人工智能系列 之Hadoop平台介绍及应用1
Posted 琅晓琳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能系列 之Hadoop平台介绍及应用1相关的知识,希望对你有一定的参考价值。
1 前言
1.1 大数据的4V特征:容量、种类、速度和价值:
容量:1 PB = 1024TB = 1024×1024GB = 1024×1024×1024MB = 1024×1024×1024×1024KB;
种类:结构化数据、非结构化数据和半结构化数据(如html和XML文档);
价值:价值密度低是大数据的一个显著特征;
速度:增长和处理速度快,时效性高。
1.2 Hadoop:Apache Lucene 创始人 Doug Cutting 创建的,最早起源于 Apache Nutch 项目。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题 ——如何解决数十亿网页的存储和索引问题:
分布式文件系统:Google File System;
分布式计算框架:MapReduce;
分布式数据库:BigTable。
本质:分布式的操作系统,利用集群的多个节点共同协同完成一项或者多项具体业务功能的系统。
2 Hadoop的核心组件
基础功能组件:Common;
分布式文件系统:HDFS:
HDFS适合存储海量数据的分布式文件系统,在HDFS中,1个文件会被拆分成多个Block,每个Block默认大小为128M(可调节),这些Block被复制为多个副本;
分布式运算框架:MapReduce:
input—>splitting—>record reader—>mapping—>shuffing—>reduce
shuffing:数据从map中出来到进入reduce之前称为shuffle阶段,shuffle的处理任务:将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
运算资源调度系统:YARN:
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。通过YARN,不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度。
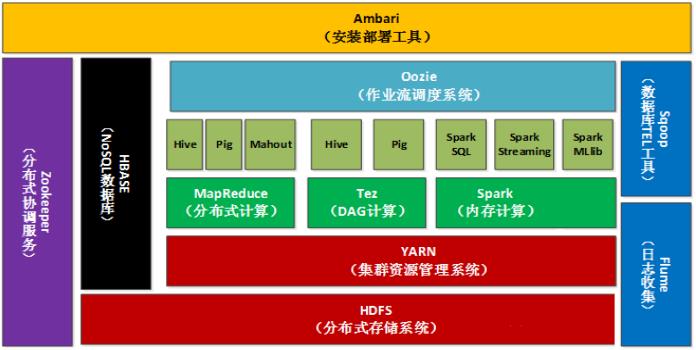
Ambari(安装部署配置管理工具):创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具;
Zookeeper(分布式协作服务):Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作;
HBase(分布式列存储数据库):HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,采用了BigTable的数据模型,增强的稀疏排序映射表(Key/Value);
Oozie(工作流调度器):Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行;
Hive(基于 Hadoop 的数据仓库工具):Hive 的本质是将 HQL 语句转换为MapReduce 任务运行,使不熟悉 MapReduce 编程的用户很方便地利用HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算,即联机分析处理;
Flume(日志采集工具):Flume 是由 Cloudera 软件公司开发的高可用的分布式日志收集系统,2009年捐赠给Apache 软件基金会,成为 Hadoop 生态圈成员;
Sqoop(数据迁移工具):Apache Sqoop™ 是一个用于在 Apache Hadoop 和结构化数据存储(如关系数据库)之间高效地传输大量数据的工具。Sqoop 于2012年3月成功从孵化器升级成为 Apache 顶级项目;
Pig(ad-hoc脚本):由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具;
Spark(内存DAG计算模型):Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
3 Hadoop中的Namenode、Datanode和Secondary Namenode等概念
Namenode:Namenode 管理着文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据;
Secondary Namenode:Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份;
Datanode:Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表;
NodeManager:NodeManager管理一个YARN集群中的每一个节点。比如监视资源使用情况( CPU,内存,硬盘,网络),跟踪节点健康等;
ResourceManager:ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager);
JournalNode:两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。
4 参考资料:
https://blog.csdn.net/weixin_40535323/article/details/82025442 Hadoop学习(二)Hadoop三大核心组件
https://blog.csdn.net/qq_25062299/article/details/95592877 大数据Hadoop生态圈介绍
https://www.cnblogs.com/hanzhi/articles/8969109.html HADOOP生态圈介绍
https://blog.csdn.net/lvtula/article/details/82354989 hdfs的namenode、datanode和secondarynamenode
https://blog.csdn.net/leanaoo/article/details/83279235 Hadoop中JournalNode的作用
以上是关于人工智能系列 之Hadoop平台介绍及应用1的主要内容,如果未能解决你的问题,请参考以下文章