计算机组成原理 — 输入输出系统 — 存储控制器接口类型
Posted 范桂飓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机组成原理 — 输入输出系统 — 存储控制器接口类型相关的知识,希望对你有一定的参考价值。
目录
ATA(IDE)
ATA(Advanced Technology Attachment, 高级技术附加装置)起源于 IBM,是一个单纯的磁盘驱动器接口,不支持其他的接口设备,适配的是 IDE(Integrated Drive Electronics,电子集成驱动器)磁盘驱动器。IDE 接口,也称为 PATA(Parallel ATA,并行 ATA)接口,意在把磁盘控制器和磁盘驱动器集成到了一起,这种做法减少了磁盘接口的电缆数目与长度,数据传输的可靠性得到了增强,磁盘制造起来也变得更容易,因为厂商不需要担心自己的磁盘驱动器是否与其它厂商的磁盘控制器兼容。对用户而言,磁盘安装起来也更为方便。
IDE 具有价格低廉,兼容性强,性价比高,数据传输慢,不支持热插拔等特点,多用于家用产品中,也有部分应用于服务器。ATA、Ultra ATA、DMA、Ultra DMA 等接口都属于 IDE 硬盘。


SATA 与 eSATA
SATA(Serial ATA,串行 ATA),又叫串口磁盘,是一个串行点对点连接系统,支持热插拔,支持主机与每个磁盘驱动器之间拥有单独的连接路径,每个磁盘驱动器都可以独享全部带宽。SATA 在机柜内部连接外部设备,而 eSATA 是外置式的 SATA 接口。
SATA 是一种完全不同于 Parallel ATA 的新型磁盘接口类型,由于采用串行方式传输数据而知名。相对于 Parallel ATA 而言,就具有非常多的优势。首先,SATA 以连续串行的方式传送数据,一次只会传送 1 位数据。这样能减少 SATA 接口的针脚数目,使连接电缆数目变少,效率也会更高。实际上,SATA 仅用四支针脚就能完成所有的工作,分别用于连接电缆、连接地线、发送数据和接收数据,同时这样的架构还能降低系统能耗和减小系统复杂性。其次,SATA 的起点更高、发展潜力更大,SATA 1.0 定义的数据传输率可达 150MB/s,这比目前最新的 Parallel ATA(即 ATA/133)所能达到 133MB/s 的最高数据传输率还高,而在 SATA 2.0 的数据传输率将达到 300MB/s,最终 SATA 将实现 600MB/s 的最高数据传输率。SATA 总线使用嵌入式时钟信号,具有更强的纠错能力,与 ATA 相比其最大的区别在于能对传输指令(不仅仅是数据)进行检查,如果发现错误会自动矫正,这在很大程度上提高了数据传输的可靠性。串行接口还具有结构简单、支持热插拔的优点。


SCSI
SCSI(Small Computer System Interface,小型计算机系统接口)是当前流行的用于服务器和微机的外部设备接口标准,目前的计算机基本都设置了 SCSI 接口,如果没有的话就需要一块专门的 SCSI 适配器卡,完成主机总线到 SCSI 总线的跨接,不同的主机总线对应不同的适配器。SCSI 设备与主机之间以 DMA 的方式传输数据库,SCSI 适配器中整合了主机通信的指令,降低了系统 I/O 处理对主机 CPU 的占用率。
与 IDE 不同,IDE 接口是普通 PC 的标准接口,而 SCSI 并不是专门为硬盘设计的接口,是一种广泛应用于小型机上的高速数据传输技术。不仅可以控制磁盘驱动器,还可以控制磁带机、光盘、打印机和扫描仪等外设。由于设备中包括了控制器,设备的功能更复杂,因而称为智能外设。SCSI 接口具有应用范围广、多任务、带宽大、CPU 占用率低,以及热插拔等优点,但也拥有较高的价格。


SAS
SAS(Serial attached SCSI,串行 SCSI),向下兼容并行 SATA,两种运行相同的指令集,在物理连接接口上提供了对 SATA 的支持,即两者可以使用相类似的电缆。从接口标准上而言,SATA 是 SAS 的一个子标准,SAS 吸收了 FC(光纤通道)的特点,因此 SAS 控制器可以直接操控 SATA 硬盘,但是 SAS 却不能直接使用在 SATA 的环境中,因为 SATA 控制器并不能对 SAS 硬盘进行控制。
在协议层,SAS 由 3 种类型协议组成,根据连接的不同设备使用相应的协议进行数据传输。其中 SSP(串行 SCSI 协议)用于传输 SCSI 命令,SMP(SCSI 管理协议)用于对连接的设备进行维护和管理,STP(SATA 通道协议)用于 SAS 和 SATA 之间数据的传输。在这 3 种协议的配合下,SAS 可以和 SATA 以及部分 SCSI 设备无缝结合。此外,与并行方式相比,串行方式能提供更快速的通信传输速度以及更简易的配置,SAS 的传输速率要比 SATA 快得多。SAS 为服务器和网络存储等应用提供了更大的选择空间。


iSCSI
iSCSI(Internet SCSI)是运行在 TCP/IP 网络上的 SCSI,iSCSI 使得标准的 SCSI 指令能够在 TCP/IP 网络上的主机与网络存储设备之间传送,也可以在系统之间传送。而 SCSI 协议只能访问本地的 SCSI 设备。
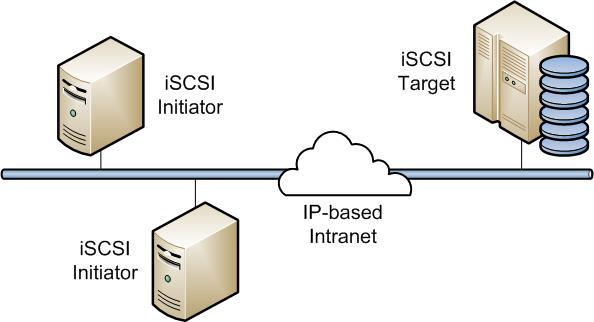
iSCSI 的工作原理:当 iSCSI Initiator(终端用户)发送一个请求后,操作系统会产生一个适当的 SCSI 指令和数据请求,SCSI 指令通过封装被加上了 TCP/IP 协议的包头,并支持在需要加密的时候执行加密处理。封装后的 SCSI 指令数据包得以在 Internet 上传送,以此突破了物理空间的限制。iSCSI Target(接收端)在收到这个数据包之后按照相反的步骤进行解析得出 SCSI 指令和数据请求,再交由 SCSI 存储设备驱动程序处理。因为 iSCSI 是双向的协议,所以 iSCSI Target 可以将数据(执行结果)返回给 iSCSI Initiator。
FC
FC(Fibre Channel,光纤通道),与 SCSI 接口一样,光纤通道最初也不是专为磁盘驱动器所设计的接口技术,而是专门为网络系统设计的。但随着存储系统对速度的需求日益增长,FC 才逐渐应用被到磁盘存储系统中。光纤通道磁盘是为提高多磁盘存储系统的速度和灵活性才开发的,它的出现大大提高了多磁盘系统的通信速度。FC 具有热插拔性、高速带宽、远程连接、连接设备数量大等特点,是为了服务器此类多磁盘系统环境而设计的,能够满足高端工作站、服务器、海量存储子网络、外设间通过集线器、交换机和点对点连接进行双向、串行数据通讯等系统对高数据传输率的要求。

RDMA
RDMA(Remote DMA,远程直接内存访问)是一种新的内存访问技术,RDMA 让计算机可以直接存取其他计算机的内存,而不需要经过处理器耗时的处理。RDMA 将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响。RDMA 技术的原理及其与 TCP/IP 架构的对比如下图所示。
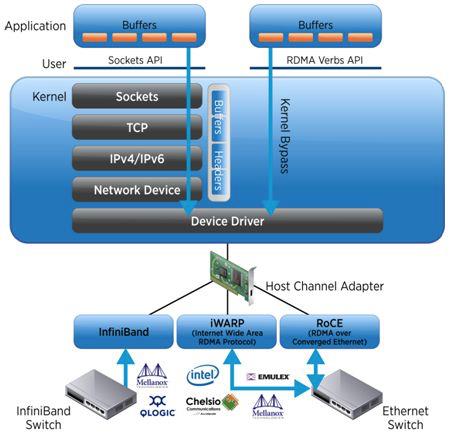
- InfiniBand(IB):从一开始就支持 RDMA 的新一代网络协议。由于这是一种新的网络技术,因此需要支持该技术的网卡和交换机。
- RDMA 融合以太网(RoCE):一种允许通过以太网进行 RDMA 的网络协议。其较低的网络头是以太网头,其上网络头(包括数据)是 InfiniBand 头。这允许在标准以太网基础架构(交换机)上使用 RDMA。只有 NIC 应该是特殊的,并支持 RoCE。
- 互联网广域 RDMA 协议(iWARP):允许通过 TCP 执行 RDMA 的网络协议。在 IB 和 RoCE 中存在功能,iWARP 不支持这些功能。这允许在标准以太网基础架构(交换机)上使用 RDMA。只有 NIC 应该是特殊的,并支持 iWARP(如果使用 CPU 卸载),否则所有 iWARP 堆栈都可以在 SW 中实现,并且丢失了大部分的 RDMA 性能优势。
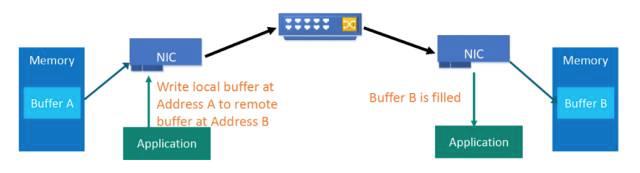
因此,RDMA 可以简单理解为利用相关的硬件和网络技术,服务器 1 的网卡可以直接读写服务器 2 的内存,最终达到高带宽、低延迟和低资源利用率的效果。如下图所示,应用程序不需要参与数据传输过程,只需要指定内存读写地址,开启传输并等待传输完成即可。
RDMA 的主要优势总结如下:
- Zero-Copy:数据不需要在网络协议栈的各个层之间来回拷贝,这缩短了数据流路径。
- Kernel-Bypass:应用直接操作设备接口,不再经过系统调用切换到内核态,没有内核切换开销。
- None-CPU:数据传输无须 CPU 参与,完全由网卡搞定,无需再做发包收包中断处理,不耗费 CPU 资源。
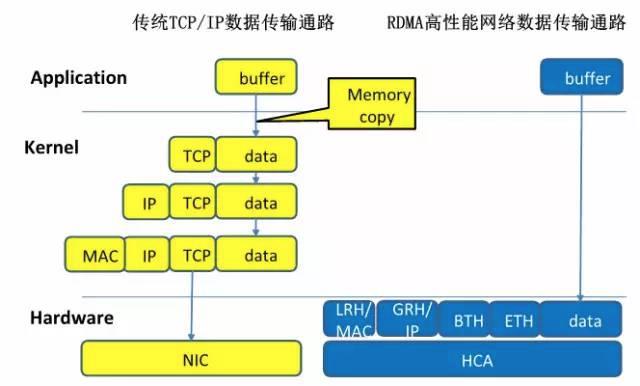
这么多优势总结起来就是提高处理效率,减低时延。
实际上 RDMA 并非最近几年才提出,事实上最早实现 RDMA 的网络协议 InfiniBand 早已应用到了高性能计算中。但是 InfinBand 和传统 TCP/IP 网络相比区别非常大,需要专用的硬件设备,承担昂贵的价格,并且会大大增加运维人力成本。
目前支持以太网的 RDMA 协议主要是 RoCE(RDMA over Converged Ethernet)和 iWARP(Internet Wide Area RDMA Protocol),系统部同学通过性能、可用性等多方面的调研后,最终引入了 RoCE 网络。RoCE 和 InfiniBand 的性能基本相近,而且比 iWARP 产业生态更加健全,主流网卡厂商都已支持。除此之外,RoCE 网络在数据链路层支持标准以太网协议,在网络层上支持 IP 协议,因此可以无缝融合到现有的 IDC 环境中,部署方便;其次由于 RoCE 网络支持标准以太网和IP协议,更加方便运维,而且设备成本更低。
NVMe
近几年存储行业发生了翻天覆地的变化,半导体存储登上了历史的舞台。和传统磁盘存储介质相比,半导体存储介质具有天然的优势。无论在可靠性、性能、功耗等方面都远远超越传统磁盘。SSD 存储介质和接口技术一直处于不断向前发展和演进的过程。SSD 分为几个阶段,第一个阶段是 SATA SSD 或者 SATA/SAS SSD 为主导,这个阶段介质以 SLC 和 eMLC 为主。第二个阶段是 PCIe SSD,PCIe SSD 最大的问题是不标准,很多私有化协议各自为政,基于 FTL 位置不同主要分为 Host based SSD 和 Device base SSD。 直到 NVMe 时代才统一了接口和协议标准,NVMe 主要的产品形态有三大类。第一类是和 SATA/SAS SS D兼容的 U.2,第二类是和 PCIe 兼容的 SSD 卡,第三类消费级产品常用的 M.2。
目前常用的半导体存储介质是 NVMe SSD,采用 PCIe 接口方式与主机进行交互,大大提升了性能,释放了存储介质本身的性能。NVMe SSD 推进了数据中心闪存化进程。

NVM Express(NVMe,Non-Volatile Memory express,非易失性内存主机控制器接口规范),是一个逻辑设备的接口规范。他是与 AHCI 类似的、基于设备逻辑接口的总线传输协议规范(相当于通讯协议中的应用层),用于访问通过 PCI-Express(PCIe)总线附加的非易失性内存介质,虽然理论上不一定要求 PCIe 总线协议。
此规范目的在于充分利用 PCI-E 通道的低延时以及并行性,还有当代处理器、平台与应用的并行性,在可控制的存储成本下,极大的提升固态硬盘的读写性能,降低由于 AHCI 接口带来的高延时,彻底解放 SATA 时代固态硬盘的极致性能。
历史上,大多数 SSD 使用如 SATA、SAS 或光纤通道等接口与计算机接口的总线连接。随着固态硬盘在大众市场上的流行,SATA 已成为个人电脑中连接 SSD 的最典型方式;但是,SATA 的设计主要是作为机械硬盘驱动器(HDD)的接口,并随着时间的推移越来越难满足速度日益提高的 SSD。随着在大众市场的流行,许多固态硬盘的数据速率提升已经放缓。不同于机械硬盘,部分 SSD 已受到 SATA 最大吞吐量的限制。
在 NVMe 出现之前,高端 SSD 只得以采用 PCI Express 总线制造,但需使用非标准规范的接口。若使用标准化的 SSD 接口,操作系统只需要一个驱动程序就能使用匹配规范的所有 SSD。这也意味着每个 SSD 制造商不必用额外的资源来设计特定接口的驱动程序。2015 年 11 月,发布了 “NVM Express 管理接口规范” (NVMe),为非用户组件和系统提供了带外管理。NVMe 提供了一个通用的基线管理功能,它可以跨越所有的 NVMe 设备和系统,以及实现可选特性的一致方法。命令包括查询和设置配置、获取子系统的健康、固件管理、命名空间管理、安全管理等。
NVMe 的优势:
- 性能有数倍的提升;
- 可大幅降低延迟;
- NVMe 可以把最大队列深度从 32 提升到 64000,SSD 的 IOPS 能力也会得到大幅提升;
- 自动功耗状态切换和动态能耗管理功能大大降低功耗;
- NVMe 标准的出现解决了不同 PCIe SSD 之间的驱动适用性问题。
目前 NVMe SSD 主流采用的存储介质是 NAND Flash。最近几年 NAND Flash 技术快速发展,主要发展的思路有两条:
- 通过 3D 堆叠的方式增加 NAND Flash 的存储密度;
- 通过增加单 Cell 比特数来提升 NAND Flash 的存储密度。
纵观 SSD 发展,NVMe 的出现虽然对接口标准和数据传输效率上得到了跨越式的提升,但是存储介质目前主流还是基于 NAND Flash 实现。那再往前发展,存储介质应该怎么发展呢?Intel Optane(傲腾)系列硬盘通过实践证明 NVMe 和 SCM(Storage Class Memory)配对时才会显现更大的存储优势,在很多时候也把 SCM 称为 VNM,那时数据存储将会迎来重大飞跃,NVMe 的未来属于 SCM。它将建立在行业协议标准而不是专有技术之上。
扩展阅读:《联通沃云虚拟机扩展内存技术的方法验证研究》
NVMe Over Fabrics
NVMe 传输是一种抽象协议层,旨在提供可靠的 NVMe 命令和数据传输。为了支持数据中心的网络存储,通过 NVMe over Fabric 实现 NVMe 标准在 PCIe 总线上的扩展,以此来挑战 SCSI 在 SAN 中的统治地位。NVMe over Fabric 支持把 NVMe 映射到多个 Fabrics 传输选项,主要包括 FC、InfiniBand、RoCE v2、iWARP 和 TCP。
NVMe Over Fabrics 使用 RDMA 或光纤通道(FC)架构等 Fabric 技术取代 PCIe 传输。如图所示,除了基于 RDMA 架构的传输包括以太网(ROCE),InfiniBand 和 iWARP,当然,采用基于原生 TCP(非 RDMA)传输也是可能的(截至 2018 年 7 月,TCP 技术仍在研发阶段)。

图中所示的 NVM 子系统是一个或多个物理结构接口(端口)的集合,每个单独的控制器通常连接到单个端口。多个控制器可以共享一个端口。尽管允许 NVM 子系统的端口支持不同的 NVMe 传输,但实际上,单个端口可能仅支持单个传输类型。NVM 子系统包括一个或多个控制器,一个或多个命名空间,一个或多个 PCI Express 端口,非易失性存储器存储介质,以及控制器和非易失性存储器存储介质之间的接口。
详细资料请参考:
- https://mp.weixin.qq.com/s/gl-RbUUtdtxK3o17nFNcxA
- https://mp.weixin.qq.com/s/2LTuDRDGeSPefCJdWnLH7w
InfiniBand 架构
InfiniBand 是一种基于交换结构和点到点通信的 I/O 接口,是一种长缆线的连接方式,具有高速、低延迟的传输特性。InfiniBand 以极高的传输速度将服务器、存储设备和网络设备连接在一起。基于 InfiniBand 技术的网卡的单端口带宽可达 20Gbps,最初主要用在高性能计算系统中,近年来随着设备成本的下降,InfiniBand 也逐渐被用到企业数据中心。
InfiniBand 由 4 中基本设备组成,包括主机通道适配器 HCA、目标通道适配器 TCA、交换机及路由器。其中 HCA 功能较强,具有微处理器,参与管理。TCA 功能比较简单。交换机和路由器是用于连接的设备。
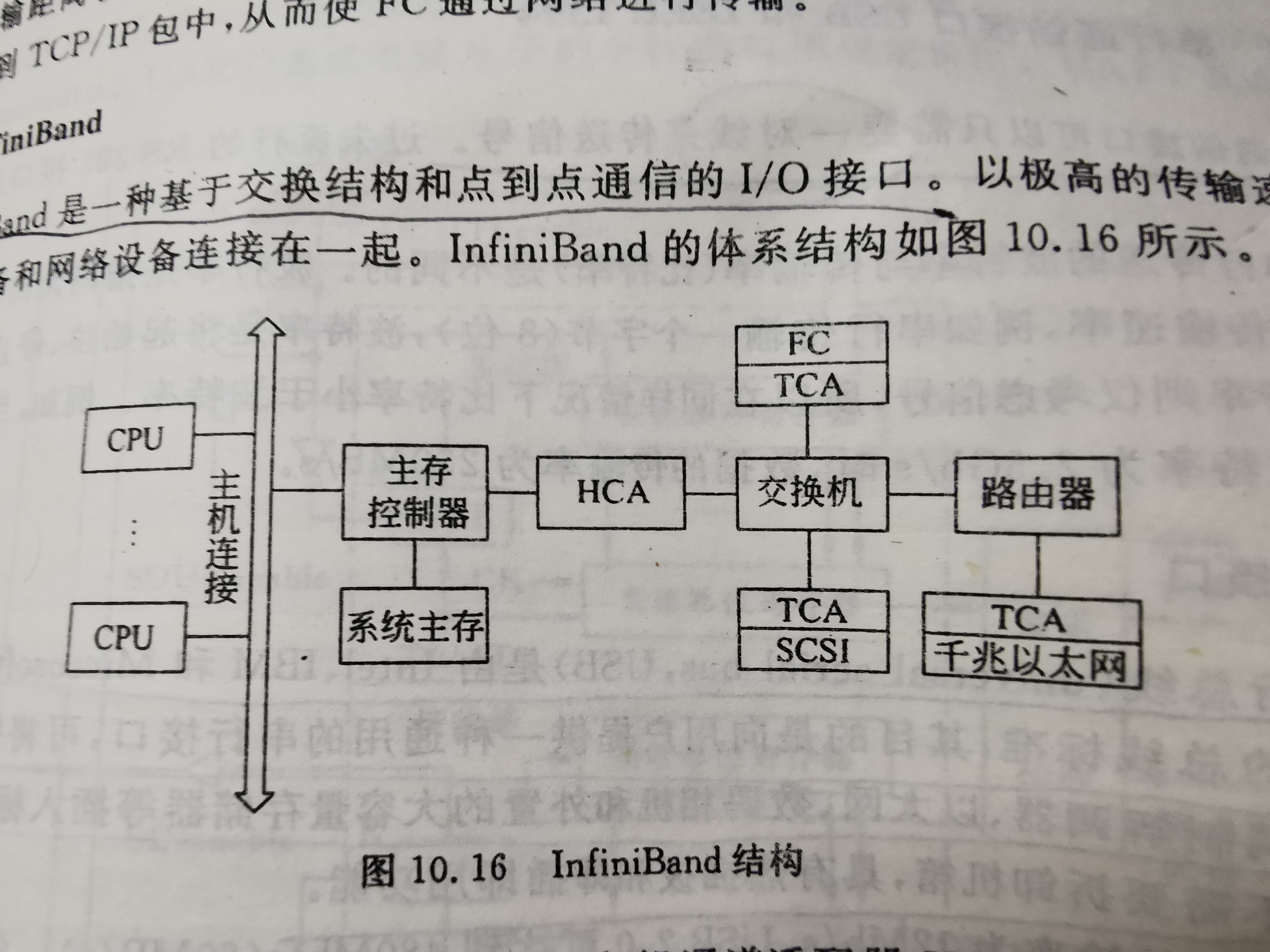
为了发挥 InfiniBand 设备的性能,需要一整套的软件栈来驱动和使用,这其中最著名的就是 OFED(OpenFabrics Enterprise Distribution),基于 InfiniBand 的设备实现了 RDMA(Remote Direct Memory Access)。RDMA 的最主要的特点就是零拷贝和旁路操作系统,数据直接在外部设备和应用程序内存之间传递,这种传递不需要 CPU 的干预和上下文切换。OFED 还实现了一系列的其它软件栈:IPoIB(IP over InfiniBand)、SRP(SCSI RDMA Protocol)等,这就为 InfiniBand 聚合存储网络和互联网络提供了基础。OFED 现已经被主流的 Linux 发行版本支持,并被整合到微软的 Windows Server 中。

以太网光纤通道 FCoE
就在大家认为 InfiniBand 是数据中心连接技术的未来时,10Gb 以太网的出现让人看到了其它选择,以太网的发展好像从来没有上限,目前它的性能已经接近 InfiniBand,而从现有网络逐渐升级到 10Gb 以太网也更易为用户所接受。
FCoE(FiberChannel Over Ethernet)的出现为数据中心互联网络和存储网络的聚合提供了另一种可能。FCoE 可将传统的 FC 存储网络功能融合到以太网中,思路是将光纤信道直接映射到以太网线上,这样光纤信道就成了以太网线上除了互联网网络协议之外的另一种网络协议。FCoE 能够很容易的和传统光纤网络上运行的软件和管理工具相整合,因而能够代替光纤连接存储网络。虽然出现的晚,但 FCoE 发展极其迅猛。与 InfiniBand 技术需要采用全新的链路相比,企业 IT 更愿意升级已有的以太网。在两者性能接近的情况下,采用 FCoE 方案似乎性价比更高。
大型数据中心利用 FCoE 等新技术将存储传输和 IP 传输融合到以太网连接上,而标准的 STP 将不再适合融合网络或超大型数据中心的扩展。随着 FCoE 采用率的提高,企业存储开始考虑加入 IP 网络上的其他协议,从存储的角度来看,TRILL 可以代替 STP。
以上是关于计算机组成原理 — 输入输出系统 — 存储控制器接口类型的主要内容,如果未能解决你的问题,请参考以下文章