Redis学习笔记37——数据分布优化:如何应对数据倾斜
Posted qq_34132502
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习笔记37——数据分布优化:如何应对数据倾斜相关的知识,希望对你有一定的参考价值。
在切片集群中,数据会按照一定规则分布在不同的实例上进行保存。但是这很容易导致一个问题:数据倾斜。
数据倾斜分为两种:
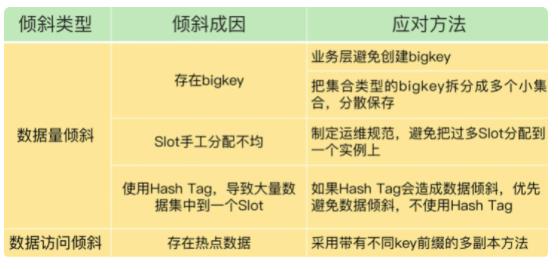
- 数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多。
- 数据访问倾斜:虽然每个集群实例上的数据量相差不大,但是某个实例上的数据是热点数据,被访问得非常频繁。
数据量倾斜
成因
当数据量倾斜发生时,数据在切片集群的多个实例上分布不均衡,大量数据集中到了一个或几个实例上
这主要有三个原因:
- 在某个实例上保存了 bigkey
- Slot 分配不均
- Hash Tag
bigkey导致倾斜
为了避免 bigkey 造成的数据倾斜,一个根本的应对方法是,我们在业务层生成数据时,要尽量避免把过多的数据保存在同一个键值对中。
此外,如果 bigkey 是集合类型,可以把 bigkey 拆分成很多个小的集合类型数据,分散保存在不同的实例上。
slot分配不均导致倾斜
如果集群运维人员没有均衡地分配 Slot,就会有大量的数据被分配到同一个 Slot 中,而同一个 Slot 只会在一个实例上分布,这就会导致,大量数据被集中到一个实例上,造成数据倾斜。
如果某一个实例上有太多的 Slot,我们就可以使用迁移命令把这些 Slot 迁移到其它实例上。
在 Redis Cluster 中,我们可以使用 3 个命令完成 Slot 迁移。
- CLUSTER SETSLOT:使用不同的选项进行三种设置,分别是设置 Slot 要迁入的目标实例,Slot 要迁出的源实例,以及 Slot 所属的实例。
- CLUSTER GETKEYSINSLOT:获取某个 Slot 中一定数量的 key。
- MIGRATE:把一个 key 从源实例实际迁移到目标实例。
Hash Tag 导致倾斜
Hash Tag 是指加在键值对 key 中的一对花括号{}。这对括号会把 key 的一部分括起来,客户端在计算 key 的 CRC16 值时,只对 Hash Tag 花括号中的 key 内容进行计算。如果没用 Hash Tag 的话,客户端计算整个 key 的 CRC16 的值。
举个例子,假设 key 是 user:profile:3231,我们把其中的 3231 作为 Hash Tag,此时,key 就变成了 user:profile:{3231}。当客户端计算这个 key 的 CRC16 值时,就只会计算 3231 的 CRC16 值。否则,客户端会计算整个“user:profile:3231”的 CRC16 值。
使用 Hash Tag 的好处是,如果不同 key 的 Hash Tag 内容都是一样的,那么,这些 key 对应的数据会被映射到同一个 Slot 中,同时会被分配到同一个实例上。

但是,使用 Hash Tag 的潜在问题,就是大量的数据可能被集中到一个实例上
数据访问倾斜
通常来说,热点数据以服务读操作为主,在这种情况下,我们可以采用热点数据多副本的方法来应对。这个方法的具体
这个方法的具体做法是,我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个 Slot 中。这样一来,热点数据既有多个副本可以同时服务请求,同时,这些副本数据的 key 又不一样,会被映射到不同的 Slot 中。在给这些 Slot 分配实例时,我们也要注意把它们分配到不同的实例上,那么,热点数据的访问压力就被分散到不同的实例上了。
但是需要注意,热点数据多副本方法只能针对只读的热点数据。如果热点数据是有读有写的话,就不适合采用多副本方法了,因为要保证多副本间的数据一致性,会带来额外的开销。
对于有读有写的热点数据,我们就要给实例本身增加资源了,例如使用配置更高的机器,来应对大量的访问压力。
小结
造成数据倾斜的原因主要有三个:
- 数据中有 bigkey,导致某个实例的数据量增加;
- Slot 手工分配不均,导致某个或某些实例上有大量数据;
- 使用了 Hash Tag,导致数据集中到某些实例上。
- 热点数据的存在导致访问量倾斜
以上是关于Redis学习笔记37——数据分布优化:如何应对数据倾斜的主要内容,如果未能解决你的问题,请参考以下文章