用python爬取豆瓣电影信息,输入类别和爬取页数,想怎么爬就怎么爬,哎就是玩!
Posted 主打Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python爬取豆瓣电影信息,输入类别和爬取页数,想怎么爬就怎么爬,哎就是玩!相关的知识,希望对你有一定的参考价值。
用python爬取豆瓣电影信息,输入类别和爬取页数,想怎么爬就怎么爬,哎就是玩!
代码操作展示:
开发环境
windows 10
python3.6
开发工具
pycharm
库
tkinter、jsonpath、lxml、random、os、xlrd
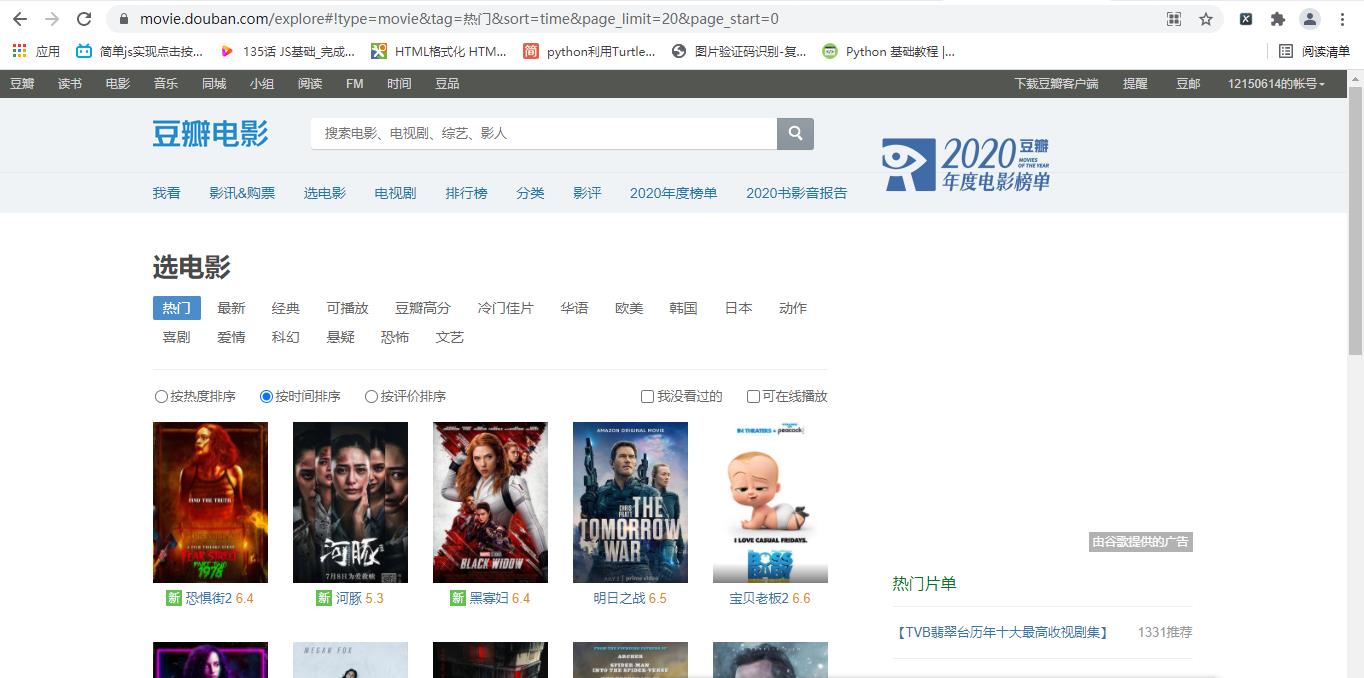
1.百度搜索豆瓣打开豆瓣电影,下面是我们要爬取的地址
start_url = https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=0界面如下
2.在进入网页的时候看到电影数据那里有加载中,确定信息为异步加载,直接右击检查进行抓包,点击Network,点击XHR,如下图所示
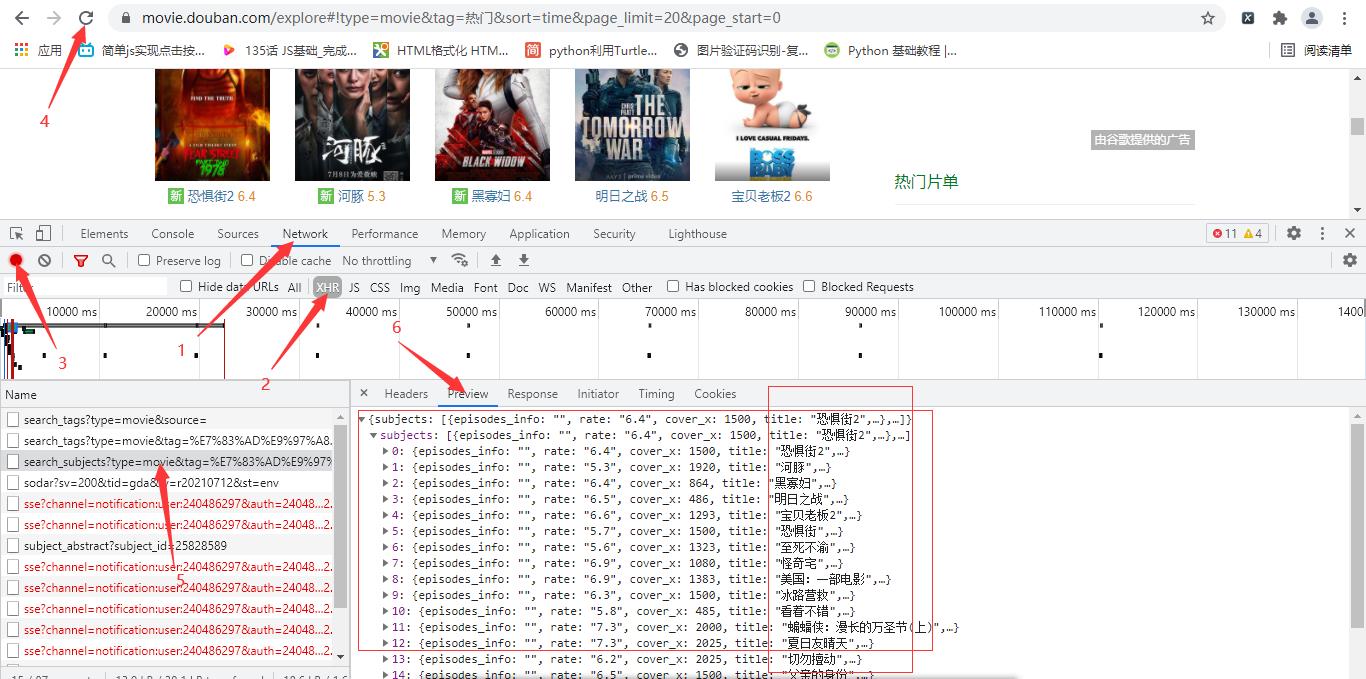
3,接下来我们看翻页操作,点击加载更多,查看网址变化
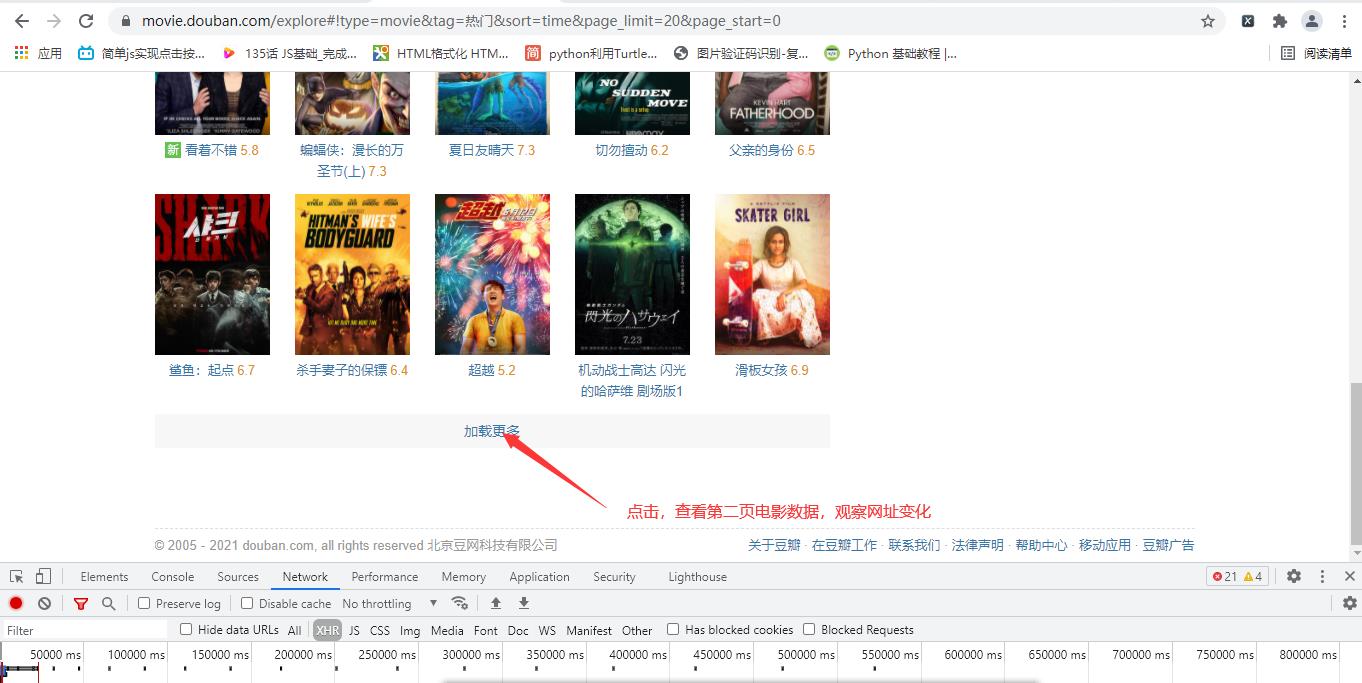
第二页地址https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=20
第三页地址
https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=40
规律找到了
最后page_start=一次增长20
同时也发现tag后面是电影的分类,可以通过更改类名获取其他类别的电影信息

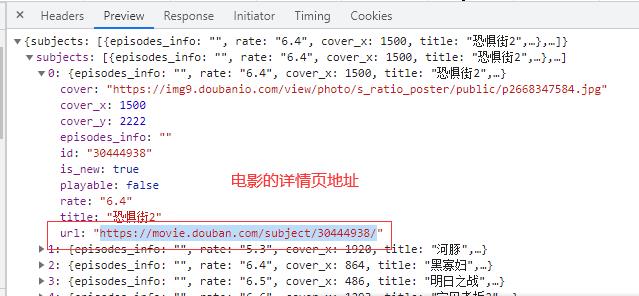
4.获取电影的详情页地址
def main(self, user_name, pass_wd):
'''
url 的拼接调用
:return:
'''
for i in range(pass_wd):
try:
start_url = self.start_url.format(user_name, i * 20)
response = session.get(start_url, headers=self.headers).json()
self.respons(response, user_name)
except:
print(f'{user_name}====保存完成正在翻页')
def respons(self, response, user_name):
'''
提取数据
:return:
'''
subjects = response['subjects']
if subjects == []:
a = subjects[6]
else:
'''提取详情页'''
url_list = jsonpath(subjects, '$..url')
for url in url_list:
5.用xpath语法提取需要的数据,并将提取的数据放到列表里
for url in url_list:
list_1 = []
res = session.get(url, headers=self.headers).content.decode()
res = etree.html(res)
'''电影名称'''
title = res.xpath('//h1/span/text()')[0]
list_1.append(title)
'''电影评分'''
pf = res.xpath('//strong/text()')[0]
list_1.append(pf)
dy_list = []
'''导演'''
dy = res.xpath('//div[@id="info"]/span[1]/span[2]/a/text()')
for d in dy:
dy_list.append(d)
# print(dy)
'''编剧'''
bj = res.xpath('//div[@id="info"]/span[2]/span[2]/a/text()')
for b in bj:
pass
# print(bj)
'''主演'''
zy = res.xpath('//span[@class="actor"]/span[@class="attrs"]/a/text()')
# zy = ''.join(zy)
# print(zy)
'''类型'''
lx = res.xpath('//span[@property="v:genre"]/text()')
# print(lx)
'''制片国家'''
zp_list = res.xpath('//div[@id="info"]/text()')
# print(zp_list)
zp = ''.join(zp_list)
zp = zp.replace(' ', '').replace('\\n', '')
zp = zp.split('/')
zp = [i for i in zp if i != '']
zp = zp[0]
data = {
'基本详情': [title, pf, dy, bj, zy, lx, zp]
}
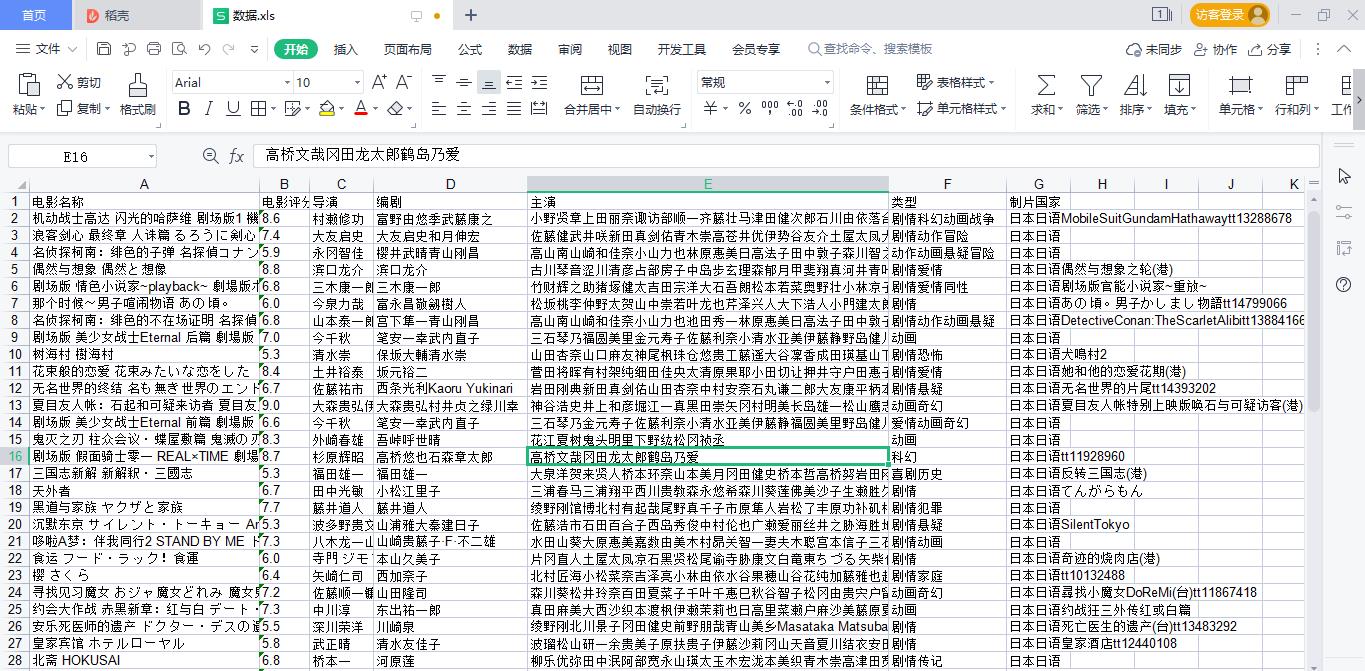
6.最后保存到表格,可以作为模板使用
def save_excel(self, data, title, f):
os_path_1 = os.getcwd() + '/数据/'
if not os.path.exists(os_path_1):
os.mkdir(os_path_1)
os_path = os_path_1 + '数据.xls'
if not os.path.exists(os_path):
# 创建新的workbook(其实就是创建新的excel)
workbook = xlwt.Workbook(encoding='utf-8')
# 创建新的sheet表
worksheet1 = workbook.add_sheet("基本详情", cell_overwrite_ok=True)
borders = xlwt.Borders() # Create Borders
"""定义边框实线"""
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left_colour = 0x40
borders.right_colour = 0x40
borders.top_colour = 0x40
borders.bottom_colour = 0x40
style = xlwt.XFStyle() # Create Style
style.borders = borders # Add Borders to Style
"""居中写入设置"""
al = xlwt.Alignment()
al.horz = 0x02 # 水平居中
al.vert = 0x01 # 垂直居中
style.alignment = al
# 合并 第0行到第0列 的 第0列到第13列
'''基本详情13'''
# worksheet1.write_merge(0, 0, 0, 13, '基本详情', style)
excel_data_1 = ('电影名称', '电影评分', '导演', '编剧', '主演', '类型', '制片国家')
for i in range(0, len(excel_data_1)):
worksheet1.col(i).width = 2560 * 3
# 行,列, 内容, 样式
worksheet1.write(0, i, excel_data_1[i], style)
workbook.save(os_path)
# 判断工作表是否存在
if os.path.exists(os_path):
# 打开工作薄
workbook = xlrd.open_workbook(os_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_path)
print(f'{f}===={title}========保存完成')
源码展示:
# !/usr/bin/nev python
# -*-coding:utf8-*-
USER_AGENT_LIST = ['Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36 TheWorld 7',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; MATP; InfoPath.2; .NET4.0C; CIBA; Maxthon 2.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1',
'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.21 (KHTML, like Gecko) Chrome/19.0.1041.0 Safari/535.21',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36 TheWorld 7',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; MATP; InfoPath.2; .NET4.0C; CIBA; Maxthon 2.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1',
'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.21 (KHTML, like Gecko) Chrome/19.0.1041.0 Safari/535.21',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4093.3 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko; compatible; Swurl) Chrome/77.0.3865.120 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Goanna/4.7 Firefox/68.0 PaleMoon/28.16.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4086.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) coc_coc_browser/91.0.146 Chrome/85.0.4183.146 Safari/537.36',
'Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/537.36 (KHTML, like Gecko) Safari/537.36 VivoBrowser/8.4.72.0 Chrome/62.0.3202.84',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0) Gecko/20100101 Firefox/83.0',
'Mozilla/5.0 (X11; CrOS x86_64 13505.63.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 OPR/72.0.3815.400',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.101 Safari/537.36',
]
import random, os, xlrd
import tkinter as tk
import jsonpath, xlwt
from lxml import etree
from xlutils.copy import copy
from jsonpath import jsonpath
from requests_html import HTMLSession
session = HTMLSession()
class DBSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('豆瓣电影信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text="请输入需要爬取的分类('热门','最新','经典','豆瓣高分','冷门佳片','华语','欧美','韩国',"
"'日本'):", font=('Arial', 12), width=150, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
self.start_url = 'https://movie.douban.com/j/search_subjects?type=movie&tag={}&sort=time&page_limit=20&page_start={}'
self.headers = {
'User-Agent': random.choice(USER_AGENT_LIST)
}
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
'''
url 的拼接调用
:return:
'''
for i in range(pass_wd):
try:
start_url = self.start_url.format(user_name, i * 20)
response = session.get(start_url, headers=self.headers).json()
self.respons(response, user_name)
except:
print(f'{user_name}====保存完成正在翻页')
def respons(self, response, user_name):
'''
提取数据
:return:
'''
subjects = response['subjects']
if subjects == []:
a = subjects[6]
else:
'''提取详情页'''
url_list = jsonpath(subjects, '$..url')
for url in url_list:
list_1 = []
res = session.get(url, headers=self.headers).content.decode()
res = etree.HTML(res)
'''电影名称'''
title = res.xpath('//h1/span/text()')[0]
list_1.append(title)
'''电影评分'''
pf = res.xpath('//strong/text()')[0]
list_1.append(pf)
dy_list = []
'''导演'''
dy = res.xpath('//div[@id="info"]/span[1]/span[2]/a/text()')
for d in dy:
dy_list.append(d)
# print(dy)
'''编剧'''
bj = res.xpath('//div[@id="info"]/span[2]/span[2]/a/text()')
for b in bj:
pass
# print(bj)
'''主演'''
zy = res.xpath('//span[@class="actor"]/span[@class="attrs"]/a/text()')
# zy = ''.join(zy)
# print(zy)
'''类型'''
lx = res.xpath('//span[@property="v:genre"]/text()')
# print(lx)
'''制片国家'''
zp_list = res.xpath('//div[@id="info"]/text()')
# print(zp_list)
zp = ''.join(zp_list)
zp = zp.replace(' ', '').replace('\\n', '')
zp = zp.split('/')
zp = [i for i in zp if i != '']
zp &#以上是关于用python爬取豆瓣电影信息,输入类别和爬取页数,想怎么爬就怎么爬,哎就是玩!的主要内容,如果未能解决你的问题,请参考以下文章