经验分享一文看懂 caffe 生成 VOC0712 lmdb 数据集
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经验分享一文看懂 caffe 生成 VOC0712 lmdb 数据集相关的知识,希望对你有一定的参考价值。
本教程详细记录了使用 caffe 制作 VOC0712 lmdb 数据集的方法。
最近在搞比特大陆的适配,里面的 fronted_from caffe 需要用到 lmdb 数据集,所以这里详细说一下原滋原味的 caffe 制作 lmdb 的方法。
1、源码编译 caffe_ssd
首先到我的 github 里 clone caffe_ssd 代码。
git clone -b caffe_ssd https://github.com/Jeremy-J-J/caffe-cudnn8.git
编译 caffe_ssd
cd caffe_ssd
cp caffe/Makefile.config caffe_ssd/
## 把 cuda 和 cudnn 关了,用 cpu 就好了
make -j32
make pycaffe
make test -j8
make runtest -j8
配置环境变量
vim ~/.bashrc
## 加入
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/PATH/TO/YOUR/caffe_ssd/python
source ~/.bashrc
验证 python 环境里的 caffe 是不是你想要的 caffe_ssd
import caffe
print(caffe.__file__) # 返回 pycaffe 的路径,你就可以知道是哪个caffe了
2、生成 VOC0712 lmdb
2.1、下载 VOC07/12 数据集
cd data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
2.2、生成 lmdb 数据集
cd caffe_ssd
./data/VOC0712/create_list.sh
./data/VOC0712/create_data.sh
其中 create_list.sh 内容
#!/bin/bash
root_dir=$HOME/data/VOCdevkit/
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in VOC2007 VOC2012
do
if [[ $dataset == "test" && $name == "VOC2012" ]]
then
continue
fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name\\/JPEGImages\\//g" $img_file
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name\\/Annotations\\//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
$bash_dir/../../build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
fi
# Shuffle trainval file.
if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file | perl -MList::Util=shuffle -e 'print shuffle(<STDIN>);' > $rand_file
mv $rand_file $dst_file
fi
done
create_data.sh 中内容如下:
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir=$cur_dir/../..
cd $root_dir
redo=1
data_root_dir="$HOME/data/VOCdevkit"
dataset_name="VOC0712"
mapfile="$root_dir/data/$dataset_name/labelmap_voc.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/$dataset_name/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
done
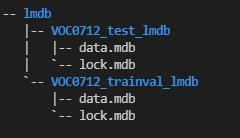
最终生成的 lmdb 数据集目录如下:
收工~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于经验分享一文看懂 caffe 生成 VOC0712 lmdb 数据集的主要内容,如果未能解决你的问题,请参考以下文章