python3爬取音乐(python经典编程案例)
Posted cui_yonghua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3爬取音乐(python经典编程案例)相关的知识,希望对你有一定的参考价值。
爬取网站:https://www.9ku.com/
下载音乐代码:
import re
import os
import time
import requests
import urllib.parse
headers = {
'Referer': 'https://www.9ku.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
def start_music():
while True:
name = input('请输入你要下载的歌曲名称:')
name1 = urllib.parse.quote(name)
url = f"https://baidu.9ku.com/song/?key={name1}"
try:
rep1 = requests.get(url=url, headers=headers).text
dowm_url = 'https:' + re.search(r'<a target="_blank" href="(?P<d_url>.*?)" class="down">下载</a>',
rep1).group('d_url')
rep2 = requests.get(url=dowm_url, headers=headers).text
return rep2
except:
print('没有找到,请输入正确的歌曲名称')
continue
def music_down(resp):
tag_music = re.search(r'<a href="(?P<d2_url>.*?)" style="display:none">(?P<mus_name>.*?)Mp3下载</a>', resp)
music_url = tag_music.group('d2_url')
music_name = tag_music.group('mus_name')
print(music_url, music_name)
if not os.path.exists('music'):
os.mkdir('music')
path = 'music/' + music_name + ".mp3"
resp = requests.get(url=music_url, headers=headers).content
with open(path, "wb") as f:
f.write(resp)
print(music_name, "下载完成")
def main():
start = time.time()
resp = start_music()
music_down(resp)
print("一共耗时", time.time() - start)
if __name__ == '__main__':
main()
执行结果如下图:
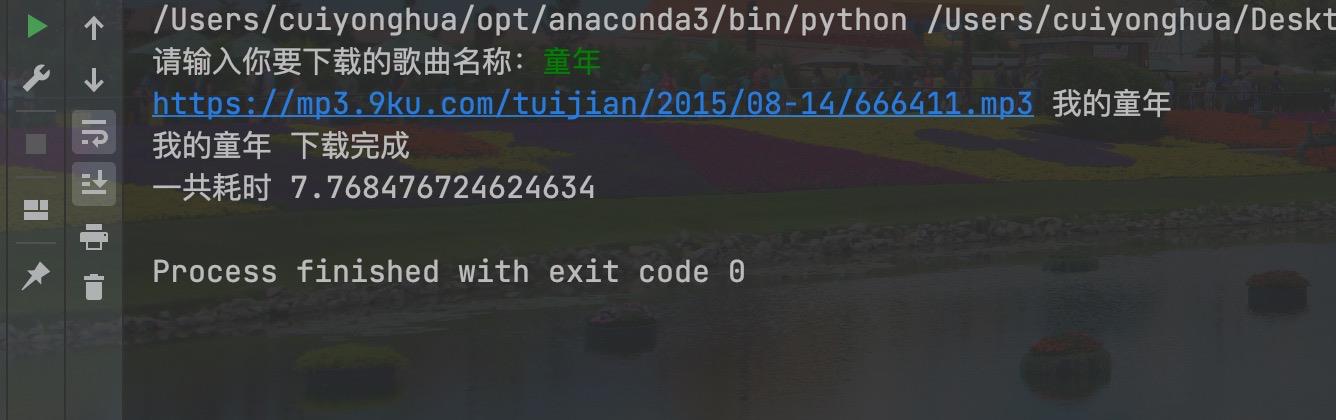
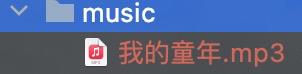
以上是关于python3爬取音乐(python经典编程案例)的主要内容,如果未能解决你的问题,请参考以下文章