Python爬虫实战爬取2021中国大学排名(简单)
Posted 桃陉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战爬取2021中国大学排名(简单)相关的知识,希望对你有一定的参考价值。
一.准备工作
引入如下库:
import requests
from bs4 import BeautifulSoup
import bs4
二.进行分析
根据网址http://www.gaosan.com/gaokao/241219.html我们找到对应网页,按F12打开开发者界面。
点击左上角图标:
然后就可以查找指定内容,我们随便点击一个大学,可以看到对应的HTML内容:
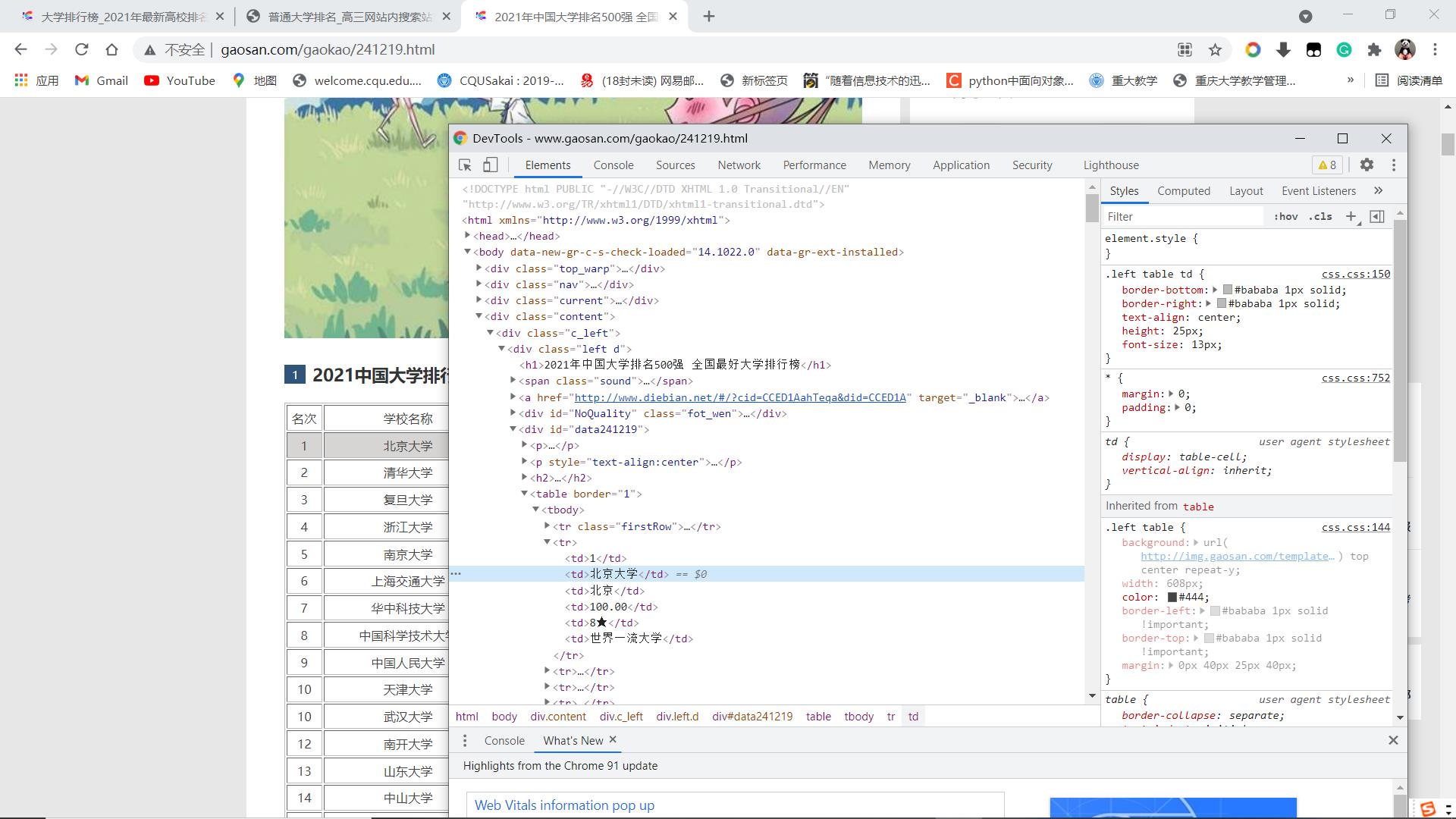
我们发现所有信息都被写在tbody标签下的tr中,每个tr表示一个学校,tr下的每一个td表示一个具体信息。注意第一个tr中的信息表示表格索引头,这样我们就可以进行爬虫了。
三.完整代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败!"
def fillUlist(ulist,html):
soup = BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string,tds[4].string,tds[5].string])
def printUlist(ulist,num):
for i in range(num):
u=ulist[i]
print("{:^10}\\t{:^20}\\t{:^10}\\t{:^10}\\t{:^10}\\t{:^10}".format(u[0],u[1],u[2],u[3],u[4],u[5],chr(12288)))
if __name__=="__main__":
ulist=[]
url = "http://www.gaosan.com/gaokao/241219.html"
html = getHtmlText(url)
fillUlist(ulist,html)
printUlist(ulist,500)
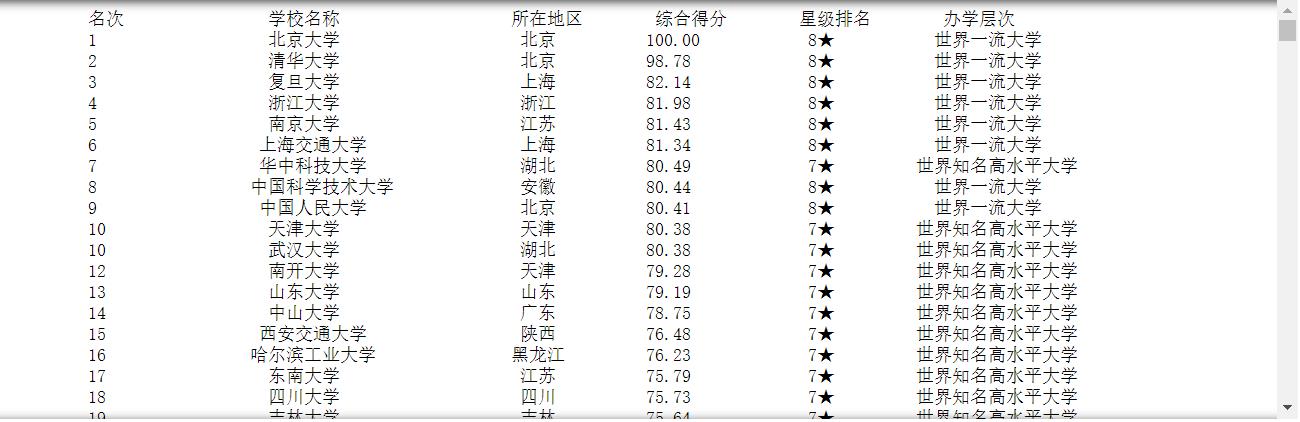
得到结果:
以上是关于Python爬虫实战爬取2021中国大学排名(简单)的主要内容,如果未能解决你的问题,请参考以下文章