用了十年竟然都不对,JavaRustGo主流编程语言的哈希表比较
Posted beyondma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用了十年竟然都不对,JavaRustGo主流编程语言的哈希表比较相关的知识,希望对你有一定的参考价值。
哈希表(HashMap、字典)是日常编程当中所经常用到的一种数据结构,程序员经常接解到的大数据Hadoop技术栈、Redis缓存数据库等等最近热度很高的技术,其实都是对键值(key-value)数据的高效存储与提取,而key-value恰恰就是哈希表中存储的元素结构,可以说Redis、HDFS这些都是哈希表的经典应用,不过笔者之前也只知道哈希表比较快,但对于具体什么场景下快,怎么用才快等等知识却一知半解,因此这里把目前的一些研究成果分享给大家。
重新认识哈希表
所谓的哈希表就是通过哈希算法快速搜索查询元素的方法,比如说你要在茫茫人海当中找到一位笔名叫做beyondma的博主,但却并不知道他具体的博客地址,在这种情况下就只能在所有的博主范围内展开逐个的排查与摸索,运气差的话我可能以找遍所有n个博主的主页,才到beyondma,这也就是这种遍历查找的时间复杂度是o(n),查找的时间会随着博主的数量而线增长。
而哈希算法就是直接将beyondma这个名字进行算法处理,直接得到beyondma的博客地址信息,在哈希算法的加持下定位某一元素的时间度变成了o(1),由于哈希算法能够将key(键值本例中指beyond)和value(本例中指beyond.csdn.net)以o(1)的时间复杂度,直接对应起来,因此哈希表被人称为key-value表,存储的元素也被称为key-value对(键值对)。哈希表的查找过程特别像查字典,给出一个字并找到这个字在字典中的位置,只是哈希表在一般情况下都很快。当然哈希表也有代价:
以空间换时间:哈希算法也称为散列算法,这种叫法相对比较直观,由于哈希算法是通过计算确认存储地址的,因此首先进入到哈希表的元素并不一定存到第一个位置,存储n个键值对的哈希表往往会消耗比切片多很多的内存空间。
哈希碰撞:哈希碰撞是指不同的键值,在经过哈希计算后得到的内存地址槽位是相同的,也就是说相同的地址上要存储两个以上的键值对,一旦发生这种情况,也就是哈希碰撞了。在发生碰撞的场景下哈希表会进行退化,其中Java会在碰撞强度到达一定级别后,会使用红黑树的方式来进行哈希键值对的存储,而Go和Rust一般都是退化成为链表。
下面我们首先来详细讲讲两个哈希表的常见误用。
哈希表的误用
不要遍历哈希表!:局部快,不意味着整体快,由于哈希表提取单个元素的速度很快,因此整个遍历整个集合所需要的时间也会更短,这种看法明显是个美丽的误会。
我们后文也会具体讲到,哈希表在遍历方面的表现结果,是由计算机组成原理决定的,与Go、Rust和Java的区别不大,因此以下例子先以Go语言的代码为例来说明。
package main
import (
"fmt"
"time"
)
func main() {
testmap := make(map[int]int)
len := 1000000
//tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
testmap[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for k, v := range testmap {
sum = sum + k + v
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}可以看到使用哈希表进行遍历的话,以上代码运行的结果为:
sum= 1000000000000
diff= 29297200
成功: 进程退出代码 0.而对比使用切片遍历的代码如下:
package main
import (
"fmt"
"time"
)
func main() {
//testmap := make(map[int]int)
len := 1000000
tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
tests1ice[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for k, v := range tests1ice {
sum = sum + k + v
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}以上代码运行结果为:
sum= 1000000000000
diff= 1953900
成功: 进程退出代码 0.可以看到同样长度的集合遍历性能表现,切片的耗时只有哈希表的5%左右,两者几乎相差两个数量级。
数据访问局部性原理的制约:局部性原理可能是计算机基本原理中威力最强的基本定理之一,也是程序员在编程过程中必须要考虑的规律,因此我们看到在计算机世界中局部性原理,经常在速度不匹配的存储介质中得到运用,比如英特尔的CPU往往分为三级高速缓存,彼此之间的速度差距大概在8到10倍之间,其中高速缓存中的第三级缓存又比内存快10倍,这样彼此之间各差10倍左右的缓存体系加速效果最好,这就像军事行动中,先锋部队既要率先行动,又不能与大部队过于脱节,才能圆满的完成任务。在实际CPU的工作当中,如果数据单元A1被访问了,那么A1的邻居A0和A2被访问到的可能性也会极大的增加,因此CPU一般都会在数据单元A1被访问的同时,将他的邻居们调入高速缓存。
也就是说切片这种在内存当中连续分布的数据结构,其元素都是以高速缓存行的大小为单位读入到高速缓存的,而高速缓存的平均速度又是内存的几十倍,因此相当于一次读取操作,就能快速处理好几个元素;但由于哈希表实际也是稀疏表,一个键值对的周围可能没有其它有效键值对,因此哈希表在遍历时实际上只能一个一个元素的处理。这样比较下来哈希表在单个元素的访问上快,但在整体遍历上慢也就不足为奇了。
在元素不多不要用哈希表!我经常看到有不少程序员在元素不多的情况下,还坚持使用哈希表来建立key-value的对应关系,其实这样的做法并不会带来效率的提升,正如我们刚刚所说,哈希算法也被称为散列算法,键值对的内存地址分布很可能并不连续,这就特别不方便局部性原理发挥作用。刚刚我们上文也提到了内存缓存行的大小通常是64byte,在实际测试过程中可以看到如果元素能在一个内存缓存行存储下来,就不要用哈希表了,这时候用数据切片,每次遍历查找的性能反而比哈希表更快。具体代码如下:
哈希表实现示例
package main
import (
"fmt"
"time"
)
func main() {
testmap := make(map[int]int)
len := 10
times := 100000
//tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
testmap[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for i := 0; i < times; i++ {
//for k, v := range testmap {
//if i%len == v {
sum = sum + i%len + testmap[i%len]
//break
//}
//}
//sum = sum + k + v
//tests1ice[i%len] = i + 1
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}以上代码结果如下:
sum= 1000000
diff= 2929500而切片遍历查找的实现如下:
package main
import (
"fmt"
"time"
)
func main() {
//testmap := make(map[int]int)
len := 10
times := 100000
tests1ice := make([]int, len, len)
for i := 0; i < len; i++ {
tests1ice[i] = i + 1
}
sum := 0
now := time.Now().UnixNano()
for i := 0; i < times; i++ {
for k, v := range tests1ice {
if i%len == k {
sum = sum + k + v
break
}
}
//sum = sum + k + v
//tests1ice[i%len] = i + 1
}
diff := time.Now().UnixNano() - now
fmt.Println("sum=", sum)
fmt.Println("diff=", diff)
// fmt PrintIn("slice=", slice)
}sum= 810000
diff= 1953000
成功: 进程退出代码 0.少元素方面集合的元素定位性能上,哈希表比切片慢了40%,当然这也是局部性原理造成的,由于元素比较少,因此切片这样内存连续数据结构,完全可以在高速缓存中完成数据的查找定位,这样综合下来其性能反而还要比哈希表要快。
正如前文所述,哈希算法的工作机制本身就决定了哈希表对存储空间就有一定的浪费,因此在没有性能优势的情况下,尤其是上述遍历及短表的场景下,就不要再用哈希表了,完全没有必要。
哈希表的实现机制要点
在笔者看了部分哈希表的代码之后,Java、Go和Rust这三种语言有一些相同的机制,也有一些不同,其中有两点值得关注,当然由于水平有限,如有错误之处敬请指正。
避免使用连续内存块:我们知道在内存、硬盘等存储设备的管理中,连续的空间往往是比较宝贵的,而哈希表是相对比较稀疏的数据结构,因此Java、Go和Rust基本都引用了一些比如桶的机制,尽量避免占用连续的内存块。以Go语言的实现为例:
type hmap struct {
count int // map的长度
flags uint8
B uint8 // map中的bucket的数量,
noverflow uint16 //
hash0 uint32 // hash 种子
buckets unsafe.Pointer // 指向桶的指针
oldbuckets unsafe.Pointer // 指向旧桶的指针,这里用于溢出
nevacuate uintptr
extra *mapextra // optional fields
}
// 在桶溢出的时候会用到extra
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
type bmap struct {
tophash [bucketCnt]uint8// Map中的哈希值的高8位为桶的地址
}在访问Map中的键值对时,需要先计算key的哈希值,其中哈希的值的低8位定位到具体的桶(bucket),通过高8位在桶内定位到具体的位置,而不同桶之间所占用的内存区域也不需要是连续的空间,这样也就从一定程度上弥补哈希表占用空间较大的缺点。
哈希碰撞处理:我们刚刚也介绍了哈希表碰撞的内容,也就是出现了不同的键值对要存储在同一个内存槽位的场景,极端情况下是所有键值对全部发生碰撞,这样哈希表实际也就退化成了链表,Java对碰撞的处理相对比较成熟,如果退化的链表长度大于8,那么Java会选择用红黑树这种近似于二叉排序树的数据结构进行替代,从而保证定位性能不低于O(logn)
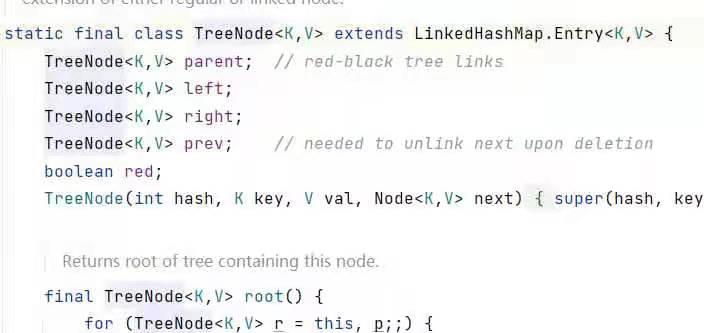
而如果链表的长度小于等于8,那么如我们上文介绍,在数据长度比较短的情况下其实链表的性能可能还会更好,没必要使用引入红黑树,由此可见Java这门语言的确已经非常成熟。
以上是关于用了十年竟然都不对,JavaRustGo主流编程语言的哈希表比较的主要内容,如果未能解决你的问题,请参考以下文章