大数据(9a)Flink入门Java代码
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(9a)Flink入门Java代码相关的知识,希望对你有一定的参考价值。
文章目录
1、Flink简介
- Apache Flink是为
分布式、高性能、随时可用以及准确的流处理应用程序
打造的开源流处理框架
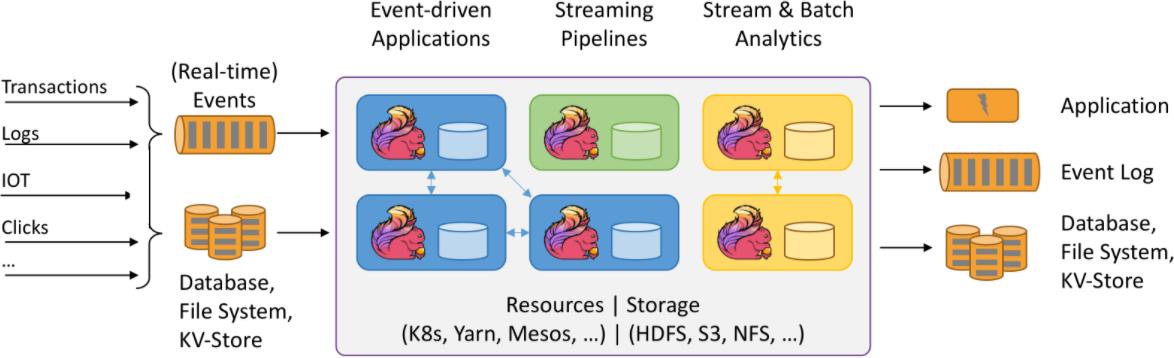
1.1、Flink特点
1.1.1、事件驱动(event-driven)
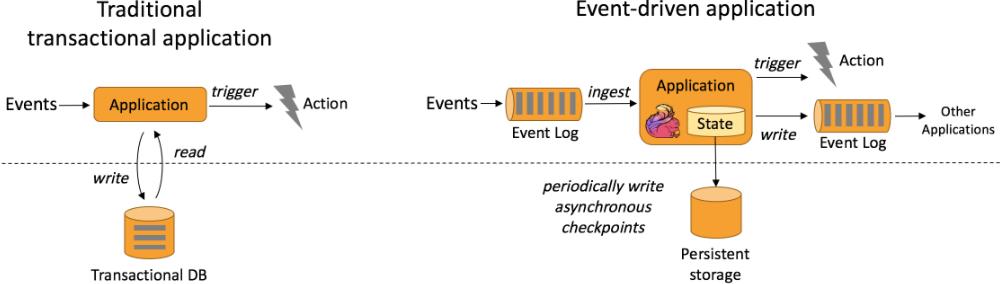
- 事件驱动型应用是一类具有状态的应用
它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作
事件驱动型应用
1.1.2、无界数据流 和 有界数据流
- 在Spark世界观中,一切皆由批次组成,离线数据是大批次,实时数据是小批次
- 在Flink世界观中,一切皆由流组成,离线数据是有界限的流,实时数据是一个没有界限的流

1.1.3、分层API
Flink的分层API

- 高等级API更容易使用,低等级API更灵活
- DataStream API 较为常用
2、Windows环境上跑Flink
Flink应用程序支持批和流式处理分析

2.1、创建Maven工厂,导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
2.2、代码示例:词频统计
2.2.1、自定义数据处理函数
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class MyFlatMap implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
}
2.2.2、批处理
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
public class WordCountBatch {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
DataSet<String> inputDataSet = env.readTextFile("src/main/resources/a.txt");
// 分词,平化,分组,合计
DataSet<Tuple2<String, Integer>> wordCountDataSet =
inputDataSet.flatMap(new MyFlatMap())
.groupBy(0) // 对Tuple2的0号位置进行分组
.sum(1); // 对Tuple2的1号位置进行求和
// 打印输出
wordCountDataSet.print();
}
}
打印结果
(dd,3)
(aa,4)
(bb,1)
(cc,2)
2.2.3、流式处理
2.2.3.1、读本地文件
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCountStream {
public static void main(String[] args) throws Exception {
// 流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
DataStream<String> inputDataStream = env.readTextFile("src/main/resources/a.txt");
// 分词,平化,分组,合计
DataStream<Tuple2<String, Integer>> wordCountDataStream = inputDataStream
.flatMap(new MyFlatMap())
.keyBy(0)
.sum(1);
// 打印,设置并行度
wordCountDataStream.print().setParallelism(1);
// 执行
env.execute();
}
}
打印结果
(dd,1)
(cc,1)
(dd,2)
(cc,2)
(dd,3)
(aa,1)
(aa,2)
(aa,3)
(aa,4)
(bb,1)
2.2.3.2、读取网络数据
虚拟机输入命令
nc -lk 7777
运行下面Java代码(只改了第10行)
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCountStreamSocket {
public static void main(String[] args) throws Exception {
// 流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从网络中读取数据
DataStream<String> inputDataStream = env.socketTextStream("hadoop100", 7777);
// 分词,平化,分组,合计
DataStream<Tuple2<String, Integer>> wordCountDataStream = inputDataStream
.flatMap(new MyFlatMap())
.keyBy(0)
.sum(1);
// 打印,设置并行度
wordCountDataStream.print().setParallelism(1);
// 执行
env.execute();
}
}
打印结果
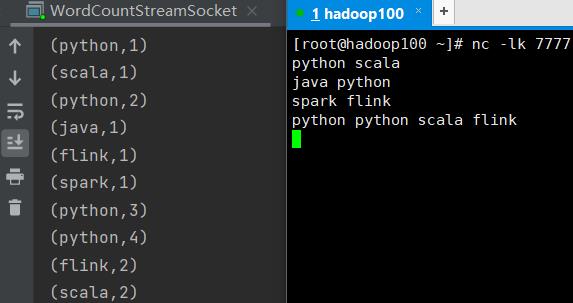
3、Appendix
| en | 🔉 | cn |
|---|---|---|
| transaction | trænˈzækʃn | n. 交易;事务 |
| event-driven | ɪˈvent ˈdrɪvn | 事件驱动的 |
| ingest | ɪnˈdʒest | vt. 摄取;咽下;吸收; |
| trigger | ˈtrɪɡər | n. 触发器;v. 触发 |
| persistent | pərˈsɪstənt | 执着的,坚持不懈的;(动植物某部位,如角、叶等)存留的 |
| persistent storage | 永久存储 | |
| asynchronous | eɪˈsɪŋkrənəs | adj. [电] 异步的;不同期的 |
| checkpoint | ˈtʃekpɔɪnt | n. 检查站,关卡 |
| conciseness | kənˈsaɪsnəs | n. 简明 |
| expressiveness | ɪkˈspresɪvnəs | n. 善于表现;表情丰富 |
| KV-Store | 键值对方式存储 |
以上是关于大数据(9a)Flink入门Java代码的主要内容,如果未能解决你的问题,请参考以下文章