Python自然语言处理工具包推荐
Posted studyer_domi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python自然语言处理工具包推荐相关的知识,希望对你有一定的参考价值。
结巴分词
就是前面说的中文分词,这里需要介绍的是一个分词效果较好,使用起来像但方便的Python模块:结巴。
结巴中文分词采用的算法
-
基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
-
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
-
对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
结巴中文分词支持的分词模式
目前结巴分词支持三种分词模式:
-
精确模式,试图将句子最精确地切开,适合文本分析;
-
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
-
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
使用方法如下:
# -*- coding:utf-8 -*-import jiebatext = '我来到北京清华大学'default_mode = jieba.cut(text)full_mode = jieba.cut(text,cut_all=True)search_mode = jieba.cut_for_search(text)print("精确模式:","/".join(default_mode))print("全模式:","/".join(full_mode))print("搜索引擎模式:","/".join(search_mode))
返回的数据如下:
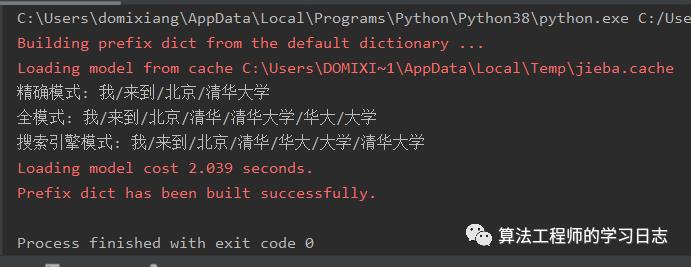
上述代码解释:
-
cut方法接受两个输入参数: 1) 第一个参数为需要分词的字符串 2)cut_all参数用来控制是否采用全模式,默认不采用。
-
cut_for_search方法接受一个参数:需要分词的字符串,该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
-
注意:待分词的字符串可以是gbk字符串、utf-8字符串或者unicode
-
cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(…))转化为list
结巴中文分词的其他功能
1、添加或管理自定义词典
结巴的所有字典内容存放在dict.txt,你可以不断的完善dict.txt中的内容。
2、关键词抽取
通过计算分词后的关键词的TF/IDF权重,来抽取重点关键词。
具体示例:
# -*- coding:utf-8 -*-import jieba.analysetext = "结巴中文分词模块是一个非常好的Python分词组件"tags = jieba.analyse.extract_tags(text,2)print("关键词抽取:","/".join(tags))
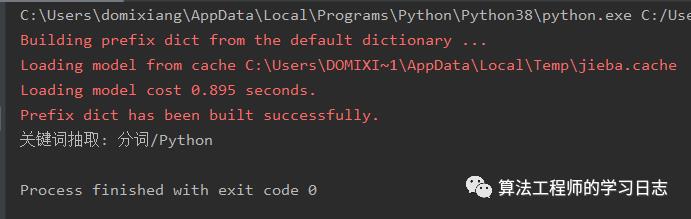
更多信息请查看:https://github.com/fxsjy/jieba/
北大pkuseg
pkuseg简介
pkuseg是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。pkuseg具有如下几个特点:
-
多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。我们目前支持了新闻领域,网络领域,医药领域,旅游领域,以及混合领域的分词预训练模型。在使用中,如果用户明确待分词的领域,可加载对应的模型进行分词。如果用户无法确定具体领域,推荐使用在混合领域上训练的通用模型。各领域分词样例可参考txt。
-
更高的分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
-
支持用户自训练模型。支持用户使用全新的标注数据进行训练。
-
支持词性标注。
相关测试结果:
| MSRA | Precision | Recall | F-score |
| jieba | 87.01 | 89.88 | 88.42 |
| THULAC | 95.60 | 95.91 | 95.71 |
| pkuseg | 96.94 | 96.81 | 96.88 |
| Precision | Recall | F-score | |
| jieba | 87.79 | 87.54 | 87.66 |
| THULAC | 93.40 | 92.40 | 92.87 |
| pkuseg | 93.78 | 94.65 | 94.21 |
| Default | MSRA | CTB8 | PKU | All Average | |
| jieba | 81.45 | 79.58 | 81.83 | 83.56 | 81.61 |
| THULAC | 85.55 | 87.84 | 92.29 | 86.65 | 88.08 |
| pkuseg | 87.29 | 91.77 | 92.68 | 93.43 | 91.29 |
pkuseg的使用
1、使用默认配置进行配置
import pkusegseg = pkuseg.pkuseg() # 以默认配置加载模型text = seg.cut('我爱北京天安门') # 进行分词print(text)
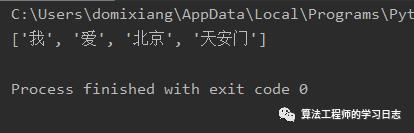
2、使用细分领域分词(如果用户明确分词领域,推荐使用细领域模型分词)
import pkusegseg = pkuseg.pkuseg(model_name='medicine') # 程序会自动下载所对应的细领域模型text = seg.cut('我爱北京天安门') # 进行分词print(text)
3、分词同时进行词性标注,各词性标签的详细含义可参考 tags.txt
import pkusegseg = pkuseg.pkuseg(postag=True) # 开启词性标注功能text = seg.cut('我爱北京天安门') # 进行分词和词性标注print(text)
4、对文件分词
import pkuseg# 对input.txt的文件分词输出到output.txt中# 开8个进程pkuseg.test('input.txt', 'output.txt', nthread=8)
5、额外使用用户自定义词典
import pkusegseg = pkuseg.pkuseg(user_dict='my_dict.txt') # 给定用户词典为当前目录下的"my_dict.txt"text = seg.cut('我爱北京天安门')print(text)
模型配置:
pkuseg.pkuseg(model_name = "default", user_dict = "default", postag = False)model_name 模型路径。"default",默认参数,表示使用我们预训练好的混合领域模型(仅对pip下载的用户)。"news", 使用新闻领域模型。"web", 使用网络领域模型。"medicine", 使用医药领域模型。"tourism", 使用旅游领域模型。model_path, 从用户指定路径加载模型。user_dict 设置用户词典。"default", 默认参数,使用我们提供的词典。None, 不使用词典。dict_path, 在使用默认词典的同时会额外使用用户自定义词典,可以填自己的用户词典的路径,词典格式为一行一个词。postag 是否进行词性分析。False, 默认参数,只进行分词,不进行词性标注。True, 会在分词的同时进行词性标注。
对文件进行分词:
pkuseg.test(readFile, outputFile, model_name = "default", user_dict = "default", postag = False, nthread = 10)readFile 输入文件路径。outputFile 输出文件路径。model_name 模型路径。同pkuseg.pkuseguser_dict 设置用户词典。同pkuseg.pkusegpostag 设置是否开启词性分析功能。同pkuseg.pkusegnthread 测试时开的进程数。
模型训练:
pkuseg.train(trainFile, testFile, savedir, train_iter = 20, init_model = None)trainFile 训练文件路径。testFile 测试文件路径。savedir 训练模型的保存路径。train_iter 训练轮数。init_model 初始化模型,默认为None表示使用默认初始化,用户可以填自己想要初始化的模型的路径如init_model='./models/'。
pkuseg实战
使用pkuseg 分词+使用wordcloud显示词云:
import pkusegfrom collections import Counterimport pprintfrom wordcloud import WordCloudimport matplotlib.pyplot as pltwith open("data/santisanbuqu_liucixin.txt", encoding="utf-8") as f:content = f.read()with open("data/CNENstopwords.txt", encoding="utf-8") as f:stopwords = f.read()lexicon = ['章北海', '汪淼', '叶文洁']seg = pkuseg.pkuseg(user_dict=lexicon)text = seg.cut(content)new_text = []for w in text:if w not in stopwords:new_text.append(w)counter = Counter(new_text)pprint.pprint(counter.most_common(50))cut_text = " ".join(new_text)wordcloud = WordCloud(font_path="font/FZYingXueJW.TTF", background_color="white", width=800, height=600).generate(cut_text)plt.imshow(wordcloud, interpolation="bilinear")plt.axis("off")plt.show()

参考链接:https://github.com/lancopku/pkuseg-python

以上是关于Python自然语言处理工具包推荐的主要内容,如果未能解决你的问题,请参考以下文章