTask)中抹掉——从GraphTask的dependencies中移除;
3,准备一个node的时候,如果is_ready是False,这通常表明这个node有多个输入(被更多的node连接,使用num_inputs()可以获得数量),那么第一次遇到这个node的时候并不会把它送往queue,而是放入GraphTask的not_ready中,这个时候顺便设置好了该node的第一个输入:
input_buffer.add(next.input_nr, std::move(output))
not_ready.emplace(next.function.get(), std::move(input_buffer));
第二次遇到该node就设置该node的第二个input:
auto &input_buffer = not_ready_it->second;
input_buffer.add(next.input_nr, std::move(output));
以此类推,直到dependencies中对应的计数降为0——is_ready从False变为了True——这个node终于不会被未来的计算所依赖了。这个node组成的FunctionTask这个时候才会被送往上述的queue,并且信息会从Graph(GraphTask)中抹掉——从GraphTask的dependencies中移除、从GraphTask的not_ready中移除。
另外,input_buffer的构建也非常有趣,当向一个node添加一个输入的时候:
input_buffer.add(next.input_nr, std::move(output));
input_nr就清楚的表明,当前的node是反向传播中要流向的node的第几个输入!
11,Engine类的call_function
这个函数的逻辑就相对简单了,调用各个反向计算的函数及注册在上面的hooks。注意fn的输入和输出,像gemfield在《PyTorch的Tensor》中说的那样,输入是一组Variable的实例——InputBuffer::variables(std::move(task.inputs)),输出也是一组Variable的实例,毕竟输出要作为下一个fn的输入嘛。相关的代码如下所示:
static variable_list call_function(FunctionTask& task) {
auto& fn = *task.fn;
auto inputs = call_pre_hooks(fn, InputBuffer::variables(std::move(task.inputs)));
const auto has_post_hooks = !fn.post_hooks().empty();
variable_list outputs = fn(std::move(inputs));
if(has_post_hooks){
return call_post_hooks(fn, std::move(outputs), inputs);
}
return outputs;
}
1,调用注册在node上的pre_hooks;
2,调用node本身,比如MeanBackward0、MulBackward0等;
3,调用注册在node上的post hooks。
总结
本文中gemfield进一步介绍了PyTorch的动态图,主要是Engine这个class。现在你已经熟悉了,反向传播计算中,会根据设备数量启动多个线程,每个线程关联一个Queue,每个worker thread都有关联的device,主进程和worker thread、worker thread和work thread之间通过queue传送输入和计算结果,task根据input的device会被送入对应的Queue——如此以来计算就会在那个device关联的worker thread中进行。数据流经每个fn/node获得的输出再作为下一个fn/node的输入,这些输入输出都是一组Variable的实例。
以上是关于可能是最详尽的PyTorch动态图解析的主要内容,如果未能解决你的问题,请参考以下文章