TensorFlow2实现空间自适应归一化(Spatial Adaptive Normalization, SPADE)
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow2实现空间自适应归一化(Spatial Adaptive Normalization, SPADE)相关的知识,希望对你有一定的参考价值。
TensorFlow2实现空间自适应归一化(Spatial Adaptive Normalization, SPADE)
空间自适应归一化(Spatial Adaptive Normalization, SPADE)
空间自适应归一化(Spatial Adaptive Normalization, SPADE)是GauGAN中的主要创新点,其用于语义分割图的层归一化,为了更好的解释SPADE,需要首先了解GauGAN网络输入——语义分割图。
使用独热编码标记分割蒙版
考虑训练GauGAN所用的Facades数据集。其中,分割图在RGB图像中被编码为不同的颜色,如下图所示。例如,一堵墙以蓝色表示,柱子以红色表示。这种表示在视觉上让我们易于理解,但对神经网络的学习并没有帮助,这是因为对于GAN而言,颜色没有语义。
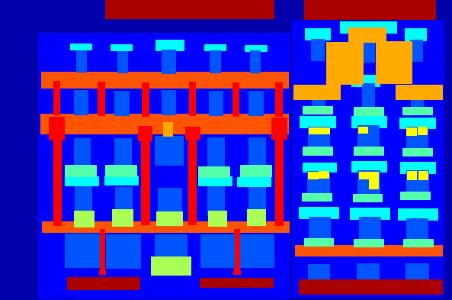
颜色在颜色空间中更接近并不意味着它们在语义上也接近。例如,我们可以用浅绿色表示草,用深绿色表示飞机,即使分割图的色相接近,它们的语义也不相关。
因此,我们应该使用类标签,而不是使用颜色来标记像素。但是,这仍然不能解决问题,因为类别标签是随机分配的数字,并且它们也没有语义。因此,一种更好的方法是在该像素中存在对象时使用标签为1的分割蒙版,否则使用标签为0的分割蒙版。换句话说,我们将分割图中的标签独热编码为形状(H, W, number of classes)的分割蒙版。
在JPEG编码中,在压缩过程中会删除一些对视觉效果不太重要的视觉信息。即使结果像素应该属于同一类并且看起来是相同的颜色,它们也可能具有不同的值。因此,我们无法将JPEG图像中的颜色映射到类。为了解决这个问题,我们需要使用未压缩的图片格式BMP。在图像加载和预处理中,我们将加载文件,并将它们从BMP转换为独热编码的分割蒙版。
有时,TensorFlow的基本图像预处理API无法执行一些复杂的任务,因此我们需要使用其他Python库,tf.py_function允许我们在TensorFlow训练流程中运行通用Python函数:
def load(image_file):
def load_data(image_file):
jpg_file = image_file.numpy().decode('utf-8')
bmp_file = jpg_file.replace('.jpg', '.bmp')
png_file = jpg_file.replace('.jpg', '.png')
image = np.array(Image.open(jpg_file))/127.5-1
map = np.array(Image.open(png_file))/127.5-1
labels = np.array(Image.open(bmp_file), dtype=np.uint8)
h,w,_ = image.shape
n_class = 12
mask = np.zeros((h,w,n_class),dtype=np.float32)
for i in range(n_class):
one_hot[labels==i,i] = 1
return map, image, mask
[mask, image, label] = tf.py_function(load_data, [image_file], [tf.float32, tf.float32, tf.float32])
了解了独热编码的语义分割掩码的格式后,我们将使用TensorFlow2实现SPADE。
实现SPADE
实例归一化已在图像生成中非常流行,但是它往往会削弱分割蒙版的语义:假设输入图像仅包含一个分割标签;例如,假设整个图像都是天空,由于输入具有统一的值,因此输出在通过卷积层后也将具有统一的值。
实例归一化为每个通道计算跨维度(H, W)的平均值。因此,该通道的均值将是相同的统一值,并且用均值减去后的归一化激活将变为零。显然,语义已经丢失,这是一个十分极端的示例,但是逻辑是相似的,我们可以看到分割掩码随着其面积的增大而失去了其语义含义。
为了解决这个问题,SPADE规范化了由分割蒙版限定的局部区域,而不是整个蒙版。下图显示了SPADE的体系结构:
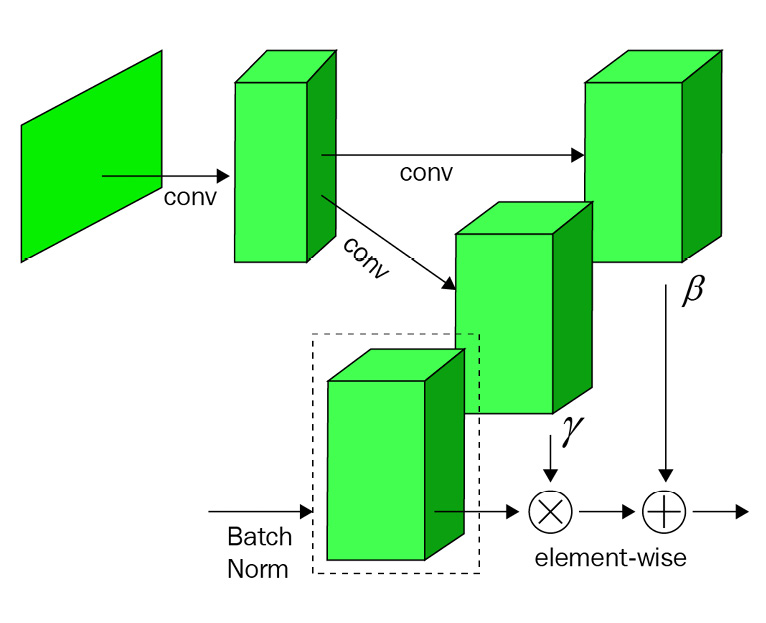 在批归一化中,计算跨维度
在批归一化中,计算跨维度(N, H, W)的通道的均值和标准差,对于SPADE来说是相同的。区别在于,每个通道的γ和β不再是标量值,而是二维向量,形状为(H, W)。换句话说,对于每个从语义分割图中获悉的激活,都有一个γ和β值。因此,归一化被不同地应用于不同的分割区域。这两个参数是通过使用两个卷积层来学习的,如下图所示:
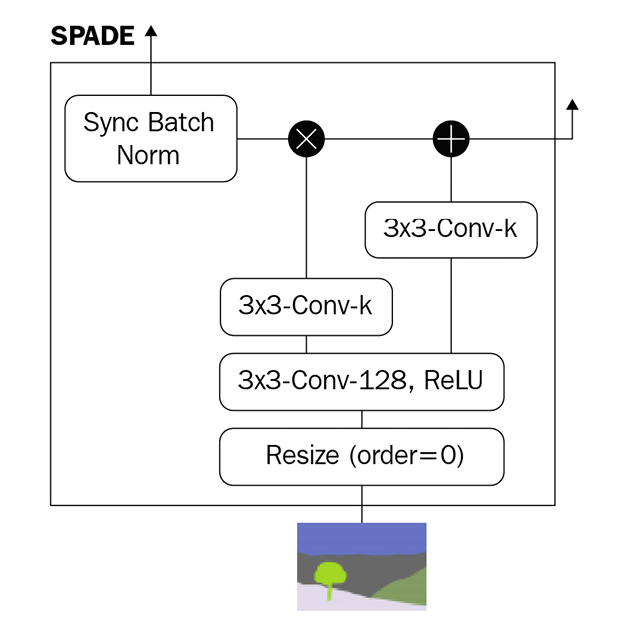
SPADE不仅应用于网络输入阶段,同样还应用于内部层。现在,我们可以为使用TensorFlow2的自定义层实现SPADE。
将首先在__init__构造函数中定义卷积层,如下所示:
class SPADE(layers.Layer):
def __init__(self, filters, epsilon=1e-5):
super(SPADE, self).__init__()
self.epsilon = epsilon
self.conv = layers.Conv2D(128, 3, padding='same', activation='relu')
self.conv_gamma = layers.Conv2D(filters, 3, padding='same')
self.conv_beta = layers.Conv2D(filters, 3, padding='same')
接下来,获得激活图尺寸,以在以后调整大小时使用:
def build(self, input_shape):
self.resize_shape = input_shape[1:3]
最后,在call()中将层和操作连接在一起,如下所示:
def call(self, input_tensor, raw_mask):
mask = tf.image.resize(raw_mask, self.resize_shape, method='nearest')
x = self.conv(mask)
gamma = self.conv_gamma(x)
beta = self.conv_beta(x)
mean, var = tf.nn.moments(input_tensor, axes=(0,1,2), keepdims=True)
std = tf.sqrt(var+self.epsilon)
normalized = (input_tensor - mean) / std
output = gamma * normalized + beta
return output
接下来,我们将研究如何利用SPADE。
在残差网络中应用SPADE
最后,将研究如何将SPADE插入残差块中:
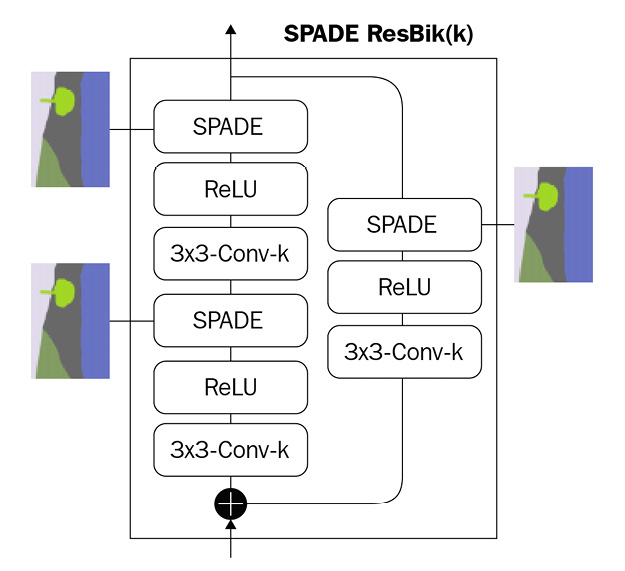
SPADE残差块中的基本构建块是SPADE-ReLU-Conv层。每个SPADE都接受两个输入——上一层的激活和语义分割图。
与标准残差块一样,有两个卷积ReLU层和一个跳跃路径。只要残差块之前和之后的通道数发生变化,就需要进行学习跳跃连接连接。发生这种情况时,前向路径中两个SPADE的输入处的激活图将具有不同的尺寸。但是,我们已经在SPADE块中内置了调整大小的功能。以下是用于SPADE残差块构建所需图层的代码:
class Resblock(layers.Layer):
def __init__(self, filters):
super(Resblock, self).__init__()
self.filters = filters
def build(self, input_shape):
input_filter = input_shape[-1]
self.spade_1 = SPADE(input_filter)
self.spade_2 = SPADE(self.filters)
self.conv_1 = layers.Conv2D(self.filters, 3, padding='same')
self.conv_2 = layers.Conv2D(self.filters, 3, padding='same')
self.learned_skip = False
if self.filters != input_filter:
self.learned_skip = True
self.spade_3 = SPADE(input_filter)
self.conv_3 = layers.Conv2D(self.filters, 3, padding='same')
最后,在call()中将各层连接起来:
def call(self, input_tensor, mask):
x = self.spade_1(input_tensor, mask)
x = self.conv_1(tf.nn.leaky_relu(x, 0.2))
x = self.spade_2(x, mask)
x = self.conv_2(tf.nn.leaky_relu(x, 0.2))
if self.learned_skip:
skip = self.spade_3(input_tensor, mask)
skip = self.conv_3(tf.nn.leaky_relu(skip, 0.2))
else:
skip = input_tensor
output = skip + x
return output
以上是关于TensorFlow2实现空间自适应归一化(Spatial Adaptive Normalization, SPADE)的主要内容,如果未能解决你的问题,请参考以下文章