大数据(9b)Flink集群部署
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(9b)Flink集群部署相关的知识,希望对你有一定的参考价值。
文章目录
1、下载地址
https://archive.apache.org/dist/flink/
2、解压
tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C $B_HOME/
cd $B_HOME
mv flink-1.10.1 flink
3、环境变量
https://yellow520.blog.csdn.net/article/details/112692486
export FLINK_HOME=$B_HOME/flink
4、打包上传一个Flink代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class MyFlatMap implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
}
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCount {
public static void main(String[] args) throws Exception {
// 流执行环境
StreamExecutionEnvironment e = StreamExecutionEnvironment.getExecutionEnvironment();
// 从网络中读取数据
DataStream<String> inputDataStream = e.socketTextStream("localhost", 7777);
// 分词,平化,分组,合计
DataStream<Tuple2<String, Integer>> ds;
ds = inputDataStream.flatMap(new MyFlatMap()).keyBy(0).sum(1);
// 打印,设置并行度
ds.print();
// 执行
e.execute();
}
}
5、开启网络数据传输端口
nc -lk 7777
6、Flink的YARN模式
把Flink的Hadoop包放到lib下
cp flink-shaded-hadoop-2-uber-2.8.3-10.0.jar $FLINK_HOME/lib
ll $FLINK_HOME/lib
启动Hadoop
hadoop.py start
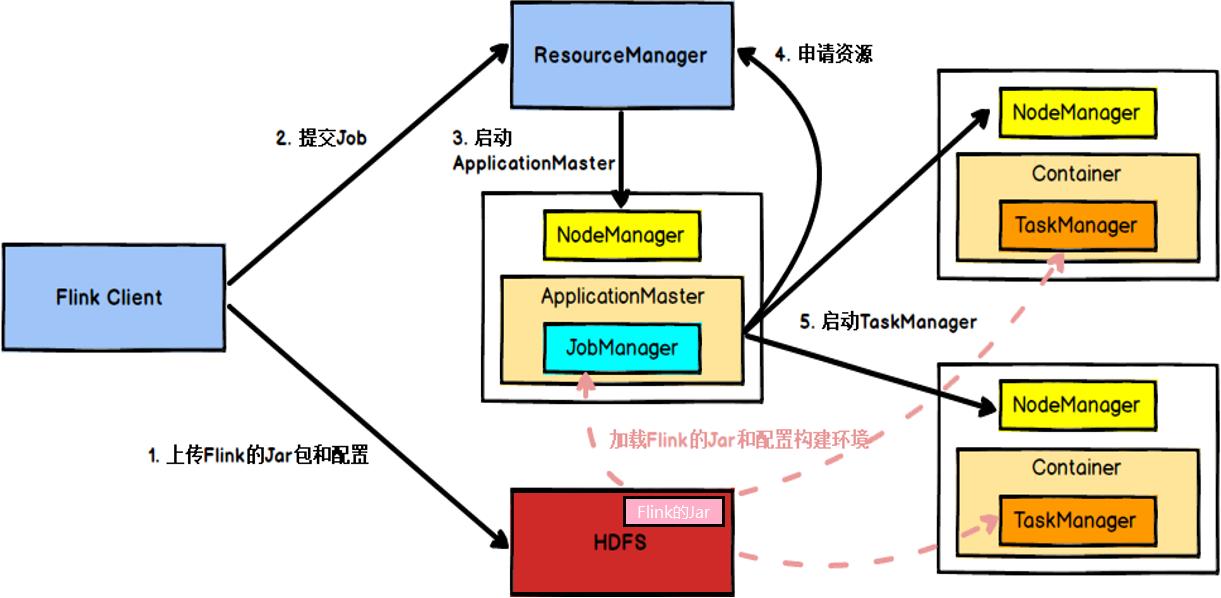
6.1、会话模式(Session Mode)
在YARN中初始化一个Flink集群,开辟指定的资源,以后提交任务都向这里提交。
这个flink集群会常驻在YARN集群中
6.1.1、开启会话
$FLINK_HOME/bin/yarn-session.sh \\
-s 2 \\
-jm 1024 \\
-tm 1024 \\
-nm a1 \\
-d
| 参数 | 说明 |
|---|---|
-s(--slots) | 每个TaskManager的slot数量 |
-jm | JobManager的内存(单位MB) |
-tm | 每个TaskManager的内存(单位MB) |
-nm | YARN上应用程序名字 |
-d | 后台执行 |
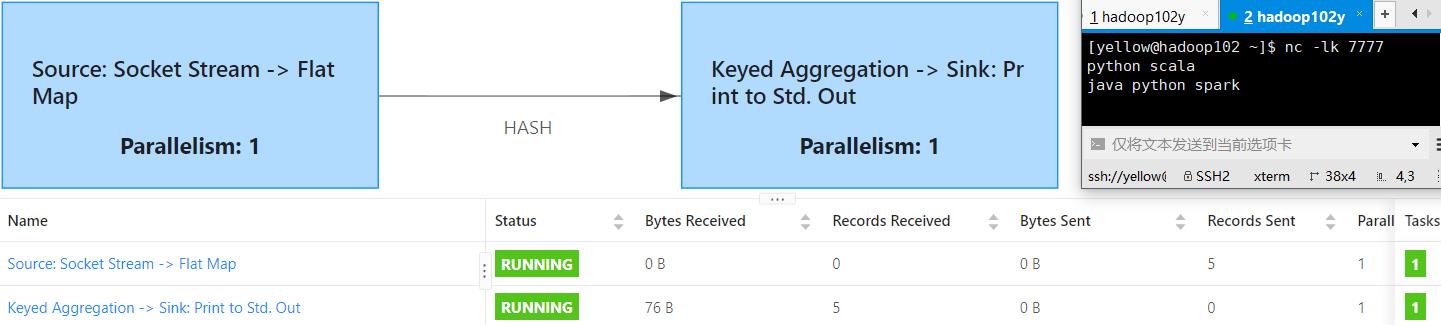
6.1.2、运行jar包
$FLINK_HOME/bin/flink run -c WordCount FlinkPractise-1.0-SNAPSHOT.jar
结果
如图示5个单词,Records也是5
6.1.3、关闭会话
yarn application --list
yarn application --kill application_1626235724262_0001
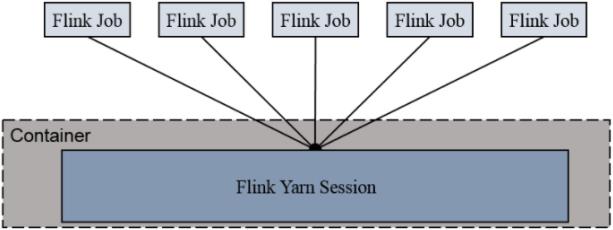
6.2、任务独立提交模式(Per-Job Cluster Mode)
每次提交都会创建一个新的Flink集群,任务之间互相独立
任务执行完成之后创建的集群也会消失
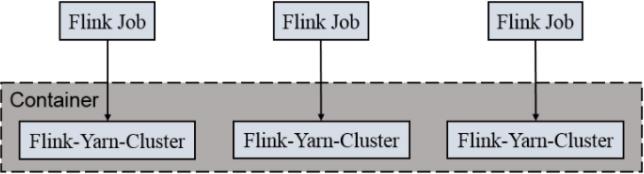
多了个-m yarn-cluster
$FLINK_HOME/bin/flink run \\
-m yarn-cluster \\
-c WordCount \\
FlinkPractise-1.0-SNAPSHOT.jar
7、Appendix
| en | 🔉 | cn |
|---|---|---|
| session | ˈseʃn | n. 会议;(法庭的)开庭;(议会等的)开会;学期;会话 |
| slot | slɒt | n. 位置;狭槽;水沟;硬币投币口;vt. 跟踪 |
| slots | slɒts | n. 插槽 |
以上是关于大数据(9b)Flink集群部署的主要内容,如果未能解决你的问题,请参考以下文章