(Java实习生)每日10道面试题打卡——Java基础知识篇2
Posted 兴趣使然的草帽路飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(Java实习生)每日10道面试题打卡——Java基础知识篇2相关的知识,希望对你有一定的参考价值。
- 临近秋招,备战暑期实习,祝大家每天进步亿点点!
- 本篇总结的是Java基础知识相关的面试题,后续会每日更新~

1、请你说一下Java中的IO流?以及他们的分类和作用?
IO 流的分类:
- 按照数据流的方向的不同,可以分为
输入流和输出流; - 按照处理数据单位的不同,可以划分为
字节流和字符流; - 按照流的实现功能的不同,可以划分为
节点流和处理流;
Java Io流共涉及40多个类,这40多个类都是从如下4个抽象类基类中派生出来的:
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
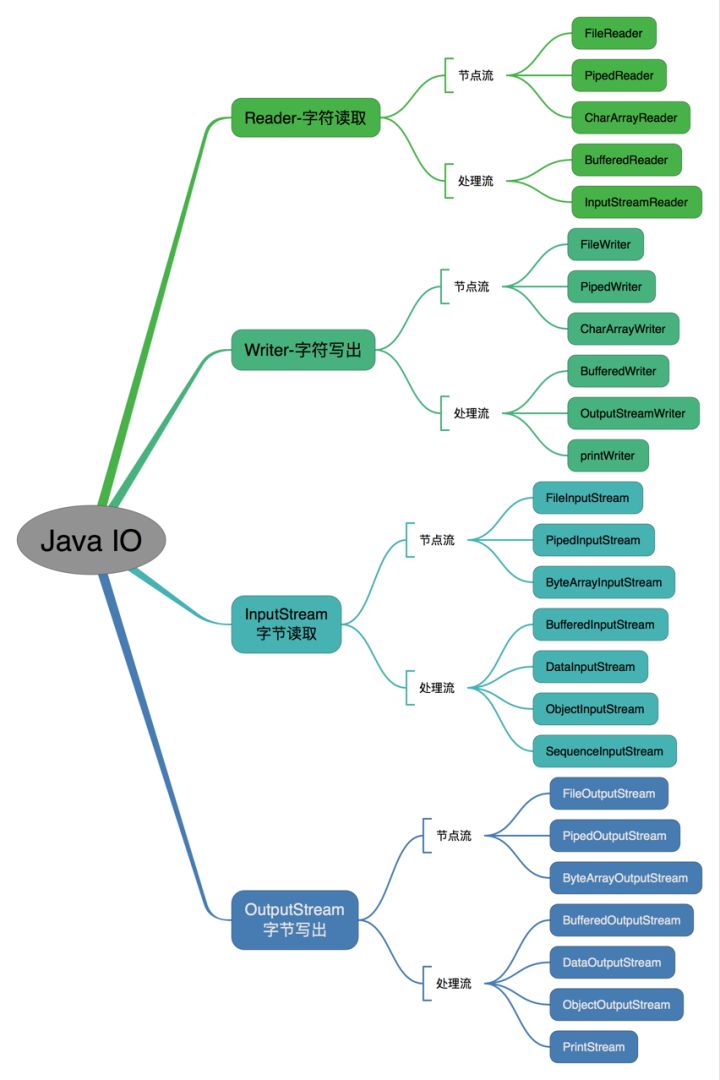
这里我们重点提一下 转换流和 缓冲流:
转换流:实现字节流和字符流之间的转换。
InputStreamReader:将一个字节输入流转换为字符输入流。OutputStreamWriter:将一个字符输出流转换为字节流。
缓冲流:增加缓冲功能,避免频繁读写硬盘。
如:BufferedInputStrean 、BufferedOutputStream、 BufferedReader、 BufferedWriter
我们来看一个转换流和缓冲流配合使用的案例:
// 获取键盘录入对象:
InputStream in = System.in;
// 将字节流对象转成字符流对象,使用转换流: InputStreamReader
InputStreamReader isr = new InputStreamReader(in);
// 为了提高效率,将字符串进行缓冲区技术高效操作,使用:BufferedReader
BufferedReader bufr = new BufferedReader(isr);
// 最常见写法:
// BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
// --------------------------------------------------------------------------------------
// 同理输出流转换亦是如此:
OutputStream out = System.out;
OutputStreamWriter osw = new OutputStreamWriter(out);
BufferedWriter bufw = new BufferedWriter(osw);
// 最常见写法:
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
流使用结束后记得关闭流,关闭的顺序遵循如下几个规则:
- ① 先开后关,先开的输入流,再开的输出流,通过读取输入流写入输出流中,那么应该先关输出流,再关输入流,但是一般关闭输入输出流操作都是在读写完成后的
finally中执行的,所以即使先关输入流,再关输出流也不会任何问题,因为读写操作没有进行了。 - ② 先关外层,再关内层。如
BufferedInputStream包装了一个FileInputStream,那么先关BufferedInputStream,再关FileInputStream。但要注意的是由于一般处理流持有节点流引用,处理流都会在自己的close方法中去关闭节点流,因此我们只要关闭外层的处理流即可,如果多此一举的关闭节点流反而会报错。如BufferedInputStream包装了FileInputStream,我们只要关闭BufferedInputStream即可。 - 只关处理流,不关节点流,原因见上述第二条。
2、请你说一说BIO、NIO、AIO 有什么区别?
在对比这三者的区别之前,先了解一下什么是同步/异步、阻塞/非阻塞:
- 同步,一个任务的完成之前不能做其他操作,必须等待(相当于在打电话)。
- 异步,一个任务的完成之前,可以进行其他操作(相当于在聊QQ)。
- 阻塞,是相对于CPU来说的, 挂起当前线程,不能做其他操作只能等待。
- 非阻塞,无须挂起当前线程,也可以去执行其他操作。
BIO、NIO、AIO的区别:
-
BIO:同步阻塞,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。每当有一个客户端向服务器发起请求时,服务器都要启动一个线程,如图所示:
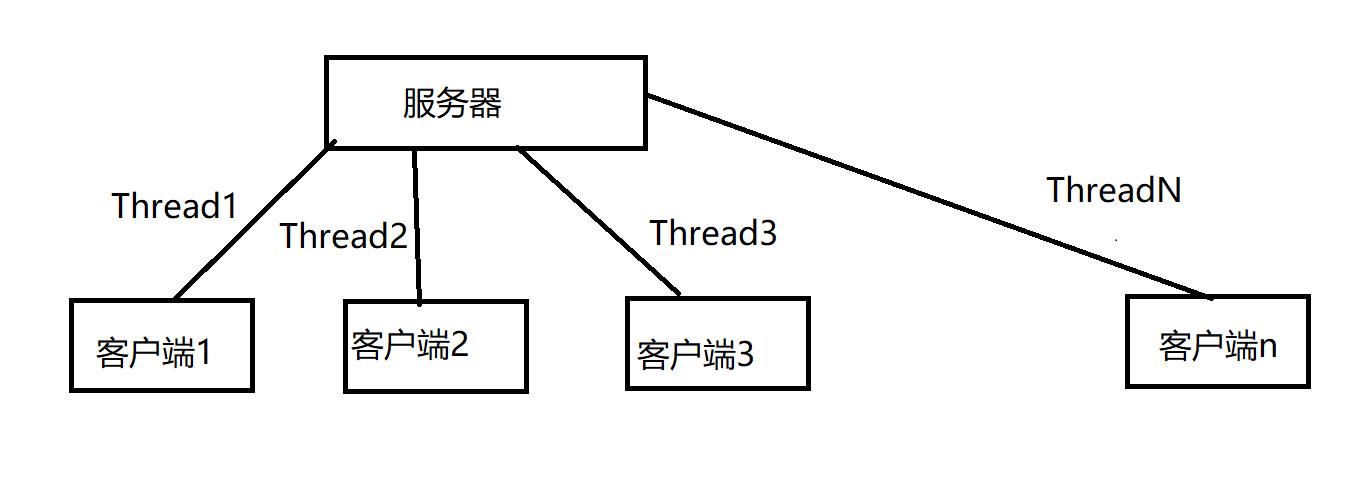
无论客户端是否响应,线程都必须一直等待。
-
NIO:同步非阻塞,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。服务器用一个线程来处理多个请求,客户端发送的请求会注册到多路复用器(selector选择器)上,有I/O请求的客户端分配线程处理,如图:
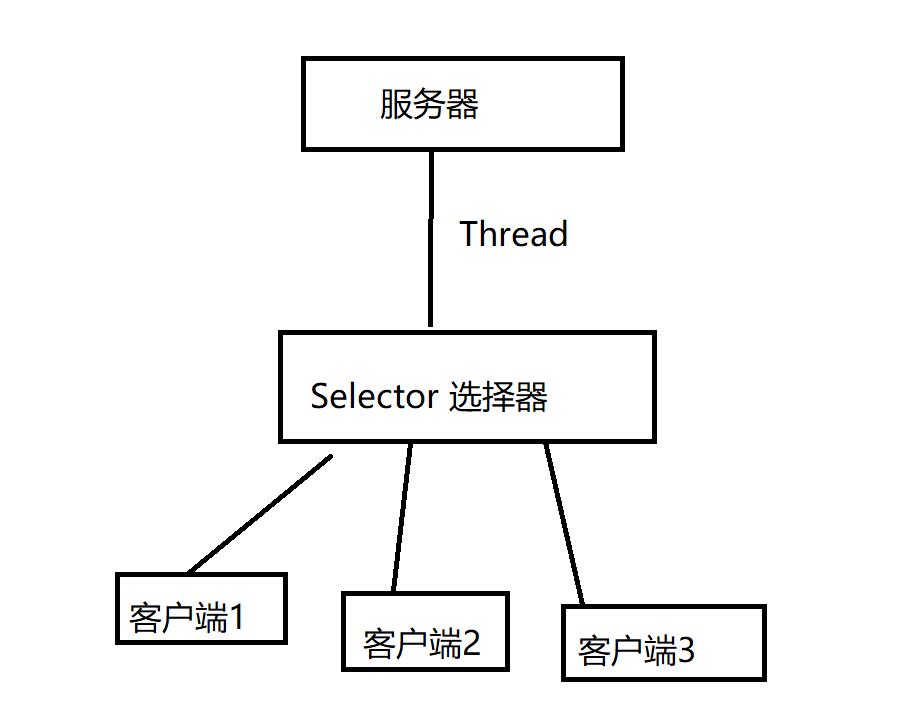
-
AIO:异步非阻塞,是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。客户端发送的请求先交给操作系统处理,OS 处理后再通知线程。
3、请你说一下Error 和 Exception 区别是什么?
Error 和 Exception 都是 Throwable 的子类,用于表示程序出现了不正常的情况。区别在于:
- Error 是程序错误,通常为虚拟机相关错误,如系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,JAVA 应用程序也不应对这类错误进行捕获,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复;
- Exception 是程序异常,是可以在应用程序中进行捕获并处理的,是一种设计或实现问题,也就是说,它表示如果程序运行正常,从不会发生的情况。
4、请问 try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
答案:会执行,在 return 前执行。
代码如下:
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
} finally {
a = 40;
// 结果直接返回40
return a;
}
}
总结:
- 不管有没有异常,
finally中的代码都会执行。 - 当
try、catch中有return时,finally中的代码依然会继续执行。 - 如果
return的数据是引用数据类型,而在finally中对该引用数据类型的属性值的改变起作用,try中的return语句返回的就是在finally中改变后的该属性的值。 finally代码中最好不要包含return,程序会提前退出,也就是说返回的值不是try或catch中的值。finally是在return后面的表达式运算之后执行的,此时并没有返回运算之后的值,而是把值保存起来,不管finally对该值做任何的改变,返回的值都不会改变,依然返回保存起来的值。也就是说方法的返回值是在finally运算之前就确定了的。
5、6、7问参考文章:Java中的128陷阱和new String(“xxx“)创建了几个对象问题
5、请你说一下:String str = new String(“abc”) 创建了几个字符串对象?
答案:1 个或者 2 个。
Ⅰ如果字符串常量池中已经有"abc"存在,这种情况只需要新建1个对象,否则就需要新建2个对象。Ⅱ当字符串常量池没有"abc",此时会创建如下两个对象:- 一个是字符串字变量
"abc"所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,此时该实例也是在堆中,字符串常量池只存放引用。 - 另一个是通过
new String()创建并初始化的,内容与"abc"相同的实例,也是在堆中。
- 一个是字符串字变量
总结: new String("xxx"); 如果字符串常量池intern中没有对应的xxx 那么就需要在字符串常量池新建,然后再在堆上new 一个对象。
6、请问 String str = “xyz” 和 String str = new String(“xyz”) 区别?
- 两个语句都会先去字符串常量池中检查是否已经存在 “xyz”,如果有则直接使用,如果没有则会在常量池中创建 “xyz” 对象。
- 另外,String s = new String(“xyz”) 还会通过 new String() 在堆里创建一个内容与 “xyz” 相同的对象实例。所以前者其实理解为被后者的所包含。
7、Java中的128陷阱有了解过吗?
先来看一个例子:
public static void main(String[] args) {
Integer a=127,b=127;
Integer c=128,d=128;
System.out.println(a==b);// true
System.out.println(c==d);// false
}
为什么出现这种情况呢?
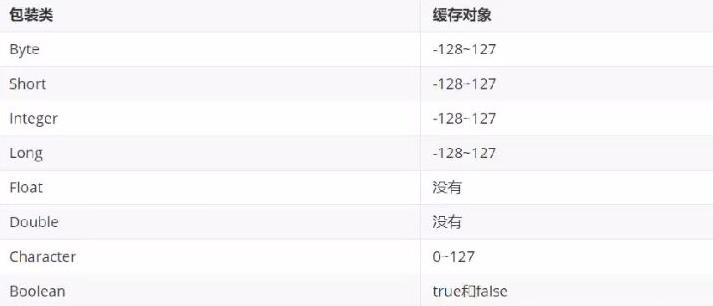
- 我们都知道
Integer是 基本类型int的包装类型。 - 在Java设计之初,设计者认为,开发者可能经常用到的数字范围都在 100 以内,而每次使用这些数字的包装类型都要开辟新空间的话,可能会占用大量的资源。
- 因此他们规定在
-128~127之间的Integer类型的变量,直接指向常量池中的缓存地址,不再使用new去开辟出新的空间。
执行 Integer c = 128,相当于执行:Integer c = Integer.valueOf(128),基本类型自动转换为包装类的过程称为,自动装箱(autoboxing)。
这也是出现上述代码两次比较结果不同的原因!下面我们看下valueOf() 源码去体会下:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
在Integer 中引入了IntegerCache 来缓存一定范围的值,默认情况下范围为:-128~127。
因此:上述代码中的 127 命中了 IntegerCache,所以 a 和 b 是相同对象,而 128 则没有命中,所以 c 和 d 是不同对象。
那么,如果想要正确比较的话 c 与 d 的话,就需要拆箱比较,即在变量后加intValue()方法:
public static void main(String[] args) {
Integer a=127,b=127;
Integer c=128,d=128;
System.out.println(a==b);// true
System.out.println(c.intValue()==d.intValue());// true
}
可以直接记住下面的表格,道理都是一样的:
8、Java中的深拷贝和浅拷贝有了解过吗?
深拷贝和浅拷贝区别是什么?
- 数据分为基本数据类型和引用数据类型。基本数据类型:数据直接存储在栈中;引用数据类型:存储在栈中的是对象的引用地址,真实的对象数据存放在堆内存里。
- 浅拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:只是复制了对象的引用地址,新旧对象指向同一个内存地址,修改其中一个对象的值,另一个对象的值随之改变。
- 深拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:开辟新的内存空间,在新的内存空间里复制一个一模一样的对象,新老对象不共享内存,修改其中一个对象的值,不会影响另一个对象。
- 深拷贝相比于浅拷贝速度较慢并且花销较大。
深拷贝/浅拷贝分析案例
- 浅拷贝实现 Cloneable,深拷贝是通过实现 Serializable 读取二进制流
深拷贝实现:
首先Person 对象实现 Serializable 接口,然后自定义深拷贝方法 deepClone():
/**
* 深拷贝
*
* 注意:要实现序列化接口
* @return
*/
public Person deepClone() {
try {
// 输出 (序列化)
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
// 输入 (反序列化)
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
Person person = (Person) ois.readObject();
return person;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
接下来验证一下深拷贝是否成功:
@Test
public void testPropotype() throws CloneNotSupportedException {
Person person1 = new Person();
person1.setAge(22);
person1.setName("csp");
// 初始化list 并为其加入数据
person1.setList(new ArrayList<>());
person1.getList().add("aaa");
person1.getList().add("bbb");
System.out.println("person1:"+person1);
//-----------------------------浅拷贝-------------------------------
//Person person2 = person1.clone();
//-----------------------------深拷贝-------------------------------
Person person2 = person1.deepClone();
person2.setName("hzw");
// 给peron2 中的list添加一条数据
person2.getList().add("ccc");
System.out.println("person2"+person2);
System.out.println("person1:"+person1);
boolean flag1 = person1 == person2;
System.out.println("person1 和 person2 的 引用地址是否相同: " + flag1);
boolean flag2 = person1.getList() == person2.getList();
System.out.println("person1 和 person2 的 list 引用地址是否相同: " + flag2);
}
输出结果:
空参构造函数调用...
person1:Person{name='csp', age=22, list=[aaa, bbb]}
person2Person{name='hzw', age=22, list=[aaa, bbb, ccc]}
person1:Person{name='csp', age=22, list=[aaa, bbb]}
person1 和 person2 的 引用地址是否相同: false
person1 和 person2 的 list 引用地址是否相同: false
由结果可得出:深拷贝 person2 所得到的 list 内存地址和原来person1 中的内存地址是不同的,深拷贝成功!
9、Java中子父类继承情况下构造函数/代码块/静态代码块执行顺序你知道吗?
实例来源:《Java编程思想》,博客链接:Java编程思想1-15章笔记
案例代码:
class A{
public A()
{
System.out.println("1.父类A的构造方法");
}
{
System.out.println("2.父类A的构造代码块");
}
static{
System.out.println("3.父类A的静态代码块");
}
}
public class B extends A{
public B()
{
System.out.println("4.子类B的构造方法");
}
{
System.out.println("5.子类B的构造代码块");
}
static{
System.out.println("6.子类B的静态代码块");
}
//测试
public static void main(String[] args)
{
System.out.println("7.start......");
new B();
System.out.println("8.end.....");
}
}
输出结果:
>>> 3.父类A的静态代码块
>>> 6.子类B的静态代码块
>>> 7.start......
>>> 2.父类A的构造代码块
>>> 1.父类A的构造方法
>>> 5.子类B的构造代码块
>>> 4.子类B的构造方法
>>> 8.end.....
-
主类B中的静态块优先于主方法执行,所以6应该在7前面执行,且B类继承于A类,所以先执行A类的静态块3,所以进入主方法前的执行顺序为:3 6
-
进入主方法后执行7,
new B()之后应先执行A的构造方法然后执行B的构造方法,但由于A类和B类均有构造代码块块,构造代码块又优先于构造方法执行即 2 1(A的构造家族) 5 4(B的构造家族),有多少个对象,构造家族就执行几次,题目中有两个对象 所以执行顺序为:3 6 7 2 1 5 4 2 1 5 4 8
这里有个更具体的案例:一道有意思的“初始化”面试题
10、Java中静态变量/成员变量、静态内部类/成员内部类的区别你知道吗?
静态内部类和内部类的关系
- 只有内部类才能被声明为静态类,即静态内部类;
- 只能在内部类中定义静态类;
- 静态内部类与外层类绑定,即使没有创建外层类的对象,它一样存在;
- 静态类的方法可以是静态的方法也可以是非静态的方法,静态的方法可以在外层通过静态类调用,而非静态的方法必须要创建类的对象之后才能调用;
- 静态内部类只能引用外部类的static成员变量(也就是类变量)
- 如果一个内部类不是被定义成静态内部类,那么在定义成员变量或者成员方法的时候,是不能够被定义成静态的;
总结:
- 是否能拥有静态成员:静态内部类可以有静态成员(方法,属性),而非静态内部类则不能有静态成员(方法,属性)
- 访问外部类的成员是否有限制:静态内部类只能够访问外部类的静态成员,而非静态内部类则可以访问外部类的所有成员(方法,属性)
- 静态内部类和非静态内部类在创建时有区别:
// 假设类A有静态内部类B和非静态内部类C,创建B和C的区别为:
A a=new A();
A.B b=new A.B();
A.C c=a.new C();
静态变量/成员变量
- 成员变量存在于堆内存中。
- 静态变量存在于方法区中。
- 成员变量与对象共存亡,随着对象创建而存在,随着对象被回收而释放。
- 静态变量与类共存亡,随着类的加载而存在,随着类的消失而消失。
- 成员变量所属于对象,所以也称为实例变量。
- 静态变量所属于类,所以也称为类变量。
- 成员变量只能被对象所调用 。
- 静态变量可以被对象调用,也可以被类名调用。
总结的面试题也挺费时间的,文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,还请三连支持一下,后续会亿点点的更新!

为了帮助更多小白从零进阶 Java 工程师,从CSDN官方那边搞来了一套 《Java 工程师学习成长知识图谱》,尺寸 870mm x 560mm,展开后有一张办公桌大小,也可以折叠成一本书的尺寸,有兴趣的小伙伴可以了解一下,当然,不管怎样博主的文章一直都是免费的~

以上是关于(Java实习生)每日10道面试题打卡——Java基础知识篇2的主要内容,如果未能解决你的问题,请参考以下文章
(Java实习生)每日10道面试题打卡——Java简单集合篇