Note_Spark_Day14:Structured Streaming(以结构化方式处理流式数据,底层分析引擎SparkSQL引擎)
Posted 大数据Manor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Note_Spark_Day14:Structured Streaming(以结构化方式处理流式数据,底层分析引擎SparkSQL引擎)相关的知识,希望对你有一定的参考价值。
stypora-copy-images-to: img
typora-root-url: ./
Spark Day14:Structured Streaming
01-[了解]-上次课程内容回顾
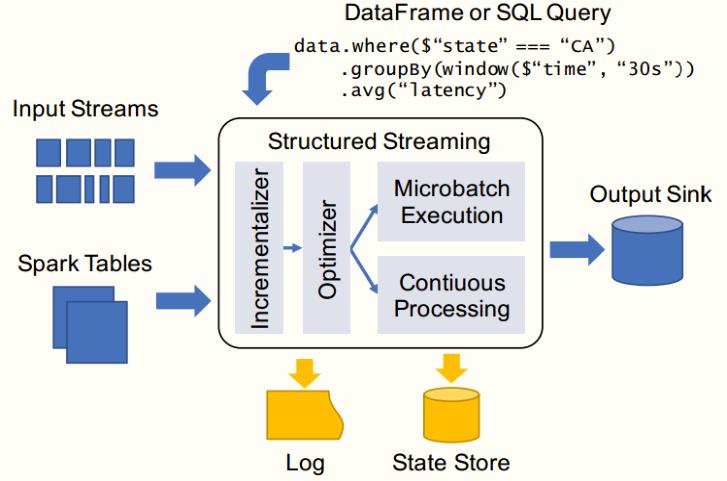
继续讲解:StructuredStreaming,以结构化方式处理流式数据,底层分析引擎SparkSQL引擎。
0、数据源(Source)
支持4种数据源:TCP Socket(最简单)、Kafka Source(最常用)
- File Source:监控某个目录,当目录中有新的文件时,以流的方式读取数据
- Rate Source:自动每秒生成一定数量数据
1、StreamingQuery基本设置
- 设置查询名称:queryName
- 设置触发时间间隔
默认值:Trigger.Processing("0 seconds"),一有数据,立即处理
- 检查点Checkpoint目录
sparkConf.conf("spark.sql.streaming.checkpointLocation", "xx")
option("checkpointLocation", "xx")
- 输出模式OutputMode
Append,追加,数据都是新的
Update,更新数据输出
Complete,所有数据输出
2、Sink终端
表示处理流式数据结果输出地方,比如Console控制台,也可以输出到File Sink
自定义输出
- foreach,表示针对每条数据的输出
- foreachBatch,表示针对每批次数据输出,可以重用SparkSQL中数据源的输出
3、集成Kafka(数据源Source和数据终端Sink)
既可以从Kafka消费数据,也可以向Kafka写入数据
- 数据源Source:从Kafka消费数据,其他参数可以设置
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
// .option("subscribe", "topic1,topic2") // .option("subscribePattern", "topic.*")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
- 数据终端Sink:将流式数据集DataFrame数据写入到Kafka 中,要求必须value字段值,类型为String
val ds = df
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.start()
02-[掌握]-集成Kafka之实时增量ETL(DSL)
/* ============================= 基于Dataset 转换操作 ====================*/
val etlStreamDF: Dataset[String] = kafkaStreamDF
.selectExpr("CAST(value AS STRING)") // 提取value字段值,并且转换为String类型
.as[String] // 转换为Dataset
.filter{msg =>
null != msg &&
msg.trim.split(",").length == 6 &&
"success".equals(msg.trim.split(",")(3))
}
/* ============================= 基于 DataFrame DSL操作 ====================*/
val filter_udf: UserDefinedFunction = udf(
(msg: String) => {
null != msg &&
msg.trim.split(",").length == 6 &&
"success".equals(msg.trim.split(",")(3))
}
)
val etlStreamDF: Dataset[Row] = kafkaStreamDF
.select($"value".cast(StringType))
.filter(filter_udf($"value"))
完整代码如下:
package cn.itcast.spark.kafka
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.functions._
/**
* 实时从Kafka Topic消费基站日志数据,过滤获取通话转态为success数据,再存储至Kafka Topic中
* 1、从KafkaTopic中获取基站日志数据
* 2、ETL:只获取通话状态为success日志数据
* 3、最终将ETL的数据存储到Kafka Topic中
*/
object _01StructuredEtlKafka {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
// TODO: 1. 从Kafka Topic中获取基站日志数据(模拟数据,文本数据)
val kafkaStreamDF: DataFrame = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", "stationTopic")
.option("maxOffsetsPerTrigger", "10000")
.load()
// TODO: 2. ETL:只获取通话状态为success日志数据
/*
val etlStreamDF: Dataset[String] = kafkaStreamDF
.selectExpr("CAST(value AS STRING)") // 提取value字段值,并且转换为String类型
.as[String] // 转换为Dataset[String]
.filter{msg =>
null != msg &&
msg.trim.split(",").length == 6 &&
"success".equals(msg.trim.split(",")(3))
}
*/
val filter_udf: UserDefinedFunction = udf(
(msg: String) => {
null != msg &&
msg.trim.split(",").length == 6 &&
"success".equals(msg.trim.split(",")(3))
}
)
val etlStreamDF: DataFrame = kafkaStreamDF
// 选择value字段,值转换为String类型
.select($"value".cast(StringType))
// 过滤数据:status为success
.filter(filter_udf($"value"))
// TODO: 3. 最终将ETL的数据存储到Kafka Topic中
val query: StreamingQuery = etlStreamDF
.writeStream
.queryName("query-state-etl")
.outputMode(OutputMode.Append())
.trigger(Trigger.ProcessingTime(0))
// TODO:将数据保存至Kafka Topic中
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("topic", "etlTopic")
.option("checkpointLocation", "datas/ckpt-kafka/10001")
.start()
query.awaitTermination()
query.stop()
}
}
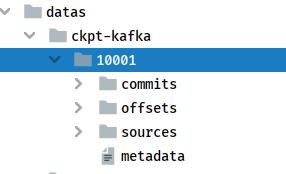
运行流式应用程序,查看Checkpoint目录数据结构如下:
需求:修改上述代码,将ETL后数据转换为JSON数据,存储到Kafka Topic中。
station_6,18600007723,18900006663,success,1620457646879,10000
|
{
"stationId": "station_6",
"callOut": "18600007723",
"callIn": "18900006663",
"callStatus": "success",
"callTime": "1620457646879",
"duration": "10000"
}
step1、分割文本数据,获取各个字段的值
step2、给以Schema,就是字段名称
step3、转换为JSON字符串
package cn.itcast.spark.kafka
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.functions._
/**
* 实时从Kafka Topic消费基站日志数据,过滤获取通话转态为success数据,再存储至Kafka Topic中
* 1、从KafkaTopic中获取基站日志数据
* 2、ETL:只获取通话状态为success日志数据
* 3、最终将ETL的数据存储到Kafka Topic中
*/
object _01StructuredEtlKafka {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
// TODO: 1. 从Kafka Topic中获取基站日志数据(模拟数据,文本数据)
val kafkaStreamDF: DataFrame = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", "stationTopic")
.option("maxOffsetsPerTrigger", "10000")
.load()
// TODO: 2. ETL:只获取通话状态为success日志数据
/*
val etlStreamDF: Dataset[String] = kafkaStreamDF
.selectExpr("CAST(value AS STRING)") // 提取value字段值,并且转换为String类型
.as[String] // 转换为Dataset[String]
.filter{msg =>
null != msg &&
msg.trim.split(",").length == 6 &&
"success".equals(msg.trim.split(",")(3))
}
*/
val filter_udf: UserDefinedFunction = udf(
(msg: String) => {
null != msg &&
msg.trim.split(",").length == 6 &&
"success".equals(msg.trim.split(",")(3))
}
)
val etlStreamDF: DataFrame = kafkaStreamDF
// 选择value字段,值转换为String类型
.select($"value".cast(StringType))
// 过滤数据:status为success
.filter(filter_udf($"value"))
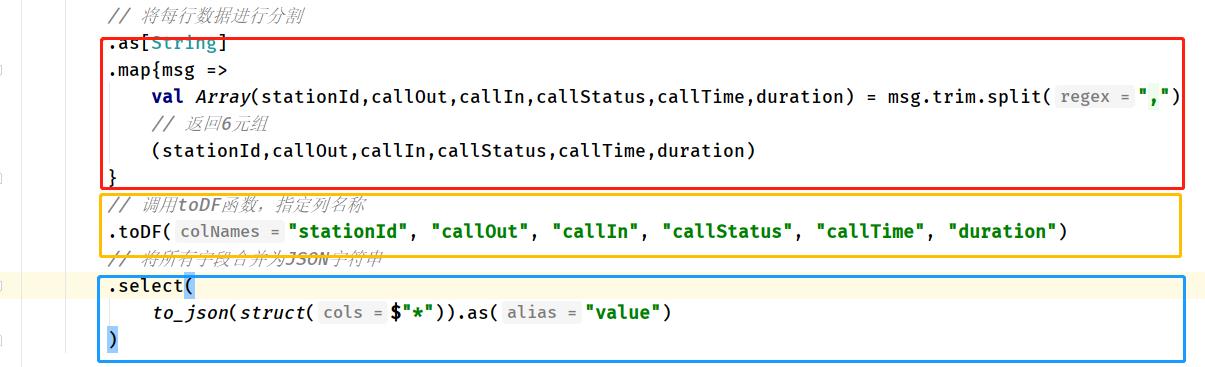
// 将每行数据进行分割
.as[String]
.map{msg =>
val Array(stationId,callOut,callIn,callStatus,callTime,duration) = msg.trim.split(",")
// 返回6元组
(stationId,callOut,callIn,callStatus,callTime,duration)
}
// 调用toDF函数,指定列名称
.toDF("stationId", "callOut", "callIn", "callStatus", "callTime", "duration")
// 将所有字段合并为JSON字符串
.select(
to_json(struct($"*")).as("value")
)
// TODO: 3. 最终将ETL的数据存储到Kafka Topic中
val query: StreamingQuery = etlStreamDF
.writeStream
.queryName("query-state-etl")
.outputMode(OutputMode.Append())
.trigger(Trigger.ProcessingTime(0))
// TODO:将数据保存至Kafka Topic中
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("topic", "etlTopic")
.option("checkpointLocation", "datas/ckpt-kafka/10001")
.start()
query.awaitTermination()
query.stop()
}
}
03-[了解]-今日课程内容提纲
继续讲解StructuredStreaming结构化流中知识点:
1、高级特性
本质上还是微批处理,增量查询,每次处理数据是1条或者多条
- Spark 2.3开始,数据处理模式:
Continues Processing,持续流处理,来一条数据处理一条数据,做到真正的实时处理
目前功能属于测试阶段
- 对流式数据进行去重
批处理分析时:UV,唯一访客数
2、案例:物联网数据实时分析
模拟产生监控数据
DSL和SQL进行实时流式数据分析
熟悉SparkSQL中数据分析API或函数使用
3、窗口统计分析:基于事件时间EvnetTime窗口分析
原理和案例演示
延迟数据处理,使用Watermark水位线
04-[掌握]-高级特性之Continuous Processing
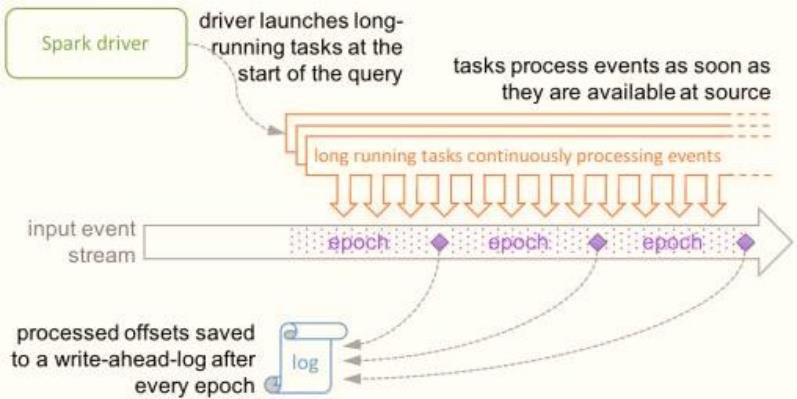
连续处理(Continuous Processing)是Spark 2.3中引入的一种新的实验性流执行模式,可实现低的(~1 ms)端到端延迟,并且至少具有一次容错保证。
连续处理(Continuous Processing)是“真正”的流处理,通过运行一个long-running的operator用来处理数据。
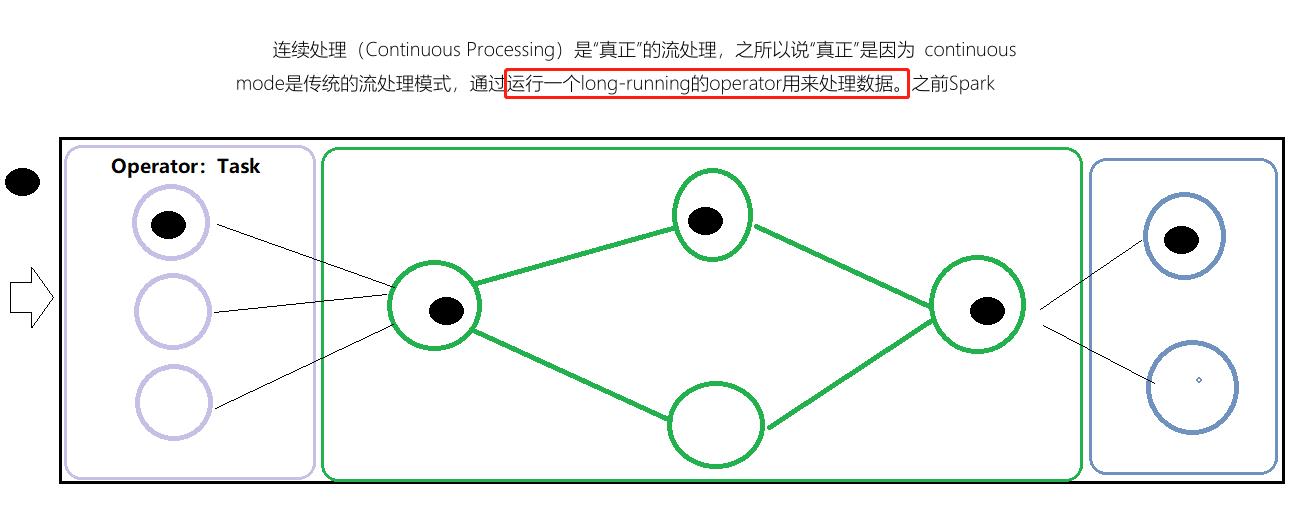
continuous mode 处理模式
只要一有数据可用就会进行处理,如下图所示:
范例演示:从Kafka实时消费数据,经过ETL处理后,将数据发送至Kafka Topic。
目前(Spark2.4.5版本)仅仅支持从Kafka消费数据,向Kafka写入数据,当前ContinuesProcessing处理模式
package cn.itcast.spark.continuous
import java.util.concurrent.TimeUnit
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 从Spark 2.3版本开始,StructuredStreaming结构化流中添加新流式数据处理方式:Continuous processing
* 持续流数据处理:当数据一产生就立即处理,类似Storm、Flink框架,延迟性达到100ms以下,目前属于实验开发阶段
*/
object _02StructuredContinuous {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
// TODO: 1. 从KafkaTopic中获取基站日志数据(模拟数据,文本数据)
val kafkaStreamDF: DataFrame = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("subscribe", "stationTopic")
.load()
// TODO: 2. ETL:只获取通话状态为success日志数据
val etlStreamDF: Dataset[String] = kafkaStreamDF
// 提取value值,并转换为String类型,最后将DataFrame转换为Dataset
.selectExpr("CAST(value AS STRING)")
.as[String]
// 进行数据过滤 -> station_2,18600007445,18900008443,success,1606466627272,2000
.filter(msg => {
null != msg && msg.trim.split(",").length == 6 && "success".equals(msg.trim.split(",")(3))
})
// TODO: 3. 最终将ETL的数据存储到Kafka Topic中
val query: StreamingQuery = etlStreamDF
.writeStream
.queryName("query-state-etl")
.outputMode(OutputMode.Append())
// TODO: 设置连续处理Continuous Processing,其中interval时间间隔为Checkpoint时间间隔
.trigger(Trigger.Continuous(1, TimeUnit.SECONDS))
.format("kafka")
.option("kafka.bootstrap.servers", "node1.itcast.cn:9092")
.option("topic", "etlTopic")
.option("checkpointLocation", "data/structured/station-etl-1002")
.start()
query.awaitTermination()
query.stop()
}
}

05-[掌握]-高级特性之Streaming Deduplication
在StructuredStreaming结构化流中,可以对流式数据进行去重操作,提供API函数:
deduplication
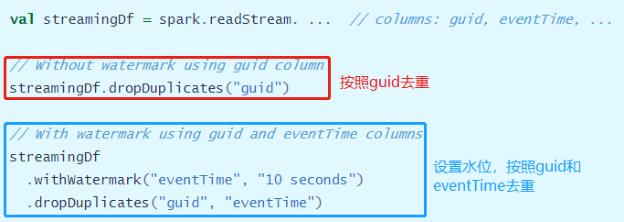
演示范例:对网站用户日志数据,按照userId和eventType去重统计,网站代码如下。
package cn.itcast.spark.deduplication
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* StructuredStreaming对流数据按照某些字段进行去重操作,比如实现UV类似统计分析
*/
object _03StructuredDeduplication {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
// 导入隐式转换和函数库
import org.apache.spark.sql.functions._
import spark.implicits._
// 1. 从TCP Socket 读取数据
val inputTable: DataFrame = spark.readStream
.format("socket") // 列名称为:value,数据类型为:String类型
.option("host", "node1.itcast.cn")
.option("port", 9999)
.load()
// 2. 数据处理分析: {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
val resultTable: DataFrame = inputTable
// 需要从JSON字符串中,提取字段的之
.select(
get_json_object($"value", "$.userID").as("userId"), //
get_json_object($"value", "$.eventType").as("eventType") //
)
// 按照userId和EventType去重
.dropDuplicates("userId", "eventType")
// 分组统计
.groupBy($"userId", $"eventType").count()
// 3. 设置Streaming应用输出及启动
val query: StreamingQuery = resultTable.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.option("numRows", "100")
.option("truncate", "false")
.start()
query.awaitTermination() // 流式查询等待流式应用终止
// 等待所有任务运行完成才停止运行
query.stop()
}
}
06-[掌握]-物联网数据实时分析之需求概述及准备
物联网IoT:Internet of Things

模拟一个智能物联网系统的数据统计分析,产生设备数据发送到Kafka,结构化流Structured Streaming实时消费统计。对物联网设备状态信号数据,实时统计分析:
1)、信号强度大于30的设备;
2)、各种设备类型的数量;
3)、各种设备类型的平均信号强度;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rP0dyCM9-1626355251732)(/img/image-20210508162232609.png)]
运行数据模拟生成器,产生设备监控数据
07-[掌握]-物联网数据实时分析之基于DSL实现
按照业务需求,从Kafka消费日志数据,基于DataFrame数据结构调用函数分析,代码如下:
package cn.itcast.spark.iot.dsl
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.types.{DoubleType, LongType}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 对物联网设备状态信号数据,实时统计分析:
* 1)、信号强度大于30的设备
* 2)、各种设备类型的数量
* 3)、各种设备类型的平均信号强度
*/
object _04IotStreamingOnlineDSL {
def main(args: Array[String]): Unit = {
// 1. 构建SparkSession会话实例对象,设置属性信息
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
以上是关于Note_Spark_Day14:Structured Streaming(以结构化方式处理流式数据,底层分析引擎SparkSQL引擎)的主要内容,如果未能解决你的问题,请参考以下文章
Note_Spark_Day12: StructuredStreaming入门
Note_Spark_Day13:Structured Streaming
Note_Spark_Day11:Spark Streaming