GFS分布式文件系统(相关理论及实验操作详解)
Posted 噫噫噫呀呀呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GFS分布式文件系统(相关理论及实验操作详解)相关的知识,希望对你有一定的参考价值。
目录
一、GlusterFS简介
GlusterFS 是一个开源的分布式文件系统。
由存储服务器、客户端以及NFS/Samba存储网关(可选,根据需要选择使用)组成。
没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。
传统的分布式文件系统大多通过元服务器来存储元数据,元数据包含存储节点上的目录信息、目录结构等。这样的设计在浏览目录时效率高,但是也存在一些缺陷,例如单点故障。一旦元数据服务器出现故障,即使节点具备再高的冗余性,整个存储系统也将崩溃。而GlusterFS 分布式文件系统是基于无元服务器的设计,数据横向扩展能力强,具备较高的可靠性及存储效率。
GlusterFs同时也是Scale-Out(横向扩展)存储解决方案Gluster的核心,在存储数据方面具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。
GlusterFS支持借助TCP/IP或InfiniBandRDMA网络 (一种支持多并发链接的技术,具有高带宽、低时延、高扩展性的特点)将物理分散分布的存储资源汇聚在一起,统一提供存储服务,并使用统一全局命名空间来管理数据。
二、 GlusterFS特点
●扩展性和高性能
GlusterFS利用双重特性来提供高容量存储解决方案。
(1)Scale-Out架构允许通过简单地增加存储节点的方式来提高存储容量和性能(磁盘、计算和I/O资源都可以独立增加),支持10GbE和InfiniBand等高速网络互联。
(2) Gluster弹性哈希(ElasticHash) 解决了GlusterFS对元数据服务器的依赖,改善了单点故障和性能瓶颈,真正实现了并行化数据访问。GlusterFS采用弹性哈希算法在存储池中可以智能地定位任意数据分片(将数据分片存储在不同节点上),不需要查看索引或者向元数据服务器查询。
●高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问当数据出现不一致时,自我修复功能能够把数据恢复到正确的状态,数据的修复是以增量的方式在后台执行,几乎不会产生性能负载。
GlusterFS可以支持所有的存储,因为它没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、XFS等)来存储文件,因此数据可以使用传
统访问磁盘的方式被访问。
●全局统一命名空间
分布式存储中,将所有节点的命名空间整合为统一命名空间,将整个系统的所有节点的存储容量组成一个大的虛拟存储池,供前端主机访问这些节点完成数据读写操作。
●弹性卷管理
GlusterFs通过将数据储存在逻辑卷中,逻辑卷从逻辑存储池进行独立逻辑划分而得到。
逻辑存储池可以在线进行增加和移除,不会导致业务中断。逻辑卷可以根据需求在线增长和缩减,并可以在多个节点中实现负载均衡。
文件系统配置也可以实时在线进行更改并应用,从而可以适应工作负载条件变化或在线性能调优。
●基于标准协议
Gluster存储服务支持NFS、CIFS、HTTP、FTP、SMB 及Gluster原生协议,完全与POSIX标准(可移植操作系统接口)兼容。
现有应用程序不需要做任何修改就可以对Gluster中的数据进行访问,也可以使用专用API进行访问。
三、GlusterFS术语
●Brick(存储块):
指可信主机池中由主机提供的用于物理存储的专用分区,是GlusterFS中的基本存储单元,同时也是可信存储池中服务器上对外提供的存储目录。
存储目录的格式由服务器和目录的绝对路径构成,表示方法为SERVER:EXPORT,如192.168.121.55:/data/mydir/
●Volume(逻辑卷):
一个逻辑卷是一组Brick的集合。卷是数据存储的逻辑设备,类似于LVM中的逻辑卷。大部分Gluster管理操作是在卷上进行的。
●FUSE:
是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码。
●VFS:
内核空间对用户空间提供的访问磁盘的接口。
●Glusterd (后台管理进程) :
在存储群集中的每个节点上都要运行。
四、模块化堆栈式架构
GlusterFS采用模块化、堆栈式的架构。
通过对模块进行各种组合,即可实现复杂的功能。例如Replicate模块可实现RAID1,Stripe 模块可实现RAID0,
通过两者的组合可实现RAID10和RAID01,同时获得更高的性能及可靠性。
五、GlusterFS 的工作流程
(1)客户端或应用程序通过GlusterFS 的挂载点访间数据。
(2) linux系统内核通过VFS API收到请求并处理。
(3) VFS将数据递交给FUSE内核文件系统,并向系统注册一“个实际的文件系统FUSE,而FUSE 文件系统则是将数据通过/dev/fuse设备文件递交给了GlusterFs client 端。可以将FUSE 文件系统理解为一个代理。
(4) GlusterFS client 收到数据后,client 根据配置文件的配置对数据进行处理。
(5)经过GlusterFS client 处理后,通过网络将数据传递至远端的GlusterFS Server,并且将数据写入到服务器存储设备上。
六、弹性HASH算法
弹性HASH算法是Davies-Meyer算法的具体实现,通过HASH 算法可以得到一个32位的整数范围的hash值, 假设逻辑卷中有N个存储单位Brick,则32位的整数范围将被划分为N个连续的子空间,每个空间对应一个Brick。
当用户或应用程序访问某一个命名空间时,通过对该命名空间计算HASH值,根据该HASH 值所对应的32位整数空间定位数据所在的Brick。
弹性HASH算法的优点:
保证数据平均分布在每一个Brick 中。
解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈。
七、GlusterFs的卷类型
GlusterFS支持七种卷,即分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷和分布式条带复制卷。
●分布式卷(Distribute volume):
文件通过HASH算法分布到所有Brick Server上,这种卷是GlusterFS的默认卷;以文件为单位根据HASH算法散列到不同的Brick,其实只是扩大了磁盘空间,如果有一块磁盘损坏,数据也将丢失,属于文件级的RAID0,不具有容错能力。在该模式下,并没有对文件进行分块处理,文件直接存储在某个Server节点上。由于直接使用本地文件系统进行文件存储,所以存取效率并没有提高,反而会因为网络通信的原因而有所降低。
分布式卷具有如下特点:
文件分布在不同的服务器,不具备冗余性。
更容易和廉价地扩展卷的大小。
单点故障会造成数据丢失。
依赖底层的数据保护。
#示例原理:
Filel和File2存放在Server1, 而File3存放在Server2,文件都是随机存储,一个文件(如File1)要么在Server1上,要么在Server2上,不能分块同时存放在Server1和Server2。
#创建一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中
gluster volume create dis-volume server1:/dir1 server2:/dir2 server3:/dir3
●条带卷(Stripe volume):
类似RAID0,文件被分成数据块并以轮询的方式分布到多个Brick Server上,文件存储以数据块为单位,支持大文件存储,文件越大,读取效率越高,但是不具备冗余性。
条带卷特点:
数据被分割成更小块分布到块服务器群中的不同条带区。
分布减少了负载且更小的文件加速了存取的速度。
没有数据冗余。
#示例原理:
File被分割为6段,1、3、5放在Server1,2、4、6放在Server2。
#创建了一个名为stripe-volume的条带卷,文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
●复制卷(Replica volume):
将文件同步到多个Brick上,使其具备多个文件副本,属于文件级RAID 1,具有容错能力。因为数据分散在多个Brick中,所以读性能得到很大提升,但写性能下降。
复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低。
复制卷特点:
卷中所有的服务器均保存一个完整的副本。
卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中Brick所包含的存储服务器数。
至少由两个块服务器或更多服务器。
具备冗余性。
#示例原理:
Filel同时存在Server1 和Server2,File2 也是如此,相当于Server2 中的文件是Server1 中文件的副本。
#创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
●分布式条带卷(Distribute Stripe volume):
BrickServer数量是条带数(数据块分布的Brick数量)的倍数,兼具分布式卷和条带卷的特点。
主要用于大文件访问处理,创建一个分布式条带卷最少需要4台服务器。
#示例原理:
File1和File2通过分布式卷的功能分别定位到Server1和Server2。在Server1中,File1 被分割成4段,其中1.3在Server1中的exp1目录中,2、4在Server1中的exp2目录中。
在Server2 中,File2 也被分割成4段,其中1、3在Server2中的exp3目录中,2、4在Server2 中的exp4目录中。
#创建一个名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)。Brick的数量是4 (Server1:/dir1、
Server2:/dir2、Server3:/dir3 和Server4:/dir4),条带数为2 (stripe 2)
gluster volume create dis-stripe stripe 2 transport tcp server1:/dirl server2:/dir2 server3:/dir3 server4:/dir4
创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或者复制卷:如果存储服务器的数量是条带或复制数的2倍甚至更多,那么将创建的是分布式条带卷
或分布式复制卷。
●分布式复制卷(Distribute Replica volume )
Brick Server数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点。主要用于需要冗余的情况下。
#示例原理:
Filel和File2通过分布式卷的功能分别定位到Serverl和Server2。 在存放File1时,File1根据复制卷的特性,将存在两个相同的副本,分别是Server1中的exp1目录和Server2
中的exp2 目录。在存放File2时,File2 根据复制卷的特性,也将存在两个相同的副本,分别是Server3中的exp3目录和Server4中的exp4目录。
#创建一个名为dis-rep的分布式复制卷,配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是复制数的倍数(>=2倍)。Brick的数量是4 (Server1:/dir1、
Server2:/dir2、Server3:/dir3 和Server4:/dir4),复制数为2(replica 2)
gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
●条带复制卷(Stripe Replica volume) :
类似RAID10,同时具有条带卷和复制卷的特点。
●分布式条带复制卷(Distribute Stripe Repl icavolume) :
三种基本卷的复合卷,通常用于类Map Reduce应用。
八、部署GlusterFS群集
| 节点 | IP地址 | 磁盘 | 挂载点 |
|---|---|---|---|
| Node1节点 | 192.168.110.10 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| Node2节点 | 192.168.110.20 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| Node3节点 | 192.168.110.60 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| Node4节点 | 192.168.110.70 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb1 /data/sdc1 /data/sdd1 /data/sde1 |
| 客户端节点 | 192.168.110.80 | ———————— | ———————— |
先给四个节点分别添加四块硬盘
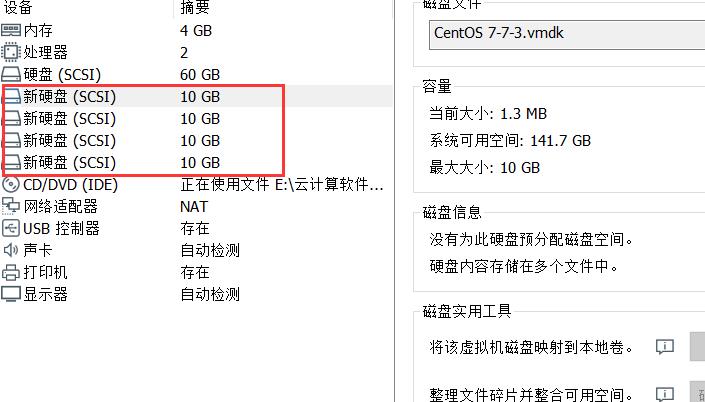
-----准备环境( 所有node节点上操作) -----
1.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
2.磁盘分区,并挂载(四个节点都做
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\\np\\n\\n\\n\\nw\\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
chmod +x /opt/fdisk.sh
./fdisk.sh
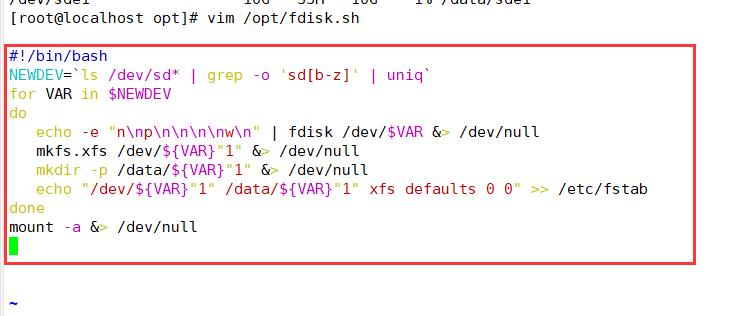
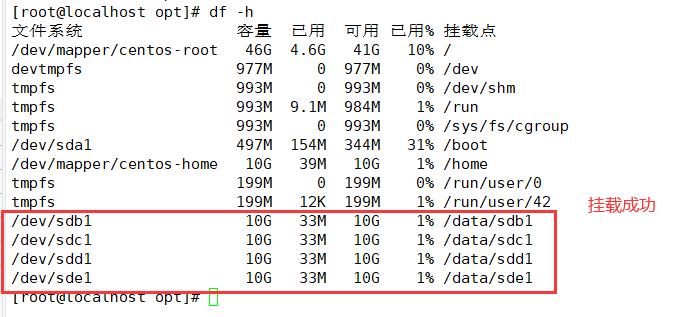
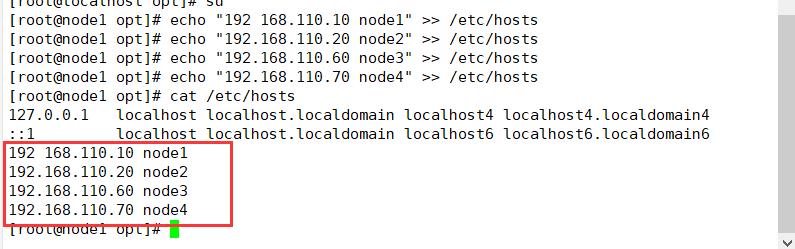
3.修改主机名,配置/etc/hosts文件(四个节点都修改)
#以Node1节点为例:
hostnamectl set-hostname node1
su
echo "192 168.110.10 node1" >> /etc/hosts
echo "192.168.110.20 node2" >> /etc/hosts
echo "192.168.110.60 node3" >> /etc/hosts
echo "192.168.110.70 node4" >> /etc/hosts

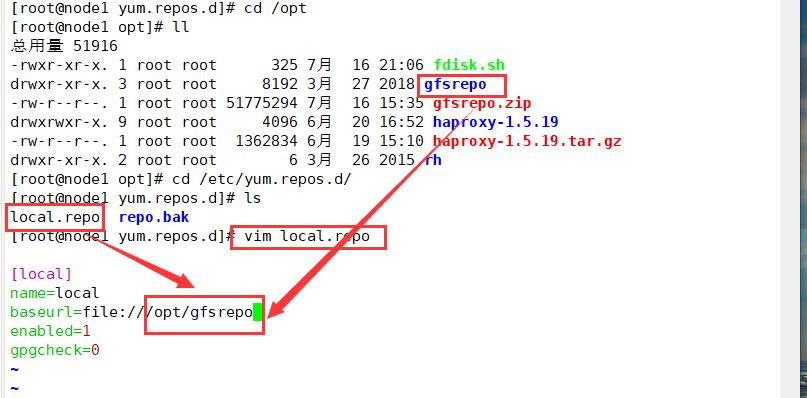
#将gfsrepo软件上传到/opt目录下
unzip gfsrepo.zip
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file;///opt/gfsrepo
gpgcheck=0
enabled=1
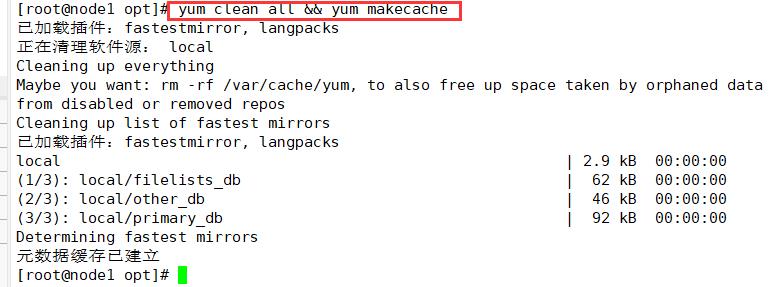
yum clean all && yum makecache

#yum -y install centos- release-gluster
#如采用官方YUM源安装,可以直接指向互联网仓库
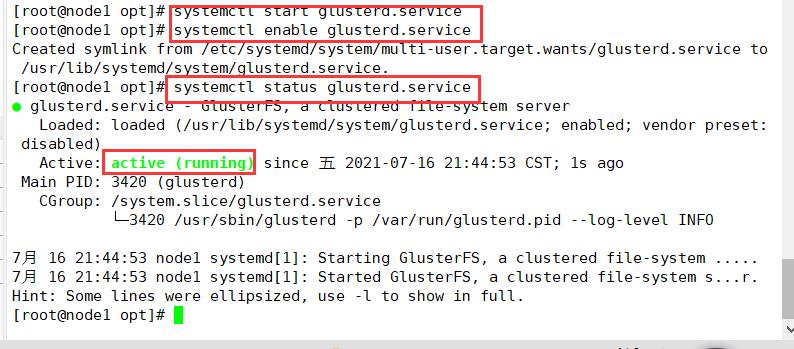
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service

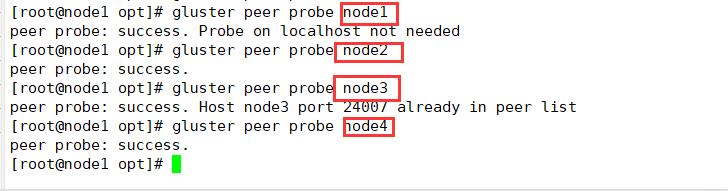
添加节点到存储信任池中(在node1 节点上操作,在192.168.110.10上)
#只要在一台Node节点上添加其它节点即可
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
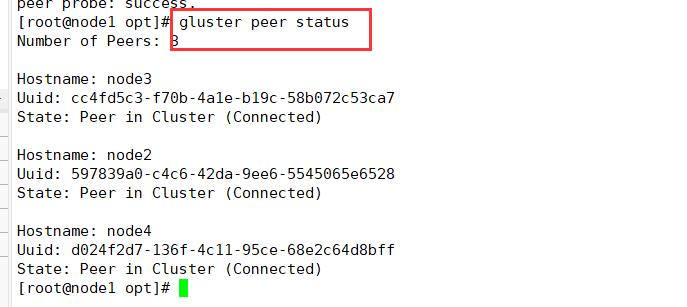
#在每个Node节点上查看群集状态
gluster peer status
创建卷(只需要在一台节点上创建即可,在192.168.110.10上)
#根据规划创建如下卷:
卷名称 卷类型 Brick
dis-volume 分布式卷 node1(/data/sdb1)、node2(/data/sdb1)
stripe -volume 条带卷 nodel(/data/sdc1)、node2(/data/sdc1)
rep-volume 复制卷 node3(/data/sdb1)、node4 (/data/sdb1)
dis-stripe 分布式条带卷 node1(/data/sdd1)、node2 (/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1)
dis-rep 分布式复制卷 node1(/data/sde1)、node2 (/data/sde1)、node3(/data/sde1)、node4(/data/sde1)
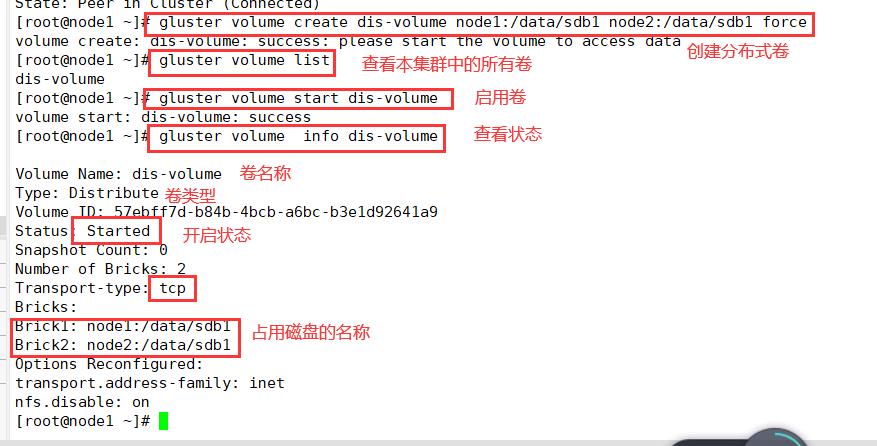
1.创建分布式卷
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force
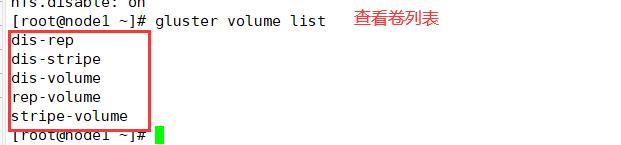
#查看卷列表
gluster volume list
#启动新建分布式卷
gluster volume start dis-volume
#查看创建分布式卷信息
gluster volume info dis-volume
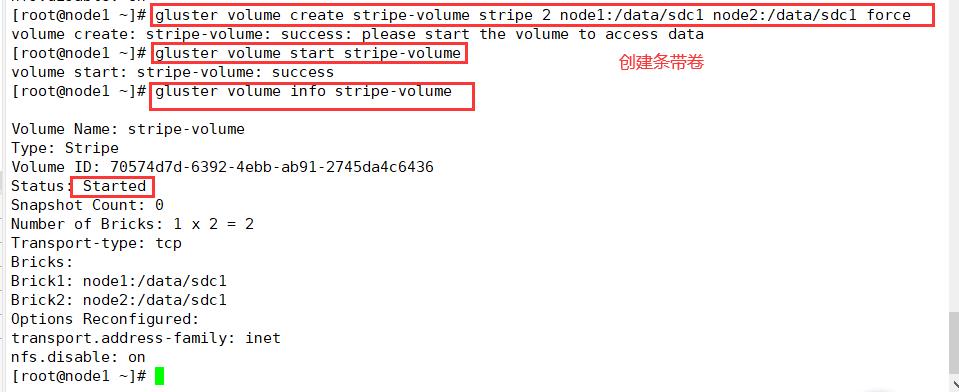
2.创建条带卷
#指定类型为stripe,数值为2,且后面跟了2个Brick Server, 所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume
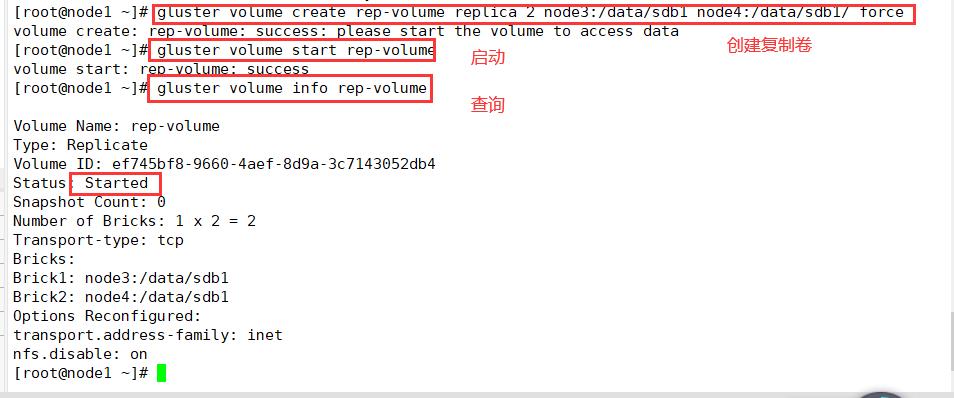
3.创建复制卷
#指定类型为replica, 数值为2,且后面跟了2个Brick Server, 所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
gluster volume start rep-volume
gluster volume info rep-volume
4.创建分布式条带卷
#指定类型为stripe, 数值为2,而且后面跟了4个Brick Server, 是2的两倍,所以创建的是分布式条带卷
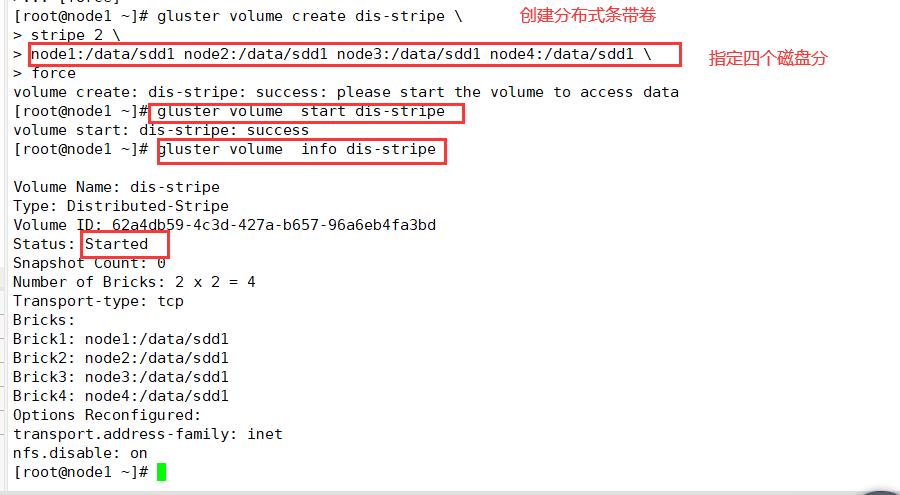
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
gluster volume start dis-stripe
gluster volume info dis-stripe
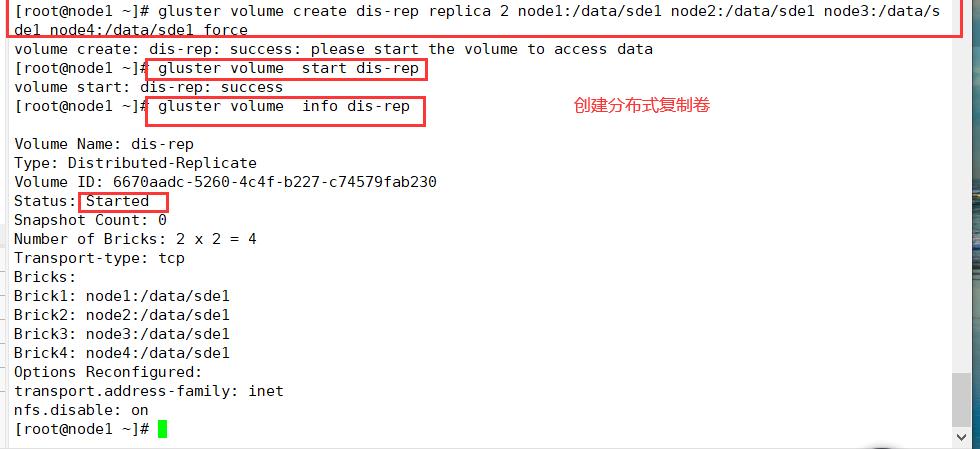
5、创建分布式复制卷
创建分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
启动新建分布式复制卷
gluster volume start dis-rep
查看创建分布式复制卷信息
gluster volume info dis-rep
部署Gluster客户端(192.168.110.80)
1.安装客户端软件
#将gfsrepo软件上传到/opt目下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
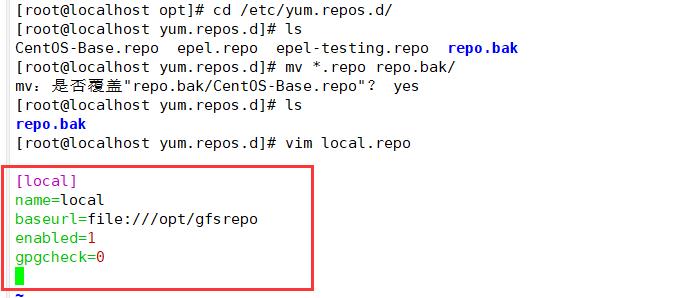
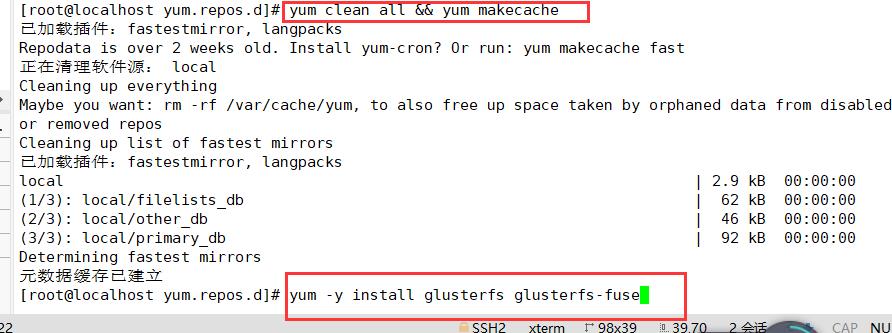
yum clean all && yum makecache
yum -y install glusterfs glusterfs-fuse
2.创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test

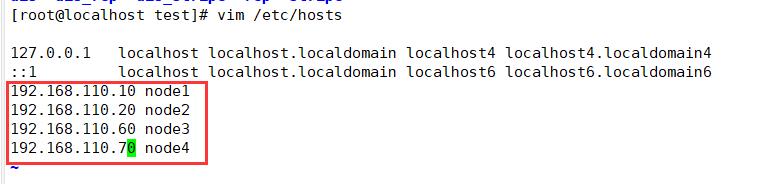
3.配置/etc/hosts文件
echo "192.168.110.10 node1" >> /etc/hosts
echo "192.168.110.20 node2" >> /etc/hosts
echo "192.168.110.60 node3" >> /etc/hosts
echo "192.168.110.70 node4" >> /etc/hosts
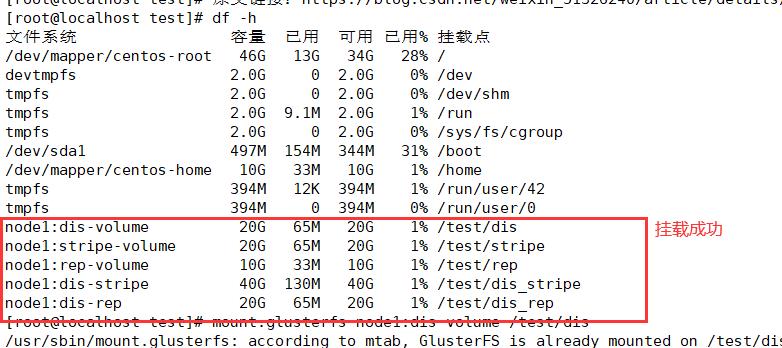
4.挂载Gluster文件系统
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_rep
df -Th
#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0
测试Gluster文件系统
1.卷中写入文件,客户端操作
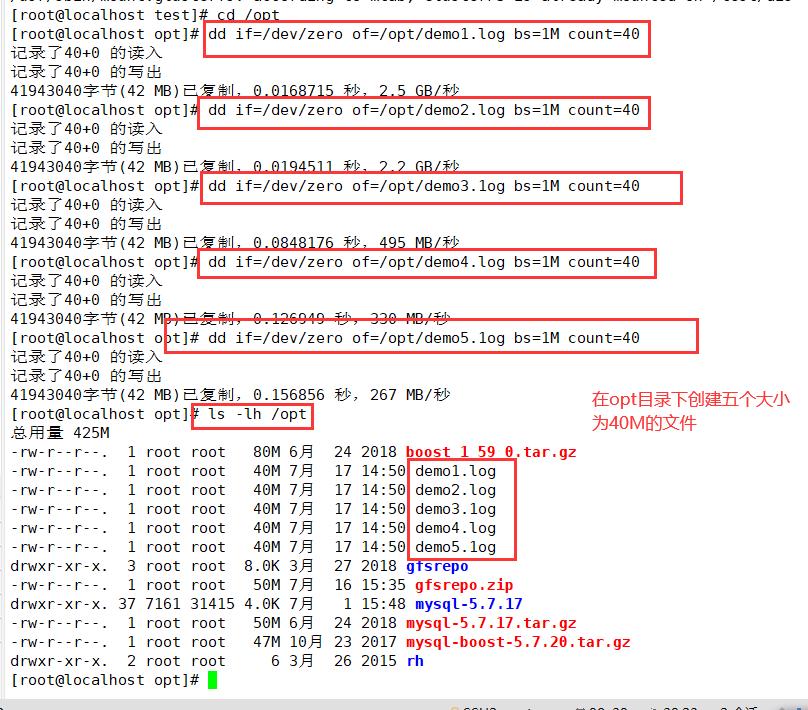
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.1og bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.1og bs=1M count=40
ls -lh /opt
cp /opt/demo* /test/dis
cp /opt/demo* /test/stripe/
cp /opt/demo* /test/rep/
cp /opt/demo* /test/dis_stripe/
cp /opt/demo* /test/dis_rep/

2、查看文件分布
查看卷对应的磁盘分区中的文件数据,验证结果
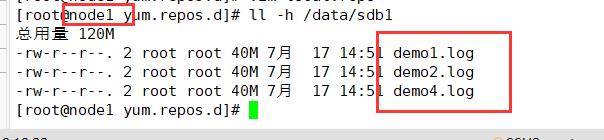
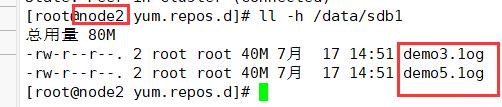
分布式只会将demo文件分开存储(5个文件不在同一磁盘分区上),不会将数据分片和备份
(1)查看分布式文件分布
node1:/dev/sdb1
ll -h /data/sdb1
node2:/dev/sdb1
ll -h /data/sdb1
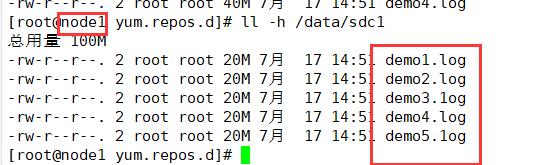
(2)查看条带卷文件分布
条带卷会将每个demo文件中的数据分片存储(两个分区各有20M的文件),没有备份
node1:/dev/sdc1
ll -h /data/sdc1
node2:/dev/sdc1
ll -h /data/sdc1
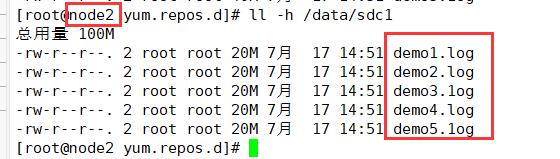
(3)查看复制卷文件分布
复制卷会将每个文件放入卷中的磁盘分区中(两分区的文件一样)
node3:/dev/sdb1
ll -h /data/sdb1
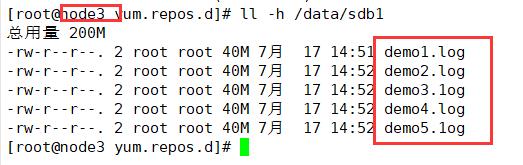
node4:/dev/sdb1
ll -h /data/sdb1
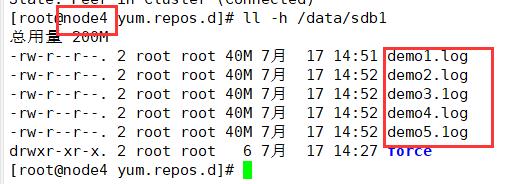
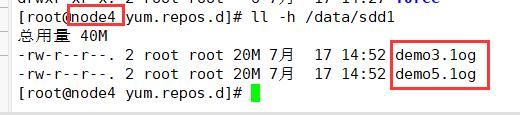
(4)查看分布式条带卷分布
分布式条带卷中,带有分布式和条带卷的特点,即将数据分片,又将文件分开存储,没有备份
node1:/dev/sdd1
ll -h /data/sdd1
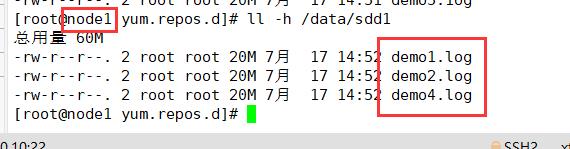
node2:/dev/sdd1
ll -h /data/sdd1
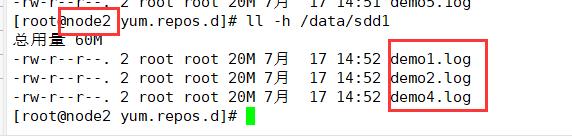
node3:/dev/sdd1
ll -h /data/sdd1
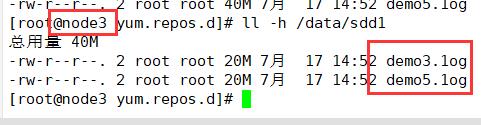
node4:/dev/sdd1
ll -h /data/sdd1
(5)查看分布式复制卷分布
分布式复制卷中,带有分布式和复制卷的特点,即将文件分开存储,又复制一遍文件(备份)
node1:/dev/sde1
ll -h /data/sde1
node2:/dev/sde1
ll -h /data/sde1
node3:/dev/sde1
ll -h /data/sde1
node4:/dev/sde1
ll -h /data/sde1
冗余测试(192.168.110.80)
挂起 node2 节点或者关闭glusterd服务来模拟故障,然后在客户端查看文件
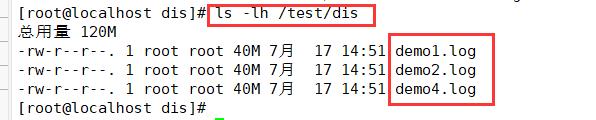
①分布式卷
缺少demo3和demo5,所以分布式卷不具备冗余
ls -lh /test/dis
②条带卷
文件无法找到,说明数据全部丢失,所以条带卷不具备冗余
ls -lh /test/stripe/

③分布式条带卷
存储的5个文件无法找到,所以分布式条带卷不具备冗余
ls -lh /test/dis_stripe/

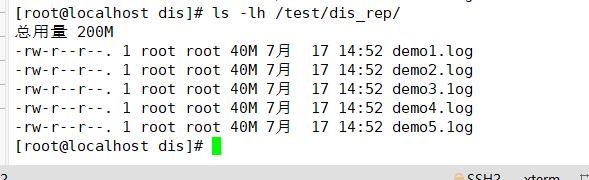
④分布式复制卷
文件全部存在,所以分布式复制卷具有冗余
ls -lh /test/dis_rep/
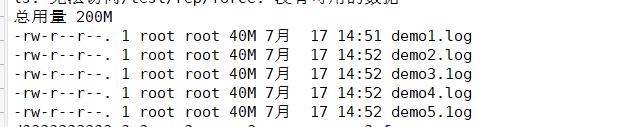
⑤复制卷
文件全部存在,所以复制卷具有冗余
ls -lh /test/rep/
其他的维护命令:
1.查看GlusterFS卷
gluster volume list
2.查看所有卷的信息
gluster volume info
3.查看所有卷的状态
gluster volume status
4.停止一个卷
gluster volume stop dis-stripe
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe
6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.allow 192.168.121.550
#仅允许
gluster volume set dis-rep auth.allow 192.168.80.* #设置192.168.80.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)
以上是关于GFS分布式文件系统(相关理论及实验操作详解)的主要内容,如果未能解决你的问题,请参考以下文章