小胖坐我电动车后坐搂着我腰,问我:Redis 主从复制原理是怎样的?
Posted king哥Java架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小胖坐我电动车后坐搂着我腰,问我:Redis 主从复制原理是怎样的?相关的知识,希望对你有一定的参考价值。
00 前言
我负责我司的报表系统,小胖是我小弟。随着业务量的增加,单实例顶不住,我就搭建了多个 Redis 实例,实现主从模式。
好学的小胖就问我啊,秃头哥,多实例之间的数据是怎么保持同步的呀?你教教我好不好嘛~
我拿起手中 82 年的开水抿了一口,跟小胖说:你先看这篇文章,学会了操作,我再给你讲讲原理吧。
老规矩,还是先上脑图:(PS:文末有我准备的大厂面试题)
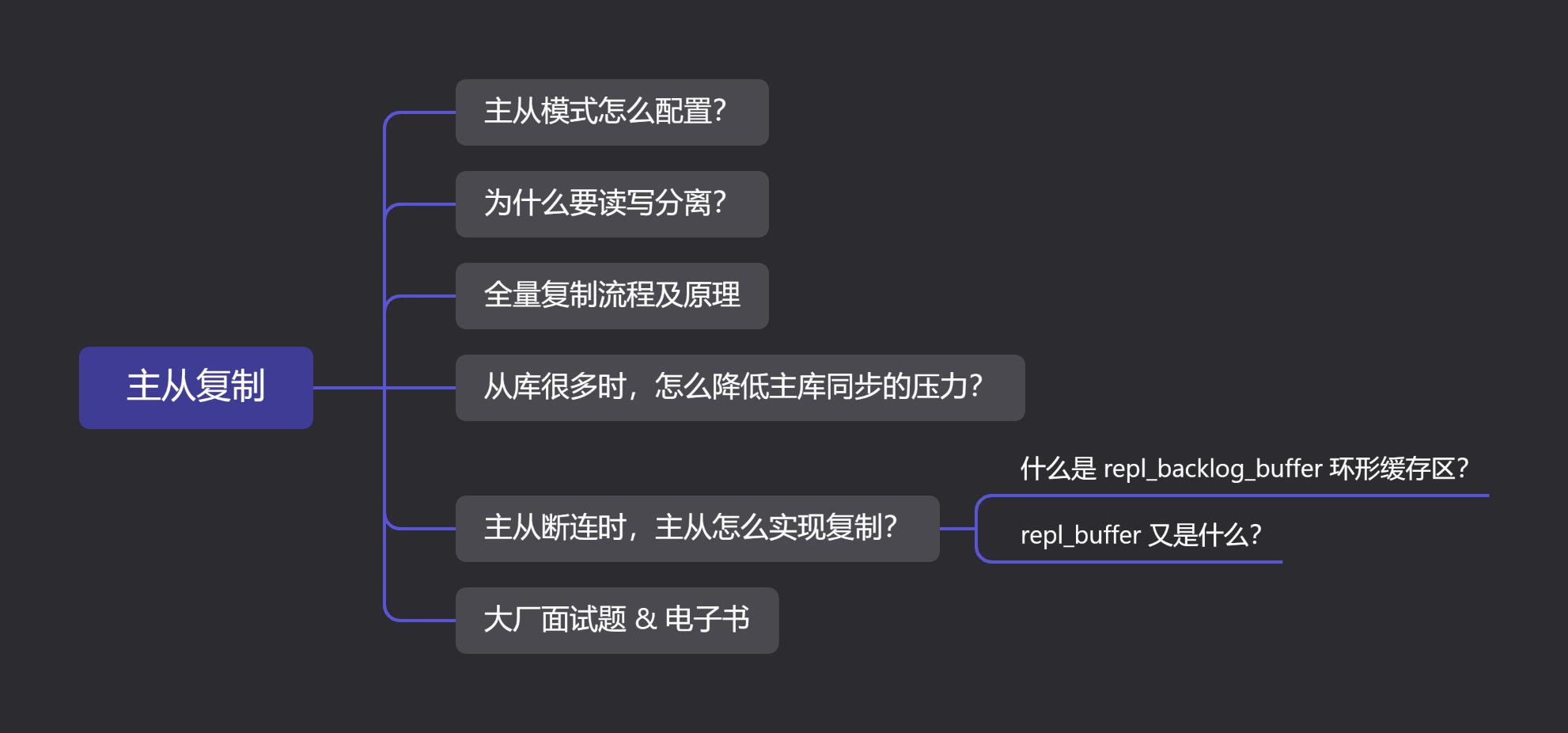
01 主从复制
Redis 的高可靠主要由两点保证,一是数据尽量少丢失,二是服务尽量少中断。持久化保证了第一点;而第二点则由 Redis 集群保证,Redis 的做法就是多实例保持数据同步。
1.1 读写分离
Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。
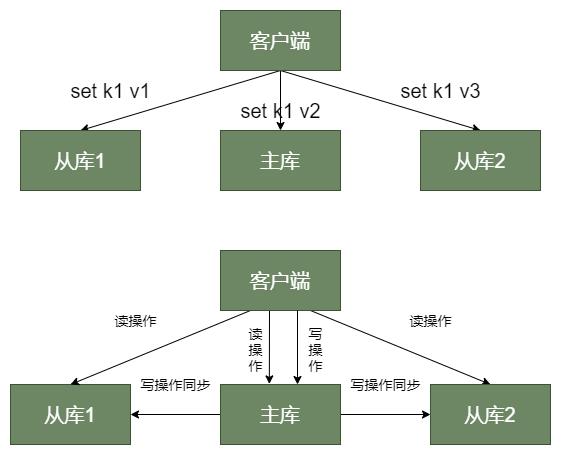
为什么要读写分离呢?
看看上图,如果所有库都可以写,那将会发生一个 key 在不同实例就有不同的值。比如上图对应的键 k1 在不同实例就有不同的 v1、v2、v3 值,这是绝对不能接受的。
有人说,,可以加锁呀
但是这会涉及到加锁、实例间协商是否完成修改等一堆操作,带来巨额的开销,Redis 以快著称,这也是不能接受的。
那咋办呀?读写分离咯
主从库模式采用读写分离,所有数据修改只会在主库进行。主库有最新数据,会同步给从库,这样,主从库的数据就是一致的。
问题就在同步了,主从库之间是怎么同步的呢?一起来探讨下
1.2 全量复制
当我们启动多个 Redis 实例的时候,它们相互之间就通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
比如现在有实例1(127.0.0.1)和实例2(127.0.0.2),在实例 2 执行 replicaof 后,实例 2 就变成实例 1 的从库啦。
replicaof 127.0.0.2 6379
建立关系之后,Redis 会进行第一次全量复制。过程如下:
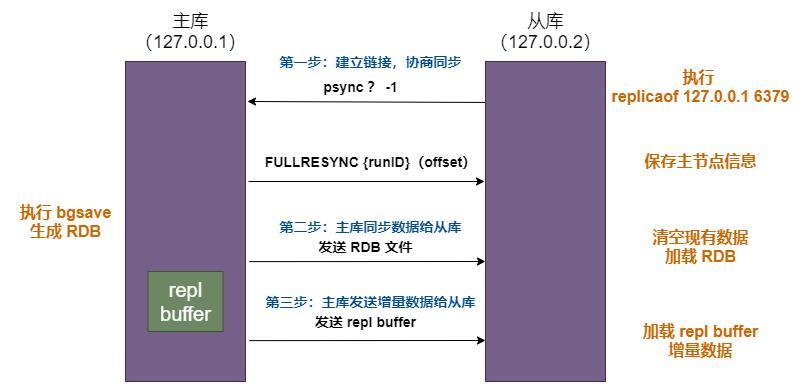
第一步,主从库建立连接、协商同步的过程,主要是为全量复制做准备。
从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。
- runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为 “?”。
- offset,此时设为 -1,表示第一次复制。主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。
FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
第二步,主库执行 bgsave 命令,生成 RDB 文件,发送给从库。从库收到后,先清空自己的数据(避免主从不一致),在本地完成数据加载。
主库在将数据同步给从库的过程中,仍然可以正常接收请求。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。
为了保证主从一致性,主库会在内存中用 replication buffer 记录 RDB 文件生成后收到的所有写操作。
第三步,主库会把 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。如此,主从就实现了同步。
1.3 主从级联分散压力
以上还有个问题:如果直接跟主库建立关系的从库非常多,那么主库会 fork 很多线程去生成 RDB 和 发送 RDB 文件,这将会造成主库阻塞。那咋办?
主从级联的模式就来了:选一个资源较多的实例作为级联的从库,作为叶子节点的从库执行以下命令将所选从库作为主库,这样就形成了级联关系。
replicaof 所选从库的IP 6379
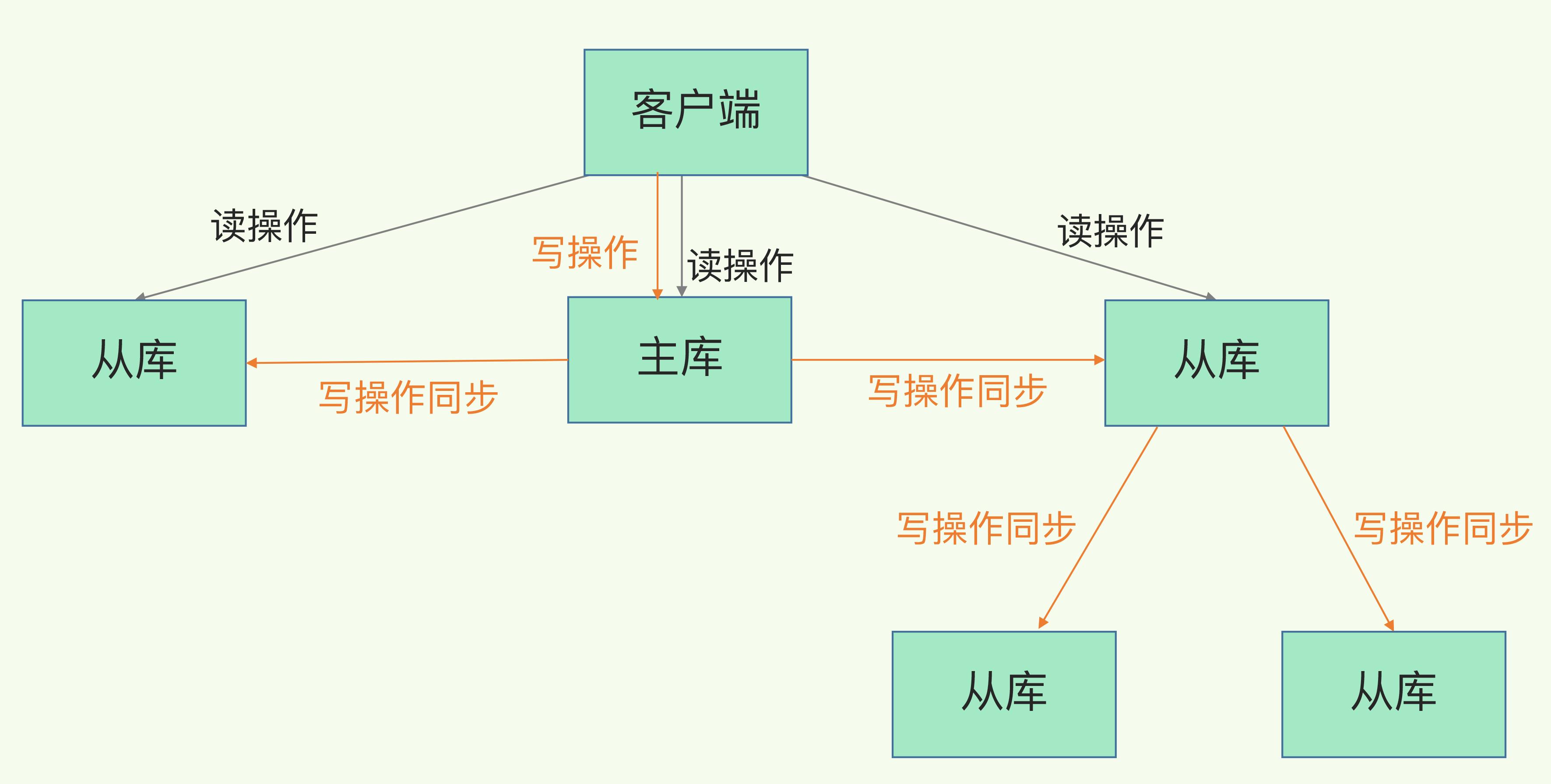
如上图,主库就跟两个实例做主从关系,从库又跟另外的从库建立主从关系,类似于树结构。如此,主库便可减少压力。
就上图来说,主库原来要跟 4 个从库建立主从关系;加了级联之后,只需要建立两个主从关系,剩下的由某一个从库去承担。这颇有点父养子,子又养子的意思。
这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
1.4 增量复制
细想一下,上面的主从复制还有问题:如果主从之间的网络断开了咋办?
其实 Redis 2.8 之前,主从断开了,做的是全量复制。但这种方式开销太大,已被淘汰。2.8 之后的 Redis 采用的是增量复制。
增量复制依赖一个环形缓冲区 repl_backlog_buffer(只要有从库存在,就会有这个缓存区),主从断连后,主库会把断连期间的写操作命令,写入 repl_backlog_buffer 缓冲区。repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
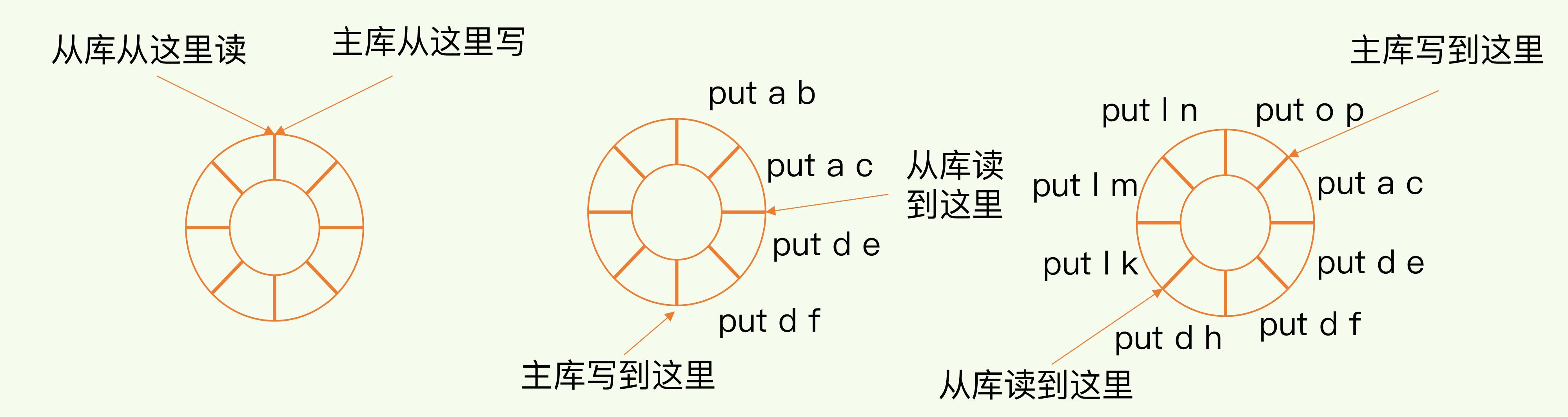
如上图所示,还没断连时,主从指向同一个位置;主库写,从库读,一直往前走。突然,断连了,从库没法写、主库继续读。
恢复连接后,从库发送 psync {runID}{offset} 告诉主库,自己上次读到哪。主库通过 offset 在 repl_backlog_buffer 中找到从库断开的位置,主从之间的偏移量就是增量复制需要同步的内容。比如上图的 put d e 和 put d f 两个操作。
把这部分增量数据复制到 repl_buffer 中,主库再发送给从库读入。
基于此增量复制的整个流程是这样的:
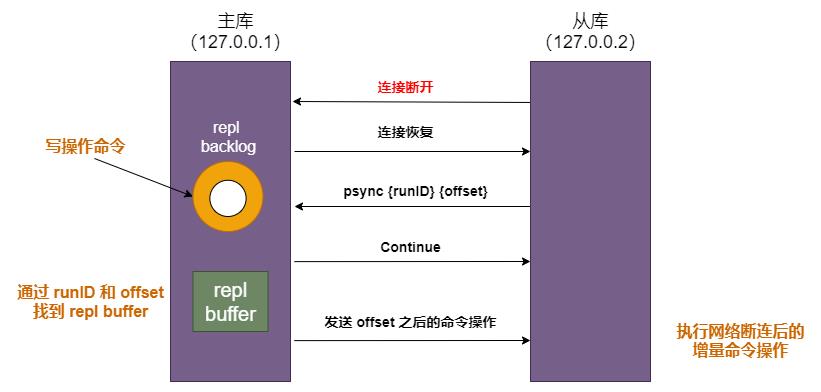
你可能也发现了?repl_backlog_buffer 是环形缓存区,如果从库断开时间太久,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。这该咋办呀?
连接恢复后,主库根据从库上次读到的 offset 位置判断是否被覆盖?如果是,从库连上主库后也只能乖乖地进行一次全量同步。
为了避免全量同步,可以通过参数 repl_backlog_size 设置 repl_backlog_buffer 的大小,把它弄大点。
计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小
repl_backlog_size = 缓冲空间大小 * 2
这样一来,发生全量同步的概率就小了很多了。
一直想整理出一份完美的面试宝典,但是时间上一直腾不开,这套一千多道面试题宝典,结合今年金三银四各种大厂面试题,以及 GitHub 上 star 数超 30K+ 的文档整理出来的,我上传以后,毫无意外的短短半个小时点赞量就达到了 13k,说实话还是有点不可思议的。
一千道互联网 Java 工程师面试题
内容涵盖:Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、Redis、mysql、Spring、SpringBoot、SpringCloud、RabbitMQ、Kafka、Linux等技术栈(485页)
初级—中级—高级三个级别的大厂面试真题
阿里云——Java 实习生/初级
List 和 Set 的区别 HashSet 是如何保证不重复的
HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
HashMap 的扩容过程
HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
对象的四种引用
Java 获取反射的三种方法
Java 反射机制
Arrays.sort 和 Collections.sort 实现原理 和区别
Cloneable 接口实现原理
异常分类以及处理机制
wait 和 sleep 的区别
数组在内存中如何分配
答案展示:


美团——Java 中级
BeanFactory 和 ApplicationContext 有什么区别
Spring Bean 的生命周期
Spring IOC 如何实现
说说 Spring AOP
Spring AOP 实现原理
动态代理(cglib 与 JDK)
Spring 事务实现方式
Spring 事务底层原理
如何自定义注解实现功能
Spring MVC 运行流程
Spring MVC 启动流程
Spring 的单例实现原理
Spring 框架中用到了哪些设计模式
为什么选择 Netty
说说业务中,Netty 的使用场景
原生的 NIO 在 JDK 1.7 版本存在 epoll bug
什么是 TCP 粘包/拆包
TCP 粘包/拆包的解决办法
Netty 线程模型
说说 Netty 的零拷贝
Netty 内部执行流程
答案展示:


蚂蚁金服——Java 高级
题 1:
jdk1.7 到 jdk1.8 Map 发生了什么变化(底层)?
ConcurrentHashMap
并行跟并发有什么区别?
jdk1.7 到 jdk1.8 java 虚拟机发生了什么变化?
如果叫你自己设计一个中间件,你会如何设计?
什么是中间件?
ThreadLock 用过没有,说说它的作用?
Hashcode()和 equals()和==区别?
mysql 数据库中,什么情况下设置了索引但无法使用?
mysql 优化会不会,mycat 分库,垂直分库,水平分库?
分布式事务解决方案?
sql 语句优化会不会,说出你知道的?
mysql 的存储引擎了解过没有?
红黑树原理?
题 2:
说说三种分布式锁?
redis 的实现原理?
redis 数据结构,使⽤场景?
redis 集群有哪⼏种?
codis 原理?
是否熟悉⾦融业务?记账业务?蚂蚁⾦服对这部分有要求。
好啦~展示完毕,大概估摸一下自己是青铜还是王者呢?
前段时间,在和群友聊天时,把今年他们见到的一些不同类别的面试题整理了一番,于是有了以下面试题集,也一起分享给大家~
如果你觉得这些内容对你有帮助,可以加入csdn进阶交流群,领取资料
基础篇


JVM 篇

MySQL 篇



Redis 篇



由于篇幅限制,详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
需要的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于小胖坐我电动车后坐搂着我腰,问我:Redis 主从复制原理是怎样的?的主要内容,如果未能解决你的问题,请参考以下文章