Redis歇息笔记32——主从切换与故障切换的问题
Posted qq_34132502
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis歇息笔记32——主从切换与故障切换的问题相关的知识,希望对你有一定的参考价值。
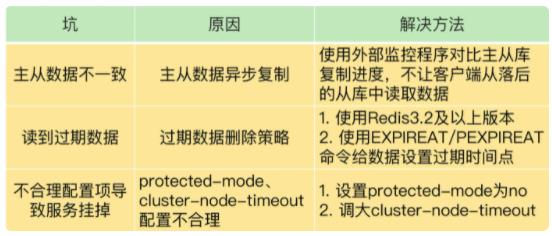
主从数据不一致
为什么会出现这个问题?因为主从库间的复制命令是异步的。
具体来说,在主从库命令传播阶段,主库收到新的写命令后,会发送给从库。但是,主库并不会等到从库实际执行完命令后,再把结果返回给客户端,而是主库自己在本地执行完命令后,就会向客户端返回结果了。如果从库还没有执行主库同步过来的命令,主从库间的数据就不一致了。
那在什么情况下,从库会滞后执行同步命令呢?其实,这里主要有两个原因。
- 主从库间的网络可能会有传输延迟
- 即使从库及时收到了主库的命令,但是,也可能会因为正在处理其它复杂度高的命令(例如集合操作命令)而阻塞
所以应对的方法也有两个:
- 在硬件环境配置方面,我们要尽量保证主从库间的网络连接状况良好
- 我们还可以开发一个外部程序来监控主从库间的复制进度
如果某个从库的进度差值大于我们预设的阈值,我们可以让客户端不再和这个从库连接进行数据读取,这样就可以减少读到不一致数据的情况。
读取过期数据
我们在使用 Redis 主从集群时,有时会读到过期数据。例如,数据 X 的过期时间是 202107140900,但是客户端在 202107140910 时,仍然可以从从库中读到数据 X。一个数据过期后,应该是被删除的,客户端不能再读取到该数据,但是,Redis 为什么还能在从库中读到过期的数据呢?
其实,这是由 Redis 的过期数据删除策略引起的。
Redis使用两种策略来删除过期数据:
- 惰性删除
- 定期删除
惰性删除
当一个数据的过期时间到了以后,并不会立即删除数据,而是等到再有请求来读写这个数据时,对数据进行检查,如果发现数据已经过期了,再删除这个数据。
这样会减少删除操作对CPU资源的使用,但是会导致大量已过期的数据留存在内存中,占用过多内存资源。
定期删除
Redis 每隔一段时间(默认 100ms),就会随机选出一定数量的数据,检查它们是否过期,并把其中过期的数据删除,这样就可以及时释放一些内存。
了解了这两个策略之后,我们可能会发现,如果使用了惰性删除的话就可能不会读取到过期数据了啊?其实不是这样的。
首先,在Redis3.2版本之前,如果使用惰性删除,从裤在服务读请求的时候,并不会判断数据是否过期,而是会返回过期数据。在3.2版本以后,如果读取了过期数据,从库虽然不会删除,但是会返回空值,这就避免了客户端读到过期数据。
而且,就算使用了3.2版本之后的Redis,还是有可能读取到过期数据,因为Redis在从库设置过期时间可能会延后。
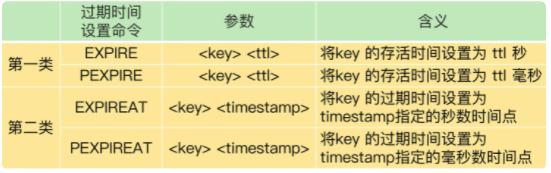
设置数据过期时间的命令一共有 4 个,我们可以把它们分成两类:
- EXPIRE 和 PEXPIRE:它们给数据设置的是从命令执行时开始计算的存活时间;
- EXPIREAT 和 PEXPIREAT:它们会直接把数据的过期时间设置为具体的一个时间点。
比如,当主从库全量同步时,如果主库接收到了一条 EXPIRE 命令,那么,主库会直接执行这条命令。这条命令会在全量同步完成后,发给从库执行。而从库在执行时,就会在当前时间的基础上加上数据的存活时间,这样一来,从库上数据的过期时间就会比主库上延后了。
所以,在业务应用中使用 EXPIREAT/PEXPIREAT 命令,把数据的过期时间设置为具体的时间点,避免读到过期数据。
主从故障切换
主从故障切换时,也会因为配置不合理而踩坑。接下来,我向你介绍两个服务挂掉的情况,都是由不合理配置项引起的。
protected-mode
这个配置项的作用是限定哨兵实例能否被其他服务器访问。当这个配置项设置为 yes 时,哨兵实例只能在部署的服务器本地进行访问。当设置为 no 时,其他服务器也可以访问这个哨兵实例。
正因为这样,如果 protected-mode 被设置为 yes,而其余哨兵实例部署在其它服务器,那么,这些哨兵实例间就无法通信。当主库故障时,哨兵无法判断主库下线,也无法进行主从切换,最终 Redis 服务不可用。
cluster-node-timeout
这个配置项设置了 Redis Cluster 中实例响应心跳消息的超时时间。
当我们在 Redis Cluster 集群中为每个实例配置了“一主一从”模式时,如果主实例发生故障,从实例会切换为主实例,受网络延迟和切换操作执行的影响,切换时间可能较长,就会导致实例的心跳超时(超出 cluster-node-timeout)。实例超时后,就会被 Redis Cluster 判断为异常。而 Redis Cluster 正常运行的条件就是,有半数以上的实例都能正常运行。
所以,如果执行主从切换的实例超过半数,而主从切换时间又过长的话,就可能有半数以上的实例心跳超时,从而可能导致整个集群挂掉。所以,可以将 cluster-node-timeout 调大些(例如 10 到 20 秒)。
小结
- 主从数据不一致。Redis 采用的是异步复制,所以无法实现强一致性保证(主从数据时时刻刻保持一致),数据不一致是难以避免的。我给你提供了应对方法:保证良好网络环境,以及使用程序监控从库复制进度,一旦从库复制进度超过阈值,不让客户端连接从库。
- 对于读到过期数据,这是可以提前规避的,一个方法是,使用 Redis 3.2 及以上版本;另外,你也可以使用 EXPIREAT/PEXPIREAT 命令设置过期时间,避免从库上的数据过期时间滞后。不过,这里有个地方需要注意下,因为 EXPIREAT/PEXPIREAT 设置的是时间点,所以,主从节点上的时钟要保持一致,具体的做法是,让主从节点和相同的 NTP 服务器(时间服务器)进行时钟同步。
- 对于不合理的配置导致服务器挂掉,可以将
protected-mode设置为no;调大cluster-node-timeout
最后,关于主从库数据不一致的问题,还有一点需要注意:Redis 中的slave-serve-stale-data配置项设置了从库能否处理数据读写命令,你可以把它设置为no。这样一来,从库只能服务 INFO、SLAVEOF 命令,这就可以避免在从库中读到不一致的数据了。
不过,需要注意下这个配置项和 slave-read-only 的区别,slave-read-only 是设置从库能否处理写命令,slave-read-only 设置为 yes 时,从库只能处理读请求,无法处理写请求,你可不要搞混了。
以上是关于Redis歇息笔记32——主从切换与故障切换的问题的主要内容,如果未能解决你的问题,请参考以下文章