2.Kong入门与实战 基于Nginx和OpenResty的云原生微服务网关 --- Kong 的安装和基本概念
Posted enlyhua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.Kong入门与实战 基于Nginx和OpenResty的云原生微服务网关 --- Kong 的安装和基本概念相关的知识,希望对你有一定的参考价值。
2.1 Kong 的安装部署
2.1.1 环境介绍
2.1.2 直接安装
yum install epel-release
yum install kong-2.0.0.el7.amd64.rpm --nogpgcheck
kong version
2.1.3 容器安装
docker pull kong:2.0
2.1.4 Kubernetes 安装
2.2 Kong 数据库的安装部署
kong 数据库支持 PostgreSQL,Cassandra和DB-less(无数据库)三种安装模式。
2.2.1 PostgreSQL
2.2.2 Cassandra
2.2.3 DB-less
DB-less 模式,此时使用 yaml 或者 json 文件直接进行声明式配置即可。
DB-less模式与声明式配置相组合,具有以下优势:
1.减少过多依赖:所有配置都加载在内存中,不需要数据库的安装和管理。
2.适用于CI/CD场景:配置文件可以保存在git中,方便使用。
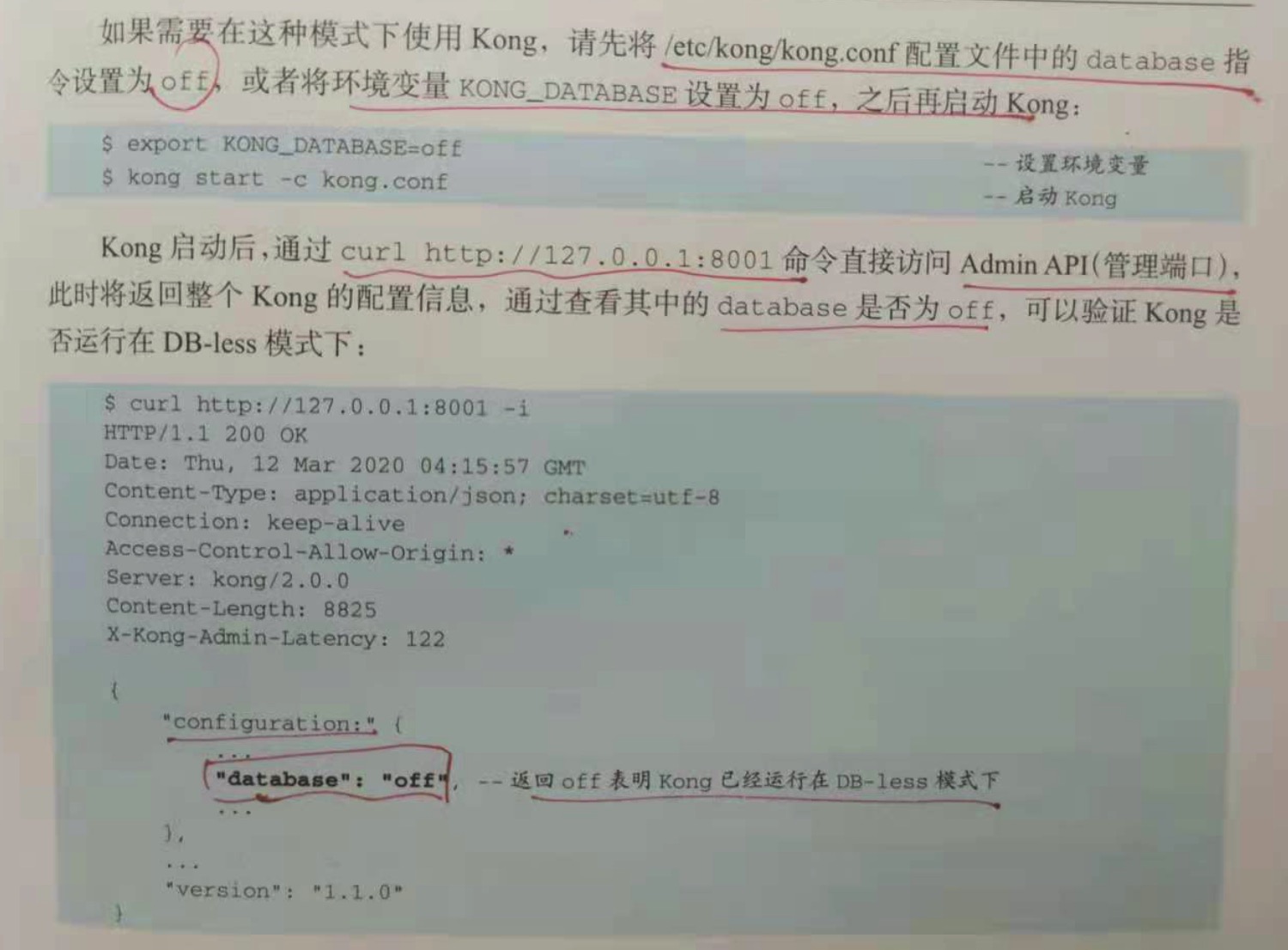
如果需要在这种模式下使用Kong,请先将 /etc/kong/kong.conf 配置文件中的 database 指令设置为 off,或者将环境变量 KONG_DATABASE
设置为 off,之后再启动 kong:
export KONG_DATABASE=off
kong start -c kong.conf
kong 启动后,通过 curl http://127.0.0.1:8001 命令直接访问 Admin API(管理端口),此时将返回整个 kong 的配置信息,通过查看其中的
database 是否为 off,可以验证kong是否运行在 DB-less 模式下面。
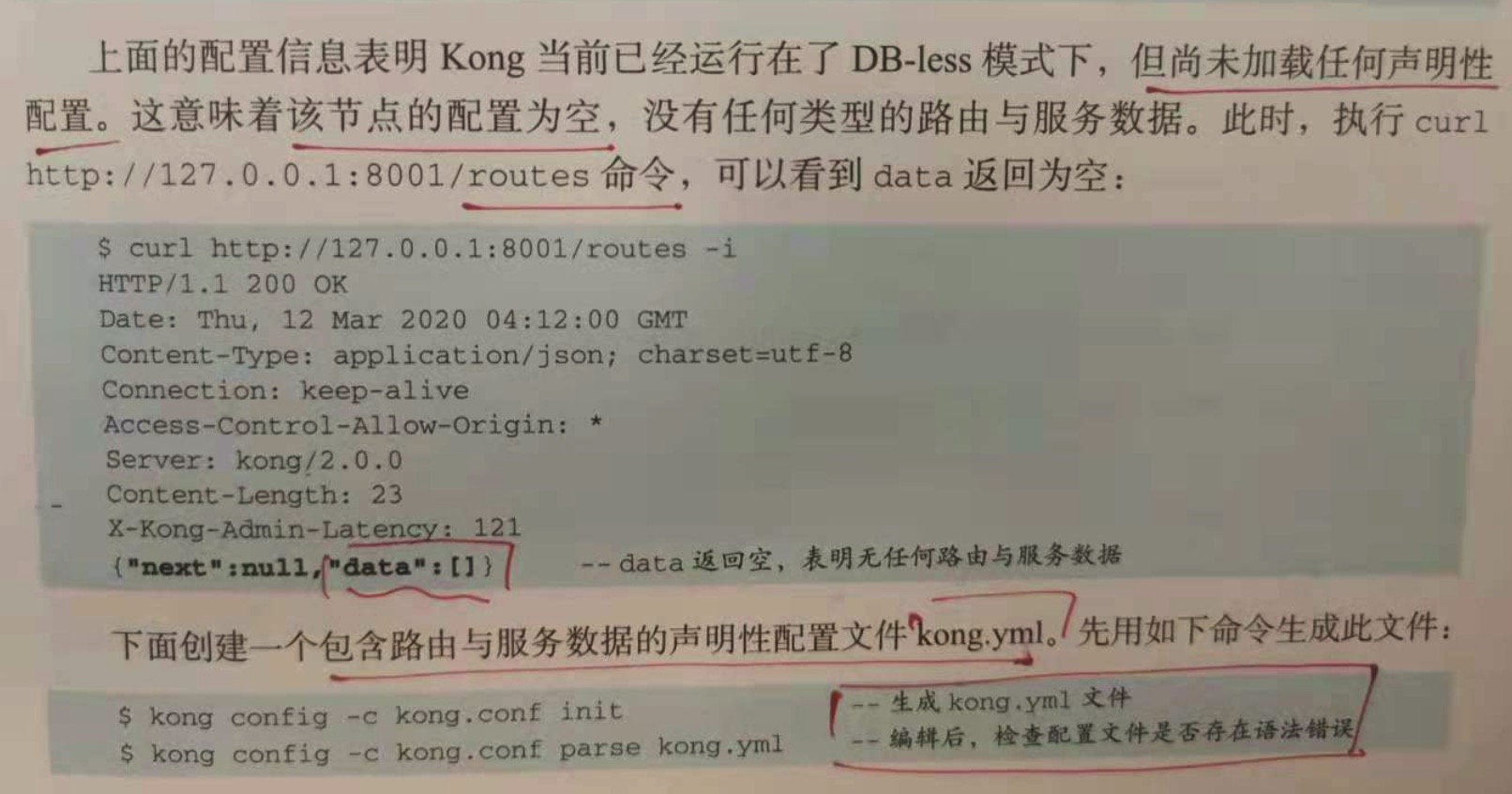
curl http://127.0.0.1:8001/routes,可以看到 data 为空。
kong config -c kong.conf init //生成 kong.yml 文件
kong config -c kong.conf parse kong.yml //编辑后,检查配置文件是否存在语法错误
注意:kong.yml 文件生成的路径在当前目录中。
有两种方法可以将声明性配置加载到 kong 的内存中:通过kong.conf 配置文件和通过Admin API。前者是编辑 kong.conf 配置文件中的
declarative_config 指令(或者使用等效的 KONG_DECLARATIVE_CONFIG 环境变量):
export KONG_DATABASE=off
export KONG_DECLARATIVE_CONFIG=kong.yml
kong start -c kong.conf
后者是使用 Admin API 管理的 /config 端点将声明性配置加载到正在运行的 kong 节点中:
http://127.0.0.1:8001/config config=@kong.yml
DB-less 模式下需要注意:
1.内存缓存要求
路由,服务等实体的配置必须符合Kong的缓存大小,请参考 kong.conf 中的 mem_cache_size。
2.没有中央数据库协调
由于每个节点都是完全独立的配置,所以没有集群传播机制。
3.只读的Admin API
因为需要通过文件的形式声明配置,所以只能通过get方法获取api,其他操作都会返回405。
4.插件的兼容性
大部分内置插件都可以运行,但有些插件由于需要数据库协调或创建外部内容而无法运行,比如与身份验证插件相关的或者redis限速。
2.3 Kong 基础配置
在默认情况下,kong 监听下面端口:
1. 8000 :监听来自客户端的 http 请求流量,并将其路由转发给上游服务器。
2. 8443 :监听传入的 https 请求流量,并将其路由转发给上游服务器。
3. 8001 :监听来自 kong Admin API 的 http 请求流量。
4. 8444 :监听来自 kong Admin API 的 https 请求流量。
以 PostgreSQL 为例 :
//1.复制一份 kong 的配置文件
cp /etc/kong/kong.conf.default /etc/kong/kong.conf
//2.在postgreSQL 上创建名为 kong 的数据库
CREATE USER kong; CREATE DATABASE kong OWNER kong;
//3.使用vim编辑 kong.conf,定位到 DATASTORE
database = postgres -- 数据库类型
pg_host = 127.0.0.1
pg_port = 5432
pg_user = kong
pg_password = 123456
pg_database = kong
//4.定位到 nginx,打开注释,把代理服务端口8000调整为80,管理服务端口8443调整为443
//为了方便使用,我们这里把 8000 调整为 80,8443 调整为 443
proxy_listen = 0.0.0.0:80, 0.0.0.0:443 ssl
//管理端口保持不变
admin_listen = 0.0.0.0:8001, 0.0.0.0:443 ssl
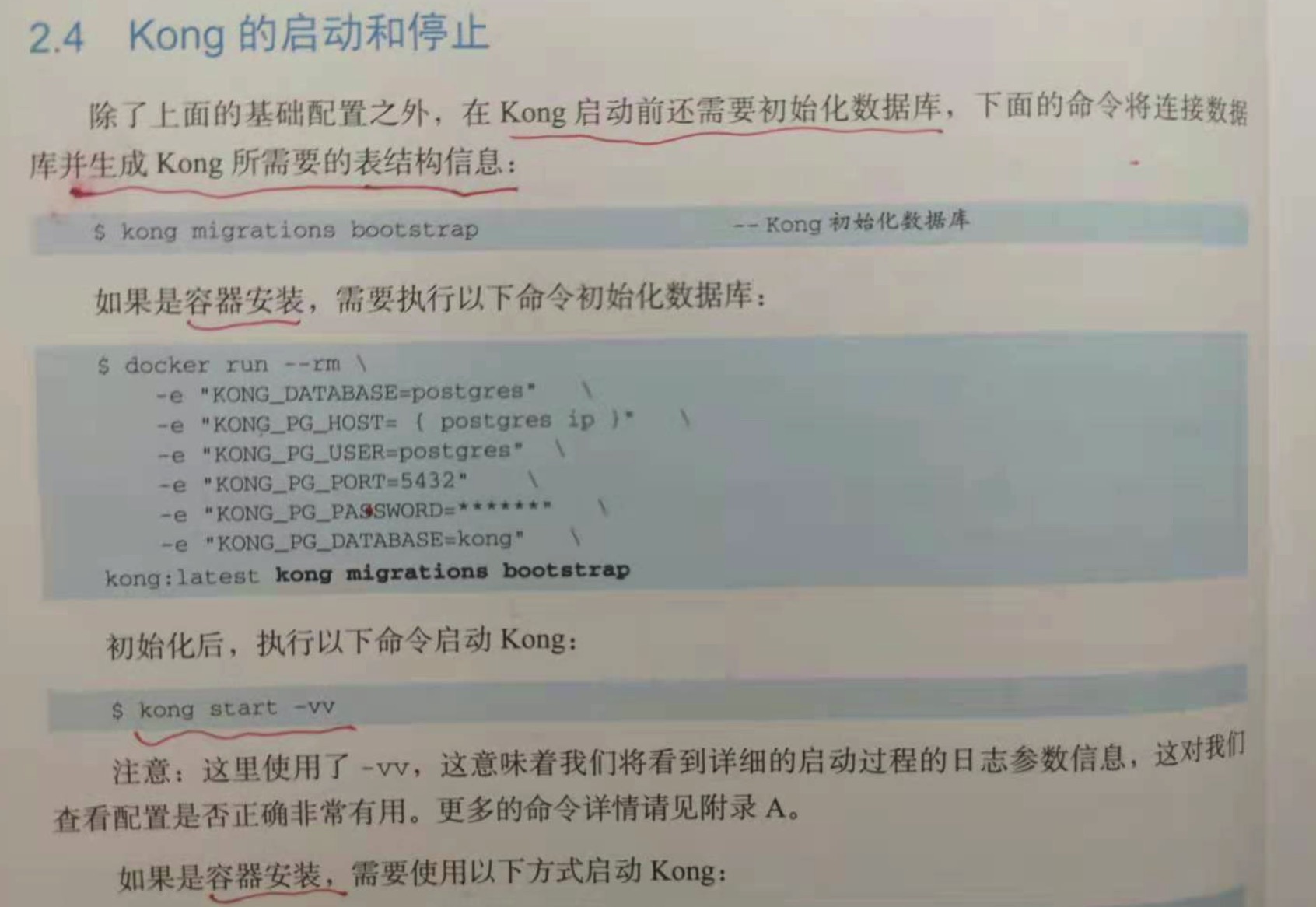
2.4 Kong 的启动和停止
//kong 需要在启动之前初始化数据库,下面的命令将连接数据库并生成kong所需要的表结构信息
kong migrations bootstrap
//启动 kong
kong start -vv
//优雅的关闭kong,即等待当前正在进行的请求完成后再关闭,直到所设定的时间超时
kong quit -t 10
//直接停止正在运行的kong
kong stop
//重新载入kong
kong reload
在重新载入时,会先等当前请求完成后并关闭后,再启动新的工作进程,同时采用之前生成的 /usr/local/kong/.kong_env环境配置文件(注意不是
/etc/kong/kong.conf 文件)。如果需要调整配置文件,建议调整原始的 kong.conf 文件或同时调整这2个文件,不然对环境配置文件进行的所有修改
都将丢失。
2.5 Kong 的基础对象
kong 的基础对象有8大类:
1.路由(route)
2.服务(service)
3.上游(upstream)
4.目标(target)
5.消费者(consumer)
6.插件(plugin)
7.证书(certificate)
8.SNI(Server Name Indication,服务器名称指示)
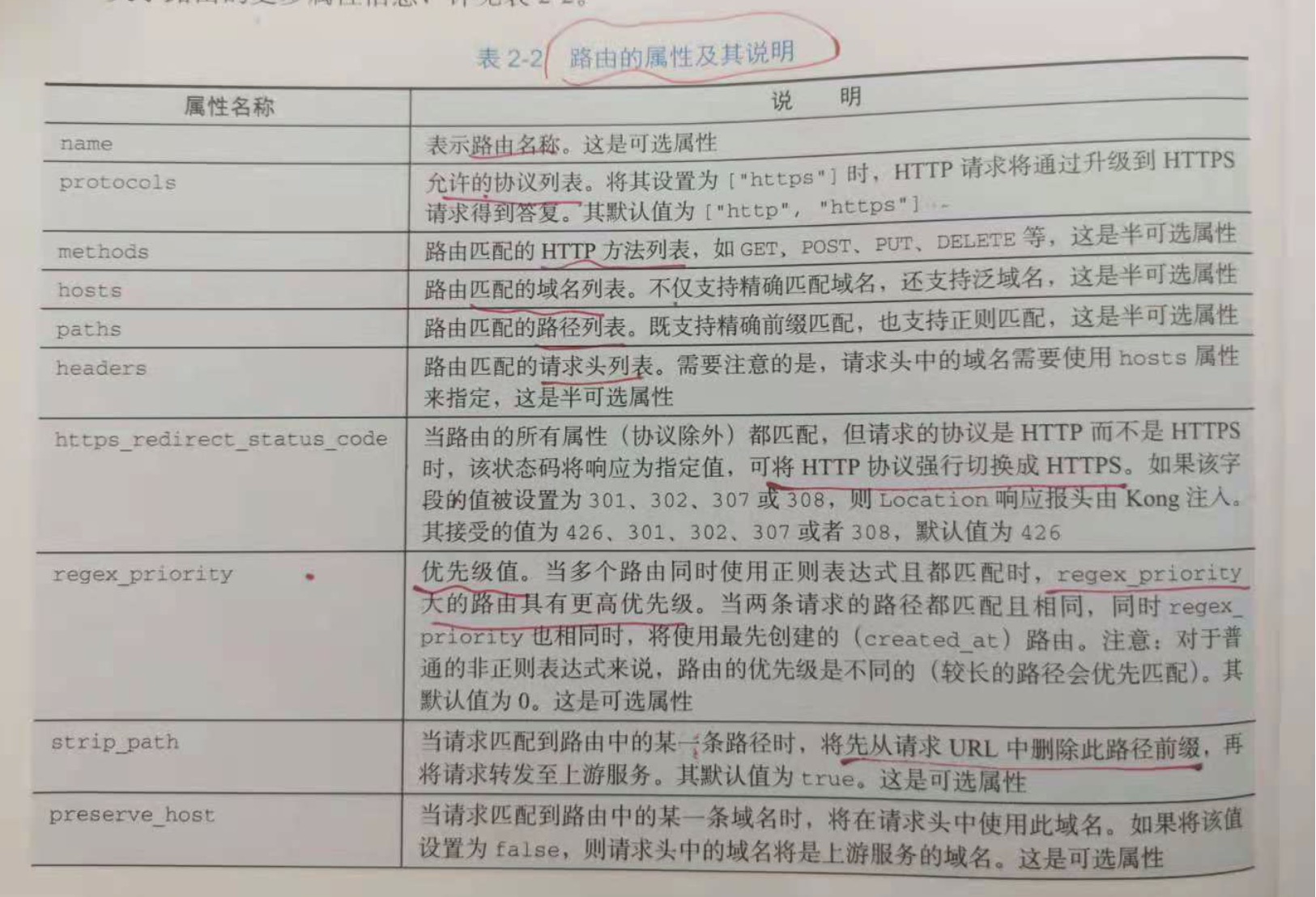
2.5.1 路由
路由定义了客户端请求与服务之间的匹配规则,它支持精确匹配,模糊匹配以及正则匹配,是请求的入口点。每个路由都与特定的服务相关联,一个
服务下可以有一个或者多个与之相关联的路由,每个路由匹配到的请求都将被代理到与该路由关联的服务。路由和服务的组合提供了自由,灵活,多变的
路由机制,基于此,我们可以定义更为具体的(细粒度)的匹配入口。
注意,一个路由至少需要一个匹配规则和协议。
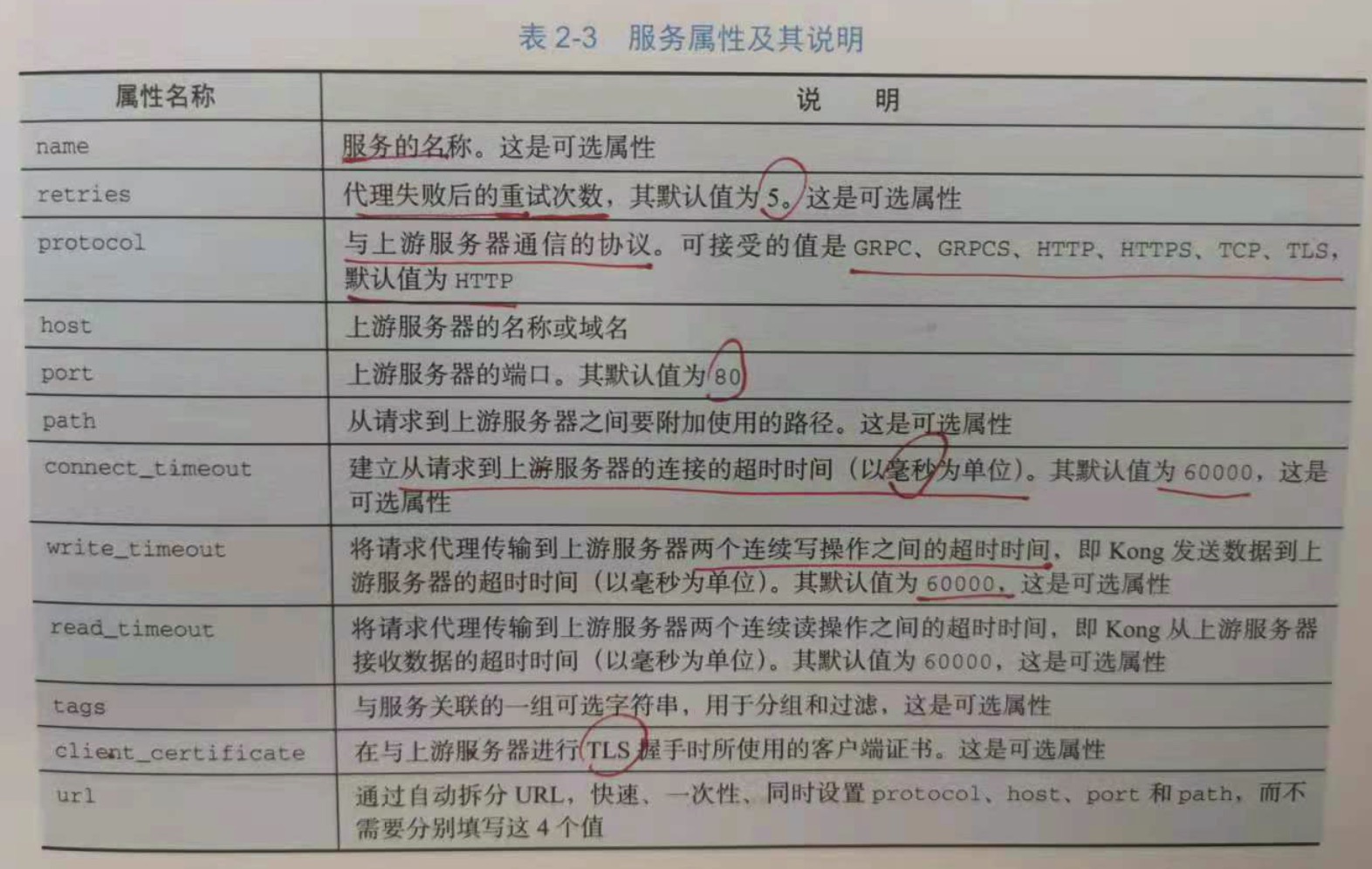
2.5.2 服务
服务是用于管理上游服务的入口点,用于将客户端的请求流量发送给对应的上游服务器,其主要属性是 protocol,host,port和path。服务于路由
相关联,一个服务下可以包含多个路由。路由是客户端的入口,定义了匹配客户端请求和服务的规则。具体为客户端请求先于路由做匹配,如果匹配成功,
kong就将请求代理到该路由相关联的服务。
2.5.3 上游
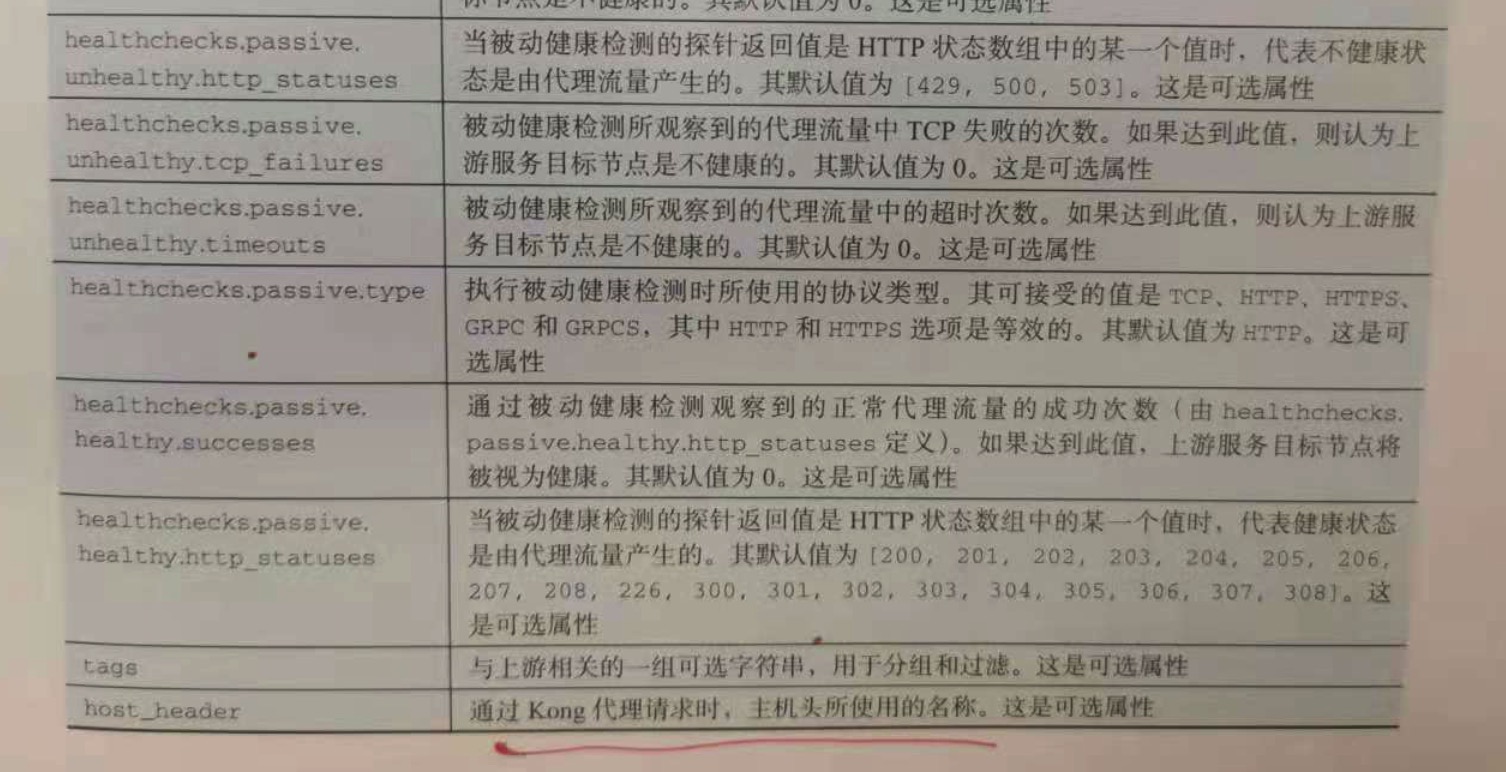
上游服务表示一个虚拟主机,我们可以对上游服务的多个目标节点进行负载均衡和健康监测。负载均衡支持多种散列(哈希)的目标节点选择策略。
健康监测有主动和被动两种模式,该机制既可以将探测到的不健康上游服务节点禁用,使之不参与负载,也可以将之启用后重新参与负载。
2.5.4 目标
目标节点代表一个真实的物理服务,通常为ip地址和端口的组合,其中端口用来标识后端上游服务器上的某个具体节点实例。每个上游都可以包含多个
目标节点地址,在运行过程中可以动态的添加或者删除。此外,每个目标节点还可以设置不同的权重。
因为上游维护着目标节点变更的历史记录,所以不能随意删除或者修改目标节点。若要禁用目标节点,需要先发布一个权重为0的新目标节点,再使用
delete 方法将之删除。
2.5.5 消费者
消费者代表一个具体的用户,是客户端请求的发起者。消费者ID可以作为主要数据存储,可以与业务数据库的用户信息相映射,关联,并为身份授权和
鉴权提供更多的策略。
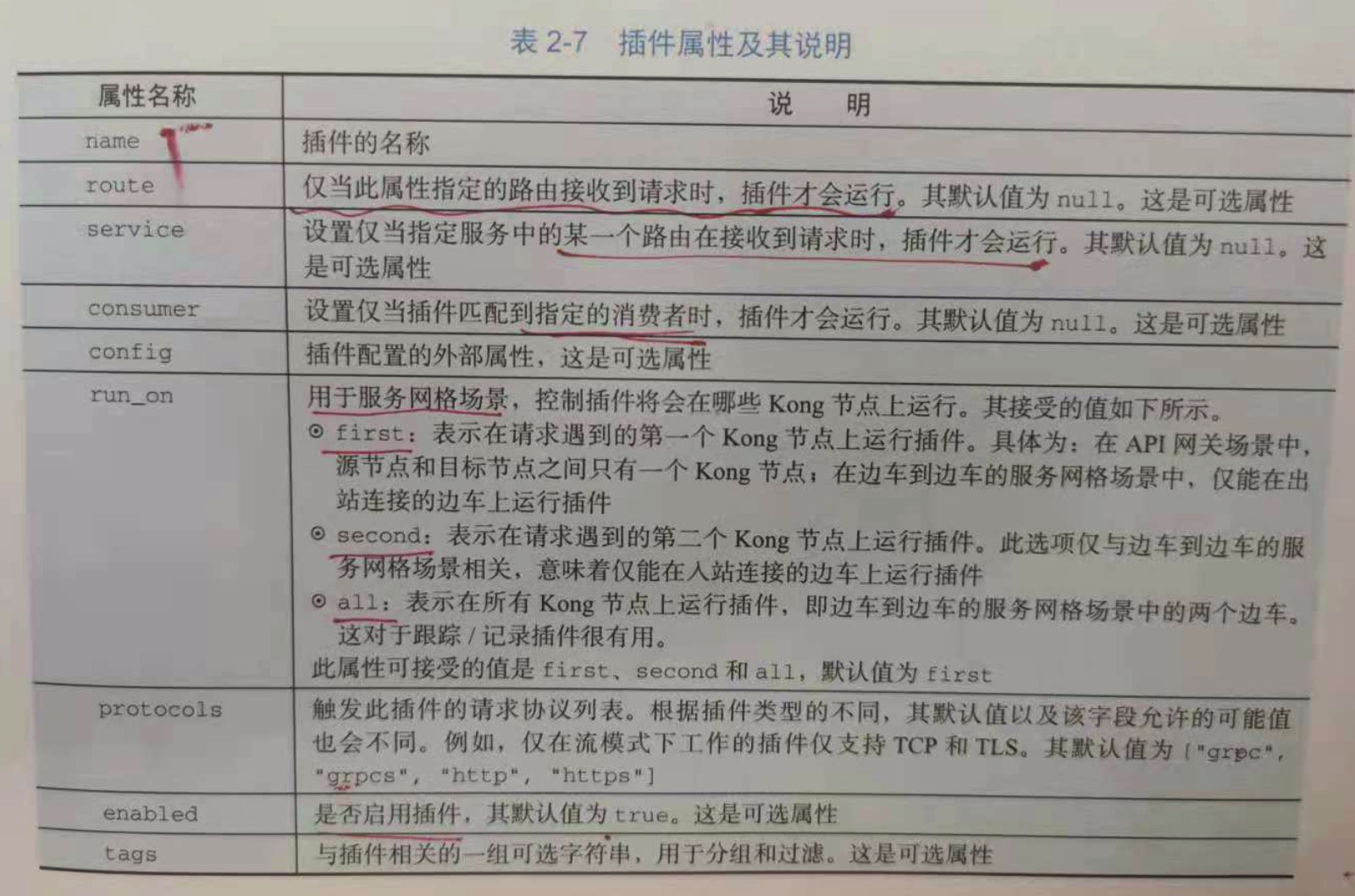
2.5.6 插件
插件表示在请求/响应生命周期内执行的功能集。通过此机制,可以在kong的服务和路由上添加,配置和扩展自定义功能,例如身份验证。在向服务
或者路由添加某个插件配置后,客户端对该服务的每个请求都将运行此插件。与此同时,插件也可以应用于某些特定的消费者,或者被配置为全局插件。
对于每个请求,配置的插件只能运行一次。
将插件应用到具体有不同配置的不同对象时,其优先级顺序的规则为:插件配置的实体越多,越具体,其优先级越高。
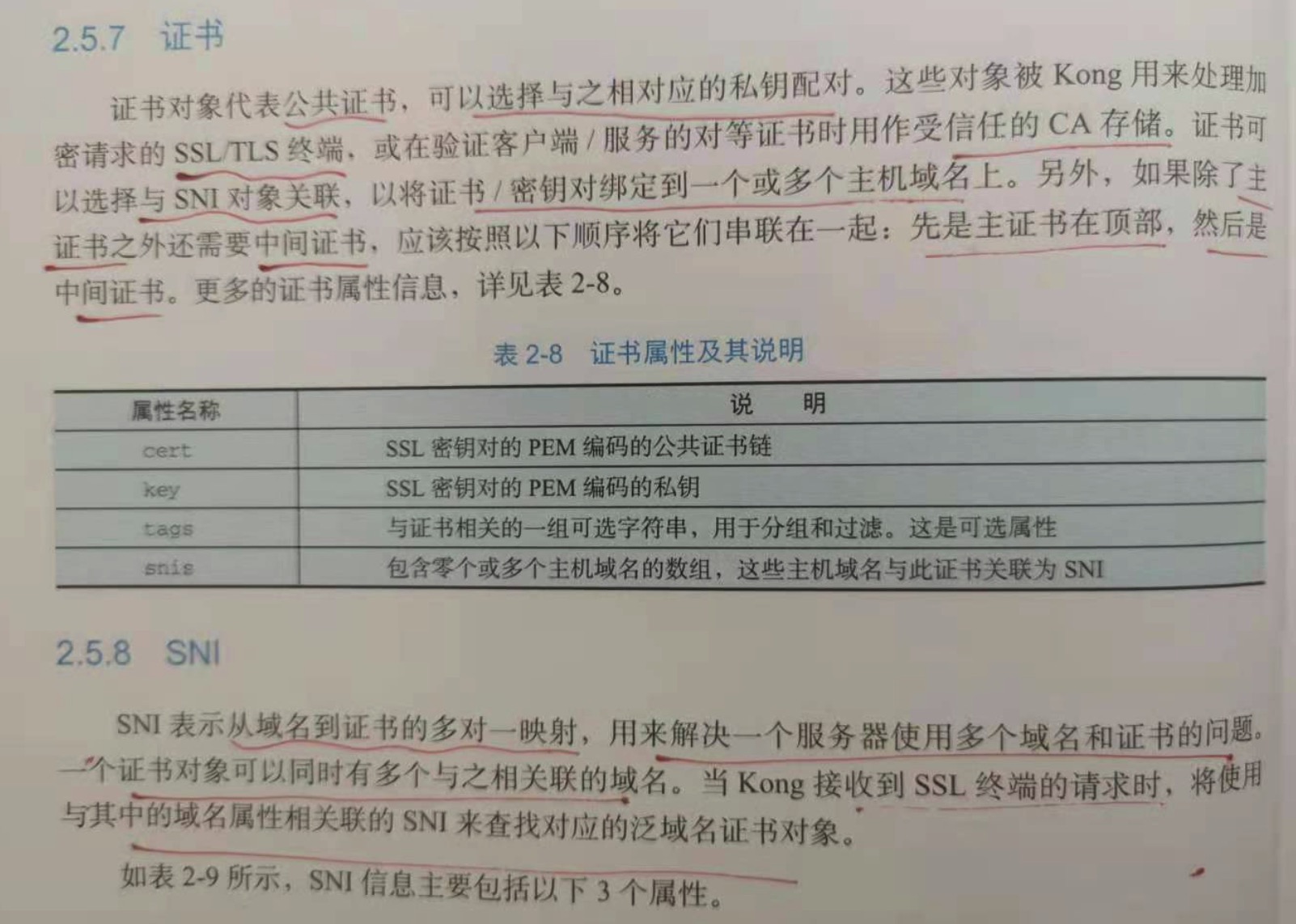
2.5.7 证书
证书对象代表公钥证书,可以选择与之对应的私钥配对。这些对象被kong用来处理加密请求的ssl/tls终端,或在验证客户端/服务的对等证书时
用作受信任的CA存储。证书可以选择与SNI对象关联,以将证书/密钥对绑定到一个或者多个主机域名上。另外,如果除了主证书之外还需要中间证书,
应该按照下面的顺序将它们串联起来:先是主证书在顶部,然后是中间证书。
2.5.8 SNI
SNI 表示从域名到证书的多对一映射,用来解决一个服务器使用多个域名和证书的问题。一个证书对象可以同时有多个与之相关联的域名。当Kong
接收到ssl终端的请求时,将使用与其中的域名属性相关联的SNI来查找对应的泛域名证书对象。
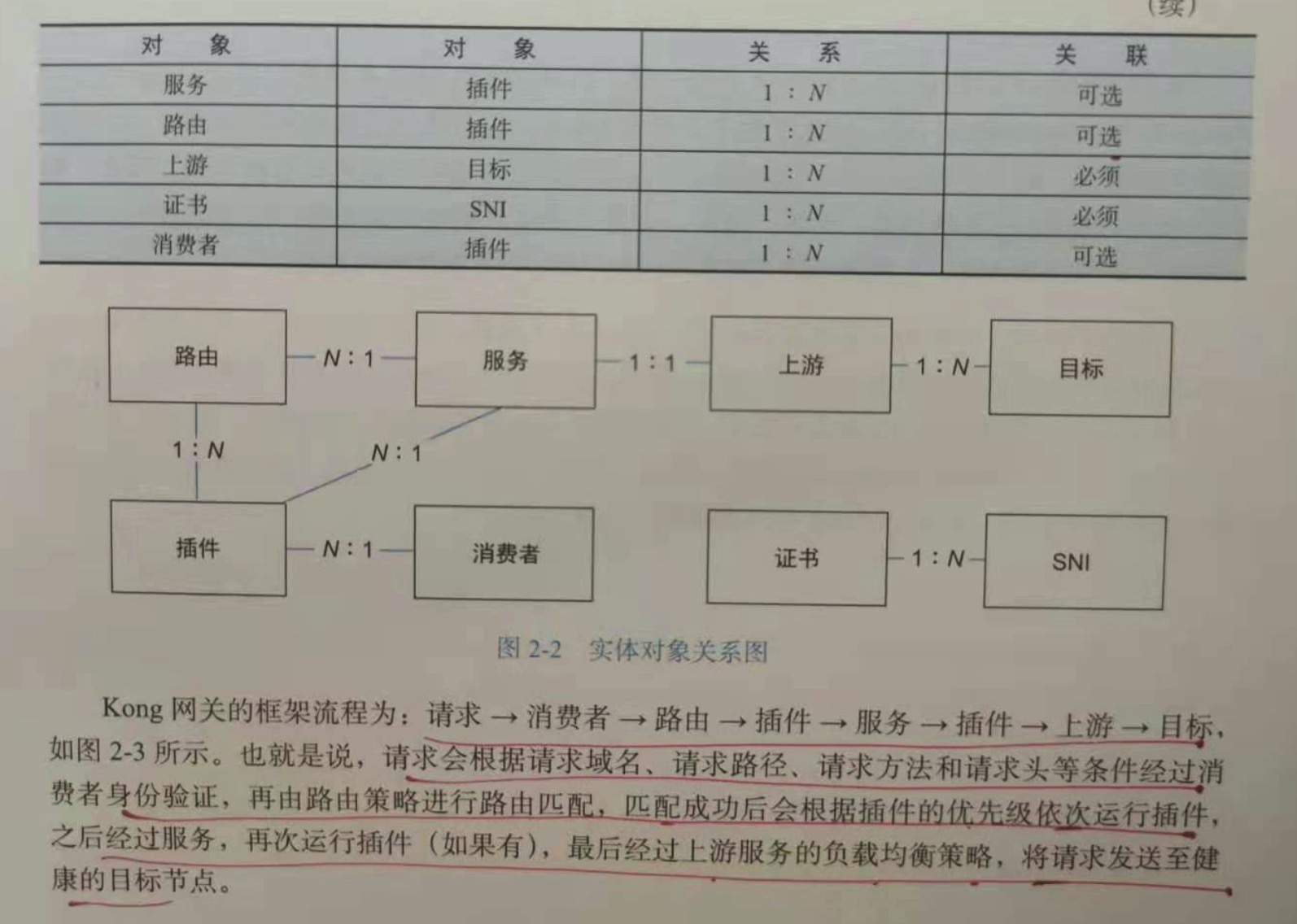
2.5.9 对象之间的关系
kong 网关的框架流程为:请求->消费者->路由->插件->上游->目标。
请求会根据 请求域名,请求路由,请求方法和请求头等条件经过 消费者身份验证,再由路由策略进行路由匹配,匹配成功后会根据插件的优先级
次序依次运行插件,之后经过服务,再次运行插件(如果有),最后经过上游服务的负载均衡策略,将请求发送至健康的目标节点。

























以上是关于2.Kong入门与实战 基于Nginx和OpenResty的云原生微服务网关 --- Kong 的安装和基本概念的主要内容,如果未能解决你的问题,请参考以下文章