[JDBC] Kettle on MaxCompute 使用指南
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[JDBC] Kettle on MaxCompute 使用指南相关的知识,希望对你有一定的参考价值。
简介: Kettle是一款开源的ETL工具,纯Java实现,可以在Windows、Unix和Linux上运行,提供图形化的操作界面,可以通过拖拽控件的方式,方便地定义数据传输的拓扑 。基本讲介绍基于Kettle的MaxCompute插件实现数据上云。
Kettle版本:8.2.0.0-342
MaxCompute JDBC driver版本:3.2.8
Setup
- 下载并安装Kettle
- 下载MaxCompute JDBC driver
- 将MaxCompute JDBC driver置于Kettle安装目录下的lib子目录(data-integration/lib)
- 下载并编译MaxCompute Kettle plugin:https://github.com/aliyun/aliyun-maxcompute-data-collectors
- 将编译后的MaxCompute Kettle plugin置于Kettle安装目录下的lib子目录(data-integration/lib)
- 启动spoon
Job
我们可以通过Kettle + MaxCompute JDBC driver来实现对MaxCompute中任务的组织和执行。
首先需要执行以下操作:
- 新建Job
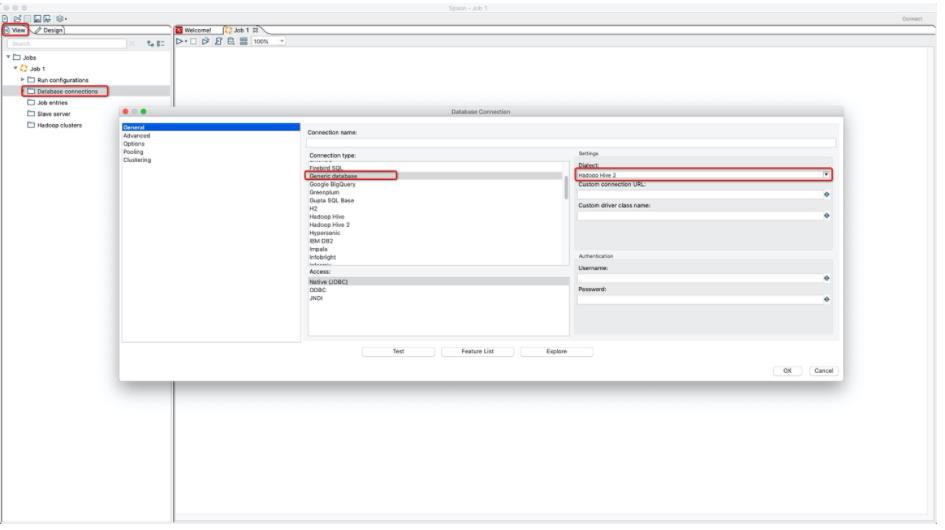
- 新建Database Connection
JDBC连接串格式为:jdbc:odps:?project=
JDBC driver class为:com.aliyun.odps.jdbc.OdpsDriver
Username为阿里云AccessKey Id
Password为阿里云AccessKey Secret
JDBC更多配置见:https://help.aliyun.com/document_detail/161246.html
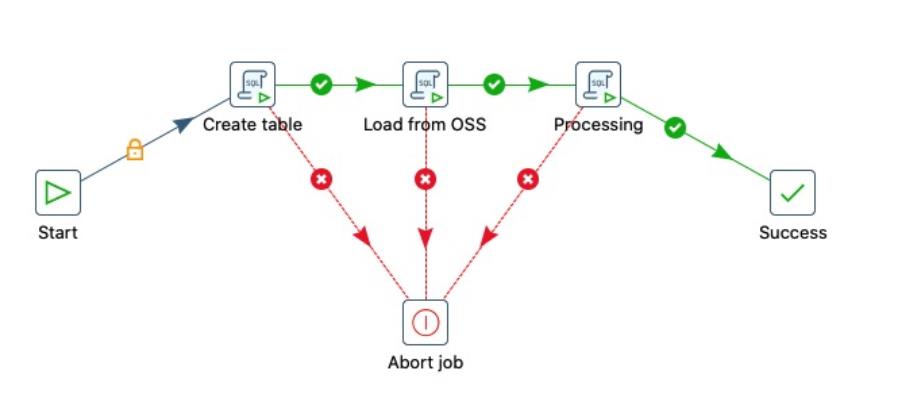
之后,可以根据业务需要,通过SQL节点访问MaxCompute。下面我们以一个简单的ETL过程为例:
Create table节点的配置如下:
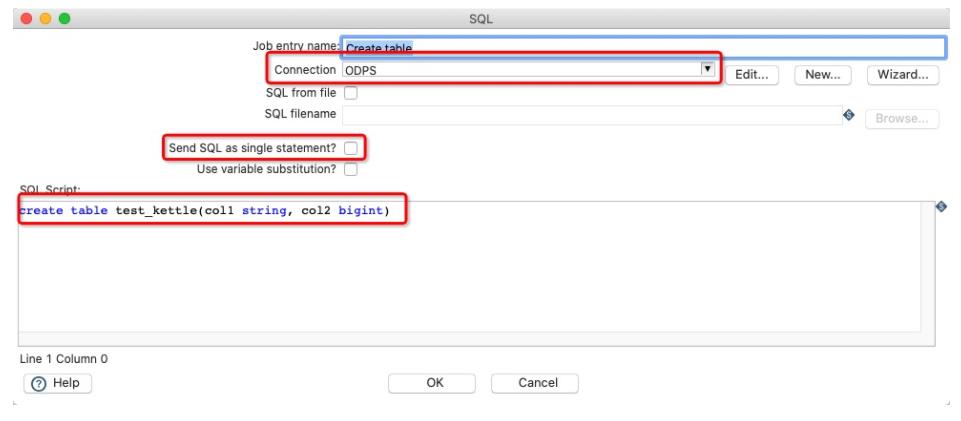
需要注意:
- 这里Connection需要选择我们配置好的
- 不要勾选Send SQL as single statement
Load from OSS节点配置如下:
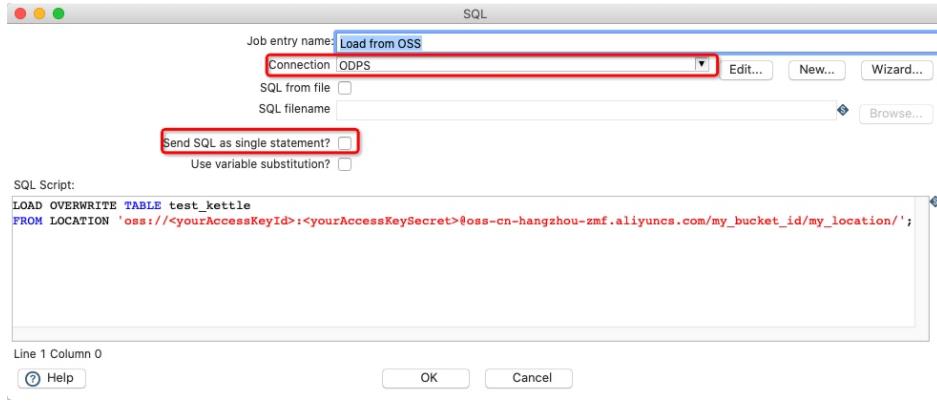
需要注意的点同Create table节点。有关更多Load的用法,见:https://help.aliyun.com/document_detail/157418.html
Processing节点配置如下:
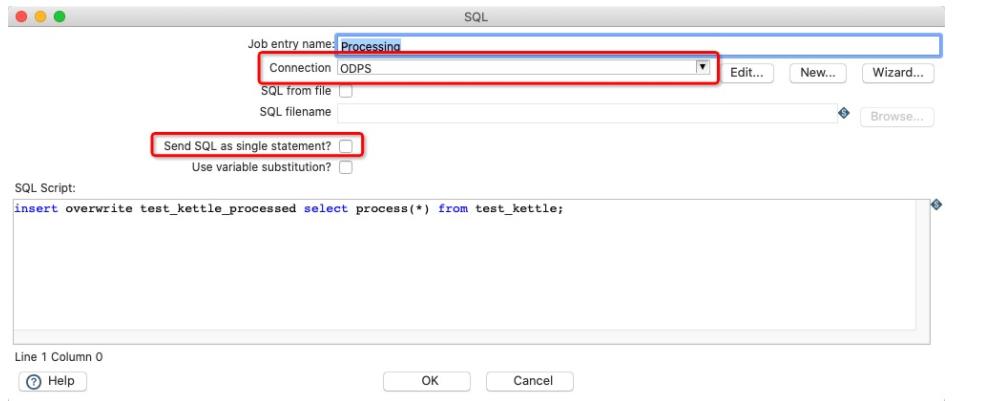
需要注意的点同Create table节点。
Transformation
我们可以通过MaxCompute Kettle plugin实现数据流出或流入MaxCompute。
首先新建Transformation,之后新建Aliyun MaxCompute Input节点,配置如下:
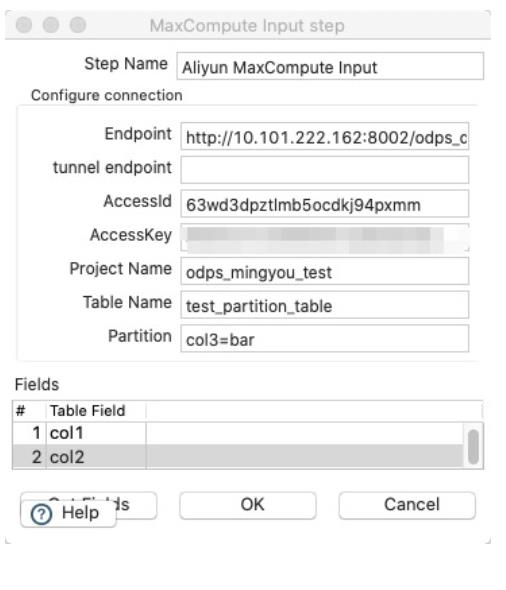
在MaxCompute中新建一张空表,schema与test_partition_table一致。
新建Aliyun MaxCompute Output节点,配置如下:
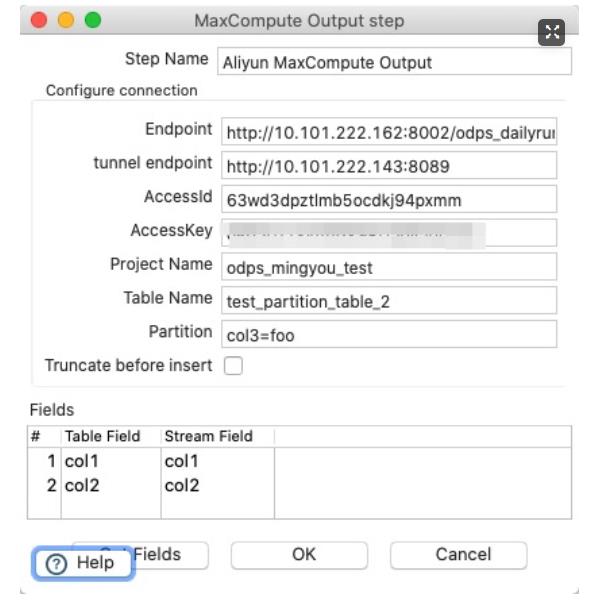
执行Transformation,数据便从test_partition_table被下载,后被上传至test_partition_table_2。
其他
设置MaxCompute flags
如图,在执行DDL/DML/SQL之前,可以通过set key=value;的方式配置flags。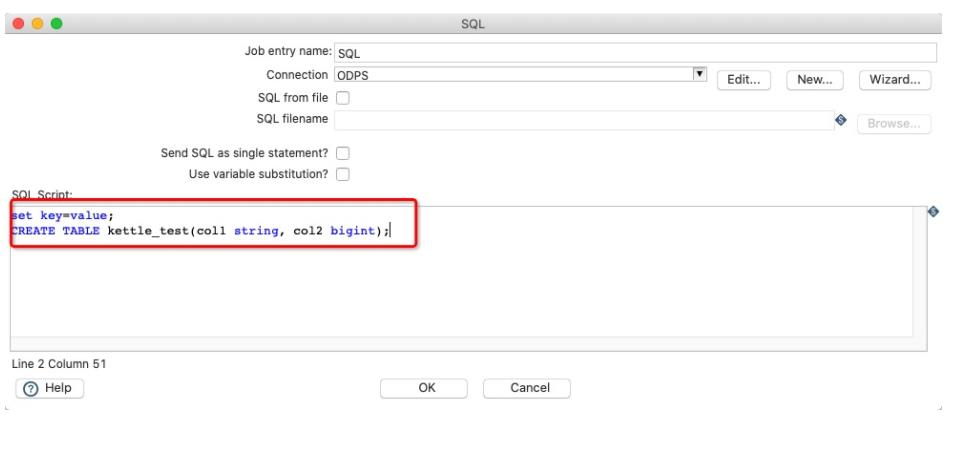
Script模式
暂时无法支持
本文为阿里云原创内容,未经允许不得转载。
以上是关于[JDBC] Kettle on MaxCompute 使用指南的主要内容,如果未能解决你的问题,请参考以下文章