ELK——ElasticStack日志分析平台
Posted 611`
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK——ElasticStack日志分析平台相关的知识,希望对你有一定的参考价值。
ElasticStack日志分析平台
ELK日志采集与分析系统概述
- ELK是Elasticsearch、Logstash、Kibana的简称,是近乎完美的开源实时日志分析平台。这三者是日志分析平台的核心组件,而并非全部。
Elasticsearch- 是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能,是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上
- 具有分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等特点
Logstash- 它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。
- 它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch
Kibana- 是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据
- 它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据,Kibana 可以为 Logstash 和 Elasticsearch 提供友好的日志分析 web 界面,可以帮助你汇总、分析和搜索重要数据日志
ELK架构
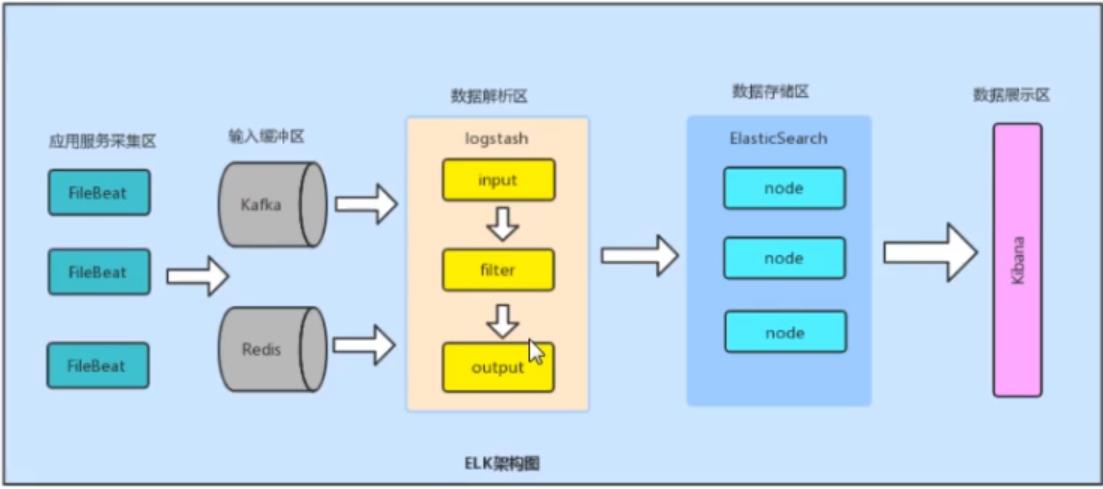
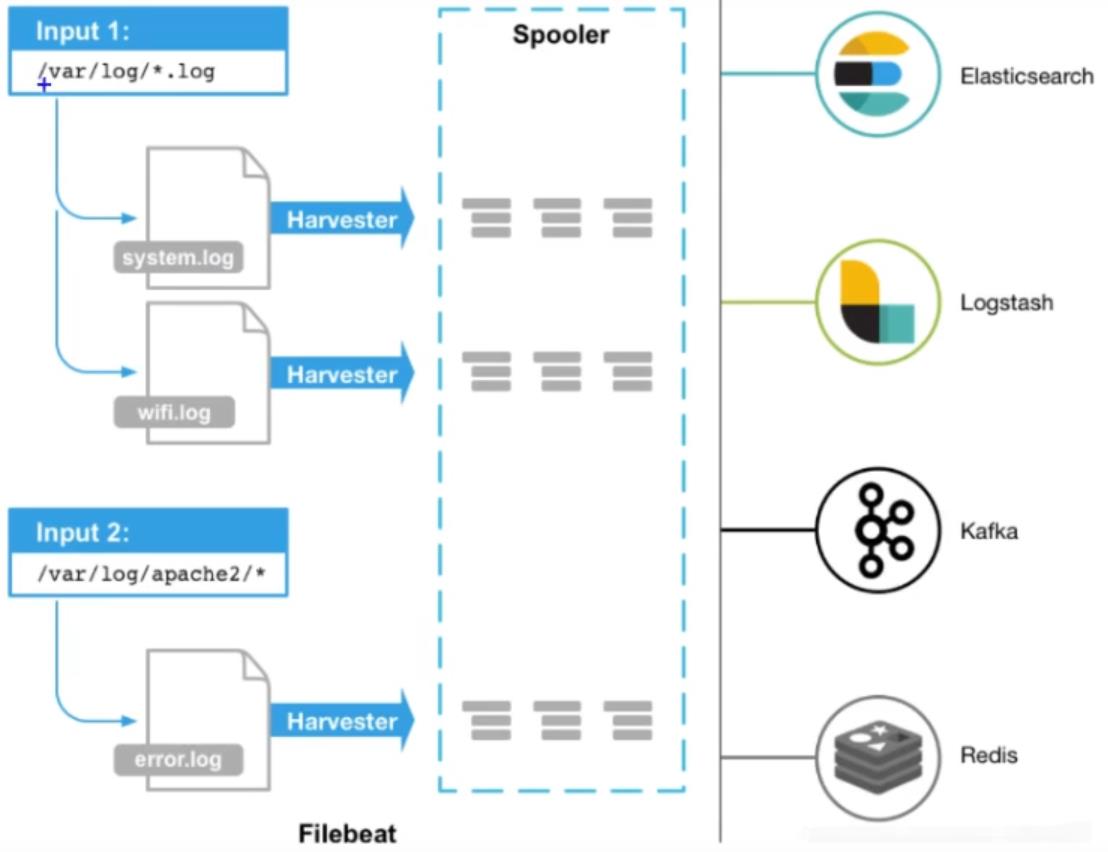
Filebeat
- 可以使用
Filebeat收集各种日志 ,之后发送到指定的目标系统上,但是同一时间只能配置一个输出目标. Filebeat会对配置好的日志内容进行收集,第一次会从每个文件的开头一直读到当前文件的最后一行。- 每一行称为一个事件,格式是一个包含很多字段的大字典,也就是
]SON格式的数据。在Filebeat中负责完成这个动作的官方称它为Harvester(收割机) - 每个事件将来会被保存到Elasticsearch中
- 在收割机读到文件的最后,会停止工作,直到文件有新的内容写入才继续工作
Filebeat安装
#官网下载filebeat
[root@pakho ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.2-linux-x86_64.tar.gz
#解压至/usr/local
[root@pakho ~]# tar xf filebeat-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@pakho ~]# mv /usr/local/filebeat-7.13.2-linux-x86_64/ /usr/local/filebeat
Filebeat启动管理
- 前台运行
- 采用前台运行的方式查看
Filebeat获取的日志结果
- 采用前台运行的方式查看
- 后台运行
- 使用nohup方式启动Filebeat到后台,日志结果可查看nohup.out文件
- 使用systemd管理的后台方式启动Filebeat进程不能查看输出日志,测试阶段勿用
配置systemd方式的Filebeat启动管理文件
[root@pakho ~]# vim /usr/lib/systemd/system/filebeat.service
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml
Restart=always
[Install]
WantedBy=multi-user.target
#建立系统进程
[root@pakho ~]# systemctl daemon-reload
[root@pakho ~]# systemctl start filebeat
Filebeat简单使用
- 准备测试数据
[root@pakho ~]# vim /tmp/access.log
112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] "GET / HTTP/1.1" 200 190 "-" "Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36" "-"
- 配置Filebeat的输入和输出
#备份配置文件
[root@pakho ~]# cp /usr/local/filebeat/filebeat.yml /usr/local/filebeat/filebeat.yml.bak
[root@pakho ~]# vim /usr/local/filebeat/filebeat.yml
filebeat.inputs: #输入模块,希望收集什么
- type: log #类型:日志
enabled: true #开启手机日志
paths: #日志路径
- /tmp/*.log
#- type: filestream
# enabled: false
# paths:
# - /var/log/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml#安装路径 modules.d下有更多的规则
reload.enabled: false #当模块配置文件发生变化时,filebeat自身重启,影响收集日志过程,一般配置完成才启动
setup.template.settings:
index.number_of_shards: 1 # 索引副本数量, 1 不产生副本
output.console: #添加 输出到终端屏幕上
pretty: true #开启
#setup.kibana:
#output.elasticsearch:
# hosts: ["localhost:9200"]
processors: #处理
- add_host_metadata: #添加此主机的源数据信息到输出数据中,如 IP MAC OS 等信息
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
Filebeat模块测试
#启动时发生了报错
[root@pakho ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml
Exiting: data path already locked by another beat. Please make sure that multiple beats are not sharing the same data path (path.data).
#关闭filebeat即可,本机器已经存在filebeat启动,datapath被lock
[root@pakho ~]# systemctl stop filebeat
[root@pakho ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml
{
"@timestamp": "2021-07-17T05:33:45.381Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.13.2"
},
"input": {
"type": "log"
},
"host": {
"id": "ad8a55213faa46babc18170804417b90",
"containerized": false,
"name": "pakho",
"ip": [
"192.168.100.200",
"fe80::ec53:d68d:60ea:b5e0"
],
"mac": [
"00:0c:29:ae:a5:a7"
],
"hostname": "filebeat",
"architecture": "x86_64",
"os": {
"type": "linux",
"platform": "centos",
"version": "7 (Core)",
"family": "redhat",
"name": "CentOS Linux",
"kernel": "3.10.0-862.el7.x86_64",
"codename": "Core"
}
},
"agent": {
"id": "33541cdc-c78e-4cf1-9181-e03db1ebdc36",
"name": "filebeat",
"type": "filebeat",
"version": "7.13.2",
"hostname": "filebeat",
"ephemeral_id": "4f5cb4e0-47b3-4398-8574-8e36905aea10"
},
"ecs": {
"version": "1.8.0"
},
"message": "112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] \\"GET / HTTP/1.1\\" 200 190 \\"-\\" \\"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36\\" \\"-\\"",
"log": {
"offset": 0, #从日志文件什么地方开始取的,从第一行
"file": {
"path": "/tmp/access.log"
}
}
}
- 找不到配置文件可使用
-c指定配置文件位置./filebeat -c /usr/local/filebeat/filebeat.yml
- filebeat本身运行日志默认位置
/usr/local/filebeat/logs/filebeat - 要修改Filebeat的日志路径,可以修改如下内容在配置文件
filebeat.yml中实现
#==================================Logging================================
# Sets log level. The default log level is info.
#Available log levels are: error, warning, info,debug
#logging.level: debug
path.logs: /var/log/ #添加此行即可
- 这样设置后,filebeat启动后,日志的目录是
/var/log,日志的文件名为filebeat,每次启动或者重启程序会产生一个新的日志文件filebeat,旧的日志命名为filebeat.1以此类推
专用日志搜集模块
模块文件存储位置
[root@pakho ~]# ls /usr/local/filebeat/modules.d
禁用模块
/usr/local/filebeat/filebeat modules disable 模块名
启用模块
/usr/local/filebeat/filebeat modules enable 模块名
Nginx模块
- 准备nginx示例模块
- 添加访问日志文件
[root@pakho ~]# vim /var/log/access.log
123.127.39.50 - - [04/Nar/2021:10:50:28 +0800] "GET/logo.jpg HTTP/1.1" 200 14137 "http://81.68.233.173/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) ApplewebKit/537.36(KHTAL, like Gecko) Chrome/88.0.4324.192 Safari/537.36" "_"
- 添加错误日志文件
[root@pakho ~]# vim /var/log/error.log
2021/03/04 10:50:28 [error] 11396#0: *5 open() "/farm/bg.jpg" failed (2: No such file or directory), client: 123.127.39.50, server: localhost, request: "GET /bg.jpg HTTP/1.1", host:"81.68.233.173", referrer: "http://81.68.233.173/"
- 启用Nginx模块
[root@pakho ~]# /usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml modules enable nginx
Enabled nginx
[root@filebeat ~]# ls /usr/local/filebeat/modules.d
nginx.yml...
modules.d/nginx.yml文件内容如下
- module: nginx
access:
enabled: true
error:
enabled: true
- nginx模块搜集日志的默认路径是:
/var/log/nginx/access.log*/var/log/nginx/error.log*
- 使用默认路径,打开模块即可
- 使用非默认路径
- 假如所要搜集的日志真实路径和日志收集模块默认的路径不一致,可以配置
var.paths:属性进行配置。- 接收的值是一个包含一个以上的日志绝对路径列表,接收的值是一个数组
- 用于给日志文件设置自定义路径的。如果不设置此选项,Filebeat将根据您的操作系统选择路径选择使用默认值
- 假如所要搜集的日志真实路径和日志收集模块默认的路径不一致,可以配置
[root@filebeat ~]# vim /usr/local/filebeat/modules.d/nginx.yml
- module: nginx
access:
enabled: true
error:
enabled: true
var.paths: ["/var/log/access.log","/var/log/error.log"]
- 或者下面的方式
- module: nginx
access:
enabled: true
error:
enabled: true
var.paths:
- "/var/log/access.log*"
- "/var/log/error.log*"
- 注意
var.paths指定的路径,是以追加的方式和模块默认路径合并到一起的,也就是说假如模块的默认路径有具体的日志文件/var/log/nginx/access.log- 这里
var.paths也配置了路径/var/log/access.log,那么最终Filebeat收集的日志路径将会是:/var/log/nginx/access.log/var/log/access.log- 原路径以及指定路径都会收集!
- 测试:调用模块进行测试:
./filebeat -e
[root@pakho filebeat]# pwd
/usr/local/filebeat
# -c 指定配置文件 -e 开启模块
[root@pakho filebeat]# ./filebeat -c /usr/local/filebeat/filebeat.yml -e
配置output
Filebeat是用于搜集日志,之后把日志推送到某个接收的系统中的,这些系统或者装置在Filebeat中称为output- output类型
console终端屏幕elasticsearch存放日志,并提供查询logstash进一步对日志数据进行处理kafka消息队列
Filebeat运行的时候,以上的output只配置一种即可- 输出到Console
- 输出完整
JSON数据
- 输出完整
output.console:
pretty: true
- 进入
Filebeat的安装目录下,执行命令前台运行
./filebeat
- 如果只想输出完整
JSON数据中的某些字段
output.console:
codec.format:
string: '%{[@timestamp]} %{[message]}'
其他输出目标
- 输出到
Elasticsearch
output.elasticsearch:
hosts: ['http://es01:9200','http://es02:9200']
- 输出到
logstach
output.logstach:
hosts: ["127.0.0.1:5044"]
重读日志文件
- 有时候处于实验目的,可能需要重新读取日志文件,这个时候需要删除安装目录下的 data文件夹,重新运行filebeat即可

- 假如出现如下报错,删除安装目录中的
data文件夹
Exiting: data path already locked by another beat. Please make sure that multiple beats are not sharing the same data path (path.data).
- 查看是否有一个进程已经处于运行状态,尝试杀死此进程,之后重新运行
Filebeat
[root@pakho filebeat]# ps -ef | grep 'filebea[t]'
root 2322 2019 0 17:10 pts/2 00:00:00 ./filebeat -c /usr/local/filebeat/filebeat.yml -e
使用Processors(处理器)过滤和增强数据
- 可以在配置中定义处理器,以便在事件发送到配置的输出之前对其进行处理。libbeat库提供以下处理:
- 减少导出字段的数量
- 使用其他元数据增强事件
- 执行其他除了和解码
- 工作方式
- 每个处理器都接收一个事件,对该事件应用已定义的操作,然后返回该事件。如果定义处理器列表,则将按照在Filebeat配置文件中定义的顺序执行它们。
去除日志中的某些行
- 删除所有以
DBG:开头的行
processors:
- drop_event: #丢弃事件
when: #当
regexp: #正则表达式,告诉系统下面这段话带正则表达式
message: "^DBG:" #message为自定义字段
向输出的数据中添加某些自定义字段
- 用于工作中标记特别的日志
processors:
- add_fields:
target: project #要添加的自定义字段key的名称
fields:
name: myproject
id: '574734885120952459'
- 执行后效果如下
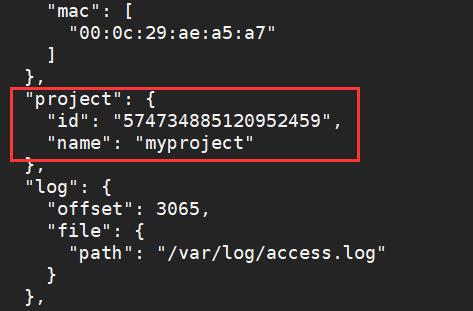
从事件中删除某些字段
processors:
- drop_fields:
fields: ["field1","field2",...]
ignore_missing: false
- 以上配置,将删除字段:
field1和field2 ignore_missing的值为false表示,字段名不存在则会返回错误,为true不会返回错误- 事件中的
@timestamp和type字段是无法删除的 - 下面的配置示例是删除顶级字段
input和顶级字段ecs中的version字段
- drop_fields:
fields: ['input',"ecs.version"]
Logstash
Logstash安装
#下载Logstash
[root@pakho ~]# curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-7.13.2-linux-x86_64.tar.gz
#解压至/usr/local
[root@pakho ~]# tar xf logstash-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@pakho ~]# mv /usr/local/logstash-7.13.2/ /usr/local/logstash
测试运行
- 运行最基本的
Logstash管道来测试Logstash安装 Logstash管道具有两个必需元素input和output,以及一个可选元素filter,输入插件使用来自源的数据,过滤器插件根据你的指定修改参数,输出插件将数据写入目标
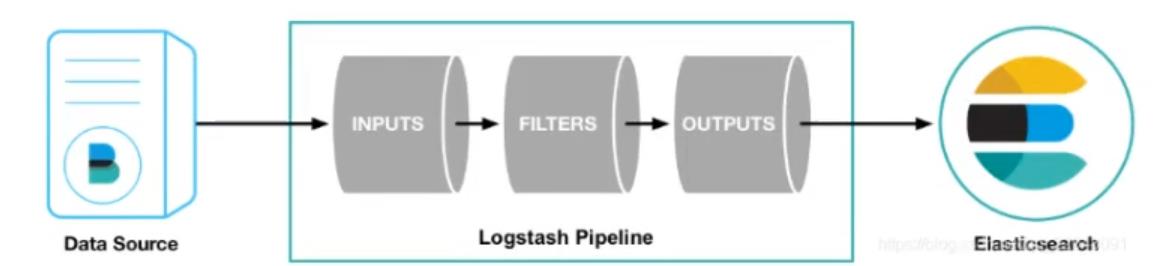
- 进入Logstash的安装目录下执行:
bin/logstash -e ''
-e选项用于设置Logstash处理数据的输入和输出-e等同于-e input { stdin { type => stdin} } output { { codec => rubydebug} }input { stdin { type => stdin} }- 表示
Logstash需要处理的数据来源于标准输入设备
- 表示
output { stdont { codec = > rubydebug} }- 表示
Logstash把处理好的数据输出到标准输出设备
- 表示
[root@pakho bin]# pwd
/usr/local/logstash/bin
#input输入 type从键盘读取 output输出 标准输出
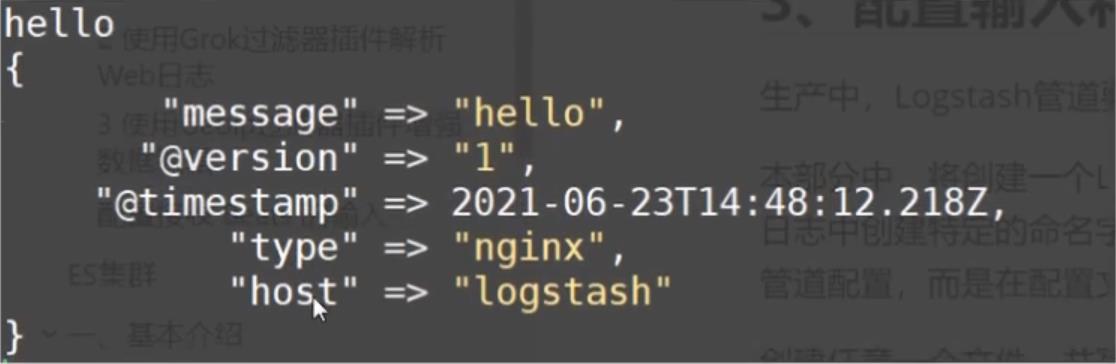
[root@pakho bin]# ./logstash -e 'input { stdin { type => stdin } } output { stdout { codec=> rubydebug } }'
...
hello
{
"@timestamp" => 2021-07-17T13:36:08.457Z,
"host" => "pakho",
"message" => "hello",
"@version" => "1",
"type" => "stdin"
}
message字段对应的值是Logstash接收到的一行完整的数据@version是版本信息,可以用于建立索引使用@timestamp处理对应的值是Logstash接收到的一行完整的数据type就是之前input中设置的值,这个值可以任意修改,但是,type是内置的变量,不能修改,用于建立索引和条件判断等hosts表示从哪个主机过来的数据- 修改
type的值为nginx的示例(主要是区分索引的时候用,这里改了没什么实效果)
./bin/logstash -e "input { stdin { type => nginx}} output { stdout { codec => rubydebug } }"
配置输入和输出
- 生产中,
Logstash管道要复杂一些:它通常具有一个或多个输入,过滤器和输出插件。 - 本部分中,将创建一个
Logstash管道,该管道使用标准输入来获取Apache Web日志作为输入,解析这些日志以从日志中创建特定的命名字段,然后将解析的数据输出到标准输出(屏幕上)。并且这次无需在命令行上定义管道配置,而是在配置文件中定义管道 - 创建任意一个文件,并写入如下内容,作为
Logstash的管道配置文件
[root@pakho ~]# vim /usr/local/logstash/config/first-pipeline.conf
input {
stdin{ }
}
output {
stdout{ }
}
- 配置文件语法测试
[root@pakho logstash]# pwd
/usr/local/logstash
[root@filebeat logstash]# bin/logstash -f config/first-pipeline.conf --config.test_and_exit
...
Configuration OK
-f用于指定管道配置文件- 运行如下命令启动
Logstash
[root@pakho logstash]# bin/logstash -f config/first-pipeline.conf
The stdin plugin is now waiting for input:
- 启动后复制如下内容到命令行中,并按下回车键
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/imageskibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama2013/" "Mozilla/5.0 (Macintosh;IntelMac 0s X 10_9_1) ApplewebKit/537.36 (KHTML,like Gecko) Chrome/32.0.1700.77 Safari/537.36"
- 将会看到如下输出
{
"host" => "pakho",
"@version" => "1",
"@timestamp" => 2021-07-17T14:00:44.109Z,
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \\"GET /presentations/logstash-monitorama-2013/imageskibana-search.png HTTP/1.1\\" 200 203023 \\"http://semicomplete.com/presentations/logstash-monitorama2013/\\" \\"Mozilla/5.0 (Macintosh;IntelMac 0s X 10_9_1) ApplewebKit/537.36 (KHTML,like Gecko) Chrome/32.0.1700.77 Safari/537.36\\""
}
使用Grok过滤器插件解析Web日志
- 现在有了一个工作管道,但是日志消息的格式不是理想的。你想解析日志消息,以便能从日志中创建特定的命名字段。为此,应该使用
grok过滤器插件 - 使用
grok过滤器插件,可以将非结构化日志数据解析为结构化和可查询的内容 grok会根据你感兴趣的内容分配字段名称,并把这些内容和对应的字段名称进行绑定grok如何知道哪些内容是你感兴趣的呢?它是通过自己预定义的模式来识别感兴趣的字段的。这个可以通过给其配置不同的模式来实现。- 这里使用的模式是
%{COMBINEDAPACHELOG} %{COMBINEDAPACHELOG}使用以下模式从Apache日志中构造行:
| 原信息 | 对应新的字段名称 |
|---|---|
| IP地址 | clientip |
| 用户ID | ident |
| 用户认证信息 | auth |
| 时间戳 | timestamp |
| HTTP请求方法 | verb |
| 请求的URL | request |
| HTTP版本 | httpversion |
| 响应码 | response |
| 响应体大小 | bytes |
| 跳转来源 | referrer |
- 并且这里想要实现修改配置文件之后自动加载它,不能配置
input为stdin - 所有,这里使用了
file,创建示例日志文件
[root@pakho ~]# vim /var/log/httpd.log
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/imageskibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; IntelMac OS X 10_9_1) AppleWebKit/537.36 (KHTAL,like Gecko) Chrome/32.0.1700.77 Safari/537.36"
确保没有缓存数据
[root@pakho data]# pwd
/usr/local/logstash/data
[root@pakho data]# ls
dead_letter_queue queue uuid
修改好的管道配置文件如下:
[root@pakho ~]# vim /usr/local/logstash/config/first-pipeline.conf
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning" #从文件起始开始收集
}
}
filter {
grok { #对web日志进行过滤处理,输出结构化的数据
#在message字段对应的值中查询匹配上COMBINEDAPACHELOG
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout{ }
}
match => {"message" => "%{COMBINEDAPACHELOG}"}的意思是:- 当匹配到
"message"字段时,用户模式"COMBINEDAPACHELOG"进行字段映射
- 当匹配到
- 配置完成后,再次进行验证
[root@pakho logstash]# bin/logstash -f config/first-pipeline.conf
- 下面是输出内容
{
"host" => "pakho",
"auth" => "-",
"timestamp" => "04/Jan/2015:05:13:42 +0000",
"ident" => "-",
"verb" => "GET",
"request" => "/presentations/logstash-monitorama-2013/imageskibana-search.png",
"bytes" => "203023",
"referrer" => "\\"http://semicomplete.com/presentations/logstash-monitorama-2013/\\"",
"@version" => "1",
"agent" => "\\"Mozilla/5.0 (Macintosh; IntelMac OS X 10_9_1) AppleWebKit/537.36 (KHTAL,like Gecko) Chrome/32.0.1700.77 Safari/537.36\\"",
"path" => "/var/log/httpd.log",
"@timestamp" => 2021-07-17T14:31:04.282Z,
"response" => "200",
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \\"GET /presentations/logstash-monitorama-2013/imageskibana-search.png HTTP/1.1\\" 200 203023 \\"http://semicomplete.com/presentations/logstash-monitorama-2013/\\" \\"Mozilla/5.0 (Macintosh; IntelMac OS X 10_9_1) AppleWebKit/537.36 (KHTAL,like Gecko) Chrome/32.0.1700.77 Safari/537.36\\"",
"httpversion" => "1.1",
"clientip" => "83.149.9.216"
}
- 由原来的非结构化数据,变为结构化数据了
- 但是原来的
message字段仍然存在,假如不需要它,可以使用grok中提供的常用选项之一:remove_field来移除这个字段remove_field可以移除任意的字段,它可以接受的值是一个数组rename可以重新命名字段
- 修改后管道配置文件如下:
[root@pakho ~]# vim /usr/local/logstash/config/first-pipeline.conf
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning" #从文件起始开始收集
}
}
filter {
grok { #对web日志进行过滤处理,输出结构化的数据
#在message字段对应的值中查询匹配上COMBINEDAPACHELOG
match => { "message" => "%{COMBINEDAPACHELOG}"} }
mutate {
#重写字段
rename => {
"clientip" => "cip"
}
}
mutate {
#去掉没用字段
remove_field => ["message","input_type","@version","fields"]
}
}
output {
stdout{ }
}
- 配置完成后,增加新日志,再次进行验证
[root@pakho logstash]# bin/logstash -f config/first-pipeline.conf
...
[2021-07-17T22:48:25,567][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
- 下面是输出内容
message不见了,而且clientip重命名为cip!
{
"@timestamp" => 2021-07-17T14:49:42.501Z,
"auth" => "-",
"host" => "pakho",
"timestamp" => "04/Jan/2015:05:13:42 +0000",
"request" => "/presentations/logstash-monitorama-2013/imageskibana-search.png",
"httpversion" => "1.1",
"bytes" => "203023",
"response" => "200",
"agent" => "\\"Mozilla/5.0 (Macintosh; IntelMac OS X 10_9_1) AppleWebKit/537.36 (KHTAL,like Gecko) Chrome/32.0.1700.77 Safari/537.36\\"",
"cip" => "83.149.9.217",
"referrer" => "\\"http://semicomplete.com/presentations/logstash-monitorama-2013/\\"",
"path" => "/var/log/httpd.log",
"ident" => "-",
"verb" => "GET"
}
使用Geoip过滤器插件增强数据编辑**
- 除解析日志数据以进行更好的搜索外,筛选器插件还可以从现有数据中获取补充信息。例如,
geoip插件可以通过查找到IP地址,并从自己自带的数据库中找到地址对应的地理位置信息,然后将该位置信息添加到日志中 - 该
geoip插件配置要求您指定包含IP地址来查找源字段的名称。在此示例中,该clientip字段包含IP地址
geoip {
source => "clientip"
}
- 由于过滤器是按顺序求值的,因此请确保该
geoip部分位于grok配置文件的该部分之后,并且grok和geoip部分都嵌套在 该filter部分中
[root@pakho ~]# vim /usr/local/logstash/config/first-pipeline.conf
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning" #从文件起始开始收集