一种通用整形数组压缩方法
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一种通用整形数组压缩方法相关的知识,希望对你有一定的参考价值。
简介: 我们在开发中后台应用或者中间件的时候,会存储一些数据在内存中以加快访问速度。随着数据量的增加,除了可以放置于堆外,还可以通过实时压缩来缓解。今天就给大家介绍一种压缩整形数组的方式。

作者 | 玄胤
来源 | 阿里技术公众号
我们在开发中后台应用或者中间件的时候,会存储一些数据在内存中以加快访问速度。随着数据量的增加,除了可以放置于堆外,还可以通过实时压缩来缓解。今天就给大家介绍一种压缩整形数组的方式。
一 数据压缩
数组指 long[] 或者 int[] 类型,在 Java 中应用很广。当数据量很大时,其内存占用的问题便突显出来,原因是一个 long 类型是占 8 个字节,而 int 也是占用 4 个字节,当有千万级别的数据时,其占用的空间便是上百 MB 级别的了。
1 去冗余
首先想到的就是缩减每个数字占用的空间。因为我们都知道就正数而言,int 3 个字节以上即可表示 2^24 = 16M 即 1600 百万个数,而再往后,即使用第 4 个字节,绝大多数我们是用不到的,但也不能砍掉,万一还会用到的;所以可以将高位去掉,是一种可行的思路,但必须动态去掉,该用的时候还是得用,这就需要存储用到多少个字节了(见图:数字压缩基本原理)。
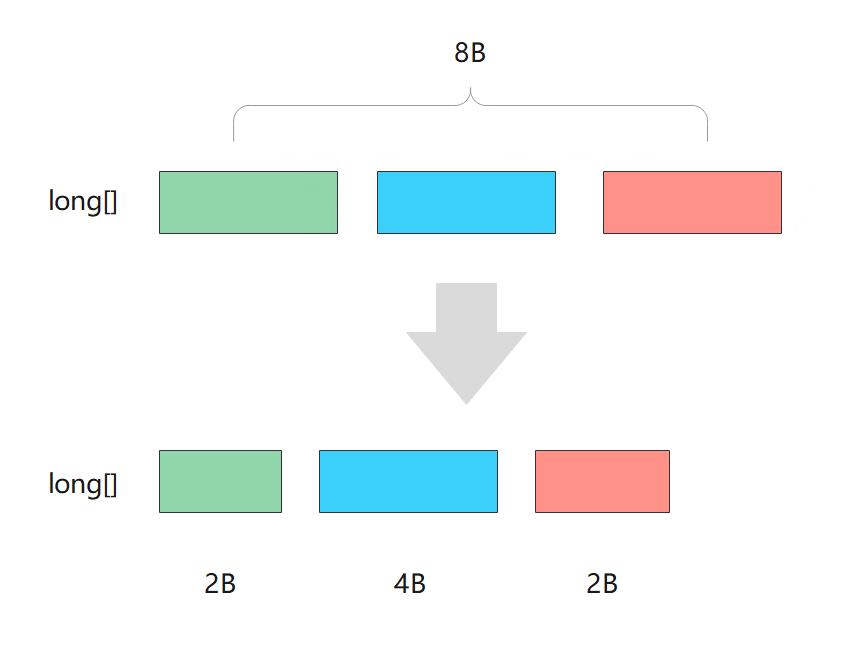
数字压缩基本原理
表示数据占用字节数有两种方式:一是借用原数据的几位来表示,就拿 long 来说,我们只需要借用 3 位就可以覆盖用到的字节数了(因为 2ˆ3 = 8),由于 2^60 以后已经是非常大的数了,几乎用不到,所以我们借用也基本不会产生负面效果;另一种就是利用字节最高位表示还有剩余数据(见图2),Facebook 在 Thrift 中就是使用此方法来压缩传输数据的。总之,我们就是要把 long 或者 int 数组压缩成 byte 数组,在使用时再依据 byte 数组中存储的信息将对应的数字还原。
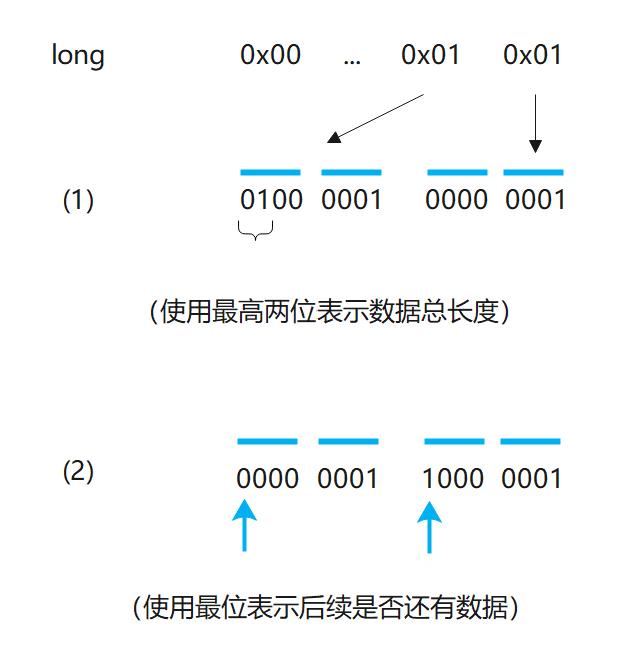
解压时识别数据大小方法
以上压缩思路在传输场景下可以很好的解决存取问题,因为都是前进先出的思路,但是如果我们需要压缩后的结构仍然具备数组的下标访问能力怎么办?
这里的难点是:之前每个数字都是固定长度,我们可以通过 “[单个数字占用的字节数]*[第几个]” 很快地找到对应的内存地址,但是压缩过后每个数字占用的空间不是一样的,这种方式就失效了,我们无法得知第 N 个数所处的内存位置。要取下标为 200 的值,难道只能线性查找 200 次吗?显然这样的效率是相当低的,其时间复杂度就由 O(1) 下降为了 O(n)。有没有更好的办法呢?当然是有的。我们可以建立索引(如下图),即:
- 将数字分为若干个桶,桶的大小可心调节(比如可以 1KB 一个桶,4KB 一个桶等)
- 我们使用另一个数组,大小为桶的数量,存储每个桶所第一个数据所在的下标
- 在查找时我首先使用二分查找到对应的桶,再使用线性查找到对应的数据
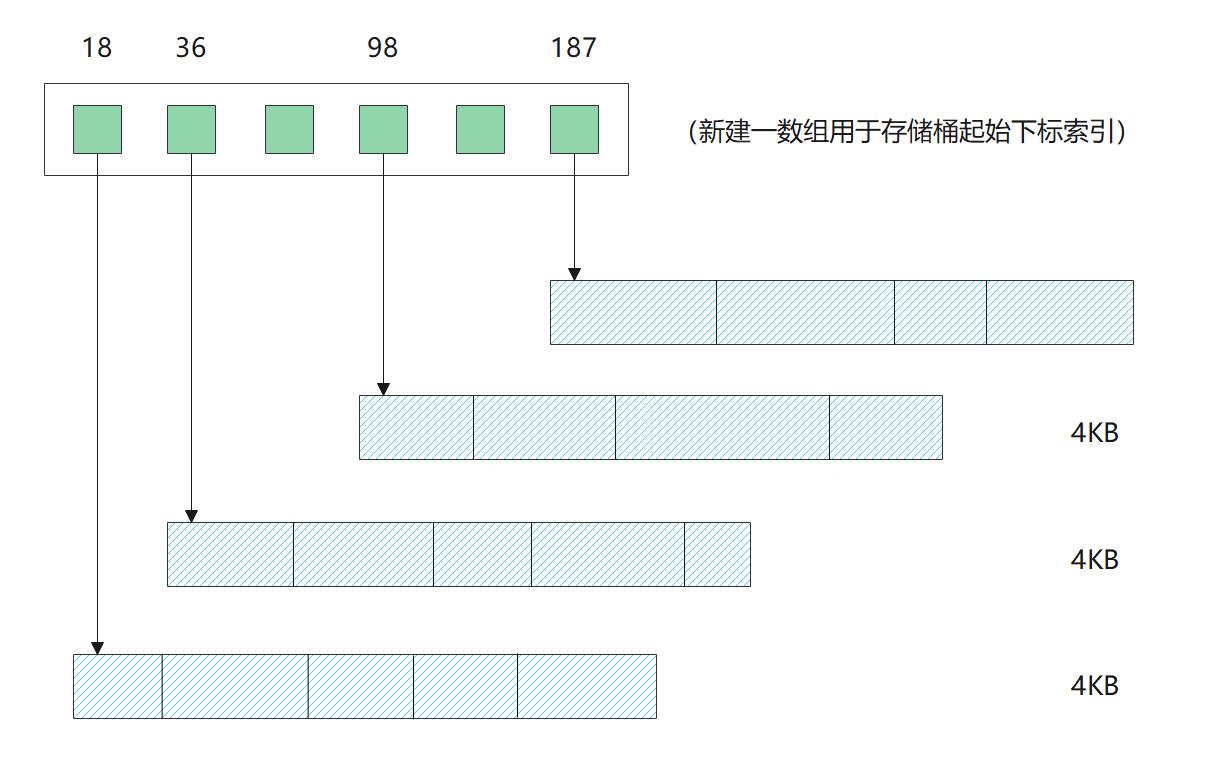
带索引可提升压缩后下标获取速度
由于只是在桶内是线性查找,而其一般不会太大,为 1KB 或者 4 KB(不能太少,因为每个桶的数组指针也是需要占用 16B 的)。由于第一次的索引二分查找解决了大部分问题,查找速度提升明显,接近 O(logN)。使用这套方式,经测试,在 4 亿随机数据的情况占用的空间可以缩减 30% 左右。经过简单测试 TPS 可以达到 100w 级别,单次存取肯定是够了。
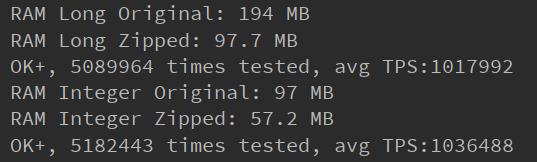
压缩效果
2 偏移量存储
利用桶内是顺序查找的性质,我们可以只在桶内第一个元素存原数字,后面的都存一个偏移量,因为当数据不会明显离散(即一会儿是十几,一会是几十亿那种),可以很好地缩减数据大小,比如两个数都占用了 3 个字节,存偏移量后,第二个数字就可以使用 1~2 个字节来表示了。当然如果你对数组本身的顺序没有要求的话,还可以先对数组进行排序,这种偏移量的效果就可以暴表了。多数情况下,可以缩减 70% 以上。
二 存取优化
上述方案在线上某应用性能压测时我们发现:单次随机获取没有受到影响,但是批量顺序获取接口下降高达 97%,从 2800 多下降到了 72。经过研究发现,批量接口之所以下降明显是由于触及到了随机获取的 TPS 上限,在 ”图:压缩效果“ 中显示,随机获取的极限 TPS 为 100w 左右,但是批量顺序场景中每次批量操作会执行 1\\~3w 次取操作,每次取操作走的是随机获取接口,所以只能是 72 这种两位数的 TPS 了,因此我们需要深度优化压缩数据的存取效率,为此采取了如下手段。
1 变固定长度桶为变长桶
之前采用二分查找是因数我们采用定长的桶(即每个桶存储的字节数是相等的),每个桶存储的数字数量不定,但如果我们采用变长桶,让每个桶存储 N 个数,那么,便可以直接通过 “整除+求余” 的方式快速打到数所在的桶,这样在寻找桶下标的时候变可以以 O(1) 的复杂度找到,相比之前二分的 O(logn) 快了很多。经过测试批量接口的 TPS 增加为 320 左右,提升 4 倍以上,效果明显。
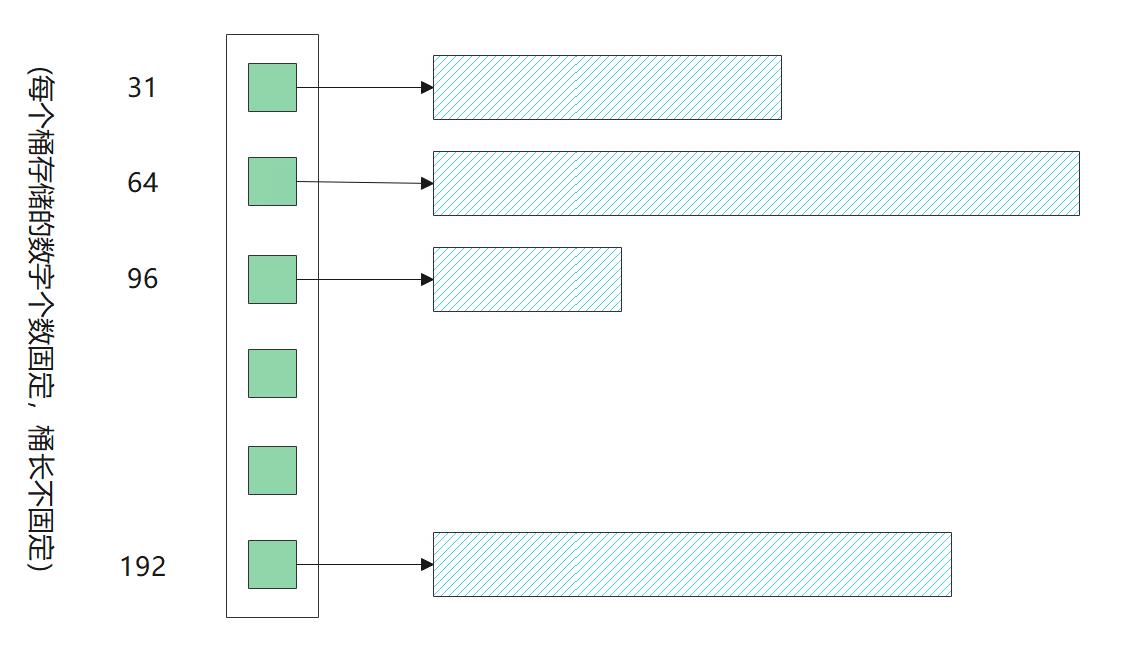
非固定桶长度可以使索引块长度固定,可快速查找
2 编写专用迭代器
批量其实也就是遍例操作,在之前遍例都是单独一个一个取的,即每次都通过 get 接口。这个接口每次都会计算一遍桶的位置,然后是偏移量,再从桶开始处依据偏移量挨个查找,在大量请求下性能开销当然大。为此我们可以根据其顺序取的特点专门设计一个迭代器,这个迭代器第一次初始化会记录下桶的位置的,下一次就可以真接偏移一个数的长度 n 而直接找到一下个数据了,其时间复杂度为 O(1)。经过测试批量接口的 TPS 可以提升至 680 左右。
3 减少中间数据,使用栈直传递共用
在原来的解压流程中,我们将数据从桶中读取出来,然后传递给解决方法进行解压,这里会在堆在产生大量的中间数据,并且之前使用许多 ByteBuffer wrap 操作,wrap 每次都会新建一个 ByteBuffer 对象,相当的耗时。由于这均为只读操作并且目前不支持数据删除,我们可以直接引用桶内的数据,通过栈传递给解压函数,这样会快很多。
修改前的代码如下,其主要逻辑是
- 计算数字所在的桶与偏移量,然后将其包装成 ByteBuffer
- 使用包装好的 ByteBuffer 线性分析字节数组,通过偏移量查找桶内数字
- 依据数字的长度信息(即前三个位)将对应的字节复制至一个临时数组中
- 将临时数组传入 inflate 方法进行解压
public long get(int ix) {
// 首先寻找 shard, 由于每个桶存储固定数量的数字,因此可以直接映射
int i = ix / SHARD_SIZE;
// 剩下的为需要线性查找的偏移量
ix %= SHARD_SIZE;
ByteBuffer buf = ByteBuffer.wrap(shards[i]);
// 找到对应数据的偏移量
long offset = 0;
if (ix > 0) {
int len = (Byte.toUnsignedInt(buf.get(0)) >>> 5);
byte[] bag = new byte[len];
buf.get(bag, 0, len);
offset = inflate(bag);
}
// 重置位置
buf.position(0);
int numPos = 0;
while (ix > 0) {
int len = (Byte.toUnsignedInt(buf.get(numPos)) >>> 5);
numPos += len;
ix -= 1;
}
buf.position(numPos);
int len = (Byte.toUnsignedInt(buf.get(numPos)) >>> 5);
byte[] bag = new byte[len];
buf.get(bag, 0, len);
return offset + inflate(bag);
}
}
private static long inflate(byte[] bag) {
byte[] num = {0, 0, 0 ,0 ,0 ,0, 0, 0};
int n = bag.length - 1;
int i;
for (i = 7; n >= 0; i--) {
num[i] = bag[n--];
}
int negative = num[i+1] & 0x10;
num[i + 1] &= 0x0f;
num[i + 1] |= negative << 63;
return negative > 0 ? -ByteBuffer.wrap(num).getLong() : ByteBuffer.wrap(num).getLong();
}
}修改后的代码:
public long get(int ix) {
// 首先寻找 shard, 由于每个桶存储固定数量的数字,因此可以直接映射
int i = ix / SHARD_SIZE;
// 剩下的为需要线性查找的偏移量
ix %= SHARD_SIZE;
byte[] shard = shards[i];
// 找到对应数据的偏移量
long offset = 0;
if (ix > 0) {
int len = (Byte.toUnsignedInt(shard[0]) >>> 5);
offset = inflate(shards[i], 0, len);
}
int numPos = 0;
while (ix > 0) {
int len = (Byte.toUnsignedInt(shard[numPos]) >>> 5);
numPos += len;
ix -= 1;
}
int len = (Byte.toUnsignedInt(shard[numPos]) >>> 5);
return offset + inflate(shards[i], numPos, len);
}
private static long inflate(byte[] shard, int numPos, int len) {
byte[] num = {0, 0, 0 ,0 ,0 ,0, 0, 0};
System.arraycopy(shard, numPos, num, num.length - len, len);
int i = num.length - len;
int negative = num[i] & 0x10;
num[i] &= 0x0f;
num[i] |= negative << 63;
return negative > 0 ? -longFrom8Bytes(num) : longFrom8Bytes(num);
}对比可以看出,这里主要是去除了 bag 数组这个中间变量,通过引用原 shard 中的数据直接去获取数据对应的 byte 数组,之前都是通过 ByteBuffer 去获取桶中的字节数据,现在我们都通过 shard[i] 直接查找,效率高了很多。经过测试,这一优化可以提升 45% 左右的性能,直接将 TPS 拉升至 910 多。
4 将堆数据变为栈数据
这个改造点有些难度的,对于中间变量来说,有些是可以避免的,我们可以使用上述的方式解决,但是有些是不能避免的,比如我们最后在解压数据的时候,对于需要返回的数字,我们肯定需要一个临时存储的地方,这就是 inflate 第一行为什么有个 byte[] num = {0, 0, 0 ,0 ,0 ,0, 0, 0}; 语句的原因。但是思考下,这个数组只是为了存储 long 的 8 个字节数据,如果直接使用 long 那么相当于是在栈上初始化了一个 8 字节大小的数组了,这里需要解决的仅仅是针对 long 如何操作指定的字节。其实这里很简单,我们只需要将对应字节左移至相应的位置即可,例如我们需要对 long 的第二个字节修改为 0x02 只需要如下操作:
longData = (longData & ˜(0xff << 2 * 8)) | (0x02 << 2 * 8)还有一个细节,就是我们直接从 byte[] 数据中取出的值是以有符号数表示的,直接合用上述上式位移会受符号位的影响,因此我们需要使用 0xff & byteAry[i] 的方式将其转换成无符号的数。最后优化后的 inflate 方法如下:
private static long inflate(byte[] shard, int numPos, int len) {
- byte[] num = {0, 0, 0 ,0 ,0 ,0, 0, 0};
+ long data = 0;
- System.arraycopy(shard, numPos, num, num.length - len, len);
+ for (int i = 0; i < len; i++) {
+ data |= (long) Byte.toUnsignedInt(shard[numPos + i]) << (len - i - 1) * 8;
+ }
- int i = num.length - len;
- int negative = num[i] & 0x10;
+ // 查看符号位
+ long negative = data & (0x10L << (len - 1) * 8);
- num[i] &= 0x0f;
- num[i] |= negative << 63;
+ // 将占用位数据清零
+ data &= ~(0xf0L << (len - 1) * 8);
- return negative > 0 ? -longFrom8Bytes(num) : longFrom8Bytes(num);
+ return negative > 0 ? -data : data;
}在这里优化后所有的堆数据申明都移除掉了,而且这里还有个附带优化,即之前采用临时数组的方式我们还需要将数组转换为 long,即 longFrom8Bytes 方法所起的作用,现在我们可以直接返回了,进一步的优化了效果,经过测试性能再次提升 35%, TPS 至 1250 左右。
5 内联短函数
每次函数调用都需要进行一次进栈退栈操作,也是费时的,在日常程序中这些损耗都可以忽略不计,但是在本次批量情况下就被放大了,通过前面的代码我们可以发现 get 方法中有一个 updateOffset 的函数,这个功能其实很简单,可以直接内联,也就多了一行代码,如下:
private void updateOffset() {
byte[] shard = shards[shardIndex];
// 找到对应数据的偏移量
int len = (0xff & shard[0]) >>> 5;
curOffset = inflate(shard, 0, len);
}我们将之内联后表示如下:
if (numPos >= shard.length) {
shardIndex++;
numPos = 0;
- updateOffset();
// 找到对应数据的偏移量
+ shard = shards[shardIndex];
+ curOffset = inflate(shard, 0, (0xff & shard[0]) >>> 5);
}还有一些例如 Byte.toUnsignedInt(int) 也就是简单的一行代码,这种都可以直接复制出来去掉方法调用。
三 性能
最后,我们批量接口的 TPS 升级至了 1380 左右,相比于最开始 72 已经提升了近 20 倍。 虽然相比于原数组还有些性能差距,但也是在同一个数量级上了。按照批量是按 5w 放大的计算,顺序单次获取的 TPS 已经达到 6500w,随机单次 get 也达到了 260w TPS,完全足够满足生产需要了。
四 优化总结
从上面的优化我们可以得出:
- Java 基本类型数据结构比对象结构快很多,越面向底层,越快
- 堆上分配数据很慢,高频调用还会频繁触发 Yong GC,对执行速度影响相当大,所以能栈绝不用堆
- 对象调用慢于直接操作,因为需要进退栈,所以如果是几行简单调用,直接将逻辑复制调出会快很多,例如 Byte.toUnsignedInt()——当然,这是在极致性能下
- 减少中间数据、减少临时变量
- 任何细小的性能损失在巨大的调用量在都会成倍扩大,所以对于批量接口要倍加小心
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于一种通用整形数组压缩方法的主要内容,如果未能解决你的问题,请参考以下文章