大文件上传服务器支持超大文件HTTP断点续传实践总结
Posted Java思维导图
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大文件上传服务器支持超大文件HTTP断点续传实践总结相关的知识,希望对你有一定的参考价值。
_来源:_blog.csdn.net/ababab12345/
article/details/80490621
最近由于笔者所在的研发集团产品需要,需要支持高性能的大文件 http 上传,并且要求支持 http 断点续传。这里在简要归纳一下,方便记忆:
服务器端由 C 语言实现,而不是用 java、php 这种解释型语言来实现;
服务器端即时写入硬盘,因此无需再次调用
move_uploaded_file、InputStreamReader这种需要缓存的技术来避免服务器内存占用与浏览器请求超时;支持 html5 与 IFRAME(针对老浏览器),并且支持获取文件上传进度。
为了更好的适应当前的移动互联网,要求对上传服务支持断点续传,断线重连。因为移动互联网并不非常稳定;再者,上传一个大文件发生异常掉线的可能性非常大,为了避免重新上传,支持断点续传就变得非常必要了。
支持断点续传的思路是:
客户端(通常是浏览器)向服务器端上传某个文件,并不断记录上传的进度,如果一旦掉线或发生其它异常,客户端可以向服务器查询某个文件已经上传的状态,从上次上传的文件位置接着上传。
网上也有大师采用分片文件上传方式来实现大文件上传,方法是将文件切成小片,例如 4MB 一个片段,服务器端每次接收一小片文件保存成一个临时文件,等待所有片段传输完毕后,再执行合并。笔者认为,如果原始文件足够小,这种方式是可以的,但一旦文件有几百兆或者几个 GB 或者几十个 GB,则合并文件的时间会非常长,常常导致浏览器响应超时或服务器阻塞。
如果自己实现独立客户端(或浏览器的 ActiveX 插件)来上传文件,则支持断点续传将是一件非常简单的事情,只需在客户端记录文件上传状态。而支持浏览器断点续传(无需安装第三方插件)一般来说是要比自己做独立客户端上传难度大一些,但也不难。我的实现思路如下:
一、浏览器在上传某个文件时候,先给这个文件生成一个 HASH 值,必须在浏览器端生成这个 HASH 值。
不能单循地依据文件名来查询文件上传记录,文件名的重复性很大,文件名 + 文件尺寸组成的值重复性缩小,如果再加上文件修改时间,则重复性进一步缩小,如果再加上一个浏览器的 ID 可以进一步缩小重复性冲突。最好的 HASH 值的计算方法是用文件的内容进行 MD5 计算,但计算量极大(其实也没有必要这么做),过多的耗时会影响上传的体验。
基于上述理由,我的 HASH 值计算思路如下:
首先给浏览器赋予一个 ID,这个 ID 保存在 Cookie 里;
浏览器的 ID+ 文件的修改时间 + 文件名 + 文件尺寸 的结果进行 MD5 来计算一个文件的 HASH 值;
浏览器的 ID 是系统在浏览器访问文件上传站点时自动给浏览器授予的。
//简单的Cookie帮助函数
function setCookie(cname,cvalue,exdays)
{
var d = new Date();
d.setTime(d.getTime()+(exdays*24*60*60*1000));
var expires = "expires="+d.toGMTString();
document.cookie = cname + "=" + cvalue + "; " + expires;
}
function getCookie(cname)
{
var name = cname + "=";
var ca = document.cookie.split(';');
for(var i=0; i<ca.length; i++)
{
var c = ca[i].trim();
if (c.indexOf(name)==0) return c.substring(name.length,c.length);
}
return "";
}
//
//简单的文件HASH值计算,如果您不是十分考究,应该可以用于产品。
//由于计算文件HASH值用到了多种数据,因此在HYFileUploader系统范围内发生HASH冲突的可能性应该非常小,应该可以放心使用。
//获取文件的ID可以用任何算法来实现,只要保证做到同一文件的ID是相同的即可,获取的ID长度不要超过32字节
//
function getFileId (file)
{
//给浏览器授予一个唯一的ID用于区分不同的浏览器实例(不同机器或者相同机器不同厂家的浏览器)
var clientid = getCookie("HUAYIUPLOAD");
if (clientid == "") {
//用一个随机值来做浏览器的ID,将作为文件HASH值的一部分
var rand = parseInt(Math.random() * 1000);
var t = (new Date()).getTime();
clientid =rand+'T'+t;
setCookie("HUAYIUPLOAD",clientid,365);
}
var info = clientid;
if (file.lastModified)
info += file.lastModified;
if (file.name)
info += file.name;
if (file.size)
info += file.size;
//https://cdn.bootcss.com/blueimp-md5/2.10.0/js/md5.min.js
var fileid = md5(info);
return fileid;
}
笔者认为:不必通过读取文件的内容来计算 HASH 值,这样会非常慢的。如果确实需要实现 HTTP 秒传,可能得这么做,这样如果不同的人上传的文件内容一致,就可避免重复上传,直接返回结果即可。
之所以给浏览器赋予一个 ID,这样可以进一步避免别的计算机的同名同尺寸文件的 HASH 值冲突。
二、查询文件的 HASH 值
在文件上传支持,先通过文件的 HASH 值从上传服务器查询文件的上传进度信息,然后从上传进度位置开始上传,代码如下:
var fileObj = currentfile;
var fileid = getFileId(fileObj);
var t = (new Date()).getTime();
//通过以下URL获取文件的断点续传信息,必须的参数为fileid,后面追加t参数是避免浏览器缓存
var url = resume_info_url + '?fileid='+fileid + '&t='+t;
var ajax = new XMLHttpRequest();
ajax.onreadystatechange = function () {
if(this.readyState == 4){
if (this.status == 200){
var response = this.responseText;
var result = JSON.parse(response);
if (!result) {
alert('服务器返回的数据不正确,可能是不兼容的服务器');
return;
}
//断点续传信息返回的文件对象包含已经上传的尺寸
var uploadedBytes = result.file && result.file.size;
if (!result.file.finished && uploadedBytes < fileObj.size) {
upload_file(fileObj,uploadedBytes,fileid);
}
else {
//文件已经上传完成了,就不要再上传了,直接返回结果就可以了
showUploadedFile(result.file);
//模拟进度完成
//var progressBar = document.getElementById('progressbar');
//progressBar.value = 100;
}
}else {
alert('获取文件断点续传信息失败');
}
}
}
ajax.open('get',url,true);
ajax.send(null);
以上是通过 jQuery-file-upload 组件的实现,通过原始 javascript 的实现代码请参见 demos 目录的 h4resume.html 样本代码。
三、执行上传
在查询完文件的断点续传信息后,如果文件确实以前已经上传,服务器将返回已经上传过的文件尺寸,我们接着从已经上传的文件尺寸位置开始上传数据即可。
html5 的 File 对象的 slice 可以用于从文件切取片段来上传。
定义和用法
slice() 方法可提取字文件的某个部分,并以新的字符串返回被提取的部分。
语法
File.slice(start,end)
参数 描述
start 要抽取的片断的起始下标。如果是负数,则该参数规定的是从字符串的尾部开始算起的位置。也就是说,-1 指字符串的最后一个字符,-2 指倒数第二个字符,以此类推。
end 紧接着要抽取的片段的结尾的下标。若未指定此参数,则要提取的子串包括 start 到原字符串结尾的字符串。另外,关注 Java 知音公众号,回复 “后端面试”,送你一份面试题宝典!
如果该参数是负数,那么它规定的是从字符串的尾部开始算起的位置。
实现分片文件上传的代码如下:
/*
文件上传处理代码
fileObj : html5 File 对象
start_offset: 上传的数据相对于文件头的起始位置
fileid: 文件的ID,这个是上面的getFileId 函数获取的,
*/
function upload_file(fileObj,start_offset,fileid)
{
var xhr = new XMLHttpRequest();
var formData = new FormData();
var blobfile;
if(start_offset >= fileObj.size){
return false;
}
var bitrateDiv = document.getElementById("bitrate");
var finishDiv = document.getElementById("finish");
var progressBar = document.getElementById('progressbar');
var progressDiv = document.getElementById('percent-label');
var oldTimestamp = 0;
var oldLoadsize = 0;
var totalFilesize = fileObj.size;
if (totalFilesize == 0) return;
var uploadProgress = function (evt) {
if (evt.lengthComputable) {
var uploadedSize = evt.loaded + start_offset;
var percentComplete = Math.round(uploadedSize * 100 / totalFilesize);
var timestamp = (new Date()).valueOf();
var isFinish = evt.loaded == evt.total;
if (timestamp > oldTimestamp || isFinish) {
var duration = timestamp - oldTimestamp;
if (duration > 500 || isFinish) {
var size = evt.loaded - oldLoadsize;
var bitrate = (size * 8 / duration /1024) * 1000; //kbps
if (bitrate > 1000)
bitrate = Math.round(bitrate / 1000) + 'Mbps';
else
bitrate = Math.round(bitrate) + 'Kbps';
var finish = evt.loaded + start_offset;
if (finish > 1048576)
finish = (Math.round(finish / (1048576/100)) / 100).toString() + 'MB';
else
finish = (Math.round(finish / (1024/100) ) / 100).toString() + 'KB';
progressBar.value = percentComplete;
progressDiv.innerHTML = percentComplete.toString() + '%';
bitrateDiv.innerHTML = bitrate;
finishDiv.innerHTML = finish;
oldTimestamp = timestamp;
oldLoadsize = evt.loaded;
}
}
}
else {
progressDiv.innerHTML = 'N/A';
}
}
xhr.onreadystatechange = function(){
if ( xhr.readyState == 4 && xhr.status == 200 ) {
console.log( xhr.responseText );
}
else if (xhr.status == 400) {
}
};
var uploadComplete = function (evt) {
progressDiv.innerHTML = '100%';
var result = JSON.parse(evt.target.responseText);
if (result.result == 'success') {
showUploadedFile(result.files[0]);
}
else {
alert(result.msg);
}
}
var uploadFailed = function (evt) {
alert("上传文件失败!");
}
var uploadCanceled = function (evt) {
alert("上传被取消或者浏览器断开了连接!");
}
//设置超时时间,由于是上传大文件,因此千万不要设置超时
//xhr.timeout = 20000;
//xhr.ontimeout = function(event){
// alert('文件上传时间太长,服务器在规定的时间内没有响应!');
//}
xhr.overrideMimeType("application/octet-stream");
var filesize = fileObj.size;
var blob = fileObj.slice(start_offset,filesize);
var fileOfBlob = new File([blob], fileObj.name);
//附加的文件数据应该放在请求的前面
formData.append('filename', fileObj.name);
//必须将fileid信息传送给服务器,服务器只有在获得了fileid信息后才对文件做断点续传处理
formData.append('fileid', fileid);
//请将文件数据放在最后的域
//formData.append("file",blob, fileObj.name);
formData.append('file', fileOfBlob);
xhr.upload.addEventListener("progress", uploadProgress, false);
xhr.addEventListener("load", uploadComplete, false);
xhr.addEventListener("error", uploadFailed, false);
xhr.addEventListener("abort", uploadCanceled, false);
xhr.open('POST', upload_file_url);
//
xhr.send(formData);
}
为了验证文件断点续传,笔者做了一个简单的界面,用于显示文件上传的过程中的状态信息,界面如下:
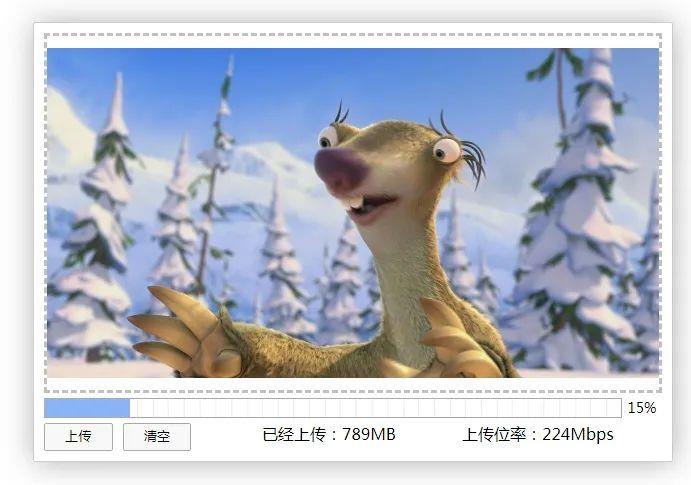
图片
通过 HTML 可以计算文件上传的进度,文件已经上传的尺寸,文件上传的位率等信息,如果在上传过程中出现任何异常,则重新上传即可,已经上传的部分将不需要重新上传。
为了验证 HTML5 断点续传,可以通过 github 来下载 这个文件上传服务器来进行测试。
https://github.com/wenshui2008/UploadServer
以上是关于大文件上传服务器支持超大文件HTTP断点续传实践总结的主要内容,如果未能解决你的问题,请参考以下文章