领域图谱之命名实体识别-Named Entity Recognition Using a Semi-supervised Model Based on BERT and Bootstrapping(代
Posted Coding With you.....
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了领域图谱之命名实体识别-Named Entity Recognition Using a Semi-supervised Model Based on BERT and Bootstrapping(代相关的知识,希望对你有一定的参考价值。
目录
背景
1.这篇文章中提出了一种基于BERT和Bootstrapping半监督模型来进行命名实体识别。
首先说一下在命名实体识别方面的背景。命名实体识别是关系抽取、事件抽取、知识图谱等诸多NLP任务的基础。技术研究进展的大概趋势
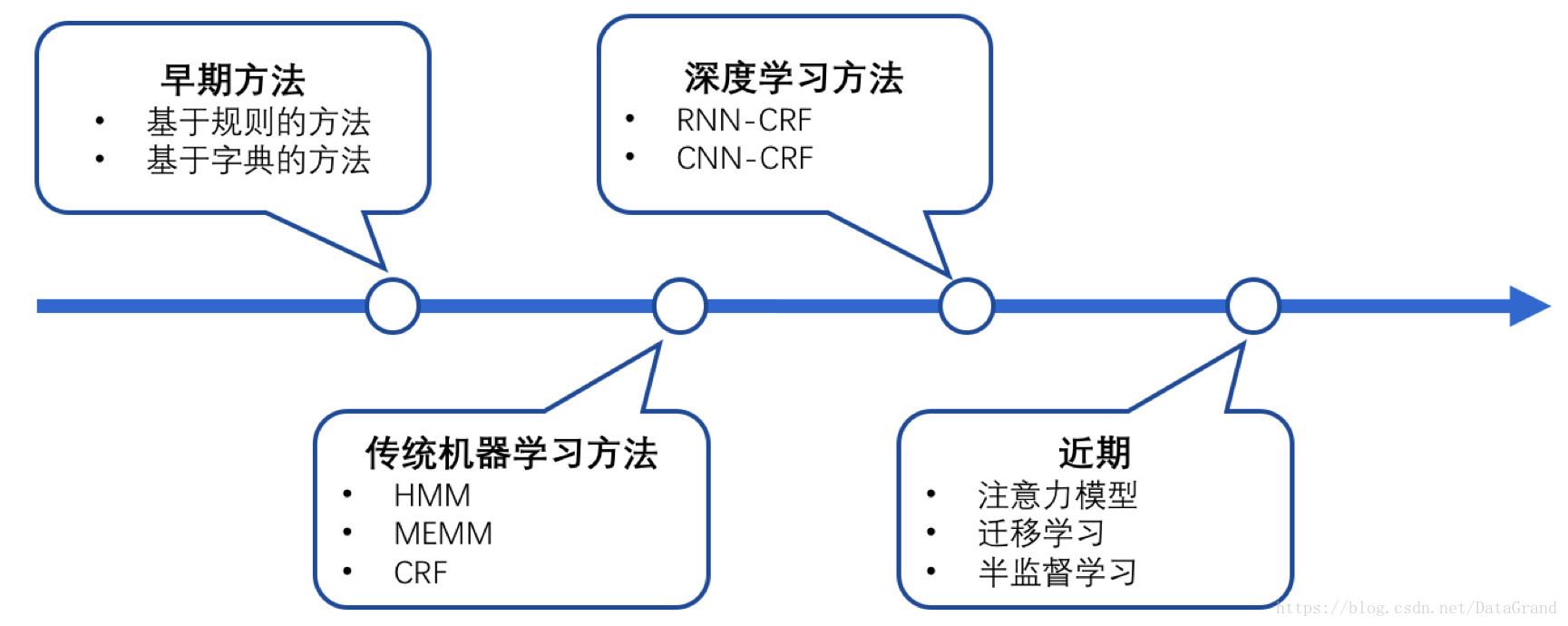
- 基于规则的方法:依赖于人工制定的规则,一般基于句法、语法、词汇的模式以及特定领域的知识等。由于特定领域的规则性,这种方法的特点是高精确率与低召回率,并且类似的规则难以迁移应用到别的领域中去,对新的领域而言,需要重新制定规则。
- 在这之后,实体抽取多采用基于机器学习方法。在基于机器学习的方法中,命名实体识别被当作序列标注问题。利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。常用模型包括隐马尔可夫模型(HMM)、MEMM(最大熵马尔可夫模型)和条件随机场(CRF)等。就是应用领域知识来表征每个训练样本,应用机器学习算法训练模型;然后利用维特比算法和统计概率等计算最佳标记序列。
要求实体的上下文以及构词具有统计规律,其次要有充足的训练语料。
- 传统的基于特征的方法需要大量的工程技巧与领域知识;而深度学习方法可以从输入中自动发掘信息以及学习信息的表示。目前较流行的方法是将统计方法与深度神经网络相结合,学界提出了DL-CRF模型做序列标注。在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测。比如使用如LSTM-CRF和BiLSTM-CRF等神经网络模型可以获得良好的性能,但需要大量的标记数据。在目前的情况下,专业领域很难获得大量的标记样本。贴标签的样品需要专业知识、需要花费大量的人力和时间。因此考虑如何利用有限的训练数据,训练出一个命名更好的实体识别模型。
- 注意力机制重点改进了词向量与字符向量的拼接。这样就使得模型可以动态地利用词向量和字符向量信息。近期通过引入迁移学习技术,降低了实体识别模型对于大量标注数据的需求。在命名实体识别中引入迁移学习,利用源域数据和模型完成目标域任务模型构建,提高目标域的标注数据量并且降低对标注数据数量的需求,在处理数据不足的命名实体识别任务上,具有非常好的效果。所谓的半监督,跟文本分类一样,其中的一种方法就是先训练一个标注系统,然后预测新语料,只保留那些置信度高的实体,然后将预测后的新语料作为训练语料。
总之,现在主流的深度学习命名实体识别模型,通常用于训练数据量大的场景,但不能很好地处理小样本场景。对于小样本场景,可以通过bootstrapping的方式扩展训练数据。本文采用预训练的BERT来解决语义信息问题,采用Bootstrapping来解决标注样本不足的问题,提出了一种基于BERT和Bootstrapping的半监督命名实体识别方法。
传统数据挖掘的训练模型,是纯粹在训练集上做的。但是我们很难保证,训练集跟测试集是一致的,准确来说,就是很难假设训练集和测试集的分布是一样的。于是乎,即使模型训练效果非常好,测试效果也可能一塌糊涂,这不是过拟合所致,这是训练集和测试集不一致所造成的。
解决(缓解)这个问题的一个思路就是“迁移学习”。迁移学习现在已经是比较综合的建模策略了,在此不详述。一般来说,它有两套方案:
1、在建模前迁移学习,即可以把训练集和测试集放在一起,来学习建模用到的特征,这样得来的特征已经包含了测试集的信息;
2、在建模后迁移学习,即如果测试集的测试效果还不错,比如0.5的准确率,想要提高准确率,可以把测试集连同它的预测结果一起,当做训练样本,跟原来的训练样本一起重新训练模型。
基于双向LSTM和迁移学习的seq2seq核心实体识别 代码和数据集
研究思路
1.选择BERT、BERT-BiLSTM、BERT-CRF和BERT-BiLSTM-CRF等基于BERT的神经网络模型作为核心模型,提出了一种基于自举的神经网络模型。
1) 开始先构建一个小型实体字典。
2) 使用字典中的实体学习一种模型。
3) 对于另一部分数据,使用学习的模型来识别字典中没有的实体。
4) 手动选择高质量的实体并将它们添加到实体字典中。
5) 重复步骤2–4,直到不再识别新实体或模型满足我们的要求。
2.基于BERT的NER模型
BERT-BiLSTM-CRF为例,模型分为三层:BERT层、BiLSTM层和CRF层,首先使用BERT模型提取文本重要特征得到输出向量; 然后输出向量作为下一层的输入,通过BiILSTM深度学习上下文特征信息, 进行命名实体识别; 最后CRF层对BiLSTM的输出序列处理, 结合CRF中的状态转移矩阵, 根据相邻之间标签得到一个全局最优序列.
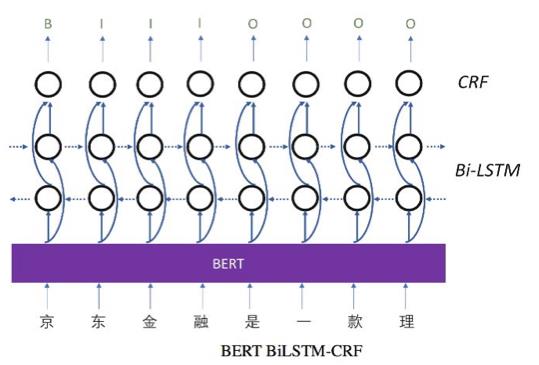
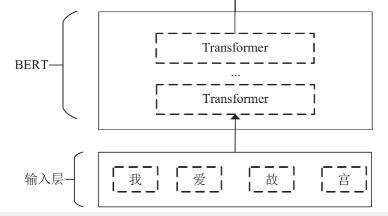
BERT层:利用预训练的BERT语言模型初始化获取输入文本信息中的字向量,记为序列 X=(x1, x2,x3,⋯,xn) , 所获取的字向量能够利用词与词之间的相互关系有效提取文本中的特征。bert 预训练模型不需要训练字向量,直接将文本输入模型训练即可。
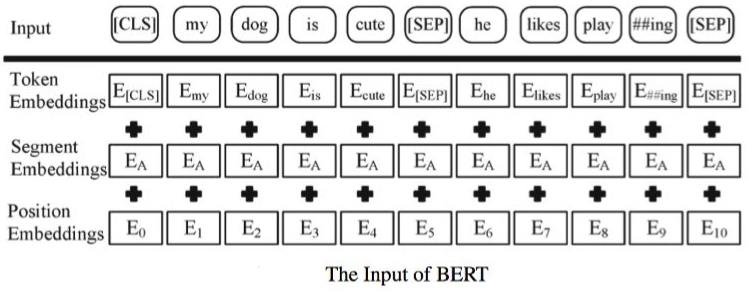
该层的输入是通过对单词向量标记嵌入、句子向量段嵌入和位置向量位置嵌入求和得到的。
- 单词向量嵌入:将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如图的示例中‘playing’被拆分成了‘play’和‘ing’;
- 分割嵌入:用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
- 位置嵌入:位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系。
根据句子最大长度和句号对原始数据进行分割,并在句子首尾补充【cls】、【sep】符号。其中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。针对数据分析中提到的文本过长的问题,采用按句子切割的方法,以标点符号优先级对句子进行切割,并按原顺序进行重组,当重组的句子长度超过512时,则新生成一条子数据并对剩余句子重复执行上述过程,直到所有的句子都被组装完成。这种数据处理的方式有效的解决了数据集文本长度过长的问题,并且完整地利用了数据信息。
BiLSTM:第一层获取的向量作为BILSTM各个时间步的输入, 通过前向和后向进行计算,并将序列进行按照位置拼接得到完整的状态序列,提取的句子特征全部映射之后的序列为矩阵 ,每一维对应每个类别标签的分数值.
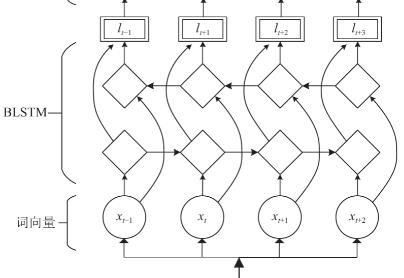

如果此时直接对每个位置的分数值进行独立分类, 选取每个分值最高的标签直接得到输出结果, 那么为什么加入CRF,因为
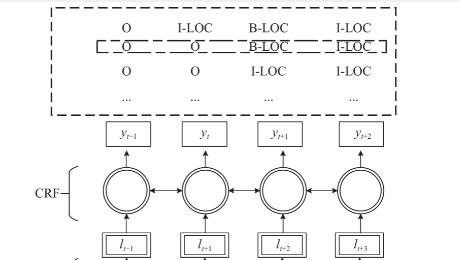
CRF层可以加入一些约束来保证最终预测结果是有效的。这些约束(eg:句子的开头应该是“B-”或“O”,而不是“I-”)可以在训练数据时被CRF层自动学习得到。直接输出则不能考虑相邻句子之间的信息, 不能得到全局最优, 分类结果不理想. 所以引入模型最后一层.
CRF层:用于捕获标签之间的依赖关系。主要是根据BiLSTM模型的预测输出序列求出使得目标函数最优化的序列.有了有用的约束,错误的预测序列将会大大减少。
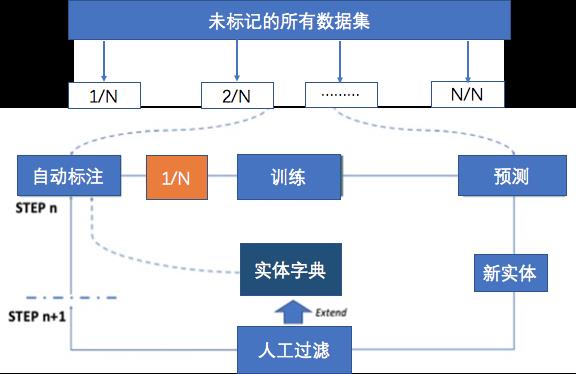
2.基于 BERT-Bootstrapping
Bootstrapping是一种自扩张方法,先初始化一个学习器,学习器通过自动学习训练语料来扩展新的知识,不断提高学习器的学习能力。
给定未标记的数据集和实体字典,算法工作如下:
1.首先我们将未标记的数据集分成N部分:集合[0],集合[1]……集合[N]。
2.将步骤初始化为0,然后重复以下步骤,直到不再创建新实体或性能符合我们的要求。
1) 自动注释:使用当前实体字典标记中的实体,通过自动标注对当前集合中进行自动标注。为了发现更多的新实体,每加载一次数据,都通过随机重放实体和添加噪声来进行数据扩充。具体地说,在每个句子中随机选择一个实体,在实体字典中随机地用另一个实体替换它,并在这个实体中随机地选择一个要用同音词替换的字。
2) 模型学习:使用实体字典自动标注来训练模型,核心模型从基于BERT的命名实体识别模型中选取。
3) 字典扩展:使用在训练阶段获得的模型来识别不在字典中的实体,从而获得一个新的实体集new entity。从新实体中手动筛选出高质量实体,并将它们添加到实体字典中,以进行下一步的自动标注。
4) n=n+1
最后,我们可以得到一个高质量的实体词典和一个性能良好的学习模型。
实验
目的是从文本中识别未知的金融实体,包括金融平台名称、公司名称、项目名称和产品名称。
数据集:2019年金融实体识别大赛数据集2019年CCF大数据与计算智能大赛数据集,数据集中有2500条数据和1416个标记实体。
采用的评价指标为:准确度、召回率和F1值。
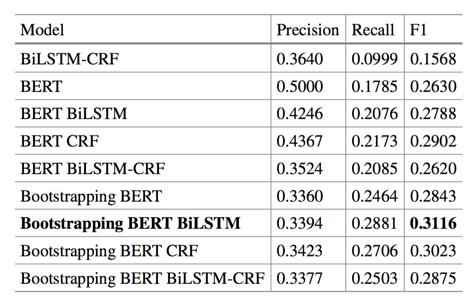
实验1
50%的标记实体被隐藏,不参加训练。使用剩下的50%的实体(708)来训练模型,并测试模型的性能以找到隐藏的708实体。
实验2
50%的标记实体被隐藏,不参加训练。使用剩下的50%的实体(708)来训练模型,并测试模型的性能,以便在包含2000个数据的测试数据集上识别新的实体。
结果:实验表明,在训练数据集标记不足的情况下,Boot-strapping比相应的模型能更好地发现测试数据集中的新实体,提高了对新实体的识别。实验还发现,随着步数的增加,模型的性能不断提高,人工过滤的工作量逐渐减少。
总结
针对标注数据不足的命名实体识别问题,提出了一种基于BERT和Bootstrapping的半监督命名实体识别算法。它从一个已知的小实体字典出发,反复进行自动标注、模型学习、字典扩充等过程,达到识别更多新实体的目的。实验表明,该算法既节省了标注成本,又保证了模型的性能。
未来的工作将测试不同形式和强度的噪声对性能的影响,并添加字典以减少人工滤波的工作量。
以上是关于领域图谱之命名实体识别-Named Entity Recognition Using a Semi-supervised Model Based on BERT and Bootstrapping(代的主要内容,如果未能解决你的问题,请参考以下文章