老板又出难题,气得我写了个自动化软件
Posted 大数据v
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了老板又出难题,气得我写了个自动化软件相关的知识,希望对你有一定的参考价值。

导读:办公神器.exe
作者:小小明,编辑:朱小五
来源:凹凸数据(ID:alltodata)
日常工作中,领导要求你将一份 Word 文档中的图片存储到一个文件夹内,你可能会一边内心崩溃,一边开始一张张的 另存为。
但假如领导要求你将几百个word文档中的图片全部都拷贝出来,你是不是打算离职不干了?
就比如下面这些word文档中的图片,你能否快速的把所有图片都拷贝出来呢?
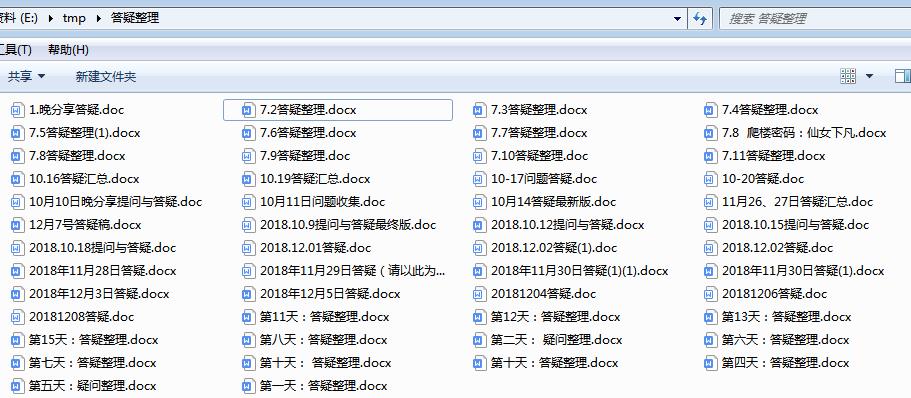
如果老朋友们看过这篇文章《老板让我从Word中复制出1000张图片?》的话,就应该知道怎么做了。
不过,上次分享的这种方法还是有缺陷的:把word文档用压缩文件打开,逐个解压的话依然会耗时较长时间,另外里面掺杂了doc格式的word文档,你还需将这些03版本的word文档另存为docx格式。
今天,将给大家展示一下全新版本!!!
写个程序,十秒内全部给你转换完毕,并把图片都提取出来,还能批量从真实修改图片格式,而不是简单的修改一下扩展名。
下面开始展示(文末附带exe可执行程序)

01 doc格式批量转为docx
python提供了win32com模块,其中的SaveAs方法可以代替人手批量将文件另存为我们需要的格式。
win32com包含在pypiwin32模块中,只需安装pypiwin32模块即可:
pip install pypiwin32下面的代码将指定目录下的doc文件转换为docx格式,并放在该目录的temp_dir下面:
from win32com import client as wc # 导入模块
from pathlib import Path
import os
import shutil
doc_path = r"E:\\tmp\\答疑整理"
temp_dir = "temp"
if os.path.exists(f"{doc_path}/{temp_dir}"):
shutil.rmtree(f"{doc_path}/{temp_dir}")
os.mkdir(f"{doc_path}/{temp_dir}")
word = wc.Dispatch("Word.Application") # 打开word应用程序
try:
for filename in Path(doc_path).glob("*.doc"):
file = str(filename)
dest_name = str(filename.parent/f"{temp_dir}"/str(filename.name))+"x"
print(file, dest_name)
doc = word.Documents.Open(file) # 打开word文件
doc.SaveAs(dest_name, 12) # 另存为后缀为".docx"的文件,其中参数12指docx文件
finally:
word.Quit()
运行结果:
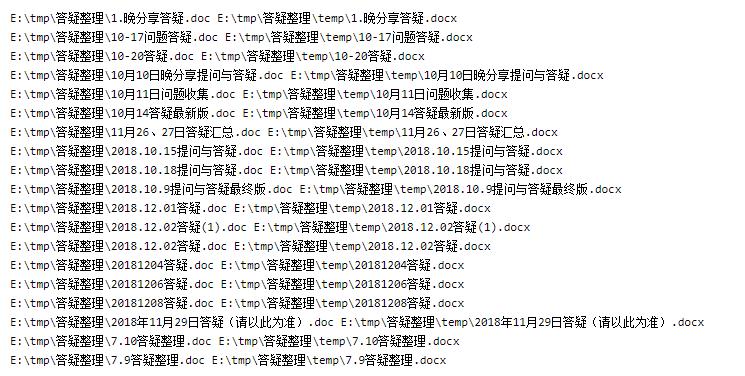
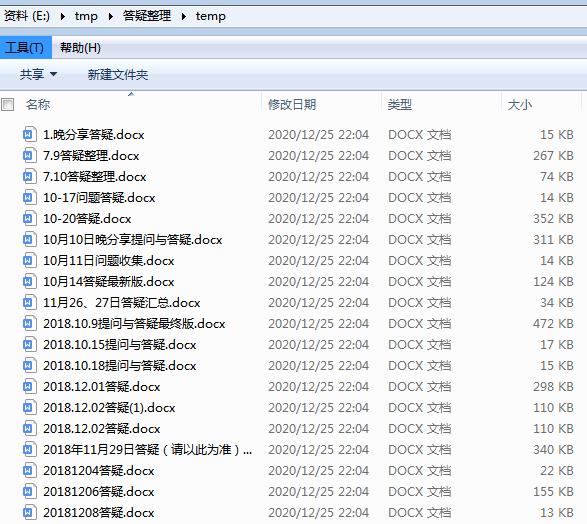
转换得到的文件:
02 批量提取docx文档的图片
docx文档其实也是一个zip压缩包,所以我们可以通过zip包解压它,下面的代码将解压每个docx文档中的图片,我将其移动到临时目录下的imgs目录下:
import itertools
from zipfile import ZipFile
import shutil
if os.path.exists(f"{doc_path}/{temp_dir}/imgs"):
shutil.rmtree(f"{doc_path}/{temp_dir}/imgs")
os.makedirs(f"{doc_path}/{temp_dir}/imgs")
i = 1
for filename in itertools.chain(Path(doc_path).glob("*.docx"), (Path(doc_path)/temp_dir).glob("*.docx")):
print(filename)
with ZipFile(filename) as zip_file:
for names in zip_file.namelist():
if names.startswith("word/media/image"):
zip_file.extract(names, doc_path)
os.rename(f"{doc_path}/{names}",
f"{doc_path}/{temp_dir}/imgs/{i}{names[names.find('.'):]}")
print("\\t", names, f"{i}{names[names.find('.'):]}")
i += 1
shutil.rmtree(f"{doc_path}/word")
打印结果:
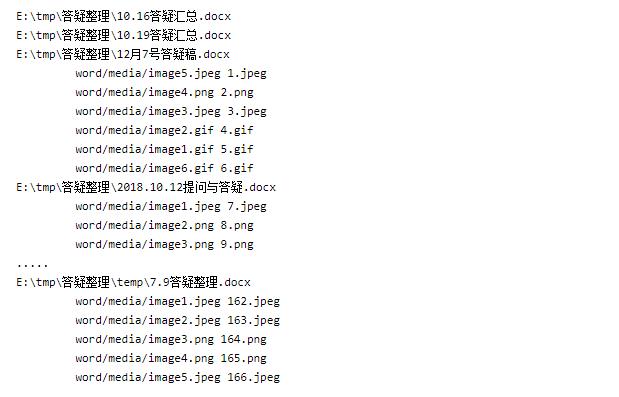
提取结果:
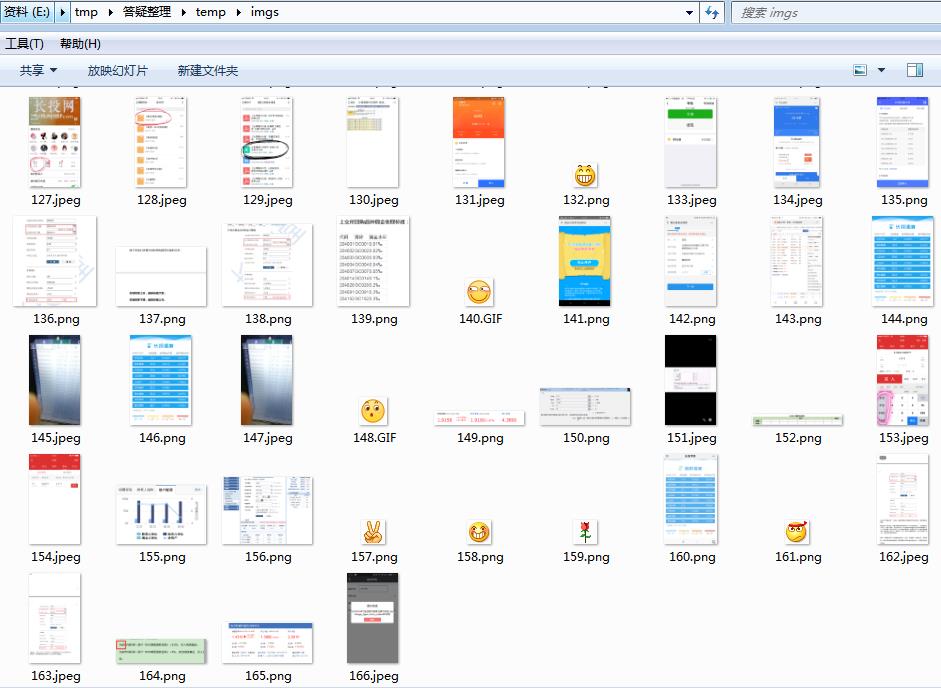
03 批量图片格式转换
PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。
由于PIL仅支持到Python 2.7,加上年久失修,于是一群志愿者在PIL的基础上创建了兼容的版本,名字叫Pillow,支持最新Python 3.x,又加入了许多新特性,因此,我们可以直接安装使用Pillow。
如果安装了Anaconda,Pillow就已经可用了。否则,需要在命令行下通过pip安装:
pip install pillow直接修改文件扩展名并不能真实的修改图片格式,通过pillow库我们即可将图片批量真实的转换为jpg格式:
from PIL import Image
if not os.path.exists(f"{doc_path}/imgs"):
os.mkdir(f"{doc_path}/imgs")
for filename in Path(f"{doc_path}/{temp_dir}/imgs").glob("*"):
file = str(filename)
with Image.open(file) as im:
im.convert('RGB').save(
f"{doc_path}/imgs/{filename.name[:filename.name.find('.')]}.jpg", 'jpeg')转换后:
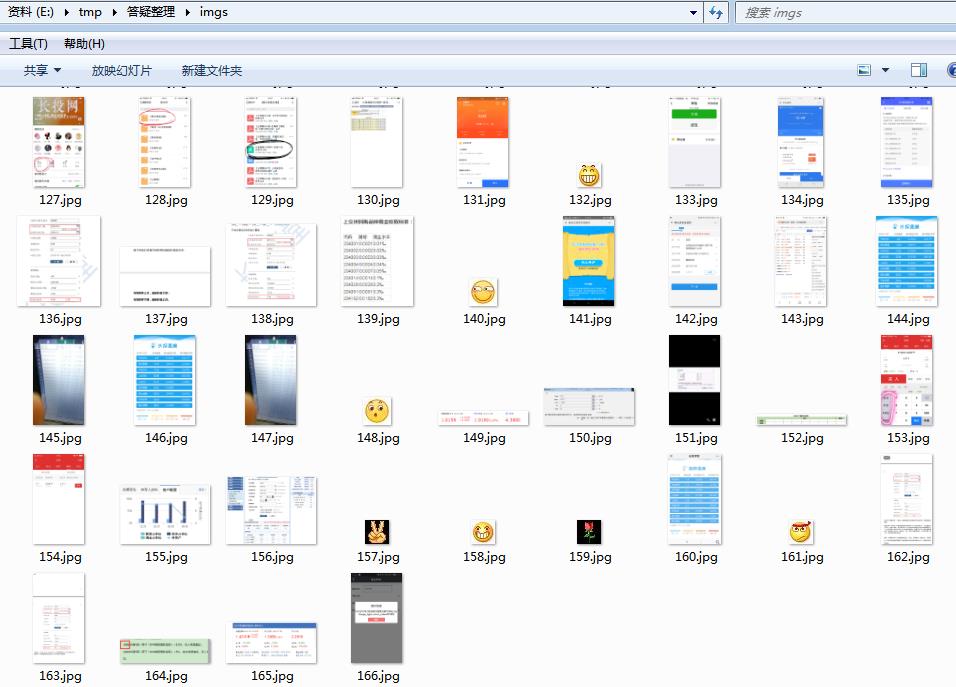
04 完整代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 创建时间:2020/12/25 21:46
__author__ = 'xiaoxiaoming'
import itertools
import os
import shutil
from pathlib import Path
from zipfile import ZipFile
from PIL import Image
from win32com import client as wc # 导入模块
def word_img_extract(doc_path, temp_dir):
if os.path.exists(f"{doc_path}/{temp_dir}"):
shutil.rmtree(f"{doc_path}/{temp_dir}")
os.mkdir(f"{doc_path}/{temp_dir}")
word = wc.Dispatch("Word.Application") # 打开word应用程序
try:
for filename in Path(doc_path).glob("*.doc"):
file = str(filename)
dest_name = str(filename.parent / f"{temp_dir}" / str(filename.name)) + "x"
print(file, dest_name)
doc = word.Documents.Open(file) # 打开word文件
doc.SaveAs(dest_name, 12) # 另存为后缀为".docx"的文件,其中参数12指docx文件
finally:
word.Quit()
if os.path.exists(f"{doc_path}/{temp_dir}/imgs"):
shutil.rmtree(f"{doc_path}/{temp_dir}/imgs")
os.makedirs(f"{doc_path}/{temp_dir}/imgs")
i = 1
for filename in itertools.chain(Path(doc_path).glob("*.docx"), (Path(doc_path) / temp_dir).glob("*.docx")):
print(filename)
with ZipFile(filename) as zip_file:
for names in zip_file.namelist():
if names.startswith("word/media/image"):
zip_file.extract(names, doc_path)
os.rename(f"{doc_path}/{names}",
f"{doc_path}/{temp_dir}/imgs/{i}{names[names.find('.'):]}")
print("\\t", names, f"{i}{names[names.find('.'):]}")
i += 1
shutil.rmtree(f"{doc_path}/word")
if not os.path.exists(f"{doc_path}/imgs"):
os.mkdir(f"{doc_path}/imgs")
for filename in Path(f"{doc_path}/{temp_dir}/imgs").glob("*"):
file = str(filename)
with Image.open(file) as im:
im.convert('RGB').save(
f"{doc_path}/imgs/{filename.name[:filename.name.find('.')]}.jpg", 'jpeg')
if __name__ == '__main__':
doc_path = r"E:\\tmp\\答疑整理"
temp_dir = "temp"
word_img_extract(doc_path, temp_dir)最终全部执行完成耗时7s:
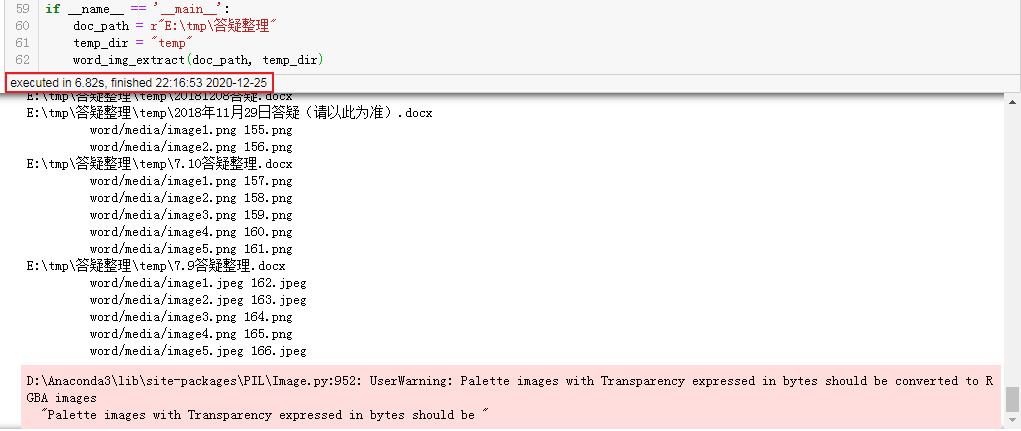
05 GUI图形化工具开发
下面使用PySimpleGUI开发一个图形化工具,使用以下命令安装该库:
pip install PySimpleGUI如果是下载速度慢的可以用下面的清华镜像地址下载:
pip install PySimpleGUI -i https://pypi.tuna.tsinghua.edu.cn/simple以下是完整代码:
import PySimpleGUI as sg
from word_img_extract import word_img_extract
sg.change_look_and_feel("GreenMono")
layout = [
[
sg.Text("请输入word文档所在的目录:"),
sg.In(size=(25, 1), enable_events=True, key="-FOLDER-"),
sg.FolderBrowse('浏览'),
], [
sg.Button('开始抽取', enable_events=True, key="抽取"),
sg.Text(size=(40, 1), key="-TOUT-")
]
]
window = sg.Window('word文档图片抽取系统', layout)
while True:
event, values = window.read()
if event in (None,):
break # 相当于关闭界面
elif event == "抽取":
if values["-FOLDER-"]:
window["-TOUT-"].update("准备抽取!!!")
sg.popup('抽取期间程序将处于假死状态,请稍等片刻,提取完成后会弹出提示!!!\\n点击ok后开始抽取!!!')
window["-TOUT-"].update("正在抽取中...")
word_img_extract(values["-FOLDER-"])
window["-TOUT-"].update("抽取完毕!!!")
sg.popup('抽取完毕!!!')
else:
sg.popup('请先输入word文档所在的路径!!!')
print(f'Event: {event}, values: {values}')
window.close()运行效果:

06 打包exe
创建并激活虚拟环境:
conda create -n gui python=3.6
conda activate gui注意:创建虚拟环境和激活环境并不是必须,只是为了精简环境,可以跳过
安装打包所用的包:
pip install PySimpleGUI
pip install pillow
pip install pywin32
pip install pyinstaller
执行以下命令进行打包:
pyinstaller -F --icon=C:\\Users\\Think\\Pictures\\ico\\ooopic_1467046829.ico word_img_extract_GUI.py常用参数说明:
-F 表示生成单个可执行文件
-w 表示去掉控制台窗口,这在GUI界面时非常有用。不过如果是命令行程序的话那就把这个选项删除吧!
-p 表示你自己自定义需要加载的类路径,一般情况下用不到
-i 表示可执行文件的图标
打包结果:
带上-w参数打包,可以去掉控制台:
pyinstaller -wF --icon=C:\\Users\\Think\\Pictures\\ico\\ooopic_1467046829.ico word_img_extract_GUI.py07 给GUI加入进度条
改造处理程序,借助生成器反馈程序的处理进度,完整代码如下:
import itertools
import os
import shutil
from pathlib import Path
from zipfile import ZipFile
from PIL import Image
from win32com import client as wc # 导入模块
def word_img_extract(doc_path, temp_dir="temp"):
if os.path.exists(f"{doc_path}/{temp_dir}"):
shutil.rmtree(f"{doc_path}/{temp_dir}")
os.mkdir(f"{doc_path}/{temp_dir}")
word = wc.Dispatch("Word.Application") # 打开word应用程序
try:
files = list(Path(doc_path).glob("*.doc"))
if len(files) == 0:
raise Exception("当前目录中没有word文档")
for i, filename in enumerate(files, 1):
file = str(filename)
dest_name = str(filename.parent / f"{temp_dir}" / str(filename.name)) + "x"
# print(file, dest_name)
doc = word.Documents.Open(file) # 打开word文件
doc.SaveAs(dest_name, 12) # 另存为后缀为".docx"的文件,其中参数12指docx文件
yield "word doc格式转docx格式:", i * 1000 // len(files)
finally:
word.Quit()
if os.path.exists(f"{doc_path}/{temp_dir}/imgs"):
shutil.rmtree(f"{doc_path}/{temp_dir}/imgs")
os.makedirs(f"{doc_path}/{temp_dir}/imgs")
i = 1
files = list(itertools.chain(Path(doc_path).glob("*.docx"), (Path(doc_path) / temp_dir).glob("*.docx")))
for j, filename in enumerate(files, 1):
# print(filename)
with ZipFile(filename) as zip_file:
for names in zip_file.namelist():
if names.startswith("word/media/image"):
zip_file.extract(names, doc_path)
os.rename(f"{doc_path}/{names}",
f"{doc_path}/{temp_dir}/imgs/{i}{names[names.find('.'):]}")
# print("\\t", names, f"{i}{names[names.find('.'):]}")
i += 1
yield "word提取图片:", j * 1000 // len(files)
shutil.rmtree(f"{doc_path}/word")
if not os.path.exists(f"{doc_path}/imgs"):
os.mkdir(f"{doc_path}/imgs")
files = list(Path(f"{doc_path}/{temp_dir}/imgs").glob("*"))
for i, filename in enumerate(files, 1):
file = str(filename)
with Image.open(file) as im:
im.convert('RGB').save(
f"{doc_path}/imgs/{filename.name[:filename.name.find('.')]}.jpg", 'jpeg')
yield "图片转换为jpg格式:", i * 1000 // len(files)
if __name__ == '__main__':
doc_path = r"E:\\tmp\\答疑整理"
for msg, i in word_img_extract(doc_path):
print(f"\\r {msg}{i}", end="")GUI程序的最终完整代码:
import PySimpleGUI as sg
from word_img_extract import word_img_extract
sg.change_look_and_feel("GreenMono")
layout = [
[
sg.Text("请输入word文档所在的目录:"),
sg.In(size=(25, 1), enable_events=True, key="-FOLDER-"),
sg.FolderBrowse('浏览'),
], [
sg.Button('开始抽取', enable_events=True, key="抽取"),
sg.Text(text_color="red", size=(47, 2), key="error"),
], [
sg.Text("准备:", size=(20, 1), key="-TOUT-"),
sg.ProgressBar(1000, orientation='h', size=(35, 20), key='progressbar')
]
]
window = sg.Window('word文档图片抽取系统', layout)
while True:
event, values = window.read()
if event in (None,):
break # 相当于关闭界面
elif event == "抽取":
if values["-FOLDER-"]:
window["error"].update("")
try:
for msg, i in word_img_extract(values["-FOLDER-"]):
window["-TOUT-"].update(msg)
window['progressbar'].UpdateBar(i)
window["-TOUT-"].update('抽取完毕!!!')
except Exception as e:
window["error"].update(str(e))
else:
sg.popup('请先输入word文档所在的路径!!!')
window.close()
重新打包:
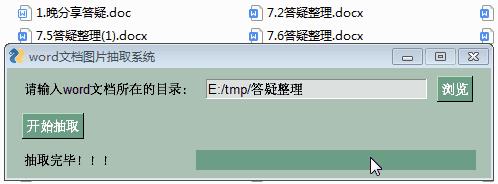
pyinstaller -wF --icon=C:\\Users\\Think\\Pictures\\ico\\ooopic_1467046829.ico word_img_extract_GUI.py运行效果:
08 exe下载
打包好的exe软件:
链接:
https://pan.baidu.com/s/11c1WSG1b8_AQdBNKxYcN0w
提取码:kxpy
关于作者:小小明,Pandas数据处理专家,致力于帮助无数数据从业者解决数据处理难题

延伸阅读????

《利用Python进行数据分析》(原书第2版)
推荐语:Python数据分析经典畅销书全新升级,第1版中文版累计销售100000册。针对Python 3.6进行全面修订和更新,涵盖新版的pandas、NumPy、IPython和Jupyter。
干货直达????
更多精彩????
在公众号对话框输入以下关键词
查看更多优质内容!
PPT | 读书 | 书单 | 硬核 | 干货 | 讲明白 | 神操作
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 1024 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
????
以上是关于老板又出难题,气得我写了个自动化软件的主要内容,如果未能解决你的问题,请参考以下文章
我写了个下载程序,用Java写的,但是写完以后发现下载大文件的时候报错,内存溢出,能看看是哪的问题么?