spark安装-3台虚拟机
Posted wyju
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark安装-3台虚拟机相关的知识,希望对你有一定的参考价值。
1.上传tar包
spark-2.4.3-bin-hadoop2.7.tgz
2.解压tar包
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz
3.修改文件名
mv spark-2.4.3-bin-hadoop2.7 spark
4.配置环境变量
进入/etc/profile
sudo vim /etc/profile
添加以下内容
#SPARK_HOME
#自己的路径
export SPARK_HOME=/data/spark/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
使配置环境生效
source /etc/profile
5.进入spark的conf文件
cd /data/spark/spark/conf/
6.修改配置文件 spark-env.sh
拷贝spark-env.sh.template 为spark-env.sh
cp spark-env.sh.template spark-env.sh
拷贝进入spark-env.sh
vim spark-env.sh
添加以下内容
# 配置一下主服务器;端口号木有配置,默认是7077,在standby上告诉mastre是自己,我的standby是bigdata102,所以在bigdata102的配置文件中下面的bigdata103改成bigdata102
#配置大哥
export SPARK_MASTER_HOST=bigdata103
# 设置zookeepr
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata101:2181,bigdata102:2181,bigdata103:2181 -Dspark.deploy.zookeeper.dir=/spark"
7.配置slaves
进入 slaves
vim slaves
添加以下内容
# 配置的从节点
bigdata101
bigdata102
bigdata103
8.分发到各个服务器
sudo scp -r conf/ bigdata102:`pwd`
sudo scp -r conf/ bigdata10:`pwd`
9.在bigdata102中修改以下内容
拷贝进入spark-env.sh
vim spark-env.sh
修改export SPARK_MASTER_HOST
# 配置一下主服务器;端口号木有配置,默认是7077,在standby上告诉mastre是自己,我的standby是bigdata102,所以在bigdata102的配置文件中下面的bigdata103改成bigdata102
#配置二哥
export SPARK_MASTER_HOST=bigdata102
# 设置zookeepr
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata101:2181,bigdata102:2181,bigdata103:2181 -Dspark.deploy.zookeeper.dir=/spark"
10.修改用户名和用户组
sudo chown -R hadoop:hadoop spark
先启动zookeeper集群
bin/zkServer.sh start
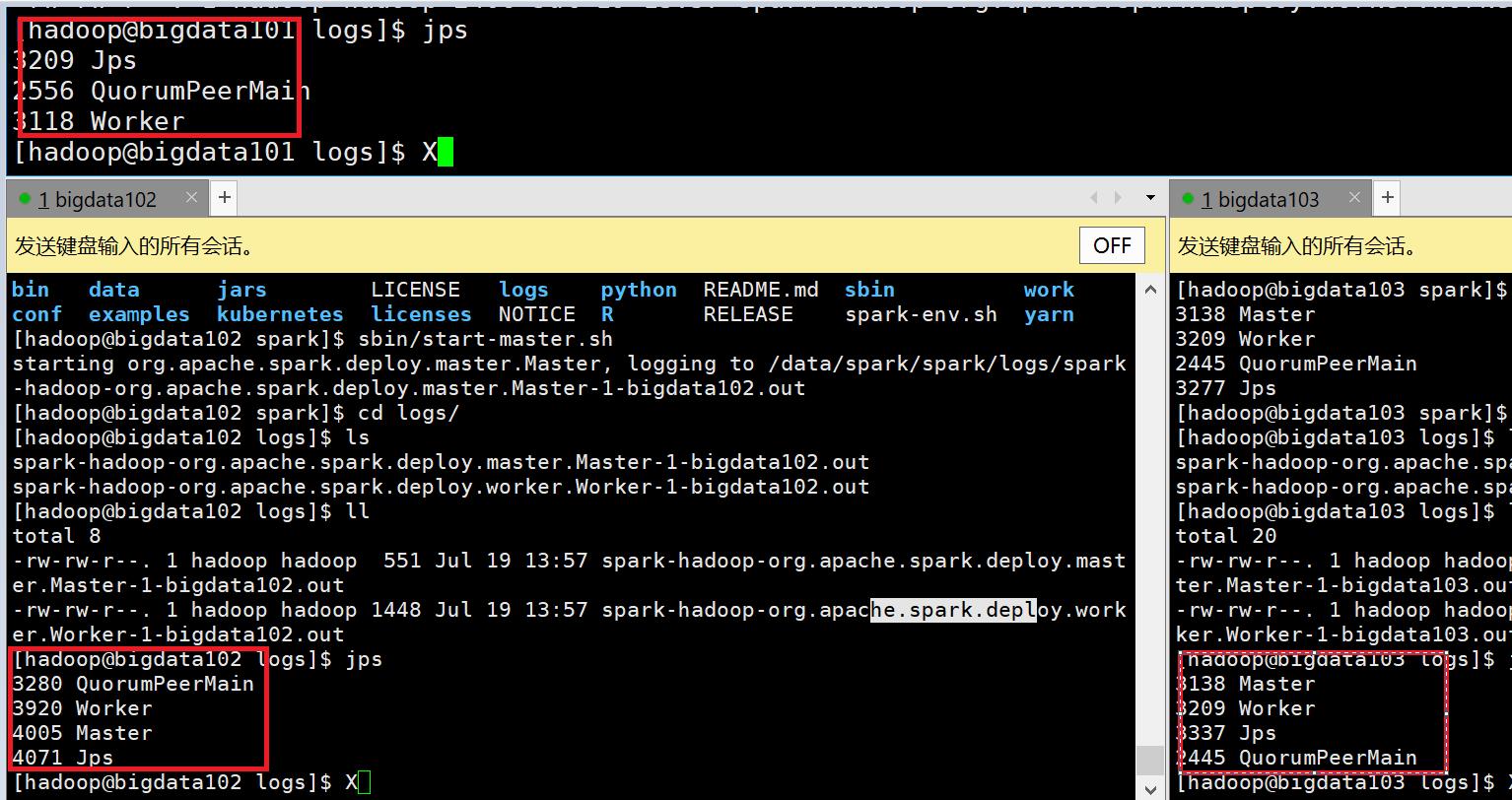
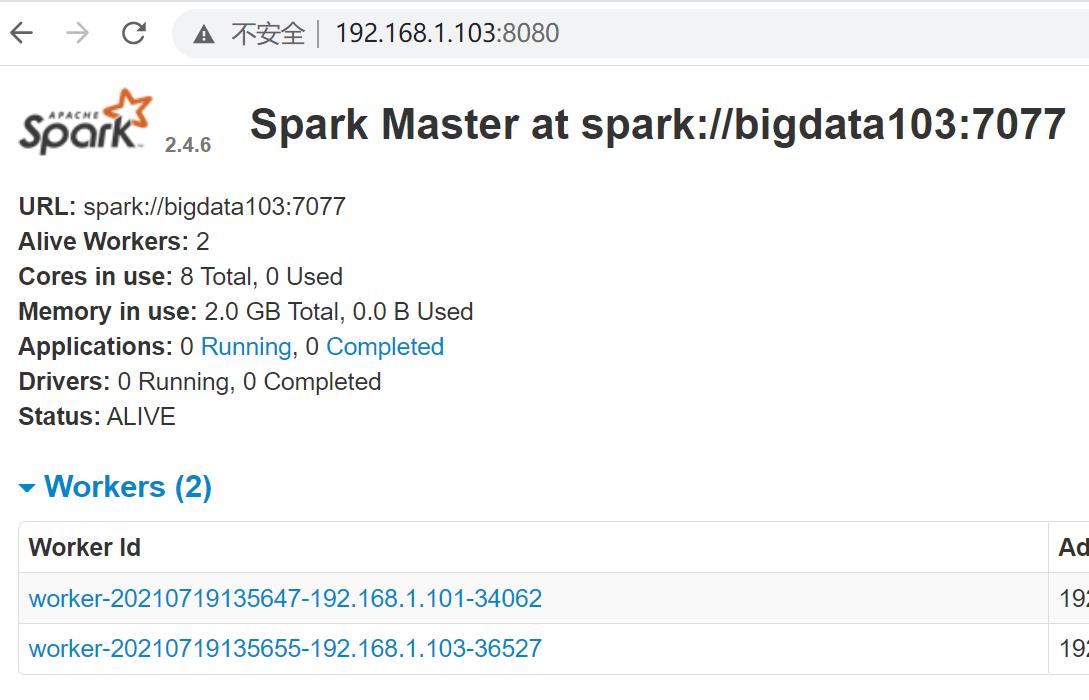
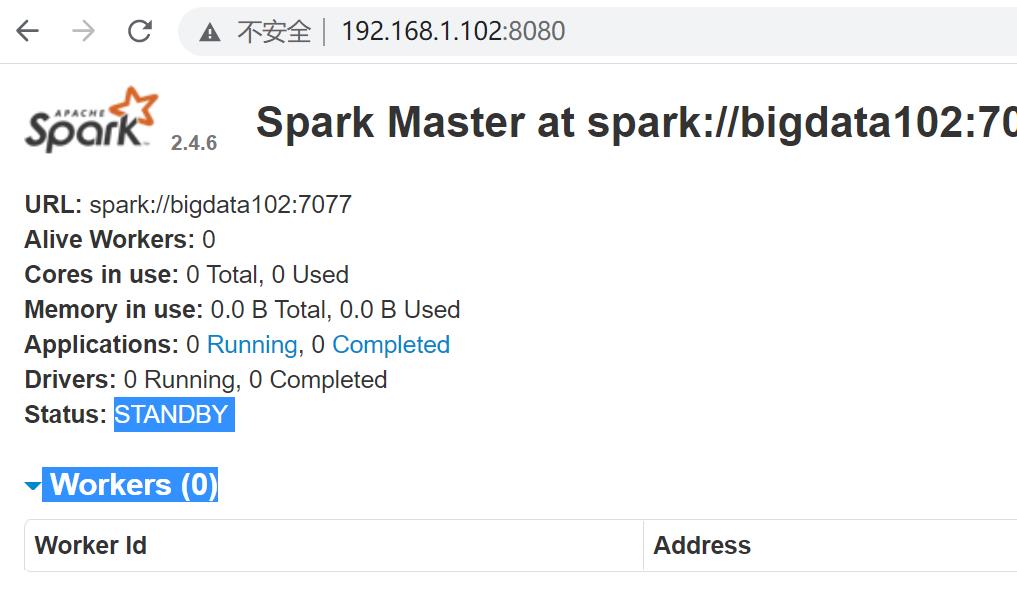
11.在bigdata103上执行一下master命令
#启动spark集群
sbin/start-all.sh
#关闭spark集群
sbin/stop-all.sh
#启动master
sbin/start-master.sh
#启动master
sbin/stop-master.sh
12.查看端口号
以上是关于spark安装-3台虚拟机的主要内容,如果未能解决你的问题,请参考以下文章