常见的链表翻转,字节跳动加了个条件,面试者高呼:我太难了!
Posted king哥Java架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见的链表翻转,字节跳动加了个条件,面试者高呼:我太难了!相关的知识,希望对你有一定的参考价值。

一. 序
我又来讲链表题了,这道题据说是来自字节跳动的面试题。
为什么说是「据说」呢?因为我也是看来的,觉得题目还是挺有意思,但是原作者给出的方案,我想了想觉得还有优化空间,就单独拿出来讲讲。
例如今天要讲的这道题。
给定单链表的头结点 head,实现一个调整链表的函数,从链表尾部开始,以 K 个结点为一组进行逆序翻转,头部剩余结点不足一组时,不需要翻转。(不能使用队列或者栈作为辅助)
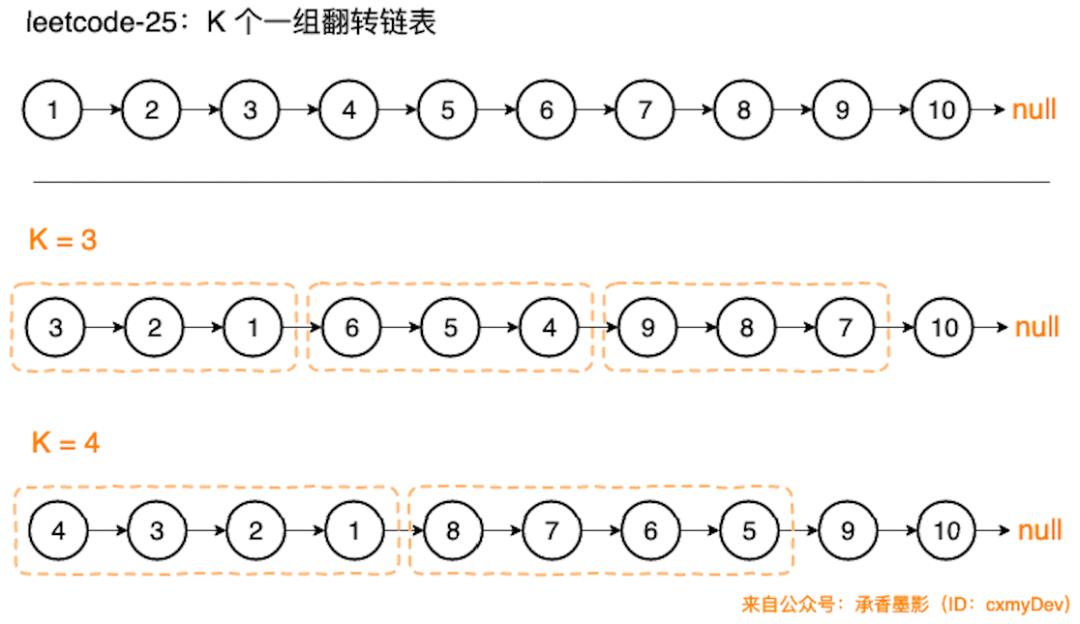
leetcode-25 是从头结点开始,以 K 个结点一组进行翻转。而字节跳动这道题,是从尾结点开始。
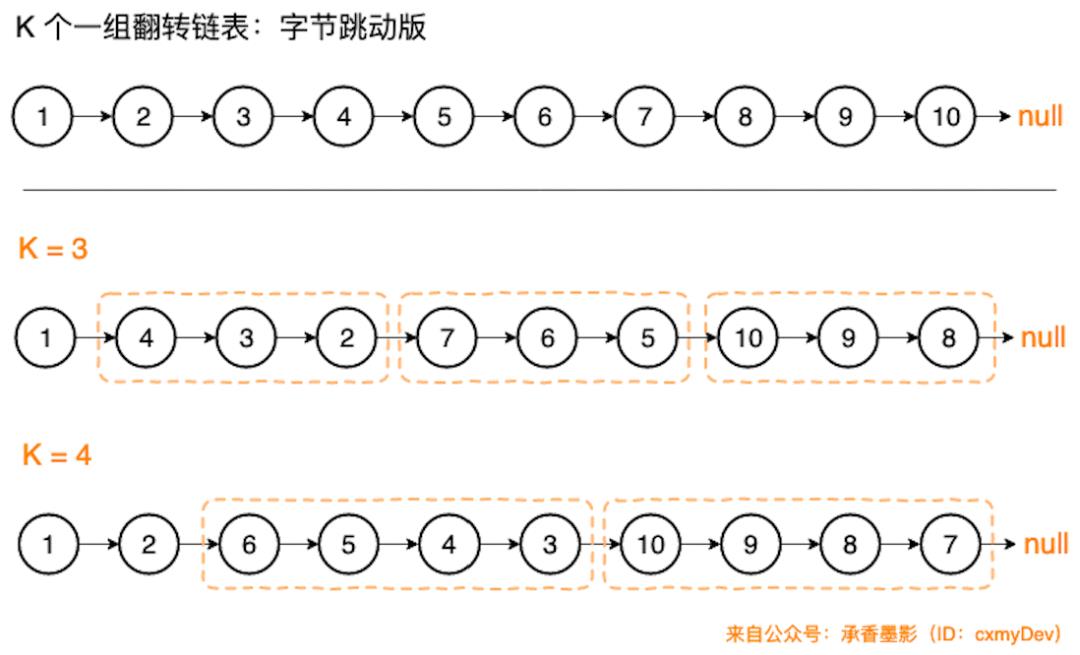
只是多了一个从尾结点开始分组翻转的条件,这道题的难度就增加了。
二. K个一组翻转链表(头条版)
2.1 其他人的解题思路
前面也说到,这道题是我看来的,当时是以一篇文章的形式发布出来。
文章我就不发了,不过先了解一下他的解题思路,有助于我们思考。
他的思路很清晰,虽然这道题他不会解,但是 leetcode-25 这个标准的以 K 个一组翻转链表的题他很熟悉。
那么可以先将原始链表,进行一次「链表翻转」,再进行「K 个一组翻转链表」,最后再做一次「链表翻转」还原链表,就得出了需要的结果。
ListNode revserseKGroupPlus(ListNode head, int k) {
// 翻转链表
head = reverseList(head);
// K 个一组翻转链表
head = reverseKGroup(head, k);
// 翻转链表
head = reverseList(head);
return head;
}
把一个不熟悉的问题,经过简单的转换,变成熟悉的问题进行解决,这种思路是没有错的。
但是呢,有个问题–
在面试的场景中,通常来说,面试官的水平会高于面试者,那么我们可以简单的理解,面试就是一个不断受挫的过程,这个过程总会被问到我们知识的边界才会停止。
面试题只是起点,面试过程中深挖的那些问题,才是触摸到我们谈薪资本的核心。当然这扯远了,继续回到本文的内容。
此时就算面试者当场写出了解题代码,也逃不开一个经典问题。
面试官:「还有更优的方案吗?」
那么这道题,有没有更优的方案?答案当然是有的。
2.2 更优一点的方案
将链表先翻转后处理,再翻转回去,这样并不优雅,其实只需一次以 K 个一组翻转链表就可以。
再回忆一下 leetcode 第 25 题,它和这道题的差异,主要来自于,对不足一组的链表结点的处理。leetcode-25 是从头结点开始处理,所以多出来的结点会在尾部,而字节跳动这道题则正好相反,余下的结点会在头部。
但是它们同时也有一种特殊情况,就是 K 个一组进行分组时,这里的 K 正好可以完整的分组,一个不多,一个不少的分成 N 组。
当链表结点数量正好为 K * N 时,那么就又回到了我们熟悉的 leetcode-25 题了。
如果我们先将原始结点进行处理,找出它正好可以整除 K 的起始结点 offset,将这个起始结点 offset 的子链表,进行 K 个一组进行翻转链表,最后把它拼接回原始链表,就完成了这道题。
这个过程,需要额外定义两个结点,第一个满足 K 个分组条件的 offset 结点,以及 offset 的前驱结点 prev 结点,prev 结点主要是用来拼接翻转后的两个链表,让其不会出现链表断裂的问题。
它们的关系如下:
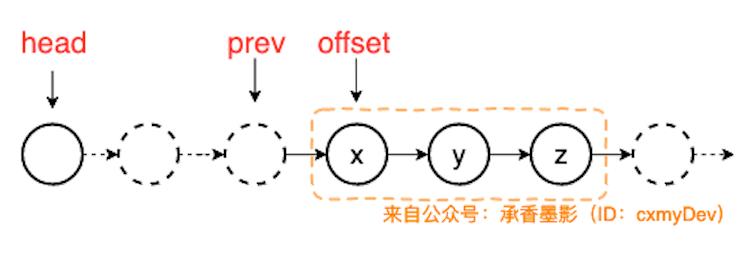
这其中还涉及到一些简单的链表运算,例如求链表的长度,这里就不展开说了,直接上核心代码,逻辑都在注释里,我们先定义一个 reverseKGroupPlus() 方法。
public ListNode reverseKGroupPlus(ListNode head, int k) {
if (head == null || k <= 1) return head;
// 计算原始链表长度
int length = linkedLength(head);
if (length < k)
return head;
// 计算 offset
int offsetIndex = length % k;
// 原始链表正好可以由 K 分为 N 组,可直接处理
if (offsetIndex == 0) {
return reverseKGroup(head, k);
}
// 定义并找到 prev 和 offset
ListNode prev = head, offset = head;
while (offsetIndex > 0) {
prev = offset;
offset = offset.next;
offsetIndex--;
}
// 将 offset 结点为起始的子链表进行翻转,再拼接回主链表
prev.next = reverseKGroup(offset, k);
return head;
}
注意当链表长度正好可以用 K 分为 N 组时,我们直接处理,否者才需要后续复杂的逻辑。
代码的注释足够清晰了,在脑子里过一遍代码的执行流程应该能明白,为了帮助大家理解,我又画了个示意图。
假设以 head 为头结点的链表长度是 10,K 为 4 时,那么计算下来 offset Index 就是 2。
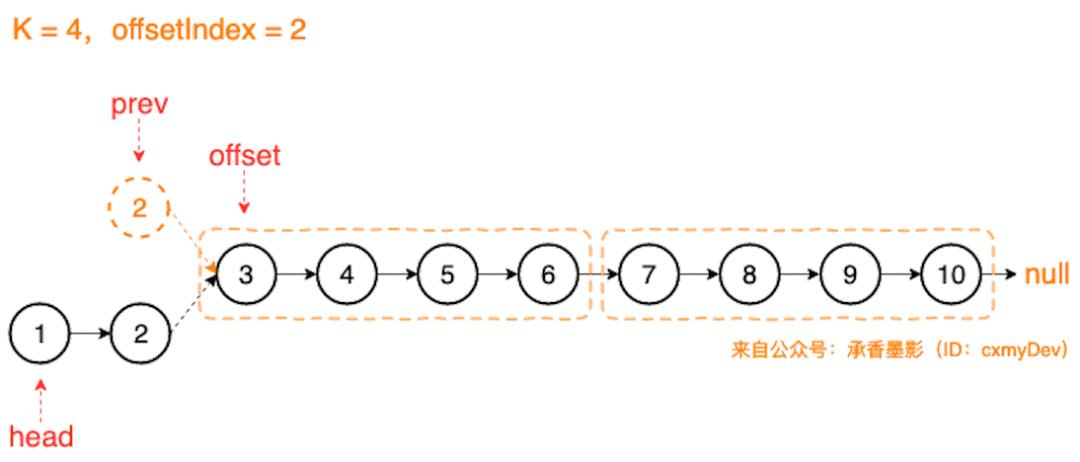
找到 prev 和 offset 结点后,就可以将以 offset 结点为头结点的子链表,进行 K 个一组翻转链表的操作了。
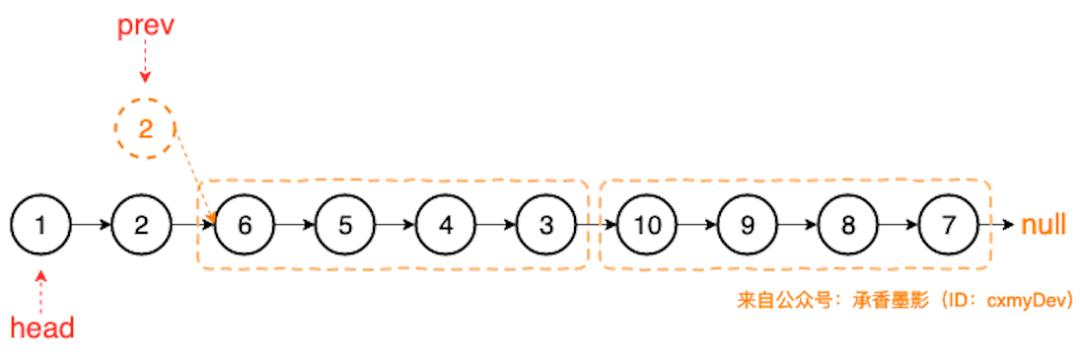
此时,head 结点为起始的链表,就是我们计算后的结果。
2.3 再补一些额外的代码
这道题,还涉及到很多其他的小算法,本身 leetcode-25 就已经被定级为「困难」,字节跳动在这道题的基础上,又增加了难度。
为了保证解题的完整,这里再补充一些相关代码。
1. 计算链表长度
private int linkedLength(ListNode head) {
int count = 0;
while (head != null) {
count++;
head = head.next;
}
return count;
}
没什么好说的,一个 while 循环搞定。
2. 以 K 个一组翻转链表
这道题在之前的文章中详细讲解了,这里直接贴代码了。
public ListNode reverseKGroup(ListNode head, int k) {
// 增加虚拟头结点
ListNode dummy = new ListNode(0);
dummy.next = head;
// 定义 prev 和 end 结点
ListNode prev = dummy;
ListNode end = dummy;
while(end.next != null) {
// 以 k 个结点为条件,分组子链表
for (int i = 0; i < k && end != null; i++)
end = end.next;
// 不足 K 个时不处理
if (end == null)
break;
// 处理子链表
ListNode start = prev.next;
ListNode next = end.next;
end.next = null;
// 翻转子链表
prev.next = reverseList(start);
// 将子连表前后串起来
start.next = next;
prev = start;
end = prev;
}
return dummy.next;
}
// 递归完成单链表翻转
private ListNode reverseList(ListNode head) {
if (head == null || head.next == null)
return head;
ListNode p = reverseList(head.next);
head.next.next = head;
head.next = null;
return p;
}
一直想整理出一份完美的面试宝典,但是时间上一直腾不开,这套一千多道面试题宝典,结合今年金三银四各种大厂面试题,以及 GitHub 上 star 数超 30K+ 的文档整理出来的,我上传以后,毫无意外的短短半个小时点赞量就达到了 13k,说实话还是有点不可思议的。
一千道互联网 Java 工程师面试题
内容涵盖:Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、Redis、mysql、Spring、SpringBoot、SpringCloud、RabbitMQ、Kafka、Linux等技术栈(485页)
初级—中级—高级三个级别的大厂面试真题
阿里云——Java 实习生/初级
List 和 Set 的区别 HashSet 是如何保证不重复的
HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
HashMap 的扩容过程
HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
对象的四种引用
Java 获取反射的三种方法
Java 反射机制
Arrays.sort 和 Collections.sort 实现原理 和区别
Cloneable 接口实现原理
异常分类以及处理机制
wait 和 sleep 的区别
数组在内存中如何分配
答案展示:


美团——Java 中级
BeanFactory 和 ApplicationContext 有什么区别
Spring Bean 的生命周期
Spring IOC 如何实现
说说 Spring AOP
Spring AOP 实现原理
动态代理(cglib 与 JDK)
Spring 事务实现方式
Spring 事务底层原理
如何自定义注解实现功能
Spring MVC 运行流程
Spring MVC 启动流程
Spring 的单例实现原理
Spring 框架中用到了哪些设计模式
为什么选择 Netty
说说业务中,Netty 的使用场景
原生的 NIO 在 JDK 1.7 版本存在 epoll bug
什么是 TCP 粘包/拆包
TCP 粘包/拆包的解决办法
Netty 线程模型
说说 Netty 的零拷贝
Netty 内部执行流程
答案展示:


蚂蚁金服——Java 高级
题 1:
jdk1.7 到 jdk1.8 Map 发生了什么变化(底层)?
ConcurrentHashMap
并行跟并发有什么区别?
jdk1.7 到 jdk1.8 java 虚拟机发生了什么变化?
如果叫你自己设计一个中间件,你会如何设计?
什么是中间件?
ThreadLock 用过没有,说说它的作用?
Hashcode()和 equals()和==区别?
mysql 数据库中,什么情况下设置了索引但无法使用?
mysql 优化会不会,mycat 分库,垂直分库,水平分库?
分布式事务解决方案?
sql 语句优化会不会,说出你知道的?
mysql 的存储引擎了解过没有?
红黑树原理?
题 2:
说说三种分布式锁?
redis 的实现原理?
redis 数据结构,使⽤场景?
redis 集群有哪⼏种?
codis 原理?
是否熟悉⾦融业务?记账业务?蚂蚁⾦服对这部分有要求。
好啦~展示完毕,大概估摸一下自己是青铜还是王者呢?
前段时间,在和群友聊天时,把今年他们见到的一些不同类别的面试题整理了一番,于是有了以下面试题集,也一起分享给大家~
如果你觉得这些内容对你有帮助,可以加入csdn进阶交流群,领取资料
基础篇


JVM 篇

MySQL 篇



Redis 篇



由于篇幅限制,详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
需要的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于常见的链表翻转,字节跳动加了个条件,面试者高呼:我太难了!的主要内容,如果未能解决你的问题,请参考以下文章