MySQL系列一:掌握MySQL底层原理从学习事务开始
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL系列一:掌握MySQL底层原理从学习事务开始相关的知识,希望对你有一定的参考价值。
点击上方蓝色“终端研发部”,选择“设为星标”
学最好的别人,做最好的我们
◆ 前言
面试时候,经常会被问到什么是事务、事务的特征、事务的隔离级别这些八股文问题,凭死记硬背通常也可回答的七七八八。但是面试官一旦换个角度问这些问题,有时候可能就语塞了。
所以学一个知识,我总在想有没有那样一个万变不离其宗的底层知识,我掌握了它便能一通百通,相关问题我就都会了,比如面试官问这些问题:
写线程操作一条数据,另外一个读线程也在读取这条数据,写线程还没有提交事务,读线程已经读到更改后的数据了,此时数据库的隔离级别是什么?
可重复读的使用场景举例?
事务隔离是怎么通过视图实现的?
读已提交、可重复读是怎么通过视图构建实现的?
二阶段提交了解吗?redo log、binlog了解吗?都有什么用处?
并发版本控制(MVCC)的概念是什么, 是怎么实现的?
什么是长事务?怎么查询各个表中的长事务?
使用长事务有什么问题?如何避免长事务的出现?
是不是感觉自己掌握的还不够精细?是不是感觉自己离三万月薪还差一点?
同样关于网络的知识也是如此,面试时会经常被人问到三次握手、四次挥手的过程。
那到底三次握手、四次挥手是为了什么?
为什么是三次握手、四次挥手?
四层负载、七层负载的区别是什么?
七层负载的瓶颈是什么?
四层负载又有什么样的问题?
。。。
最难的就是网络了,他是一切分布式、高并发的基础,不可能背一些面试题,看几本书就能说自己精通网络编程了,必须持续学习,举一反三。
所以我的想法是,学习技术不能只是在面试的时候临时抱佛脚,每一个知识点挖进去都是一个新的世界等着你去探索,这需要大量的业余时间来学习,且持续。
本文是学习mysql底层原理的第一篇,我个人认为学习MySQL一定要从事务开始,也就是先保证数据的一致性(事务、锁),然后再去考虑怎么提升性能(索引)。
本文包含内容:MySQL的事务以及日志、二阶段提交、MVCC等相关知识。

◆ Action
MySQL中,事务的支持是在引擎层的,然而MySQL原生的MyISAM引擎并不支持事务,因此逐渐被支持事务的InnoDB引擎所取代。
那你知道InnoDB引擎的由来吗?

InnoDB的历史
学习事务,除了事务的概念外,我们还应该要学习以下知识点:
redo log:物理日志,也叫重做日志
binlog:逻辑日志,也叫归档日志
两阶段提交:如何让数据库恢复到半个月内的任意时间点的状态?
MVCC:多版本并发控制
是不是面试时候,MySQL这块不是索引就是上面的这些知识点?
◆ 事务的基本概念
在MySQL中,事务的概念是指对数据库的一组操作是原子的,要么全部成功,要么全部失败。
事务的四个特性:
Atomicity(原子性):要么全部成功,要么全部失败。
Consistency(一致性):事务执行的结果必须是让数据库从一个一致性状态变成另外一个一致性状态,无论是事务的提交还是回滚,数据的完整性没有破坏。
Isolation(隔离性):一个事务的执行不能被其他事务干扰。
Durability(持久性):事务一旦提交,他对数据的改动是持久性的,事务一旦提交,相关的数据就应该从游离态或瞬时态变成持久态。
即ACID。另外,原子性、隔离性、持久性最终都是为了一致性,一致性是事务的最终目的。
我们先总体上看一条更新类型的SQL语句它的内部执行流程,然后再跟进去学习每一个细节知识点。
◆ update语句的执行流程
比如这样一条更新语句,其中id是主键:
update table_test set num = num+1 where id = 1;
它的MySQL内部执行流程如下:
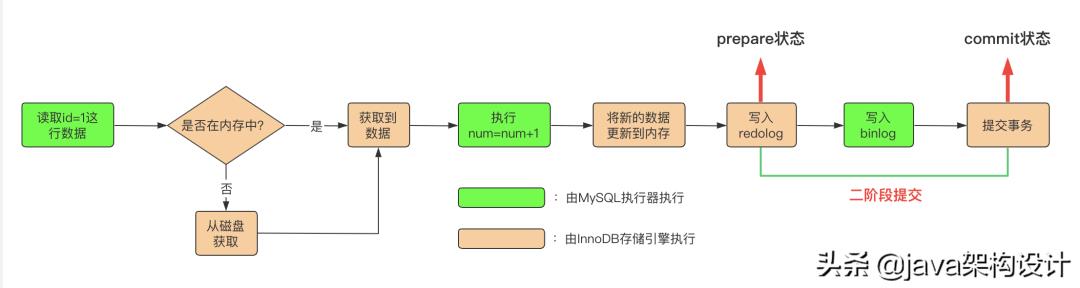
MySQL执行器先找InnoDB引擎读取id=1这一行的数据,InnoDB引擎直接用树查找主键id=1那条数据,如果数据所在页直接在内存中,那么直接返回,否则先从磁盘读取到缓存中再返回;
执行器获得数据后,执行num = num + 1,再调用InnoDB引擎接口写入新的数据;
InnoDB引擎将新的数据更新到内存中,再将这个更新操作记录到redo log中,此时redo log日志处于prepare状态,并通知执行器已就绪,随时可以提交事务;
MySQL执行器写入binlog日志并持久化到磁盘,并调用InnoDB引擎的事务提交接口,InnoDB引擎将刚刚写入的redo log日志的状态改为commit状态,至此,事务完成。
从上面的流程我们可以看到redo log的写入分为两步:prepare、commit,这就是所谓的两阶段提交。
而且两阶段提交一定是成功的写入了两个日志文件:redo log & binlog,只有这样事务才能提交,数据才能满足一致性原则。
◆ redo log
redo log是InnoDB引擎特有的日志模块,记录的是:“在某个数据页上做了什么修改”。
当MySQL执行一条更新语句的时候,InnoDB引擎会把记录先写到redo log文件中,并更新内存。此时这条更新操作就算完成了,但是并没有将数据的更新持久化的磁盘,InnoDB引擎会在一个合适的时机将数据的更新操作持久化到此盘。
这就是MySQL的WAL(Write-Ahead Logging)技术!
即先写日志,再写磁盘。
InnoDB引擎里面redo log写日志的具体实现:
指定一块固定大小的磁盘空间,例如4G,并分成4个文件,从头开始写,写到末尾再回到开头继续循环写,再次从头开始写之前,需要将即将覆盖的文件内容更新到数据文件中,然后再擦出这块内容,腾出空间写入新的redo log,如此往复。

write pos:redo log写入的位置;
check point:检查点,文件擦除的位置,当write pos追赶上check point时候,此时不能写入redo log,需要先将日志文件的部分内容更新到数据文件,并擦除这批日志文件,推进check point。
MySQL中有一个参数
innodb_flush_log_at_trx_commit,默认值是1,代表着每一次的redo log都持久化到磁盘。
这样就可以保证即使数据库发生异常宕机,重启后也可以恢复之前的数据记录,这个能力有一个专有的名词:crash-safe。
◆ binlog
binlog是MySQL server层的日志,也叫归档日志。
binlog相对于redo log,属于逻辑日志,记录的是这个语句的原始逻辑。binlog日志是持续追加写入的,不存在被覆盖一说。
binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后。
binlog日志也有一个参数sync_binlog,默认值也是1,表示每次事务的 binlog 都持久化到磁盘。这样可以保证MySQL异常重启之后binlog日志不丢失。
主从同步也是依赖于binlog日志,所以sync_binlog一定要设置为1,否则主从同步延迟是一个问题。
◆ 两阶段提交的重要性
1、数据库发生crash后重启的数据恢复;
2、数据库误操作后的数据恢复;
3、主从数据库的同步(全量+增量),redis主从同步也是这个思路哦~
4、两阶段提交是一个思想,不仅仅应用于MySQL数据库,日常分布式系统开发,为了保证数据的一致性,两阶段提交也是经常使用的一种思想。
那么问题来了:
两阶段提交是如何保证数据的一致性的?
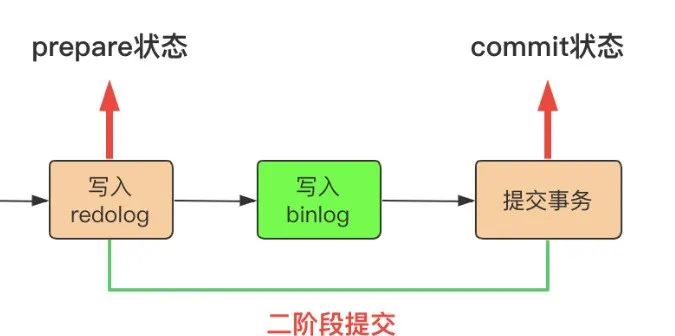
分为三步:
prepare阶段
写binlog
事务commit
当数据库在第二步崩溃时候,重启后,发现redo log没有commit且binlog没有写入,那么回滚事务。
数据同步、备份恢复的时候,没有binlog日志,数据是一致的。
当在第三步崩溃的时候,重启后发现虽然事务没有提交,但是binlog已经写入,redo log处于prepare状态,那么自动提交事务。
数据同步、备份恢复的时候,有binlog日志,数据也是一致的。

终于完成了一半了,经过上面的铺垫,我们才有资格继续学习事务,否则没有地基,就是空中楼阁。
◆ 事务的隔离性
前面我们一起回顾了事务的四大特性:ACID,说白了什么原子性、隔离性、持久性都是为了一致性而服务的。并且着重介绍了redo log和binlog两个最重要的日志模块,以及经典的两阶段提交。
再强调一遍,redo log、binlog、两阶段提交这些功能的实现保证了单个事务的原子性以及持久性。
那么还剩下最后一个隔离性,隔离性也就是说数据库同时有多个事务执行的时候,可能会出现一系列的问题,那么我们就需要设计一个合理的方式来解决随之而来的问题。
明白了吧?
隔离性就是为了多个事务同时执行而存在的!
我们先不去看都有哪些隔离级别,我们先去想多个事务同时执行会有什么问题?
参考Java的并发编程思考一下,多个线程对一个变量同时操作会有哪些问题?
带着问题出发再去理解所谓的事务隔离级别:
事务A对数据的变更操作还没有commit时候,事务B读取到了变更后的数据,产生了“脏读”的问题。
事务A开始时候读取一行数据,紧接着事务B对这行数据进行了操作,并且commit了,事务A再次读取该行数据的时候,和开始时候的数据不一致了,产生了“不可重复读”的问题。
事务A按相同的查询条件重新读取以前检索过的数据,却发现事务B插入了满足其查询条件的新数据,产生了“幻读”的问题。
总结一下即:
多个事务同时执行的时候,可能会出现“脏读(Dirty Read)”、“不可重复读(non-repeatable read)”、“幻读(phantom read)”的问题。
为了解决这些问题,我们在既要考虑数据一致性的同时,又得考虑性能的问题,因此MySQL提供了四种隔离级别来应对不同的应用场景下,性能与数据一致性折中的平衡点。
因此,MySQL对事务的隔离性提供了四种隔离级别,一级比一级要求严格,同理,并发性能上也是一级比一级低:

读未提交(read uncommitted):另外一个事务B读取到了事务A未提交的数据变更。
读提交(read committed):一个事务提交后,它对数据的变更才会被别的事务看到。
可重复读(repeatable read):一个事务在执行过程中任何时候读取到的数据,总是和这个事务启动时候看到的数据是一致的。反过来,它对事务的变更一定是在提交后才能被别的事务读取到。
串行化(serializable):完全的排队串行执行。
◆ 事务不同隔离级别的实现方式
“读未提交”是事务隔离性的最低级别,该级别下对数据没有做任何的控制;
当隔离级别为“读提交”的时候,事务中的每条SQL语句开始执行时候都会创建一个视图,一个事务中会有多个视图的创建,每次创建的时候都会从数据库中获取最新的数据;
当隔离级别为“可重复读”的时候,会在事务开始的时候创建一个视图,整个事务的执行期间都以这个视图为准,因此能够保证对数据的操作未提交之前对其他事务不可见,其他事务对数据的操作对当前事务也不可见。
而“串行化”则是直接加锁,其他事务得等锁释放后才能开始。
◆ 多版本并发控制(MVCC)
我们知道MySQL的默认隔离级别是RR,即可重复读,也就意味着:
一个事务开始之前,所有还没有提交的事务,它都不可见!
那如果一条数据(初始值是1)同时有两个事务来操作它,A事务将该条数据+1,B事务将该条数据+2,那么在RR的隔离级别下,A事务会得到数据结果为2?B事务会得到数据结果为3?如果是这样,那么就是MySQL的bug了,实际上我们想得到的结果是4。
所以我们得想清楚一个事情:
在指定的一个时间段内,一条数据被多个事务执行,如何保证数据的正确一致性?
任意一个事务回滚的时候,所操作的数据都能够正确的回归到事务开始时候的状态吗?
这就是MVCC要做的事情,当然远不止于这些!
带着问题出发,我们下篇文章详细介绍MVCC的实现原理,非常精彩的设计!
◆ 最后
最近我在系统的学习MySQL数据库的底层知识,并将这些文章与你分享,本文主要讲的是事务相关的知识,但是由于篇幅原因,加上MVCC的重要性,我不得不继续更加深入的学习MVCC,并能更好的组织自己的语言,让它能够通俗易懂,以便在某一天我回顾这些知识点的时候,它依旧清晰明了。
来源:
https://www.toutiao.com/i6864198463077220867/
BAT等大厂Java面试经验总结 想获取 Java大厂面试题学习资料扫下方二维码回复「BAT」就好了回复 【加群】获取github掘金交流群回复 【电子书】获取2020电子书教程回复 【C】获取全套C语言学习知识手册回复 【Java】获取java相关的视频教程和资料回复 【爬虫】获取SpringCloud相关多的学习资料回复 【Python】即可获得Python基础到进阶的学习教程回复 【idea破解】即可获得intellij idea相关的破解教程关注我gitHub掘金,每天发掘一篇好项目,学习技术不迷路!
回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
为什么HTTPS是安全的
因为BitMap,白白搭进去8台服务器...
《某厂内部SQL大全 》.PDF
字节跳动一面:i++ 是线程安全的吗?
大家好,欢迎加我微信,很高兴认识你!
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术!
就给个“在看”
以上是关于MySQL系列一:掌握MySQL底层原理从学习事务开始的主要内容,如果未能解决你的问题,请参考以下文章