Function Mesh:Serverless 在消息与流数据场景下的火花
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Function Mesh:Serverless 在消息与流数据场景下的火花相关的知识,希望对你有一定的参考价值。

导语 | Pulsar Functions 是 Apache Pulsar 推出的轻量级、函数式计算架构,借助 Pulsar Functions 无需部署单独系统,即可基于单条消息创建复杂的处理逻辑,简化事件流并引入 Serverless,减轻运维负担。本文由StreamNative 联合创始人、腾讯云TVP 翟佳在 Techo TVP 开发者峰会 ServerlessDays China 2021上的演讲《Function Mesh:Serverless 在消息与流数据场景的创新实践》整理而成,向大家分享。
点击可观看精彩演讲视频
一、Apache Pulsar 是什么?
Function Mesh是StreamNative最新开源的一个项目。Serverless 和K8s结合得非常紧密,Function Mesh 也是同样的初衷。之前我们做的Pulsar Functions 是将 Pulsar 跟 Serverless 做更好的整合。Function Mesh 则方便大家利用云上的资源,更好地管理Functions。
今天的分享主要从四个方向展开。Pulsar的简介、Pulsar Functions和Function Mesh,Pulsar社区。
Pulsar社区为什么诞生,想做什么样的事情?Pulsar最开始是一个消息系统,在雅虎内部诞生,当时是为了解决什么样的问题?在消息这个场景里,可能做基础设施的小伙伴都会明白,由于架构技术的原因,根据不同的场景,需求天然分成两个方向。一个是削峰填谷,内部的相互交互的MQ;另外一个场景,需要做大数据数据引擎,做数据传输的管道。这两个场景的使用场景、数据一致性、技术架构完全不同。2012年,雅虎当时主要面临的问题是各个部门之间也会维护多套系统,在内部就有三四套,相当于整个内部已经发现运维的瓶颈特别厉害,各个部门之间,数据的孤岛变得特别厉害。所以,雅虎当时做Pulsar的最主要的初衷是:对于用户来说,希望做一个统一的数据平台,提供统一的运维和管理,减轻运维压力,提高资源利用率;对于业务部门来说,2012年也是流计算刚刚兴起的时候,大家希望让更多的数据能够打通,让实时计算抓取更多的数据源,得到更精确的计算结果,更好地发挥数据的价值。从这两方面出发,Pulsar的诞生主要提供两个场景的统一,利用同一个平台,解决之前两套在消息相关场景里面的应用。
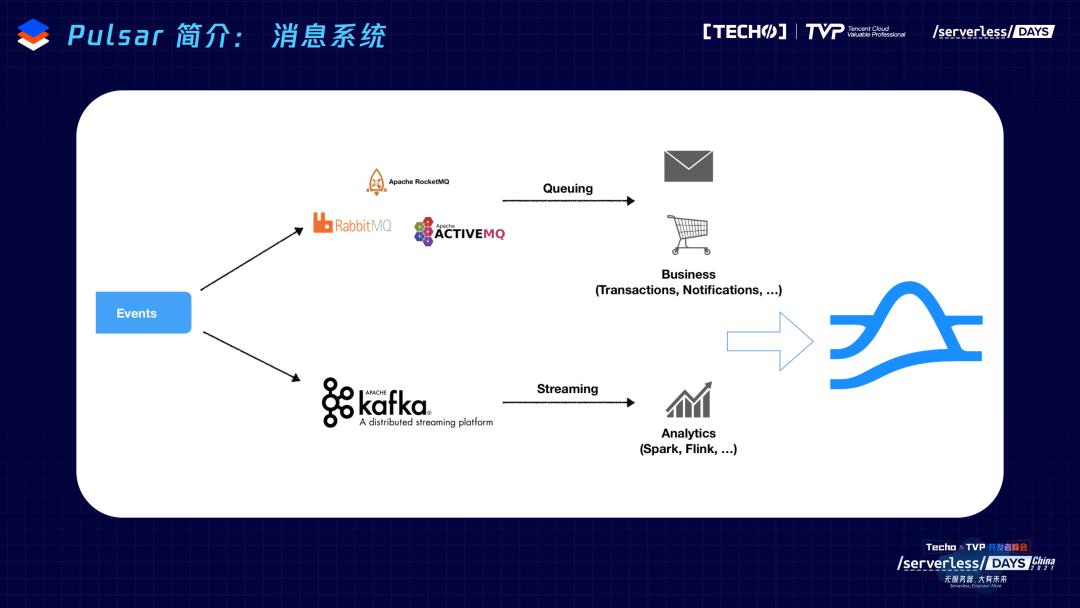
有了这样一个需求,看Pulsar为什么能够做到这样一件事情?与以下两个方面有关:
第一,云原生架构。背后有几个点,首先是服务层-计算层和存储层是完全隔离的状态。在服务层,不会保存任何数据,所有的数据都交给底层的存储层。同时,在对用户暴露的还是逻辑上的分区的概念。这个分区不像其他的系统直接绑定文件系统——绑定单节点文件夹,而是把分区又按照用户指定的大小或者时间划分成了一系列的分片,通过分片模式保证一个分区的数据可以在多个存储节点上做均衡的放置。通过这种策略,它对于每个分区都实现了分布式的存储、更加分布式的逻辑。扩容、缩容的时候也不会带来任何的数据搬迁,这是云原生架构的优势。
在架构上第二点是,节点对等的架构。这和雅虎做大集群、多租户的需求密不可分。只有节点之间状态足够简单,状态维护足够简单,才能维护比较大的集群。在推特内部,底层的存储层有两个机房,每个机房有1500个节点。对这种节点对等来说,上层Broker很好理解,不存储任何数据,所以是leaderless的概念,没有主从之分。在多个备份落到底层存储节点的时候,每个存储节点之间也是对等的状态,要写一个数据,会并发地写多个节点,单节点内部通过CRC保持一致性,但是对多节点的多份数据是并发写入的,所以多个存储节点也是对等的架构。通过这样一套机制,通过本身的cap设计,保持一致性,就有了上面提到存储计算分离的架构,又有节点对等的基础,所以会给扩展、运维、容错带来更好的体验。
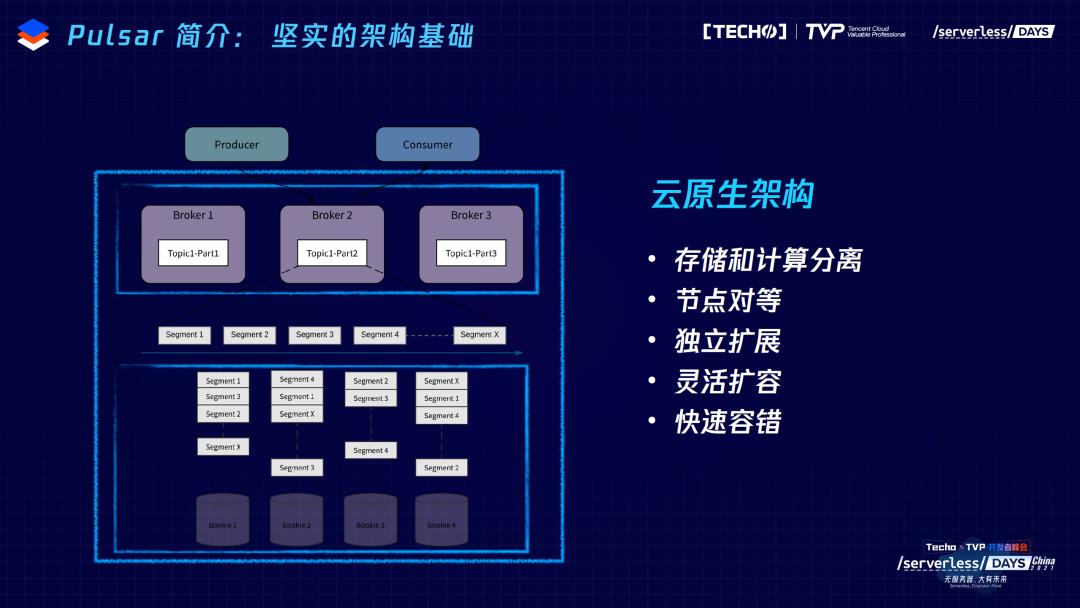
Pulsar另一个特点是有专门为消息流做的存储引擎Apache BookKeeper,BookKeeper是一个更老的系统,是2008、2009年诞生的产品,也是雅虎开源的系统,BookKeeper的诞生主要是为了解决HDFS这一层的HA,它的诞生就是为了保存namenode每一次更改,诞生之初就是为了保存元数据的元数据。所以,对一致性、低延迟、吞吐,可靠性都有特别高的要求。但是,它的模型很简单,就是一个write-ahead-log的抽象。这跟我们的消息很匹配,因为消息主要的模式也是append only 追尾写,随着时间流逝,之前老的数据价值可能会越来越低,再整体删除。
有了这样一个BookKeeper可以提供比较稳定的服务质量,一致性又特别高的支持,Pulsar就有能力支撑刚刚提到的MQ的场景;同时由于log这种简单抽象,基于数据追加写的模式提高数据的带宽,支持了流的模式。MQ、Kafka 两种场景,都通过底层的存储层提供很好的支持,通过底层的存储层得到保障。

有了前面的基础,要构建Pulsar底层对于用户特别实用的企业级feature也会特别容易。Pulsar诞生的原因,是需要有一个大集群,多租户。在这一层对于用户来说,每一个topic不再是单级的概念,而是类似于文件系统里面文件夹,是一级目录,二级目录层级的管理。第一级目录就是我们的租户,主要给用户提供更多的隔离策略,可以给每个租户分不同的权限,每个租户的管理员管理跟其他的租户、内部各个用户之间权限的管理,比如让不让第一个租户访问第二个租户的信息?类似这种鉴权的信息。
再往下,namespace这层存的是各种策略,可以方便做很多企业级的控制,比如流控;最底层就是我们说的topic。通过层级的概念、大集群的支持,可以更方便地打通用户内部各个组织、各个部门之间的数据。

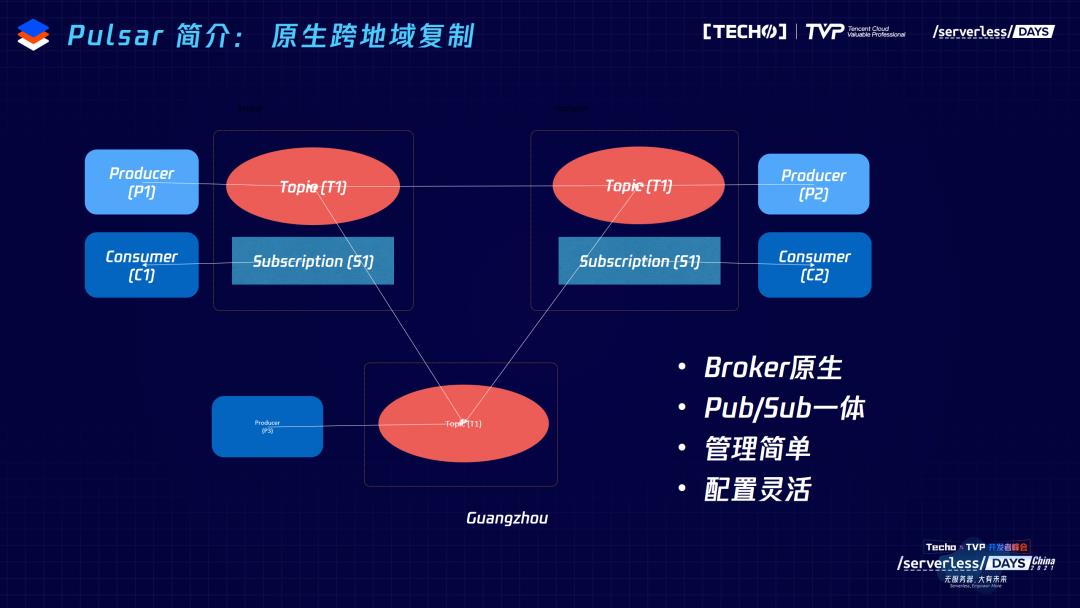
另外,Pulsar由于有很好的数据一致性,也有很多用户把它用在跨集群复制的场景里。Pulsar的跨区域复制,是broker自带的内嵌的功能,用户如果需要这个功能,简单地调Pulsar的命令,就可以完成跨级群的搭建。内部内嵌的producer可以把本地刚刚落盘的数据直接同步到远端机房,时效性特别高。用户的体验是配置起来特别简单,用起来效率特别高,延迟特别低,同时又能够提供很好的数据一致性的保障。所以,在很多的场景里有很丰富的应用,包括腾讯内部、苏宁内部,很多用户都是因为单一的场景而选择了Pulsar。
因为有了这些基础,Pulsar在社区里的增长也是特别显著的。现在社区里有403 contributors,github star数接近9000。十分感谢腾讯云有很多小伙伴对Pulsar做了很多很有用,很丰富的场景检验。
二、Pulsar Functions
Pulsar诞生之初还是从消息的领域出发,我们通过云跟整个生态做打通。今天跟大家讨论的主要集中在计算层下面的Functions,在计算层做一个详细的展开。在我们常用的大数据计算里面,大概分为三种:交互式的查询,Presto是一个比较常用的场景;再往下比如批处理、流处理,相应的Spark、Flink等都是用户常用的,上面这两种,Pulsar做的事情是提供对应connector的支持,让这些引擎能够理解Pulsar的schema,直接把Pulsar一个主题当做一个表来读取和使用。Functions的概念是我今天想跟大家重点展开的重点,它是一个轻量级的计算,跟上面复杂的计算场景,完全不是一个同样的概念。这个图可能比较直观,内部相当于是把用户常用的在消息的场景里面要做的简单计算的场景抽象出来,提供Functions的抽象。Function 左边内嵌consumer会订阅产生的消息,中间用户体检的函数提供计算,右边producer会把用户传进来的函数、计算的结果再写回到目的的topic,通过这样一种模式,把用户常用的中间需要创建、管理、调度副本数等信息作为统一的基础设施提供出来。
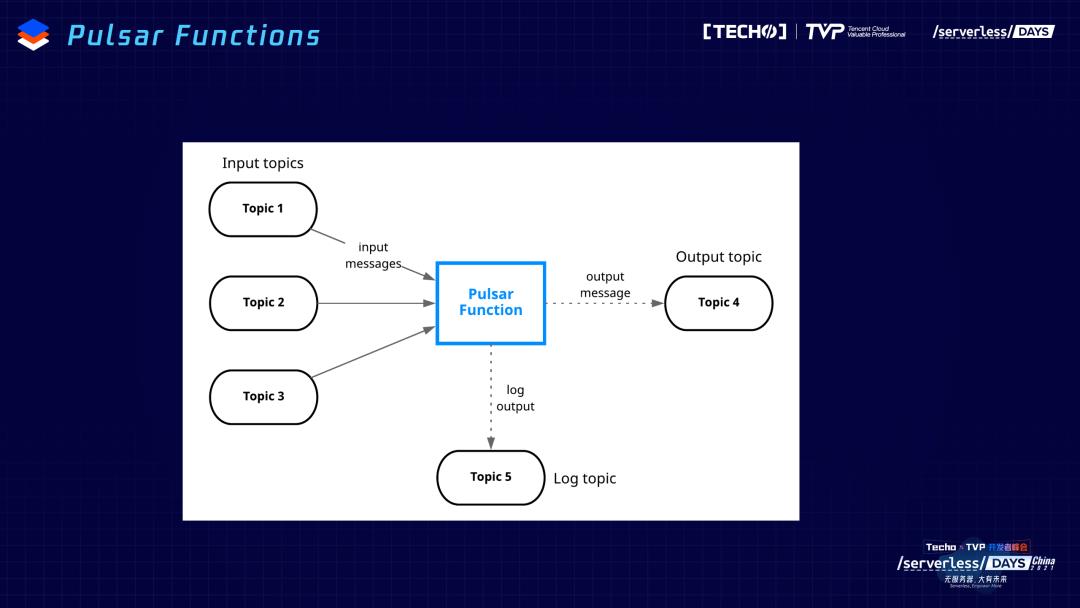
现场有同学问topic是什么概念?topic跟消息领域比较相关,是管道的抽象,是一个载体,所有的数据都通过topic做一个缓存,producer会产生消息交给topic。consumer再按照生产的顺序,用topic做消费,就是一个缓存的载体、管道。
Pulsar Functions不是要再做复杂的计算引擎,主要想把 Serverless 的理念跟消息系统做更好的结合,让Pulsar本身在消息端、数据端就能够处理很多轻量级的数据。常见的场景,比如ETL、aggregation等很简单的场景,大概占到整个数据处理量的60%—70%。特别是在IoT场景里会占到百分之八九十。对于这样一些简单的场景,通过简单的Function Mesh处理,不需要再构建复杂的集群。简单的计算都可以在我们的消息端做完处理,这些资源可以节约下来,传输的资源、计算资源都可以得到很好的节约的利用。
给大家做一个简单的演示,Functions对于用户来说是什么样的体验?这个函数需要处理的事情很简单,我对于一个topic,用户扔进来的数据“hello”,对它添加一个感叹号。对于用户这样一个函数,无论什么语言,都可以在我们的Functions里面有对应的运行时来做支持。在这个过程中,用户不需要学习任何新的逻辑,不需要学习新的API,熟悉什么语言就可以用什么语言做一个编写。编写完之后交给Pulsar Functions,Functions会订阅传进来所有的数据,根据这个数据做函数里相应的处理。

Functions跟 Serverless有关,大家的理念是一样的,跟消息做很好的结合,用 Serverless 的方式处理消息,处理计算。但是跟 Serverless 不太一样的地方是,跟数据的处理比较相关,会有各种语义的支持。在Pulsar Function内部,也提供三种语义灵活的支持。
同时,在Function Mesh内部内嵌了状态的存储,把做中间计算的结果保存到BookKeeper本身。比如要做一个统计,用户传进来的是一个句子,会把句子分成多个分词,每个词可以统计它出现的次数,这样一个次数的信息就可以记到Pulsar本身,这样的话可以通过简单的函数,完成要做的统计在topic里面出现的次数,实时更新。同时,Pulsar内部做了基于REST的admin接口,让用户更方便地使用、调度、管理Pulsar Function。背后它其实是一个REST API,可以通过自己的编程,直接调用接口,和用户应用做更好的集成。
简单地总结,Pulsar Functions简单来说就是为你的应用中、生态中的各个小伙伴都提供比较好的体验,比如对于你的开发者来说,它可以支撑各种各样的语言。我们最近也在做web的支持。另外,可以支撑不同的模型,最简单的方式可以把它扔在broker上,同时run成process的模式。部署模式也很灵活,如果资源很有限,那就部署在broker上,让它跟broker一起运行。如果需要更好的隔离性,可以拿出来单独做一个集群,通过这个集群运行你的Functions。在Function Mesh之前,我们提供了很简单的Kubernetes的支持。
它给大家带来的好处,对于使用者来说,会更加容易,因为使用者可能都是大数据的专家,熟悉各种语言,就可以根据自己熟悉的语言来编写这套逻辑。它的操作也特别简单,因为本来做大数据的处理,很多需要Pulsar。既然熟悉Pulsar,也可以跟Pulsar很好地做一个集成。有了Pulsar,跟broker运行在一起,不用另外的server。在我们的开发和部署里,也提供了一个local run的模式,用户可以很方便地调试Functions,对在整个计算的路径上各个使用者来说,Pulsar Functions都提供了很好的体验和很丰富的工具支持。
三、Function Mesh
但是,虽然有K8s支持,但之前不是原生的支持。之前用户是怎么调用Functions?Functions可以和broker部署在一起,现在在每个broker有一个Functions woker,对应Functions所有管理和运维的接口,用户提交Functions到Functions worker,再把Functions一些源数据的信息保存到Pulsar内部的topic里面。在调度的时候告诉K8s去topic里面拿源数据、有几个副本,从源数据里面读出来,然后起对应数据量Functions的实例。
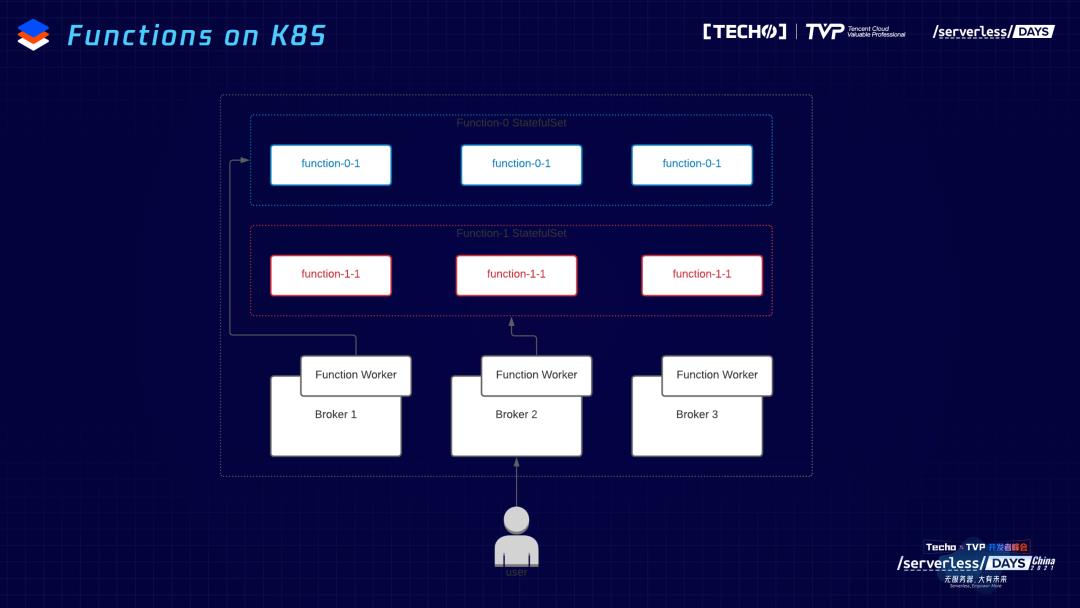
这个过程有一些不友好的地方。它的源数据本身是存储在Pulsar的topic里面,会带来一个问题,很多用户把Functions woker提起来,读topic本身的数据,获取源数据的信息,如果topic服务的broker没起来,会有一个循环crush,等到真正服务Functions worker源数据的broker起来之后,才会起来。另外,这个过程中有两部分源数据的管理,第一部分提交到Functions worker里,保存在Pulsar本身,同时会调Kubernetes,把源数据又交了一份,这样的话源数据管理就会比较麻烦。一个很简单的例子,已经把Functions交给Kubernetes,两边没有相互协调的机制。第三,做扩容、动态管理、弹性伸缩,本身就是Kubernetes很大的优势,如果再做一遍这样的事情,可能跟Kubernetes是重复的过程。
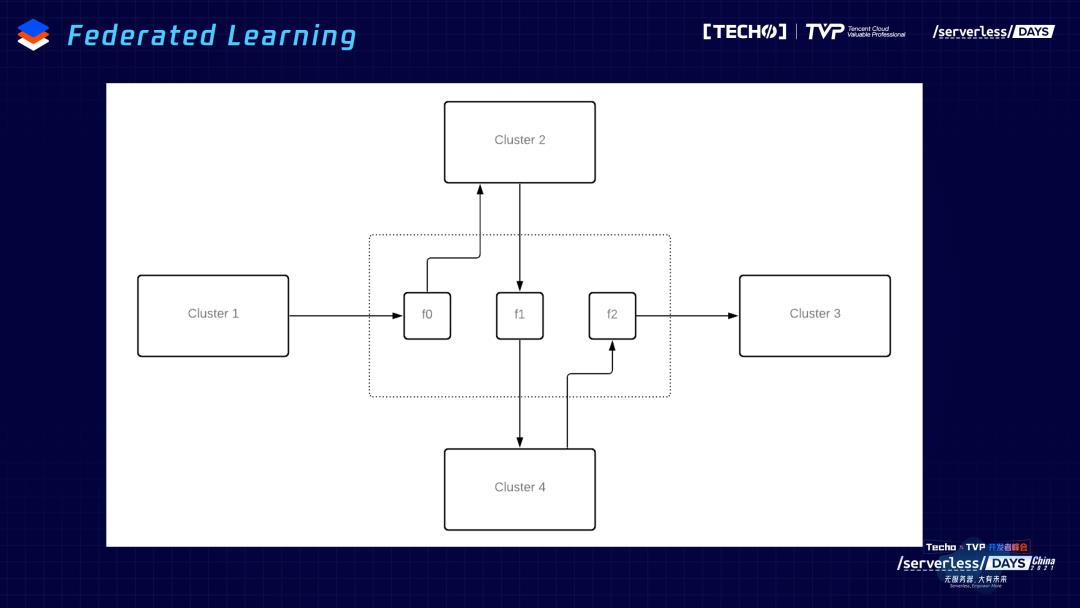
第二个问题,也是很多Pulsar Functions的用户提到的问题,Pulsar Functions运行在cluster里,很多场景不限cluster内部,需要跨多个cluster,这个时候交互会变得比较复杂。比如联邦学习的场景,用户希望数据交给Functions帮着训练,再把模型写到集群里,但是有很多场景,联邦学习Functions训练的是A用户的数据,把训练的结果写到B用户里,这个时候需要跨集群的操作。之前的操作绑定在一个集群内部,很难做到Functions跨集群级别的共享。
还有一个问题是我们当时做Pulsar Functions最直接、主要的原因,我们发现用户不是处理简单的一个问题只用一个函数,有可能需要把多个Function做一个串联,希望把多个函数多个Function作为一个整体,来做运营和管控。用之前的模式,会写很多这样的命令,而且每个命令的管理也会特别复杂,而且命令订阅、输出的topic,之间的关系很难掌控,不能做一个直观描述,管理和运维会特别麻烦。
Function Mesh主要的目的不是做更复杂的、全量的、对所有的计算都通用的框架,而是提供更好的管理,让用户更方便使用function的一个工具。比如刚刚提到的多个Function之间需要做串联,作为一个整体,给用户提供服务。所以,有了这样一个简单的需求,我们在2020年8、9月份提了一点proposal,想得很简单:希望有一个统一的地方,来描述输入和输出的关系,这样一眼就能够看出来,第一个Function的输出就是第二个Function的输入,它们之间的逻辑就可以通过yaml file做很好的描述,用户一眼就知道这两个Function之间组合的关系。
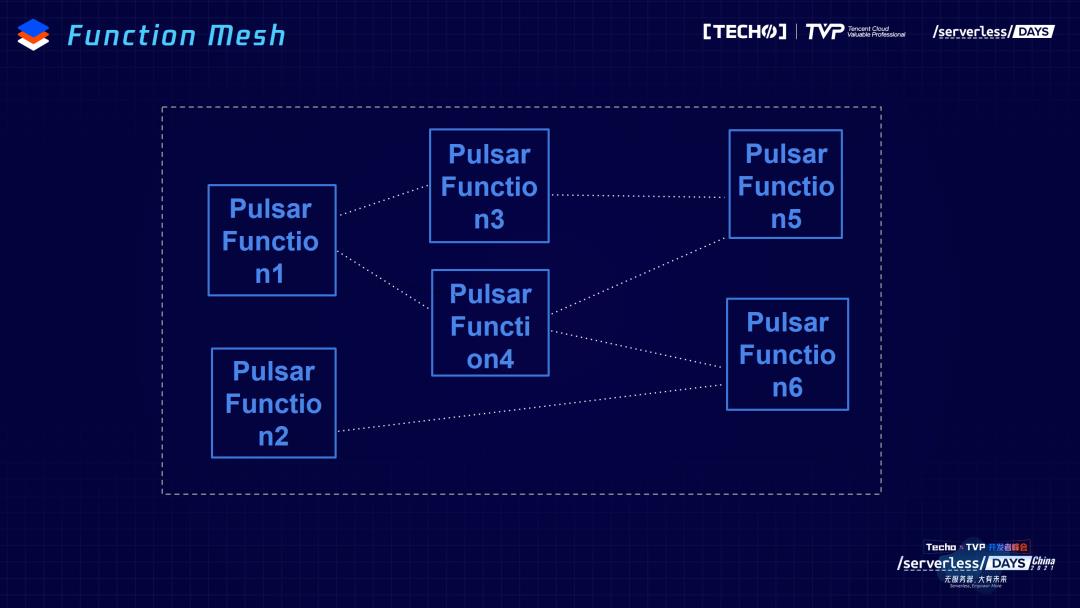
假如再把刚刚提到的逻辑和K8s做更好的整合,可以结合Kubernetes本来有的调度和弹性策略,为用户提供更好的管理和使用的体验。Pulsar Functions、Function Mesh主要以Kubernetes CRD作为核心,把每一个Function的类型,比如我们常见的Function,还有Source、Sink(相当于是Function的特例),把订阅的topic产生的数据输出到指定的地方,或者是从指定的源头(比如从数据库里)把数据输出,是Function的特例。
CRD描述Function要起几个并发,要怎么运行,前后topic之间串联的关系。CRD之外,会有Function Mesh的controller,负责具体的调度和执行。这样对于用户的体验首先从最左边来说,用户交给K8s里边,帮你描述好了各个Function之间串联的关系,同时又描述了最大、最小的并发度,需要的一些资源的信息,都可以通过yaml file来描述。yaml file交给K8s后,通过API server开始调度内部的资源,同时也会监控改变,如果有CRD描述改变了,那就会根据改变再更改pod信息,就是扩缩pod,pod和Pulsar cluster的信息更加清晰,不保存任何的信息,它作为数据的源头,或者数据的出口,只是数据的管道,不会涉及到所有元数据的管理。它的feature是刚刚提到的想要结合K8s给用户带来更好的体验,借助K8s可以很好地实现基于CPU的弹性扩缩容。
K8s有弹性的调度,可以给Function的运维带来更好的体验。CRD一旦改变,可以根据CRD的描述,控制pod的增删改。也是通过这样一种模式,运行在K8s之上,和单个pulsar的cluster是完全解耦的关系,通过这种模式,让多个cluster之间的Function共享和打通。
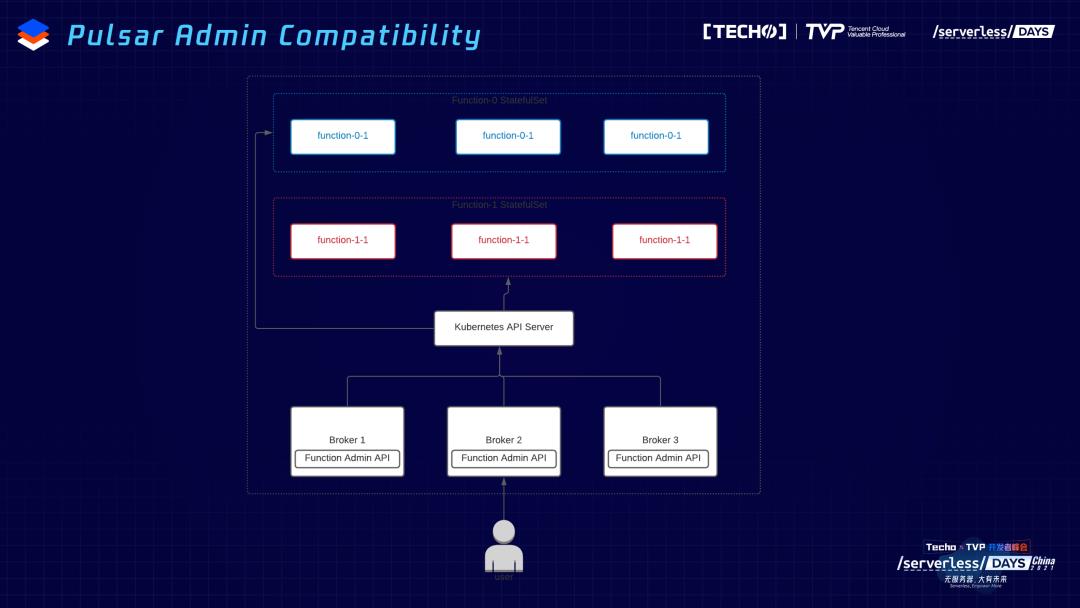
我们最近在做一个工作,想要通过Function Package Management的工具,减轻用户在操作相关的难度,应该在2.8的版本里跟大家见面。我们做Function Mesh的初衷,主要还是方便用户使用Pulsar Function,在这个基础之上,之前的接口通过rest接口做访问,所以也做了往前的兼容。基于现在的K8s,API的实现,Function Admin做了打通,用户可以通过之前的接口做管控。之前的老用户,如果不习惯直接提交CRD、提供变更方式,也可以通过这种模式拥有跟之前一样操作的体验。
四、Pulsar社区
后面是社区的情况。腾讯是Pulsar社区很重要的贡献者,之前在第一个很关键的业务场景里,提到了腾讯的计费平台,所有的业务通过Pulsar走一遍,包括微信的红包、腾讯游戏很多的计费。当时腾讯内部也调研了其他的系统,最后做了一个这样的权衡,因为Pulsar有很好的一致性,有很好的数据的堆积和运维能力,特别是云原生的架构,能够减轻大规模集群运维的痛点。
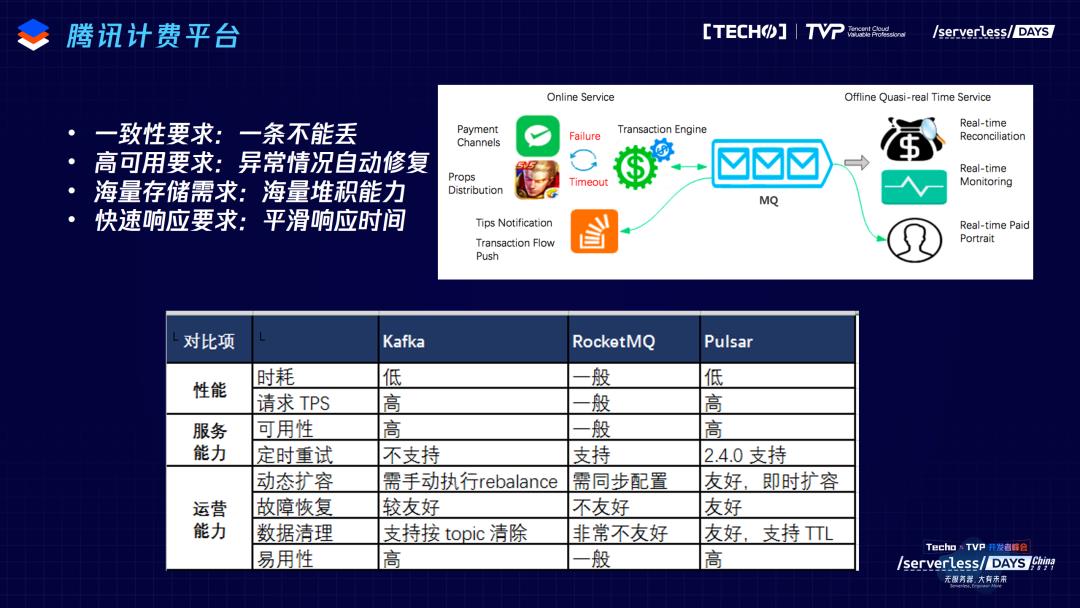
另外一个典型的场景,是在大数据场景里,需要用Kafka,对Kafka来说,这是大集群用户很常见的问题,存储计算和绑定。之前有一篇文章介绍了一些案例做了一些总结,比如存储计算绑定带来运维的不方便,扩缩容会带来集群性能下降。Kafka里有一个很头疼的问题是reblance,一旦要扩容缩容,会自动触发reblance,把topic从一个节点搬到另一个节点达到数据的再均衡。在这个过程中,搬数据可能会对线上业务带来一定的影响,因为把集群之间的带宽或者网络带宽给占了,对外部业务可能响应不及时。出现数据丢失。mirror maker性能和稳定性的问题等。其实最主要的问题还是我们提到扩缩容的问题,Bigo内部发现扩缩容极大消耗人力,也是由于这些原因,他们从Kafka的集群切换到Pulsar的集群,最近跟腾讯的小伙伴给Pulsar贡献的很重要的feature,叫KoP,在server端做Kafka协议的解析,通过这种方式,让用户得到零成本的迁移。
这个图主要是想跟大家介绍用Function的一些用户。它的场景很多是轻量级的,特别是IoT场景下,比如EMQ是Pulsar Function很早期的用户,之前的涂鸦智能、丰田智能等等都是IoT的场景,应用里面用了很多的Functions。

社区的增长有一个值得关注的点,从2019年起增长变得更加快速,这是开源社区很常见的现象,每一个开源社区背后都会有一个商业化公司。我们公司是2019年成立的,商业化公司和之前开源Pulsar的雅虎的目的不太一样。雅虎的目的是希望让更多的用户用Pulsar,帮忙打磨,但是没有很强的动力维护社区,花更大的精力开发更多的feature吸引社区用户。但这是我们商业公司的目的,依靠社区做自己的商业化,做自己的成长。所以公司成立之后,我们就会做很多开发者的沟通和协调,帮助开发者更方便地使用Pulsar,提供更多的功能来满足用户的需求。

最后是相关的社区信息,欢迎想要了解更多信息的小伙伴,通过这些渠道,找到Pulsar更多的资源。这些资源包括在B站上有很多很丰富的视频资源,其他的Apache常用的邮件列表; slack里有4000多位用户,中美大概各占一半。右边是维护的两个微信公众号,Pulsar社区和我们公司的,大家如果对Pulsar感兴趣或者对社区的工作机会感兴趣,也欢迎扫码获取更多信息,这就是今天跟大家分享的主要内容,感谢大家的时间。

讲师简介

翟佳
StreamNative 联合创始人,腾讯云TVP
StreamNative 联合创始人,腾讯云TVP。在此之前任职于 EMC,担任北京 EMC 实时处理平台技术负责人。主要从事实时计算和分布式存储系统的相关开发,在开源项目 Apache BookKeeper, Apache Pulsar 等项目中持续贡献代码,是开源项目 Apache Pulsar 和 Apache BookKeeper 的 PMC 成员和 Committer。
推荐阅读
用了 Serverless 这么久,这里有其底层技术的一点经验
Serverless + 低代码,让技术小白也能成为全栈工程师?

???? 错过了直播懊悔不已?本次峰会所有嘉宾的演讲视频回顾上线啦,点击「阅读原文」即可观看~
???? 看视频不过瘾还想要干货PPT?关注本公众号,在后台回复关键词「serverless」即可获取!

以上是关于Function Mesh:Serverless 在消息与流数据场景下的火花的主要内容,如果未能解决你的问题,请参考以下文章
CNCF调查报告:容器与Serverless大火Service Mesh采用率不高
微服务DockerKubernetesServerlessService Mesh 及更多
MATLAB中mesh函数的使用:基于像素强度画3D密度图(create a 3D density plot based on the pixel intensity:mesh function)(代
极致体验!基于阿里云 Serverless 快速部署 Function