Python爬虫:requests模块使用
Posted 晚风Adore
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:requests模块使用相关的知识,希望对你有一定的参考价值。
requests模块使用
requests模块
python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。用于发送请求,模拟浏览器上网。
使用流程
- 指定url
- 发起请求
- 获取响应数据
- 持久化存储
环境安装
建议直接下载Anaconda,在PyCharm中使用Anaconda的默认环境,其中就包含了requests模块。
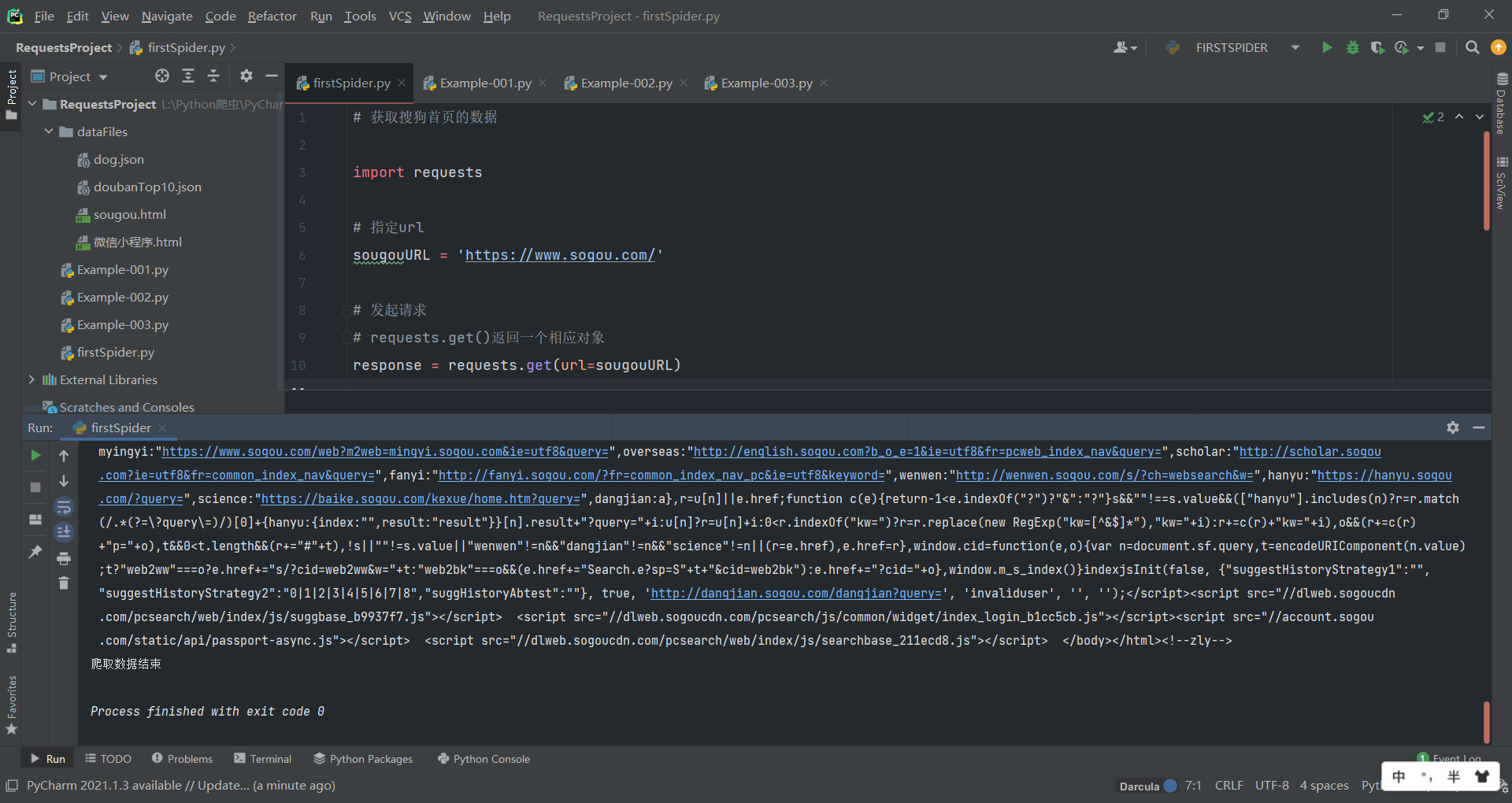
爬虫的第一个实例:获取搜狗搜索网页的源代码
# 获取搜狗首页的数据
import requests
# 指定url
sougouURL = 'https://www.sogou.com/'
# 发起请求
# requests.get()返回一个相应对象
response = requests.get(url=sougouURL)
# 获取响应数据
# text返回字符串类型数据
# 这里会得到该页面的html源码
pageText = response.text
print(pageText)
# 存储获取到的数据
with open('./sougou.html','w') as fp:
fp.write(pageText)
print('爬取数据结束')
以上是关于Python爬虫:requests模块使用的主要内容,如果未能解决你的问题,请参考以下文章