Per-FedAvg
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Per-FedAvg相关的知识,希望对你有一定的参考价值。
《Personalized Federated Learning: A Meta-Learning Approach》这篇文章利用元学习来实现联邦个性化学习,将用户看作元学习中的多个任务。和元学习一样,其目标是找到一个初始化模型,当前用户或新用户只需对他们的本地数据执行一步或几步梯度下降,便可将模型适应他们的本地数据集。这样当有一个新用户进来时,就可以通过一步或几步梯度下降快速获得一个高效的个性化模型。
文章主要内容有三点:
1、将元学习和FL进行结合,具体以FedAvg为框架,以MAML为内容,提出Per-FedAvg算法。
2、从理论角度分析Per-FedAvg在非凸函数下的收敛性。
3、描述“用户数据底层分布的相似度”对Per-FedAvg性能的影响。
Per-FedAvg
函数定义
FedAvg的优化目标如(1)所示

假设每个用户获取初始参数w,使用相对于其自身损失函数
f
i
f_i
fi的一次梯度下降对参数w进行更新,那么优化目标就有(1)变为(3)。其中a是学习率,n是参预训练的任务个数。优化目标F(w)就是所有元函数(用户更新后的本地目标函数)的平均。
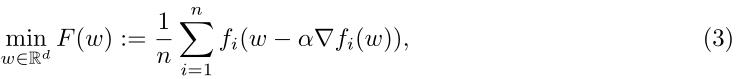
每个用户的元函数可以定义为
F
i
(
w
)
F_i(w)
Fi(w),如(4)所示。

算法步骤
和FedAvg一样,首先第一步是计算每个本地元函数的梯度,梯度
▽
F
i
(
w
)
▽F_i(w)
▽Fi(w)如(5)所示。
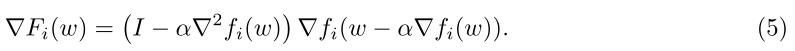
如果每轮梯度计算都要基于用户的所有数据,会需要较大的计算量。应用SGD,每次只根据用户的数据分布
p
i
p_i
pi选取本地数据
D
i
D^i
Di的一个batch来计算一个无偏梯度,公式如(6)所示。(5)中的
▽
2
f
i
(
w
)
▽^2f_i(w)
▽2fi(w)也同样可以作如此变换。
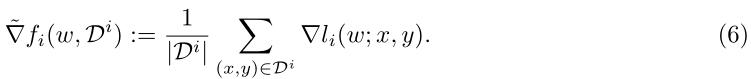
用户的本地参数的第k轮更新如(7)所示。β是本地更新的学习率,
w
k
+
1
,
t
i
w^i_{k+1,t}
wk+1,ti中i是指用户i,k+1是指对k轮的参数进行更新,t是本地梯度下降的次数。也就是说
w
k
+
1
,
0
i
w^i_{k+1,0}
wk+1,0i=
w
k
w_k
wk,
w
k
w_k
wk是本轮服务器发送给每个用户的元模型。
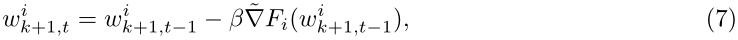
将(6)(7)的定义式代入(5)得到本地元函数梯度的有偏表达式如(8)所示。其中
D
t
i
D^i_t
Dti,
D
t
′
i
D^{'i}_t
Dt′i,
D
t
′
′
i
D^{''i}_t
Dt′′i是用户本地数据
D
i
D^i
Di三个独立的batch。
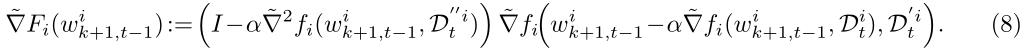
每个用户将更新后的参数
w
k
+
1
,
t
i
w^i_{k+1,t}
wk+1,ti发送到服务端,由服务端进行参数聚合,得到更新后的元模型参数
w
k
+
1
w_{k+1}
wk+1=1/rnΣ
w
k
+
1
,
t
i
w^i_{k+1,t}
wk+1,ti。
完整的算法框架如Algorithm 1所示

该算法基于FL框架,将整个MAML过程放在一个设备上进行(meta-training更新本地参数
w
k
+
1
,
t
i
w^i_{k+1,t}
wk+1,ti-hat、meta-learning更新本地元模型参数
w
k
+
1
,
t
i
w^i_{k+1,t}
wk+1,ti),最后在服务端进行参数聚合得到更新后的全局元模型参数。
以上是关于Per-FedAvg的主要内容,如果未能解决你的问题,请参考以下文章