B 站崩了,受害程序员聊聊
Posted 程序员鱼皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了B 站崩了,受害程序员聊聊相关的知识,希望对你有一定的参考价值。
非吃瓜,B 站事件始末分析 + 防治技术分享
大家好,我是鱼皮,昨天小破站崩了的事情相信很多朋友都听说了。
这要是搁以前,不爱吃瓜的我根本不会去关注这种事,崩了就崩了呗,反正天塌下来有程序员大佬们扛着,很快就会好的。
但这次不太一样,因为我自己也成为了本事件的 “受害者” !

所以今天以一名程序员的视角,带大家回顾 B 站崩了事件的始末、理性推测原因、并分享一些防治技术和收获感悟。
事件始末
B 站刚刚崩,但还没有完全崩的时候,我正在直播间写小代码、和小伙伴们友好交流。由于我在写代码的时候不会经常看弹幕,没有注意到弹幕不动了,没有任何小伙伴发弹幕。
起初我以为只是自己写代码太无聊了,没人搭理我。然后我就搁哪儿喃喃自语:奇怪了,怎么没有小伙伴发弹幕?喂,有人么?Hello?Hi?歪比八步?

后来我才发现,弹幕区连进房提示都没了,总不可能几分钟没人进来吧?肯定是出事了!
我以为是弹幕卡了,于是就关闭弹幕再打开,结果还是一样。然后我就想着重启下直播,结果关掉之后再也打不开了,屏幕上直接提示:似乎已断开和服务器的链接。

实话说,在此之前,我根本没想到 B 站这种亿级流量的平台会崩掉。所以第一反应和大家一样,都怀疑是自己网络的问题,结果发现网页能打开,换了网也连不上。于是我突然细思极恐:握草?B 站竟然也把我封了?(老通缉犯了)
就是这样,我是事故现场的受害人,是倒在地上懵逼的那个,所以直到事故发生十几分钟后,我才通过其他途径了解到,哦,原来是 B 站出事了。
虽然错过了第一现场,但通过热搜,也能了解到 B 站崩盘的大致过程,简单地说,就是在 几个小时 内,用户无法正常访问 B 站的任何功能!
打开 B 站,先是 404 Not Found 找不到资源:
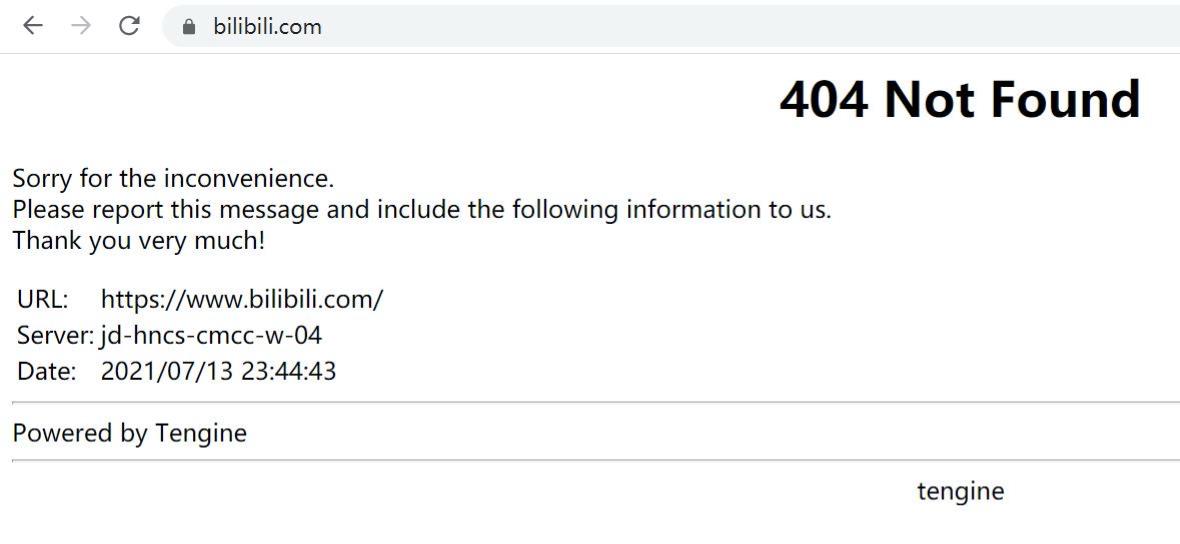
然后是 502 错误网关:

1 个小时后,一些小伙伴表示 B 站的部分功能已经可以使用了,但还是没有完全恢复,直到 14 日凌晨,B 站官方才终于回应,恢复正常了。

原因猜测
昨晚剪视频到凌晨 2 点多,本来想直接睡觉,但手贱又打开了知乎,发现 “B 站崩了” 是 Top 1 热门的问题,出于好奇就点进去想了解下事故背后的真正原因,看看大家的高见。
本来我一个非 B 站工作的外来人,对它的技术架构没有深入了解;再加上缺少关键信息、没有可靠的推测凭据,所以不准备发表意见的。结果发现前排没有几个程序员在从技术的角度推测事故原因,都是一些帮大家吃瓜更香的小回答。那我不妨根据过往学到的架构知识,做一波推测,万一推中了感觉也挺惊喜的。
其实在 20 年的时候,B 站技术总监毛剑老师就在腾讯云 + 社区分享过《B 站高可用架构实践》讲座,当时我全程看完了,但没想到,有一天,高可用的 B 站不可用了。
所以在这次分析前,我先把《B 站高可用架构实践》文章又读了一遍,有趣的是,短短半天,这篇文章的阅读量涨了 15 万!

而且更有趣的是,文章底下多了不少 “嘲讽”,什么 “八股文架构师” 之类的:
不过我觉得没必要,因为毛剑老师分享的技术确实是很实用的高可用解决方案,只不过还是缺少了一些印证吧。
文章地址:https://cloud.tencent.com/developer/article/1618923
下面说下我的猜测。
猜测 1:网关挂了
首先,这次小破站事故发生时,其他站点竟然也崩了!比如 A 站、晋江、豆瓣,统统都上了热搜。

这些事故同时发生,说明是这些系统依赖的公共服务出了问题,而唯一有能力导致大规模服务瘫痪的就是 CDN 了。
CDN 是内容分发网络,提前将源站内容发到各个地区的服务器节点,之后就可以让不同地区的用户就近获取内容,而不是都到源站获取,从而起到内容加速、负载均衡的作用。
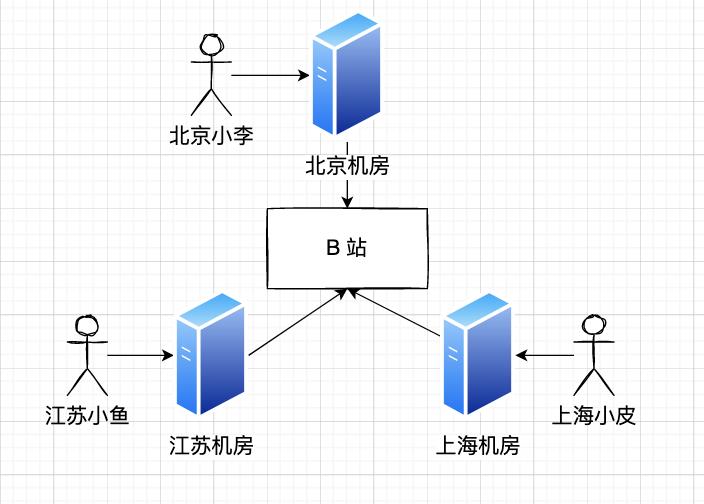
一旦 CDN 挂了,该地区用户的流量会全部打到网关上:
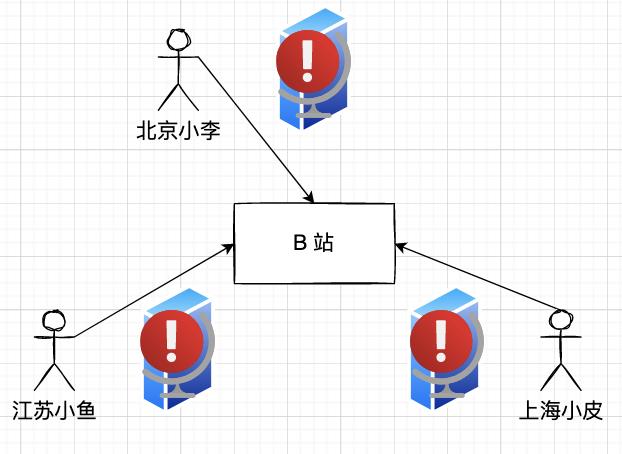
网关就像是家族老大,用户有需求就跟老大说,然后老大再分配需求给弟弟们去完成。
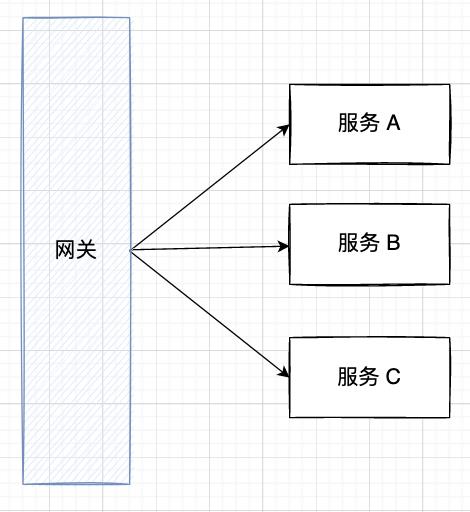
此外,网关通常还承担起了保护服务弟弟们的使命,统一负载均衡、控制流量、熔断降级等。
按道理来讲,通常网关不仅要保护下游的服务,自身也是需要安全保护的。但为什么网关没有保护好自己呢?
我的猜测是:网关还没有来的及开启保护措施(自身的熔断降级等),就被流量瞬狙了。
网关一挂,服务没爹,服务缺少了调用入口,自然就不可用了,未必所有网关后的服务都处于瘫痪状态。
猜测 2:服务雪崩
还有一种猜测是 B 站系统存在很多服务的 调用链 。由于 CDN 或者部分机器挂掉,导致某个下游服务 A 的执行耗时增加,从而导致上游调用服务 A 的服务 B 执行耗时也增加,让系统单位时间的处理能力变差。再加上上游不断积压请求,最终导致整个调用链雪崩,所有链上服务从儿子到爸爸全部灭门。
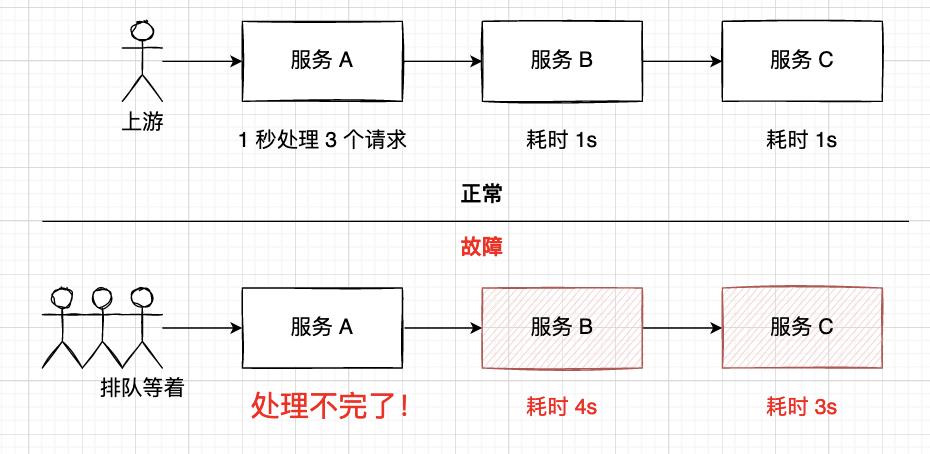
举个通俗的例子就是家里的马桶堵了,桶里的还没充下去,上面却还在不断 “送货”,最终下场就是你不能再 “送货” 了,马桶爆了!
官方解释
在官方解释是服务器机房发生故障之后,又看了其他老师的分析,感觉官方的解释还说的过去。
的确之前 B 站在对外分享高可用架构时几乎没有提到 灾备 和 多活 方面的设计,更多的是在本地服务层和应用层去处理,比如限流、降级、熔断、重试、超时处理等,所以在设计大规模分布式系统时还是要考虑更全面一些,引以为戒~
直到发文前,知乎 Top 1 的回答者又很用心地整理了线索:

为什么其他两家很快就恢复了,B 站却花了几个小时才恢复正常呢?
感觉多少和 B 站自研组件有关系,一方面受到云服务商的影响,导致下游的服务连锁挂掉了,故障面积大 ;另一方面重启也需要时间,而且重启过程中,上游的负载均衡也未必能承受住流量高峰,所以想要恢复到正常水平,至少要等待很多容器副本完全重启。
另外昨天 23 点半左右,我打开 B 站时,看到的内容是几个小时前的老数据,说明这个时候 B 站已经重启了部分服务副本,并且开启了降级措施,并没有查询真实数据。
没想到自己的这个回答还在知乎小火了一把,第一次成为了 千万浏览量 问题的 Top 2,受宠若惊,受宠若惊。。。

保命:以上本身就是我的猜测哈哈,专业度有限,欢迎大家评论区讨论,轻喷轻喷。
防治技术
再简单聊一下服务故障的防治技术,就是如何保证服务的高可用性,尽量持续为用户提供服务而不宕机。
我将了解到的技术简单分类,整理成了一张思维导图:
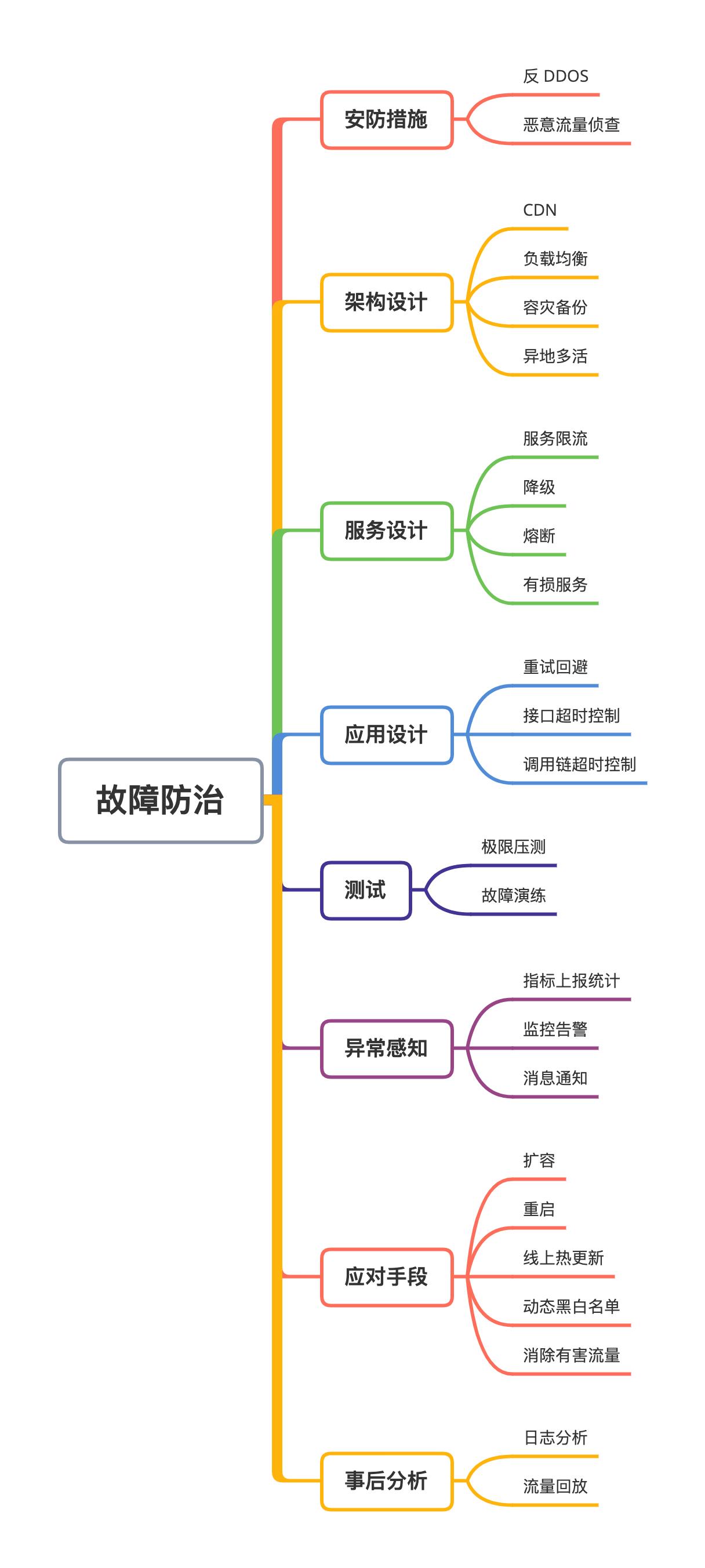
暂时想到这么多,当然还有其他的技术。
时间有限,就先不对这些技术展开去讲了。关于如何减少系统出现的 Bug、保证服务高可用,欢迎大家阅读我的历史文章:揭秘软件开发的达摩克利斯之剑,以上很多技术也都有讲解。
收获感悟
关于这次事故,我作为受害者之一,也有一些收获和感悟,而不是吃瓜吃了个寂寞。
首先是要有 质疑精神 ,我们在写程序出现问题时,习惯性地先从自己身上找原因没有任何问题,但自己排查没有发现 Bug 后,应该大胆推测是我们用到的类库、组件、或者依赖服务、甚至有可能是编辑器出了问题,而不是认为知名的东西一定正确。像小破站出了问题后,我竟然怀疑是自己的直播被封了哈哈,差点想找到管理去跪了。
在编程方面,我们不能只去背知识、听别人讲,做 八股文架构师;而是要做实践经验丰富的工程师,不盲目相信、不想当然,而是在实践中积累经验、结合实际去优化系统。

通过这次结合实际故障过程的分析,我也复习了一遍之前学到的架构知识,对一些高可用的设计有了更深的理解。有朝一日,尽量不让 编程导航(www.code-nav.cn) 成为下一个 B 站(狗头)。
还有就是上面提到的,要时刻居安思危,养成防御性编程的好习惯,而不是出了问题再去补救。像 B 站这种知名平台,出一点小问题,对用户、对企业带来的损失都是难以估量的。
感谢 B 站爸爸送来的一天大会员补偿 ❤️

最后再送大家一些 帮助我拿到大厂 offer 的学习资料:
我是如何从零开始通过自学,拿到腾讯、字节等大厂 offer 的,可以看这篇文章,不再迷茫!
我是鱼皮,点赞 还是要求一下的,祝大家都能心想事成、发大财、行大运。

以上是关于B 站崩了,受害程序员聊聊的主要内容,如果未能解决你的问题,请参考以下文章