(转)真刀真枪压测:基于TCPCopy的仿真压测方案
Posted jfcat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(转)真刀真枪压测:基于TCPCopy的仿真压测方案相关的知识,希望对你有一定的参考价值。
本文档适用人员:技术人员
提纲:
- 为什么要做仿真测试
- TCPCopy是如何工作的
- 实作:仿真测试的拓扑
- 实作:操作步骤
- 可能会遇到的问题
- ip_conntrack
- 少量丢包
- 离线重放
- 不提取7层信息
- 观测的性能指标
0x00,为什么要做仿真测试
线下的传统压力测试,难以模拟真实流量,尤其难以模拟正常流量混杂着各色异常流量。所以,线下压得好好的系统,上线后可能某天突然雪崩,说好能支撑 5 倍流量的系统重构,也许流量一翻倍就彻底挂了。
但办法总比问题多。
系统重构或重要变更上线前,可以拷贝线上真实流量,实时模拟线上流量,甚至可以放大真实流量,进行压力测试,以评估系统承载能力。
反过来也可以这样,如果线上跑着跑着发现有性能瓶颈,但线下环境难以复现,还不如把真实流量拷贝到线下重放,毕竟线下环境便于上各种排查手段,重放几遍都行,直到找到问题。
所以本次基于 Varnish 的商品详情页静态化在上线前,做了仿真压测。
如何实时拷贝线上真实流量呢?
TCPCopy。
2010年,网易技术部的王斌在王波的工作基础上开发了 TCPCopy - A TCP Stream Replay Tool。2011年9月开源。当前版本号是 1.0.0。很多公司的模拟在线测试都是基于 TCPCopy 做的,如一淘。
TCPCopy 是一种请求复制(复制基于 TCP 的 packets)工具 ,通过复制在线数据包,修改 TCP/IP 头部信息,发送给测试服务器,达到欺骗测试服务器的TCP 程序的目的,从而为欺骗上层应用打下坚实基础。
0x01,TCPCopy是如何工作的
王斌讲过,基于 Server 的请求回放领域,一般分为离线回放和在线实时复制两种。
其中请求实时复制,一般可以分为两类:
1)基于应用层的请求复制 ,
2)基于底层数据包的请求复制。
如果从应用层面进行复制,比如基于服务器的请求复制,实现起来相对简单,但也存在着若干缺点:
1)请求复制从应用层出发,穿透整个协议栈,这样就容易挤占应用的资源,比如宝贵的连接资源 ,
2)测试跟实际应用耦合在一起,容易影响在线系统,
3)也因此很难支撑压力大的请求复制,
4)很难控制网络延迟。
而基于底层数据包的请求复制,可以做到无需穿透整个协议栈,路程最短的,可以从数据链路层抓请求包,从数据链路层发包,路程一般的,可以在IP层抓请求包,从IP层发出去,不管怎么走,只要不走TCP,对在线的影响就会小得多。这也就是 TCPCopy 的基本思路。
从传统架构的 rawsocket+iptable+netlink,到新架构的 pacp+route,它经历了三次架构调整,现如今的 TCPCopy 分为三个角色:
- Online Server(OS):上面要部署 TCPCopy,从数据链路层(pcap 接口)抓请求数据包,发包是从IP层发出去;
- Test Server(TS):最新的架构调整把 intercept 的工作从 TS 中 offload 出来。TS 设置路由信息,把 被测应用 的需要被捕获的响应数据包信息路由到 AS;
- Assistant Server(AS):这是一台独立的辅助服务器,原则上一定要用同网段的一台闲置服务器来充当辅助服务器。AS 在数据链路层截获到响应包,从中抽取出有用的信息,再返回给相应的 OS 上的 tcpcopy 进程。
请配合下图1理解:
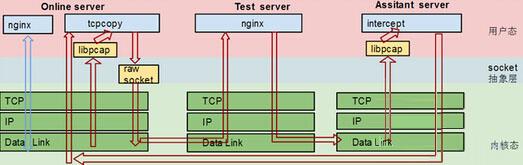
图1 三个角色的数据流转方式
Online Server 上的抓包:
tcpcopy 的新架构在 OS 上抓请求数据包默认采用 raw socket input 接口抓包。王斌则推荐采用 pcap 抓包,安装命令如下:
./configure --enable-advanced --enable-pcap
make
make install
这样就可以在内核态进行过滤,否则只能在用户态进行包的过滤,而且在 intercept 端或者 tcpcopy 端设置 filter(通过 -F 参数,类似 tcpdump 的 filter),达到起多个实例来共同完成抓包的工作,这样可扩展性就更强,适合于超级高并发的场合。
为了便于理解 pcap 抓包,下面简单描述一下 libpcap 的工作原理。
一个包的捕捉分为三个主要部分:
- 面向底层包捕获,
- 面向中间层的数据包过滤,
- 面向应用层的用户接口。
这与 Linux 操作系统对数据包的处理流程是相同的(网卡->网卡驱动->数据链路层->IP层->传输层->应用程序)。包捕获机制是在数据链路层增加一个旁路处理(并不干扰系统自身的网络协议栈的处理),对发送和接收的数据包通过Linux内核做过滤和缓冲处理,最后直接传递给上层应用程序。如下图2所示:
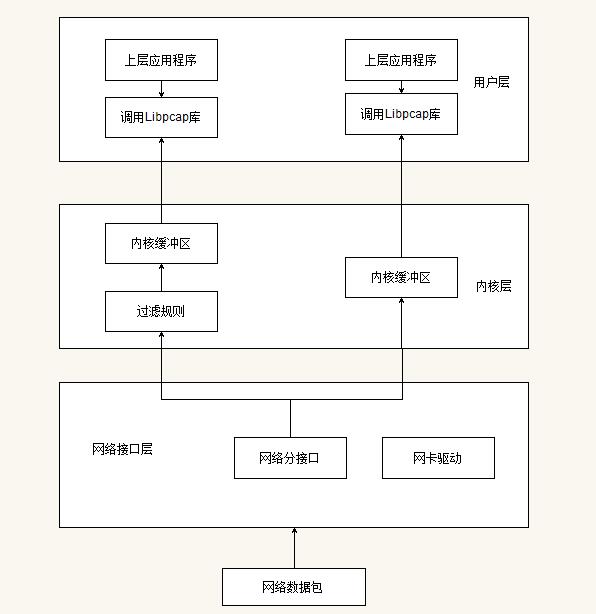
图2 libpcap的三部分
Online Server 上的发包:
如图1所示,新架构和传统架构一样,OS 默认使用 raw socket output 接口发包,此时发包命令如下:
./tcpcopy -x 80-测试机IP:测试机应用端口 -s 服务器IP -i eth0
其中 -i 参数指定 pcap 从哪个网卡抓取请求包。
此外,新架构还支持通过 pcap_inject(编译时候增加--enable-dlinject)来发包。
Test Server 上的响应包路由:
需要在 Test Server 上添加静态路由,确保被测试应用程序的响应包路由到辅助测试服务器,而不是回包给 Online Server。
Assistant Server 上的捕获响应包:
辅助服务器要确保没有开启路由模式 cat /proc/sys/net/ipv4/ip_forward,为0表示没有开启。
辅助服务器上的 intercept 进程通过 pcap 抓取测试机应用程序的响应包,将头部抽取后发送给 Online Server 上的 tcpcopy 进程,从而完成一次请求的复制。
0x02,实作:仿真测试的拓扑
下面将列出本次仿真测试的线上环境拓扑图。
环境如下:
- Online Server
- 4个生产环境 nginx
- 172.16.***.110
- 172.16.***.111
- 172.16.***.112
- 172.16.***.113
- 4个生产环境 nginx
- Test Server
- 一个镜像环境的 Nginx
- 172.16.***.52
- 一个镜像环境的 Nginx
- Assistant Server
- 镜像环境里的一台独立服务器
- 172.16.***.53
- 镜像环境里的一台独立服务器
拓扑如图3所示:
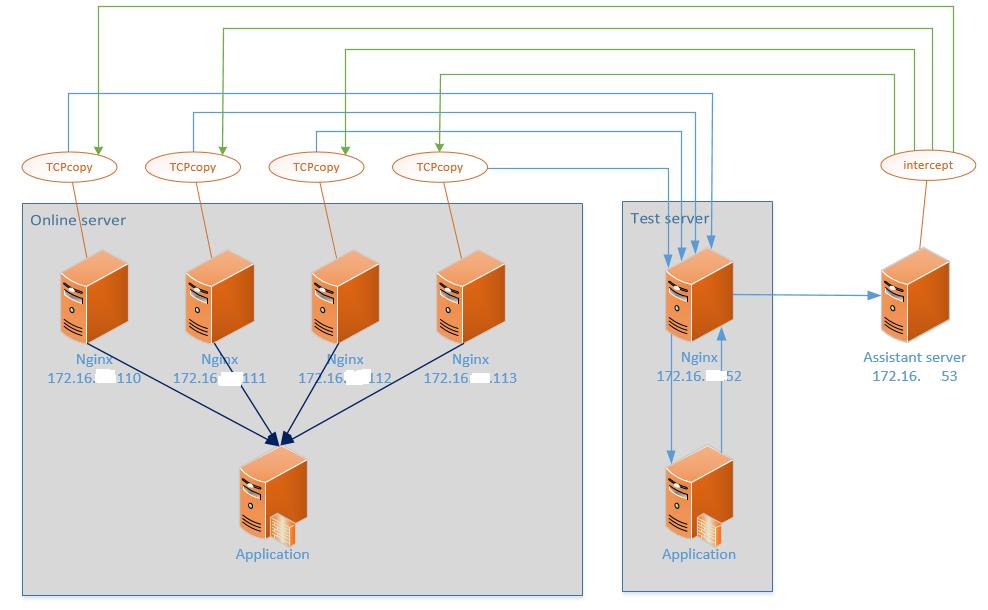
图3 压测环境拓扑
它的数据流转顺序如下图4所示:
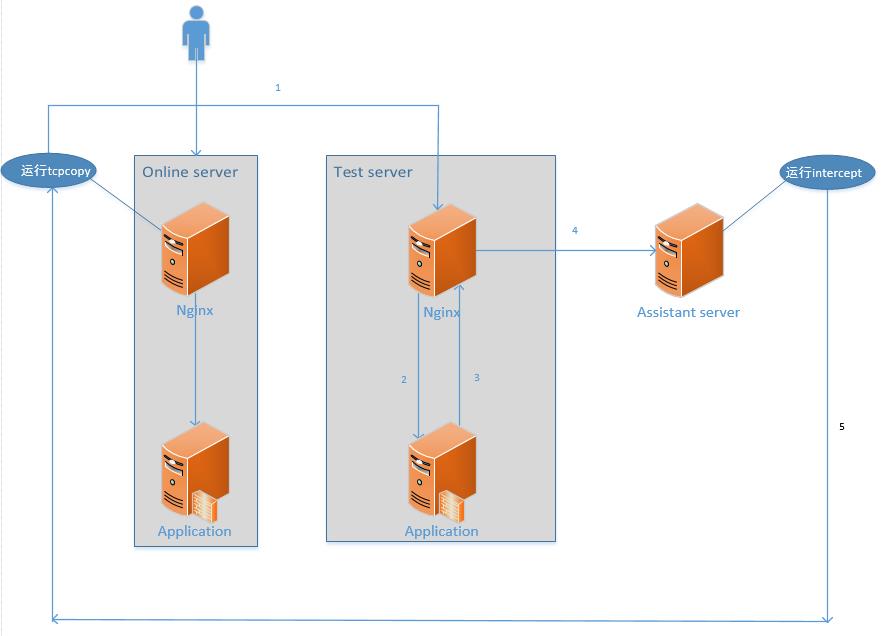
图4 压测环境的数据流转顺序
0x03,实作:操作步骤
下面分别列出在 Online Server/Test Server/Assistant Server 上的操作步骤。
3.1 Online Server 上的操作:
下载并安装 tcpcopy 客户端;
git clone http://github.com/session-replay-tools/tcpcopy
./configure
make && make install
安装完成后的各结构目录:
Configuration summary
tcpcopy path prefix: "/usr/local/tcpcopy"
tcpcopy binary file: "/usr/local/tcpcopy/sbin/tcpcopy"
tcpcopy configuration prefix: "/usr/local/tcpcopy/conf"
tcpcopy configuration file: "/usr/local/tcpcopy/conf/plugin.conf"
tcpcopy pid file: "/usr/local/tcpcopy/logs/tcpcopy.pid"
tcpcopy error log file: "/usr/local/tcpcopy/logs/error_tcpcopy.log"
运行 tcpcopy 客户端,有几种可选方式:
./tcpcopy -x 80-172.16.***.52:80 -s 172.16.***.53 -d #全流量复制
./tcpcopy -x 80-172.16.***.52:80 -s 172.16.***.53 -r 20 -d #复制20%的流量
./tcpcopy -x 80-172.16.***.52:80 -s 172.16.***.53 -n 2 -d #放大2倍流量
3.2 Test Server 上的操作:
添加静态路由:
route add -net 0.0.0.0/0 gw 172.16.***.53
3.3 Assistant Server 上的操作:
下载并安装 intercept 服务端;
git clone http://github.com/session-replay-tools/intercept
./configure
make && make install
安装完成后的各结构目录:
Configuration summary
intercept path prefix: "/usr/local/intercept"
intercept binary file: "/usr/local/intercept/sbin/intercept"
intercept configuration prefix: "/usr/local"
intercept configuration file: "/usr/local/intercept/"
intercept pid file: "/usr/local/intercept/logs/intercept.pid"
intercept error log file: "/usr/local/intercept/logs/error_intercept.log"
运行 intercept 服务端;
./intercept -i eth0 -F 'tcp and src port 80' -d
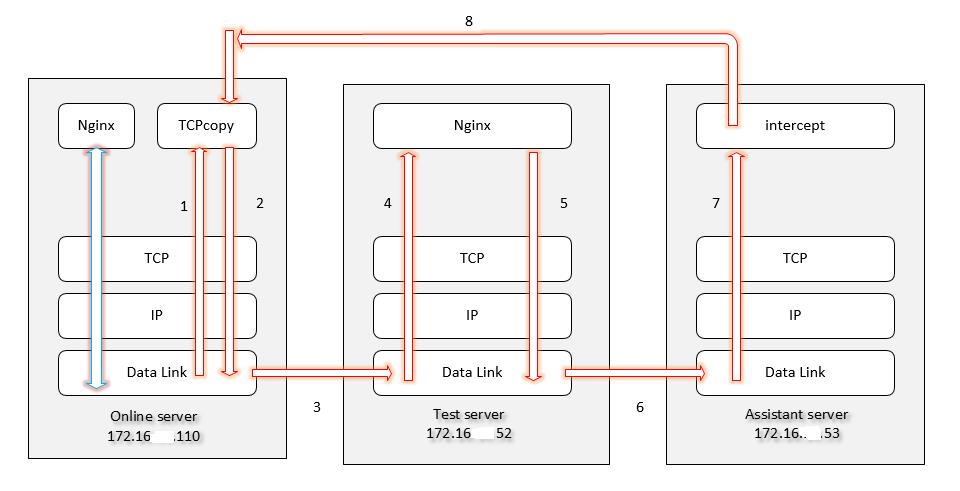
图5 生产环境和镜像环境数据传输流程图
对照上图5,再简单解释一下工作原理:
- TCPcopy 从数据链路层 copy 端口请求,然后更改目的 ip 和目的端口。
- 将修改过的数据包传送给数据链路层,并且保持 tcp 连接请求。
- 通过数据链路层从 online server 发送到 test server。
- 在数据链路层解封装后到达 nginx 响应的服务端口。
- 等用户请求的数据返回结果后,回包走数据链路层。
- 通过数据链路层将返回的结果从 test server 发送到 assistant server。注:test server 只有一条默认路由指向 assistant server。
- 数据到达 assistant server 后被 intercept 进程截获。
- 过滤相关信息将请求状态发送给 online server 的 tcpcopy,关闭 tcp 连接。
0x04,可能会遇到的问题
王斌自己讲:要想用好 tcpcopy,需要熟悉系统知识,包括如何高效率抓包,如何定位系统瓶颈,如何部署测试应用系统,如何抓包分析。常见问题有:1)部署测试系统不到位,耦合线上系统,2)忽视系统瓶颈问题,3)不知道如何定位问题,4)资源不到位,资源紧张引发的问题 。
1)ip_conntrack
2014年6月,微博的唐福林曾说:“Tcpcopy 引流工具是线上问题排查的绝佳之选,但使用者很少有人去关注开启 tcpcopy 服务时,同时会开启 ip_conntrack 内核模块,这个模块负责追踪所有 tcp 链接的状态,而且它的内部存储有长度限制,一旦超过,所有新建链接都会失败。”
王斌则回应说:“开启 tcpcopy,自身不会去开启 ip_conntrack 内核模块。开不开启 ip_conntrack 内核模块,是用户自己决定的,跟 tcpcopy 没关系。”他还建议:“当连接数量非常多的时候,本身就应该关闭 ip_conntrack,否则严重影响性能。至于 tcpcopy,默认是从 ip 层发包的,所以也会被 ip_conntrack 干涉,文档中也有描述,其实也可以采用 --enable-dlinject 来发包,避开ip层的ip_conntrack。如果没有报“ip_conntrack: table full, dropping packet”,一般无需去操心ip_conntrack。”以及“线上连接不多的场合,开启 ip_conntrack 并没有问题。线上连接比较多的场合,最好关闭 ip_conntrack,或者对线上应用系统端口设置 NOTRACK,至少我周围的系统都是这样的,这是为性能考虑,也是一种好的运维习惯。”
2)少量丢包
如何发现 TCPCopy 丢包多还是少呢?
王斌自己称,在某些场景下,pcap 抓包丢包率会远高于 raw socket 抓包,因此最好利用 pf_ring 来辅助或者采用 raw socket 来抓包。
丢包率需要在测试环境中按照定量请求发送进行对比才能展开计算,另外还需要对日志内容进行分析,有待测试。
3)离线重放
tcpcopy 有两种工作模式:
1)实时拷贝数据包;
2)通过使用 tcpdump 等抓包生成的文件进行离线(offline)请求重放。
本次仿真测试,没有试验成功第二种工作模式,留待以后进一步研究。
4)不提取 7 层信息
会议上曾提出按域名区分拷贝流量,省得把不在本次压测范围内的工程打挂,但 tcpcopy 的原理是在 ip 层拷贝,不提取 7 层的信息,也就是说,在我们的 Nginx*4 上部署 TCPCopy,只能是将所有流量拷贝到镜像环境的 Nginx 上。反正没有配置对应的 server,或者 server 停掉,这种处理不了的流量就丢弃掉。
0x05,观测的性能指标
仿真压测时,需要记录下 Test Server 以及后端各种被压工程的性能指标。
本次压测,我们记录的指标有:
- Java 工程的访问次数,响应时间,平均响应时间,调用成功或失败,Web端口连接数;
- Web容器的 thread、memory 等情况;
- 虚拟机的 CPU-usage、Load-avg、io-usage 等;
- memcached/redis 等缓存集群的命中率等;
参考资源:
1,2014,使用tcpcopy导入线上流量进行功能和压力测试;
2,2012,一淘:利用tcpcopy引流做模拟在线测试;
3,王斌的微博;
4,2013,tcpcopy架构漫谈;
5,2014,网易QA,Tcpcopy两种架构原理详解(连载二) ;
以上是关于(转)真刀真枪压测:基于TCPCopy的仿真压测方案的主要内容,如果未能解决你的问题,请参考以下文章