百度C++工程师的那些极限优化(并发篇)
Posted C语言与CPP编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度C++工程师的那些极限优化(并发篇)相关的知识,希望对你有一定的参考价值。

导读:对于工程经验比较丰富的同学,并发应该也并不是陌生的概念了,但是每个人所理解的并发问题,却又往往并不统一,本文系统梳理了百度C++工程师在进行并发优化时所作的工作。
全文15706字,预计阅读时间24分钟。
一、背景
简单回顾一下,一个程序的性能构成要件大概有三个,即算法复杂度、IO开销和并发能力。由于现代计算机体系结构复杂化,造成很多时候,工程师的性能优化会更集中在算法复杂度之外的另外两个方向上,即IO和并发,在之前的《百度C++工程师的那些极限优化(内存篇)》中,我们介绍了百度C++工程师工程师为了优化性能,从内存IO角度出发所做的一些优化案例。
这次我们就再来聊一聊另外一个性能优化的方向,也就是所谓的并发优化。和IO方向类似,对于工程经验比较丰富的同学,并发应该也并不是陌生的概念了,但是每个人所理解的并发问题,却又往往并不统一。所以下面我们先回到一个更根本的问题,重新梳理一下所谓的并发优化。
二、为什么我们需要并发?
是的,这个问题可能有些跳跃,但是在自然地进展到如何处理各种并发问题之前,我们确实需要先停下来,回想一下为什么我们需要并发?
这时第一个会冒出来的概念可能会是大规模,例如我们要设计大规模互联网应用,大规模机器学习系统。可是我们仔细思考一下,无论使用了那种程度的并发设计,这样的规模化系统背后,都需要成百上千的实例来支撑。也就是,如果一个设计(尤其是无状态计算服务设计)已经可以支持某种小规模业务。那么当规模扩大时,很可能手段并不是提升某个业务单元的处理能力,而是增加更多业务单元,并解决可能遇到的分布式问题。
其实真正让并发编程变得有价值的背景,更多是业务单元本身的处理能力无法满足需求,例如一次请求处理时间过久,业务精细化导致复杂度积累提升等等问题。那么又是什么导致了近些年来,业务单元处理能力问题不足的问题呈现更加突出的趋势?
可能下面这个统计会很说明问题:
(https://www.karlrupp.net/2015/06/40-years-of-microprocessor-trend-data/)
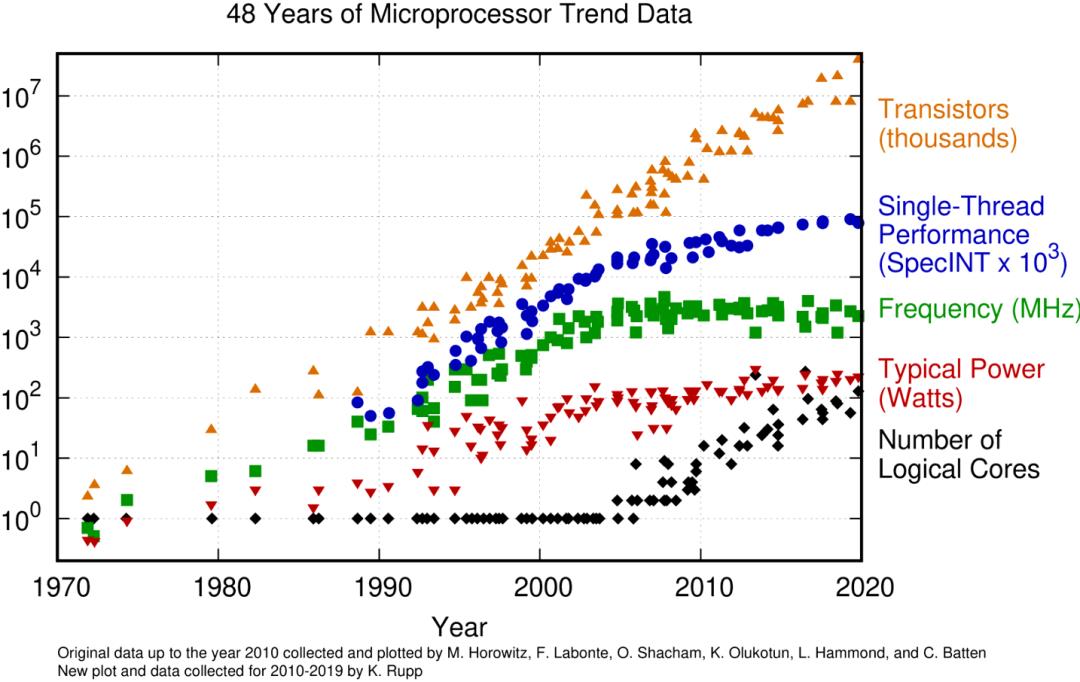
上图从一个长线角度,统计了CPU的核心指标参数趋势。从其中的晶体管数目趋势可以看出,虽然可能逐渐艰难,但是摩尔定律依然尚能维持。然而近十多年,出于控制功耗等因素的考虑,CPU的主频增长基本已经停滞,持续增加的晶体管转而用来构建了更多的核心。
从CPU厂商角度来看,单片处理器所能提供的性能还是保持了持续提升的,但是单线程的性能增长已经显著放缓。从工程师角度来看,最大的变化是硬件红利不再能透明地转化成程序的性能提升了。随时代进步,更精准的算法,更复杂的计算需求,都在对的计算性能提出持续提升的要求。早些年,这些算力的增长需求大部分还可以通过处理器更新换代来自然解决,可是随着主频增长停滞,如果无法利用多核心来加速,程序的处理性能就会随主频一同面临增长停滞的问题。因此近些年来,是否能够充分利用多核心计算,也越来越成为高性能程序的一个标签,也只有具备了充分的多核心利用能力,才能随新型硬件演进,继续表现出指数级的性能提升。而伴随多核心多线程程序设计的普及,如何处理好程序的并发也逐渐成了工程师的一项必要技能。
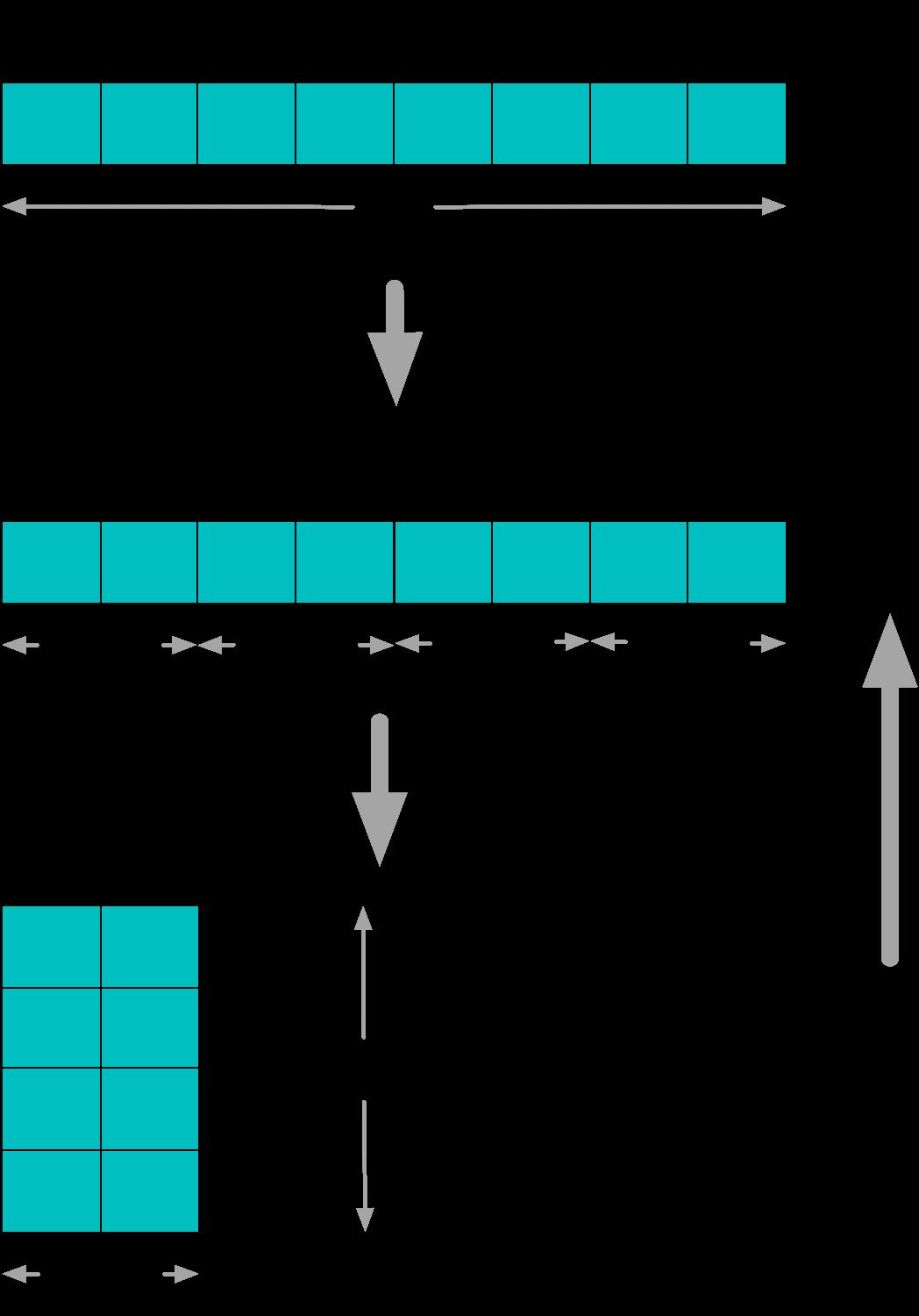
上图描述了并发加速的基本原理,首先是对原始算法的单一执行块拆分成多个能够同时运行的子任务,并设计好子任务间的协同。之后利用底层的并行执行部件能力,将多个子任务在时间上真正重叠起来,达到真正提升处理速度的目的。
需要注意的是还有一条从下而上的反向剪头,主要表达了,为了正确高效地利用并行执行部件,往往会反向指导上层的并发设计,例如正确地数据对齐,合理的临界区实现等。虽然加速看似完全是由底层并行执行部件的能力所带来的,程序设计上只需要做到子任务拆分即可。但是现阶段,执行部件对上层还无法达到透明的程度,导致这条反向依赖对于最终的正确性和性能依然至关重要。既了解算法,又理解底层设计,并结合起来实现合理的并发改造,也就成为了工程师的一项重要技能。
三、单线程中的并行执行
提到并行执行部件,大家的第一个印象往往时多核心多线程技术。不过在进入到多线程之前,我们先来看看,即使是单线程的程序设计中,依然需要关注的那些并行执行能力。回过头再仔细看前文的处理器趋势图其实可以发现,虽然近年主频不再增长,甚至稳中有降,但是单线程处理性能其实还是有细微的提升的。这其实意味着,在单位时钟周期上,单核心的计算能力依然在提升,而这种提升,很大程度上就得益于单核心单线程内的细粒度并行执行能力。
3.1 SIMD
其中一个重要的细粒度并行能力就是SIMD(Single Instruction Multiple Data),也就是多个执行单元,同时对多个数据应用相同指令进行计算的模式。在经典分类上,一般单核心CPU被归入SISD(Single Instruction Single Data),而多核心CPU被归入MIMD(Mingle Instruction Multiple D ata),而GPU才被归入SIMD的范畴。但是现代CPU上,除了多核心的MIMD基础模型,也同时附带了细粒度SIMD计算能力。
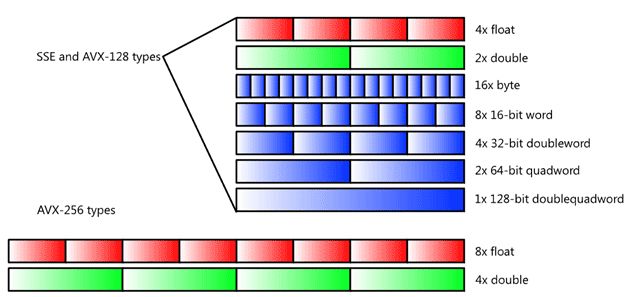
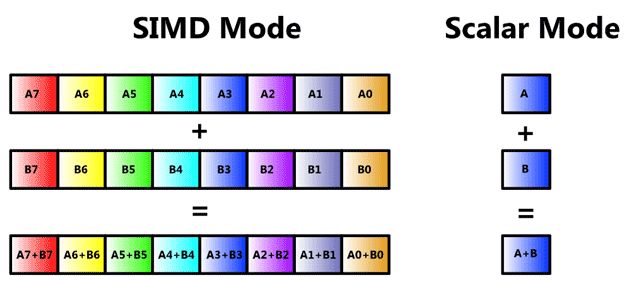
上图是Intel关于SIMD指令的一个示意图,通过增加更大位宽的寄存器实现在一个寄存器中,“压缩”保存多个较小位宽数据的能力。再通过增加特殊的运算指令,对寄存器中的每个小位宽的数据元素,批量完成某种相同的计算操作,例如图示中最典型的对位相加运算。以这个对位相加操作为例,CPU只需要增大寄存器,内存传输和计算部件位宽,针对这个特殊的应用场景,就提升到了8倍的计算性能。相比将核心数通用地提升到8倍大小,这种方式付出的成本是非常少的,指令流水线系统,缓存系统都做到了复用。
从CPU发展的视角来看,为了能够在单位周期内处理更多数据,增加核心数的MIMD强化是最直观的实现路径。但是增加一套核心,就意味增加一套 完整的指令部件、流水线部件和缓存部件,而且实际应用时,还要考虑额外的核心间数据分散和聚合的传输和同步开销。一方面高昂的部件需求, 导致完整的核心扩展成本过高,另一方面,多核心间传输和同步的开销针对小数据集场景额外消耗过大,还会进一步限制应用范围。为了最大限度利用好有限的晶体管,现代CPU在塑造更多核心的同时,也在另一个维度上扩展单核心的处理和计算位宽,从而实现提升理论计算性能(核心数 * 数据宽度)的目的。
不过提起CPU上的SIMD指令支持,有一个绕不开的话题就是和GPU的对比。CPU上早期SIMD指令集(MMX)的诞生背景,和GPU的功能定位就十分类似,专注于加速图像相关算法,近些年又随着神经网络计算的兴起,转向通用矩阵类计算加速。但是由于GPU在设计基础上就以面向密集可重复计算负载设计,指令部件、流水线部件和缓存部件等可以远比CPU简洁,也因此更容易在量级上进行扩展。这就导致,当计算密度足够大,数据的传输和同步开销被足够冲淡的情况下(这也是典型神经网络计算的的特性),CPU仅作为控制流进行指挥,而数据批量传输到GPU协同执行反而 会更简单高效。
由于Intel自身对SIMD指令集的宣传,也集中围绕神经网络类计算来展开,而在当前工程实践经验上,主流的密集计算又以GPU实现为主。这就导致了不少CPU上SIMD指令集无用论应运而生,尤其是近两年Intel在AVX512初代型号上的降频事件,进一步强化了『CPU就应该做好CPU该做的事情』这一论调。但是单单从这一的视角来认识CPU上的SIMD指令又未免有些片面,容易忽视掉一些真正有意义的CPU上SIMD应用场景。

对于一段程序来讲,如果将每读取单位数据,对应的纯计算复杂度大小定义为计算密度,而将算法在不同数据单元上执行的计算流的相同程度定义为模式重复度,那么可以以此将程序划分为4个象限。在大密度可重复的计算负载(典型的重型神经网络计算),和显著小密度和非重复计算负载(例如html树状解析)场景下,业界在CPU和GPU的选取上其实是有相对明确“最优解”的。不过对于过渡地带,计算的重复特征没有那么强, 或者运算密度没有那么大的场景下,双方的弱点都会被进一步放大。即便是规整可重复的计算负载,随着计算本身强度减小,传输和启动成本逐渐显著。另一方面,即便是不太规整可重复的计算负载,随着计算负荷加大,核心数不足也会逐渐成为瓶颈。这时候,引入SIMD的CPU和引入SIMT 的GPU间如何选择和使用,就形成了没有那么明确,见仁见智的权衡空间。
即使排除了重型神经网络,从程序的一般特性而言,具有一定规模的重复特性也是一种普遍现象。例如从概念上讲,程序中的循环段落,都或多或少意味着批量/重复的计算负载。尽管因为掺杂着分支控制,导致重复得没有那么纯粹,但这种一定规模的细粒度重复,正是CPU上SIMD发挥独特价值的地方。例如最常见的SIMD优化其实就是memcpy,现代的memcpy实现会探测CPU所能支持的SIMD指令位宽,并尽力使用来加速内存传输。另一方面现代编译器也会利用SIMD指令来是优化对象拷贝,进行简单循环向量化等方式来进行加速。类似这样的一类优化方法偏『自动透明』,也是默默支撑着主频不变情况下,性能稍有上升的重要推手。
可惜这类简单的自动优化能做到的事情还相当有限,为了能够充分利用CPU上的SIMD加速,现阶段还非常依赖程序层进行主动算法适应性改造,有 目的地使用,换言之,就是主动实施这种单线程内的并发改造。一个无法自动优化的例子就是《内存篇》中提到的字符串切分的优化,现阶段通过编译器分析还很难从循环 + 判断分支提取出数据并行pattern并转换成SIMD化的match&mask动作。而更为显著的是近年来一批针对SIMD指令重新设计的算法,例如Swiss Table哈希表,simdjson解析库,base64编解码库等,在各自的领域都带来了倍数级的提升,而这一类算法适应性改造,就已经完全脱离了自动透明所能触及的范围。可以预知近些年,尤其随着先进工艺下AVX512降频问题的逐渐解决,还会/也需要涌现出更多的传统基础算法的SIMD改造。而熟练运用SIMD指令优化技术,也将成为C++工程师的一项必要技能。
3.2 OoOE
另一个重要的单线程内并行能力就是乱序执行OoOE(Out of Order Execution)。经典教科书上的CPU流水线机制一般描述如下(经典5级RISC流水线)。
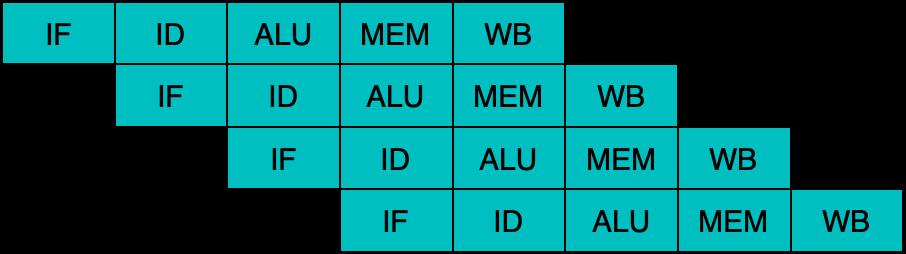
指令简化表达为取指/译码/计算/访存/写回环节,当执行环节遇到数据依赖,以及缓存未命中等场景,就会导致整体停顿的产生。其中MEM环节的影响尤其显著,主要也是因为缓存层次的深化和多核心的共享现象,带来单次访存所需周期数参差不齐的现象越来越严重。上图中的流水线在多层缓存下的表现,可能更像下图所示:

为了减轻停顿的影响,现代面向性能优化的CPU一般引入了乱序执行结合超标量的技术。也就是一方面,对于重点执行部件,比如计算部件,访存部件等,增加多份来支持并行。另一方面,在执行部件前引入缓冲池/队列机制,通用更长的预测执行来尽可能打满每个部件。最终从流水线模式,转向了更类似『多线程』的设计模式:
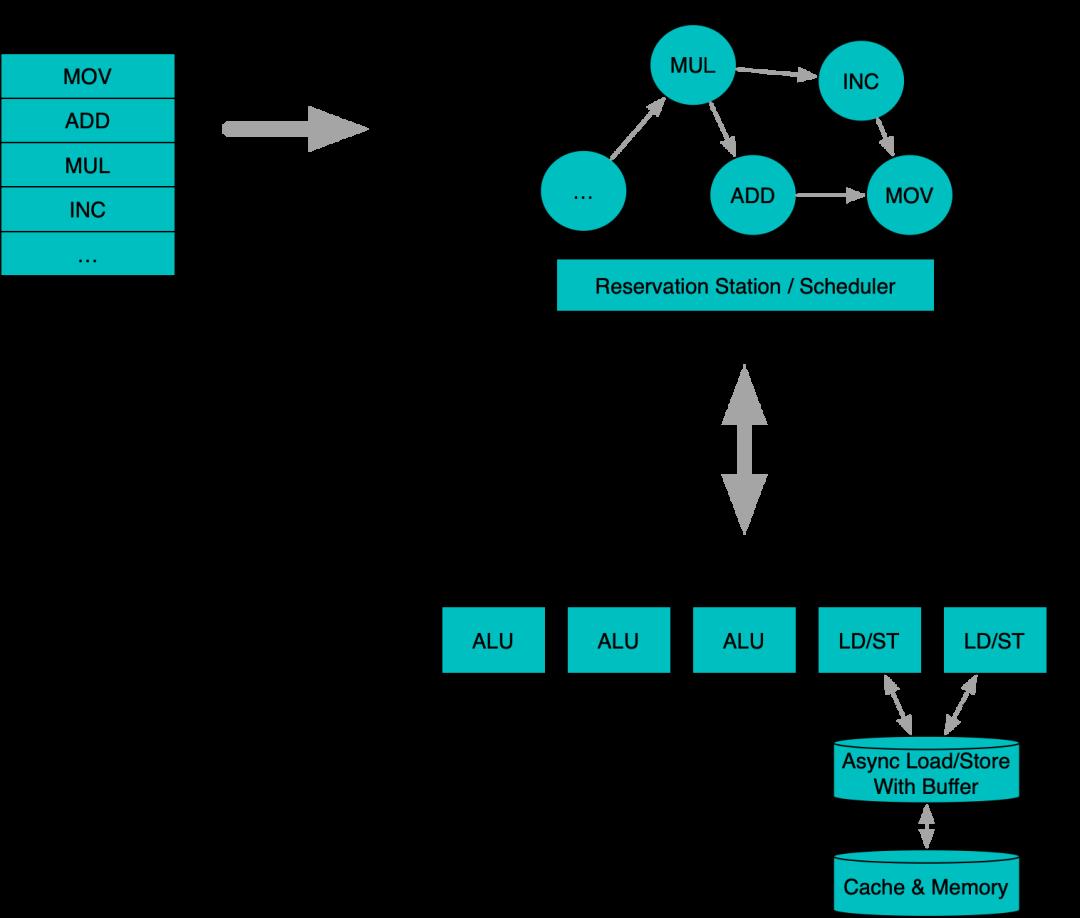
乱序执行系统中,一般会将通过预测维护一个较长的指令序列,并构建一个指令池,通过解析指令池内的依赖关系,形成一张DAG(有向无环图) 组织的网状结构。通过对DAG关系的计算,其中依赖就绪的指令,就可以进入执行态,被提交到实际的执行部件中处理。执行部件类似多线程模型中的工作线程,根据特性细分为计算和访存两类。计算类一般有相对固定可预期的执行周期,而访存类由于指令周期差异较大,采用了异步回调的模型,通过Load/Store Buffer支持同时发起数十个访存操作。
乱序执行系统和传统流水线模式的区别主要体现在,当一条访存指令因为Cache Miss而无法立即完成时,其后无依赖关系的指令可以插队执行(类似于多线程模型中某个线程阻塞后,OS将其挂起并调度其他线程)。插队的计算类指令可以填补空窗充分利用计算能力,而插队的访存指令通过更早启动传输,让访存停顿期尽量重叠来减小整体的停顿。因此乱序执行系统的效率,很大程度上会受到窗口内指令DAG的『扁平』程度的影响,依赖深度较浅的DAG可以提供更高的指令级并发能力,进而提供更高的执行部件利用率,以及更少的停顿周期。另一方面,由于Load/Store Buffer也有最大的容量限制,处理较大区域的内存访问负载时,将可能带来更深层穿透的访存指令尽量靠近排布,来提高访存停顿的重叠,也能够有效减少整体的停顿。
虽然理论比较清晰,可是在实践中,仅仅从外部指标观测到的性能表现,往往难以定位乱序执行系统内部的热点。最直白的CPU利用率其实只能表达线程未受阻塞,真实在使用CPU的时间周期,但是其实并不能体现CPU内部部件真正的利用效率如何。稍微进阶一些的IPC(Instruction Per Cyc le),可以相对深入地反应一些利用效能,但是影响IPC的因素又多种多样。是指令并行度不足?还是长周期ALU计算负载大?又或者是访存停顿过久?甚至可能是分支预测失败率过高?真实程序中,这几项问题往往是并存的,而且单一地统计往往又难以统一比较,例如10次访存停顿/20次ALU 未打满/30个周期的页表遍历,到底意味着瓶颈在哪里?这个问题单一的指标往往就难以回答了。
3.3 TMAM
TMAM(Top-down Microarchitecture Analysis Method)是一种利用CPU内部PMU(Performance Monitoring Unit)计数器来从上至下分解定位部件瓶颈的手段。例如在最顶层,首先以标定最大指令完成速率为标准(例如Skylake上为单周期4条微指令),如果无法达到标定,则认为瓶颈在于未能充分利用部件。进一步细分以指令池为分界线,如果指令池未满,但是取指部件又无法满负荷输出微指令,就表明『前端』存在瓶颈。另一种无法达到最大指令速率的因素,是『前端』虽然在发射指令到指令池,但是因为错误的预测,最终没有产出有效结果,这类损耗则被归入『错误预测』。除此以外的问题就是因为指令池调度执行能力不足产生的反压停顿,这一类被归为『后端』瓶颈。进一步例如『后端』瓶颈还可以根 据,停顿发生时,是否伴随了ALU利用不充分,是否伴随了Load/Store Buffer满负荷等因素,继续进行分解细化,形成了一套整体的分析方法。例如针对Intel,这一过程可以通过pmu-tools来被自动完成,对于指导精细化的程序瓶颈分析和优化往往有很大帮助。
int array[1024];
for (size_t i = 0; i < 1024; i += 2) {
int a = array[i];
int b = array[i + 1];
for (size_t j = 0; j < 1024; ++j) {
a = a + b;
b = a + b;}
array[i] = a;
array[i + 1] = b;
}
例如这是里演示一个多轮计算斐波那契数列的过程,因为计算特征中深层循环有强指令依赖,且内层循环长度远大于常规乱序执行的指令池深度, 存在较大的计算依赖瓶颈,从工具分析也可以印证这一点。


程序的IPC只有1,内部瓶颈也显示集中在『后端』内部的部件利用效率(大多时间只利用了一个port),此时乱序执行并没有发挥作用。
int array[1024];for (size_t i = 0; i < 1024; i += 4) { int a = array[i]; int b = array[i + 1]; int c = array[i + 2]; int d = array[i + 3]; for (size_t j = 0; j < 1024; ++j) { a = a + b; b = a + b; c = c + d; d = c + d; } array[i] = a; array[i + 1] = b; array[i + 2] = c; array[i + 3] = d;}
这里演示了典型的的循环展开方法,通过在指令窗口内同时进行两路无依赖计算,提高了指令并行度,通过工具分析也可以确认到效果。


不过实践中,能够在寄存器上反复迭代的运算并不常见,大多情况下比较轻的计算负载,搭配比较多的访存动作会更经常遇到,像下面的这个例子:
struct Line {
char data[64];
};
Line* lines[1024]; // 其中乱序存放多个缓存行
for (size_t i = 0; i < 1024; ++i) {
Line* line = lines[i];
for (size_t j = 0; j < 64; ++j) {
line->data[j] += j;
}
}
这是一个非连续内存上进行累加计算的例子,随外层迭代会跳跃式缓存行访问,内层循环在连续缓存行上进行无依赖的计算和访存操作。

可以看到,这一次的瓶颈到了穿透缓存后的内存访存延迟上,但同时内存访问的带宽并没有被充分利用。这是因为指令窗口内虽然并发度不低,不过因为缓存层次系统的特性,内层循环中的多个访存指令,其实最终都是等待同一行被从内存加载到缓存。导致真正触发的底层访存压力并不足以打满传输带宽,但是程序却表现出了较大的停顿。
for (size_t i = 0; i < 1024; i += 2) {
Line* line1 = lines[i];
Line* line2 = lines[i + 1];
...
for (size_t j = 0; j < 64; ++j) {
line1->data[j] += j;
line2->data[j] += j;
...
}
}

通过调整循环结构,在每一轮内层循环中一次性计算多行数据,可以在尽量在停顿到来的指令窗口内,让更多行出于同时从内存系统进行传输。从统计指标上也可以看出,瓶颈重心开始从穿透访存的延迟,逐步转化向访存带宽,而实际的缓存传输部件Fill Buffer也开始出现了满负荷运作的情况。
3.4 总结一下单线程并发
现代CPU在遇到主频瓶颈后,除了改为增加核心数,也在单核心内逐步强化并行能力。如果说多进程多线程技术的普及,让多核心的利用技术多少不那么罕见和困难,那么单核心内的并行加速技术,因为更加黑盒(多级缓存加乱序执行),规范性不足(SIMD),相对普及度和利用率都会更差一些。虽然硬件更多的细节向应用层暴露让程序的实现更加困难,不过困难和机会往往也是伴随出现的,既然客观发展上这种复杂性增加已经无可避免,那么是否能善加利用也成了工程师进行性能优化时的一项利器。随着体系结构的进一步复杂化,可见的未来一段时间里,能否利用一些体系结构的原理和工具来进行优化,也会不可避免地成为服务端工程师的一项重要技能。
四、多线程并发中的临界区保护
相比单线程中的并发设计,多线程并发应该是更为工程师所熟悉的概念。如今,将计算划分到多线程执行的应用技术本身已经相对成熟了,相信各个服务端工程师都有各自熟悉的队列+线程池的小工具箱。在不做其他额外考虑的情况下,单纯的大任务分段拆分,提交线程池并回收结果可能也仅仅是几行代码就可以解决的事情了。真正的难点,其实往往不在于『拆』,而在于『合』的部分,也就是任务拆分中无法避免掉的共享数据操作环节。如果说更高的分布式层面,还可以尽可能地利用Share Nothing思想,在计算发生之前,就先尽量通过任务划分来做到尽可能充分地隔离资源。但是深入到具体的计算节点内部,如果再进行一些细粒度的拆分加速时,共享往往就难以彻底避免了。如何正确高效地处理这些无法避免的共享问题,就涉及到并发编程中的一项重要技术,临界区保护。
4.1 什么是临界区
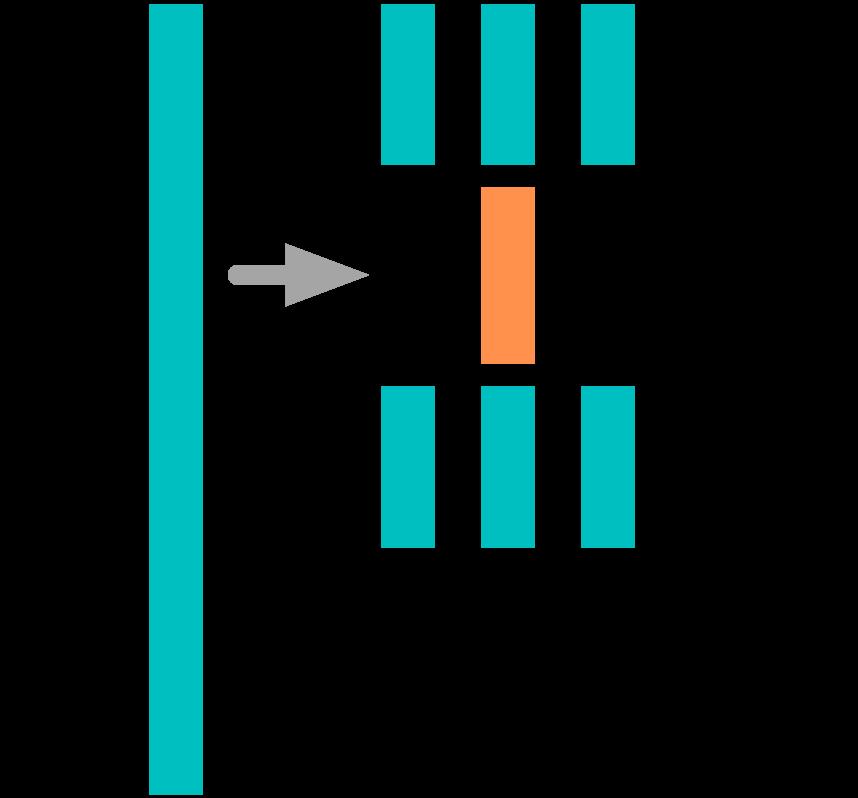
算法并发改造中,一般会产生两类段落,一类是多个线程间无需交互就可以独立执行的部分,这一部分随着核心增多,可以顺利地水平扩展。而另一类是需要通过操作共享的数据来完成执行,这部分操作为了能够正确执行,无法被多个核心同时执行,只能每个线程排队通过。因此临界区内的代码,也就无法随着核心增多来扩展,往往会成为多线程程序的瓶颈点。也是因为这个特性,临界区的效率就变得至关重要,而如何保证各个线程安全地通过临界区的方法,就是临界区保护技术。
4.1.1 Mutual Exclusion
最基本的临界区保护方法,就是互斥技术。这是一种典型的悲观锁算法,也就是假设临界区高概率存在竞争,因此需要先利用底层提供的机制进行仲裁,成功获得所有权之后,才进入临界区运行。这种互斥算法,有一个典型的全局阻塞问题,也就是上图中,当临界区内的线程发生阻塞,或被操作系统换出时,会出现一个全局执行空窗。这个执行空窗内,不仅自身无法继续操作,未获得锁的线程也只能一同等待,造成了阻塞放大的现象。但是对于并行区,单一线程的阻塞只会影响自身,同样位于在上图中的第二次阻塞就是如此。
由于真实发生在临界区内的阻塞往往又是不可预期的,例如发生了缺页中断,或者为了申请一块内存而要先进行一次比较复杂的内存整理。这就会让阻塞扩散的问题更加严重,很可能改为让另一个线程先进入临界区,反而可以更快顺利完成,但是现在必须所有并发参与者,都一起等待临界区持有者来完成一些并没有那么『关键』的操作。因为存在全局阻塞的可能性,采用互斥技术进行临界区保护的算法有着最低的阻塞容忍能力,一般在『非阻塞算法』领域作为典型的反面教材存在。
4.1.2 Lock Free

针对互斥技术中的阻塞问题,一个改良型的临界区保护算法是无锁技术。虽然叫做无锁,不过主要是取自非阻塞算法等级中的一种分类术语,本质上是一种乐观锁算法。也就是首先假设临界区不存在竞争,因此直接开始临界区的执行,但是通过良好的设计,让这段预先的执行是无冲突可回滚的。但是最终设计一个需要同步的提交操作,一般基于原子变量CAS(Compare And Swap),或者版本校验等机制完成。在提交阶段如果发生冲突,那么被仲裁为失败的各方需要对临界区预执行进行回滚,并重新发起一轮尝试。
无锁技术和互斥技术最大的区别是,临界区核心的执行段落是可以类似并行段落一样独立进行,不过又不同于真正的并行段落,同时执行的临界区中,只有一个是真正有效的,其余最终将被仲裁为无效并回滚。但是引入了冗余的执行操作后,当临界区内再次发生阻塞时,不会像互斥算法那样在参与线程之间进行传播,转而让一个次优的线程成功提交。虽然从每个并发算法参与线程的角度,存在没有执行『实质有效』计算的段落,但是这种浪费计算的段落,一定对应着另一个参与线程执行了『有效』的计算。所以从整个算法层面,能够保证不会全局停顿,总是有一些有效的计算在运行。
4.1.3 Wait-Free
无锁技术主要解决了临界区内的阻塞传播问题,但是本质上,多个线程依然是排队顺序经过临界区。形象来说,有些类似交通中的三叉路口汇合, 无论是互斥还是无锁,最终都是把两条车道汇聚成了一条单车道,区别只是指挥是否高明能保证没有断流出现。可是无论如何,临界区内全局吞吐降低成串行这点是共同的缺陷。
而Wait Free级别和无锁的主要区别也就体现在这个吞吐的问题上,在无全局停顿的基础上,Wait Free进一步保障了任意算法参与线程,都应该在有限的步骤内完成。这就和无锁技术产生了区别,不只是整体算法时时刻刻存在有效计算,每个线程视角依然是需要持续进行有效计算。这就要求了多线程在临界区内不能被细粒度地串行起来,而必须是同时都能进行有效计算。回到上面三叉路口汇聚的例子,就以为着在Wait Free级别下,最终汇聚的道路依旧需要是多车道的,以保证可以同时都能够有进展。
虽然理论角度存在不少有Wait Free级别的算法,不过大多为概念探索,并不具备工业使用价值。主要是由于Wait Free限制了同时有进展,但是并没有描述这个进展有多快。因此进一步又提出了细分子类,以比较有实际意义的Wait-Free Population Oblivious级别来说,额外限制了每个参与线程必须要在预先可给出的明确执行周期内完成,且这个周期不能和与参与线程数相关。这一点明确拒绝了一些类似线程间协作的方案(这些方案往往引起较大的缓存竞争),以及一些需要很长很长的有限步来完成的设计。

上图实例了一个典型的Wait Free Population Oblivious思路。进行临界区操作前,通过一个协同操作为参与线程分配独立的ticket,之后每个参与线程可以通过获取到的ticket作为标识,操作一块独立的互不干扰的工作区,并在其中完成操作。工业可用的Wait Free算法一般较难设计,例如ticket机制要求在协调动作中原子完成工作区分配,而很多数据结构是不容易做到这样的拆分的。时至今日各种数据结构上工业可用的Wait Free算法依旧是一项持续探索中的领域。
4.2 无锁不是万能的
从非阻塞编程的角度看,上面的几类临界区处理方案优劣有着显著的偏序关系,即Wait Free > Lock Free > Mutual Exclusion。这主要是从阻塞适应性角度进行的衡量,原理上并不能直接对应到性能纬度。但是依然很容易给工程师造成一个普适印象,也就是『锁是很邪恶的东西,不使用锁来实现算法可以显著提高性能』,再结合广为流传的锁操作自身开销很重的认知,很多工程师在实践中会有对锁敬而远之的倾向。那么,这个指导思想是否是完全正确的?
让我们先来一组实验:
// 在一个cache line上进行指定步长的斐波那契计算来模拟临界区计算负载
uint64_t calc(uint64_t* sequence, size_t size) {
size_t i;
for (i = 0; i < size; ++i) {
sequence[(i + 1) & 7] += sequence[i & 7];
}
return sequence[i & 7];
}
{ // Mutual Exclusion
::std::lock_guard<::std::mutex> lock(mutex);
sum += calc(sequence, workload);
}
{ // Lock Free / Atomic CAS
auto current = atomic_sum.load(::std::memory_order_relaxed);
auto next = current;
do {
next = current + calc(sequence, workload);
} while (!atomic_sum.compare_exchange_weak(
current, next, ::std::memory_order_relaxed));
}
{ // Wait Free / Atomic Modify
atomic_sum.fetch_add(calc(sequence, workload), ::std::memory_order_relaxed);
}
这里采用多线程累加作为案例,分别采用上锁后累加,累加后CAS提交,以及累加后FAA(Fetch And Add)提交三种方法对全局累加结果做临界区保护。针对不同的并发数量,以及不同的临界区负载,可以形成如下的三维曲线图。
其中Latency项除以临界区规模进行了归一,便于形象展示临界区负载变化下的临界区保护开销趋势,因此跨不同负载等级下不具备横向可比性。Cycles项表示多线程协同完成总量为同样次数的累加,用到的CPU周期总和,总体随临界区负载变化有少量天然倾斜。100/1600两个截面图将3中算法叠加在一起展示,便于直观对比。
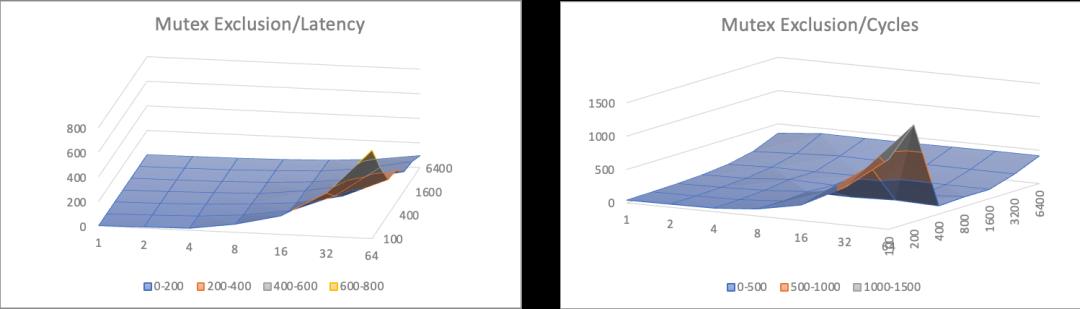
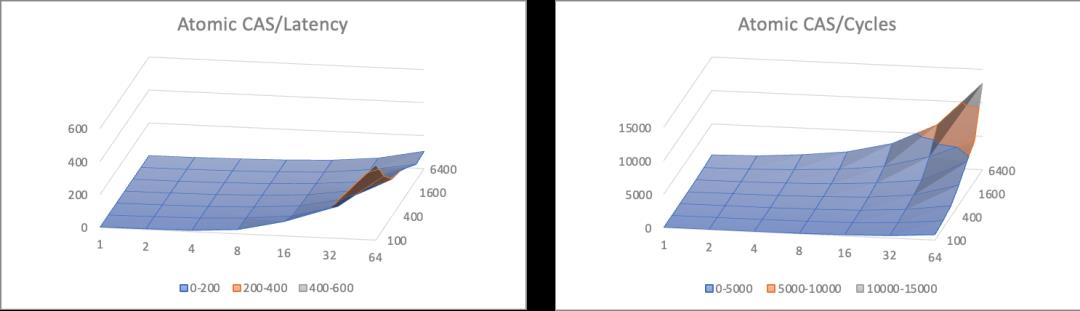
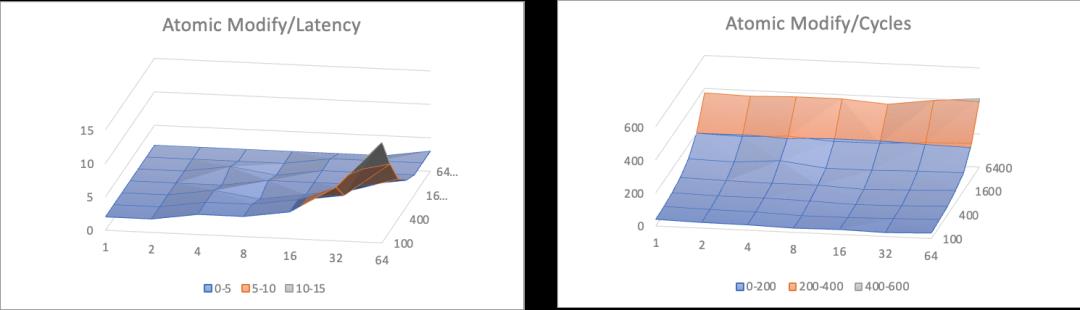
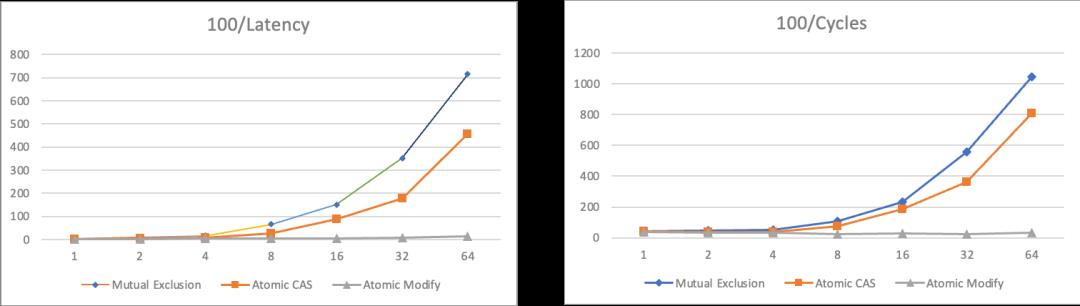
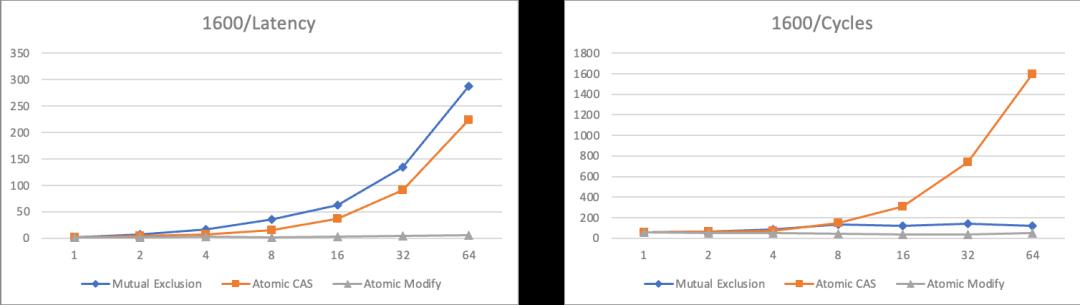
从上面的数据中可以分析出这样一些信息
1、基于FAA的Wait Free模式各方面都显著胜过其他方法;
2、无锁算法相比互斥算法在平均吞吐上有一定优势,但是并没有达到数量级水平;
3、无锁算法随竞争提升(临界区大小增大,或者线程增多),cpu消耗显著上升;
基于这些信息来分析,会发现一个和之前提到的『锁性能』的常规认知相悖的点。性能的分水岭并没有出现在基于锁的互斥算法和无锁算法中间, 而是出现在同为『未使用锁』的Lock Free和Wait Free算法中间。而且从CPU消耗角度来看,对临界区比较复杂,竞争强度高的场景,甚至Lock Free因为『无效预测执行』过多反而引起了过多的消耗。这表明了锁操作本身的开销虽然稍重于原子操作,但其实也并非洪水猛兽,而真正影响性能的,是临界区被迫串行执行所带来的并行能力折损。
因此当我们遇到临界区保护的问题时,可以先思考一下,是否可以采用Wait Free的方法来完成保护动作,如果可以的话,在性能上能够接近完全消除了临界区的效果。而在多数情况下,往往还是要采用互斥或Lock Free来进行临界区的保护。此时临界区的串行不可避免,所以充分缩减临界区的占比是共性的第一要务,而是否进一步采用Lock Free技术来减少临界区保护开销,讨论的前提也是临界区已经显著很短,不会引起过多的无效预 测。除此以外,由于Lock Free算法一般对临界区需要设计成两阶段提交,以便支持回滚撤销,因此往往需要比对应的互斥保护算法更复杂,局部性也可能更差(例如某些场景必须引入链表来替换数组)。综合来看,一般如果无法做到Wait Free,那么无需对Lock Free过度执着,充分优化临界区的互斥方法往往也足以提供和Lock Free相当的性能表现了。
4.3 并发计数器优化案例
从上文针对临界区保护的多种方法所做的实验,还可以发现一个现象。随着临界区逐渐减小,保护措施开销随线程数量增加而提升的趋势都预发显著,即便是设计上效率和参与线程数本应无关的Wait Free级别也是一样。这对于临界区极小的并发计数器场景,依旧会是一个显著的问题。那么我们就先从锁和原子操作的实现角度,看看这些损耗是如何导致的。
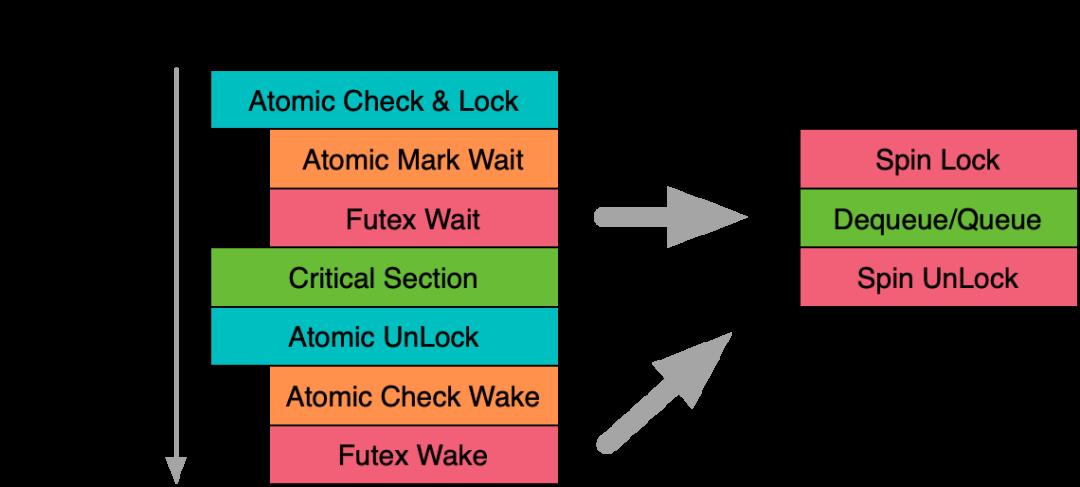
首先给出一个典型的锁实现,左侧是锁的fast path,也就是如果在外层的原子变量操作中未发现竞争,那么其实上锁和解锁其实就只经历了一组原子变量操作。当fast path检测到可能出现冲突时,才会进入内核,尝试进行排队等待。fast path的存在大幅优化了低冲突场景下的锁表现,而且现代操作系统内核为了优化锁的内存开销,都提供了『Wait On Address』的功能,也就是为了支持这套排队机制,每个锁常态只需要一个整数的存储开销即可,只有在尝试等待时,才会创建和占用额外的辅助结构。
因此实际设计中,锁可以创建很多,甚至非常多,只要能够达到足够细粒度拆解冲突的效果。这其中最典型的就是brpc中计数器框架bvar的设计。
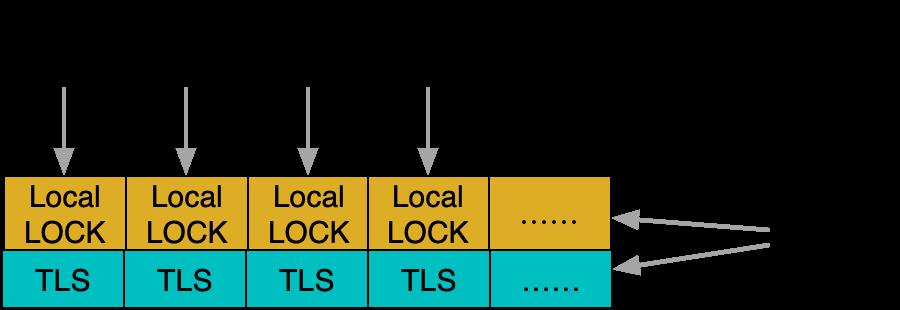
这是bvar中基础统计框架的设计,局部计数和全局汇聚时都通过每个tls附加的锁来进行临界区保护。因为采集周期很长,冲突可以忽略不记,因此虽然默认使用了大量的锁(统计量 * 线程数),但是并没有很大的内存消耗,而且运行开销其实很低,能够用来支持任意的汇聚操作。这个例子也能进一步体现,锁本身的消耗其实并不显著,竞争带来的软件或硬件上的串行化才是开销的核心。
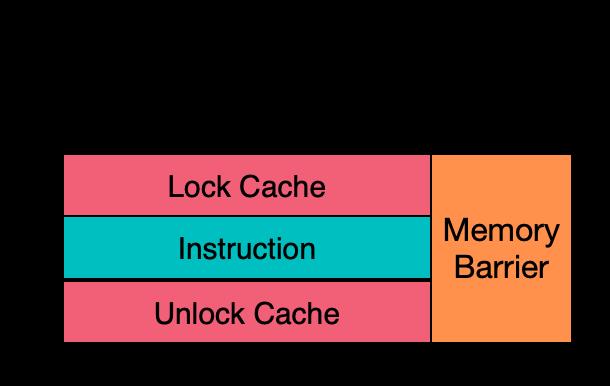
不过即使竞争很低,锁也还是会由一组原子操作实现,而当我们自己查看原子操作时,实际是由cache锁操作保护的原子指令构成,而且这个指令会在乱序执行中起到内存屏障的效果降低访存重叠的可能性。因此针对非常常用的简单计数器,在百度内部我们进行了进一步去除局部锁的改造,来试图进一步降低统计开销。
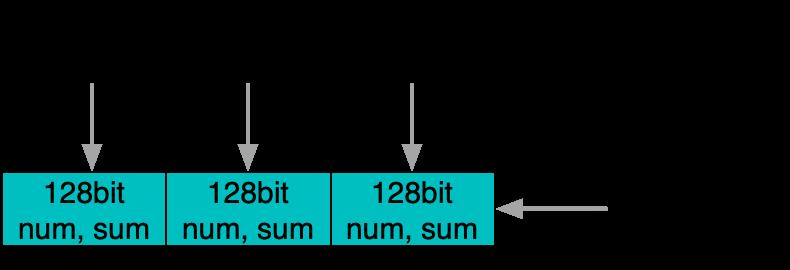
例如对于需要同时记录次数和总和的IntRecorder,因为需要两个64位加法,曾经只能依赖锁来保证原子更新。但随着新x86机型的不断普及,在比较新的X86和ARM服务端机型上已经可以做到128bit的原子load/store,因此可以利用相应的高位宽指令和正确对齐来实现锁的去除。
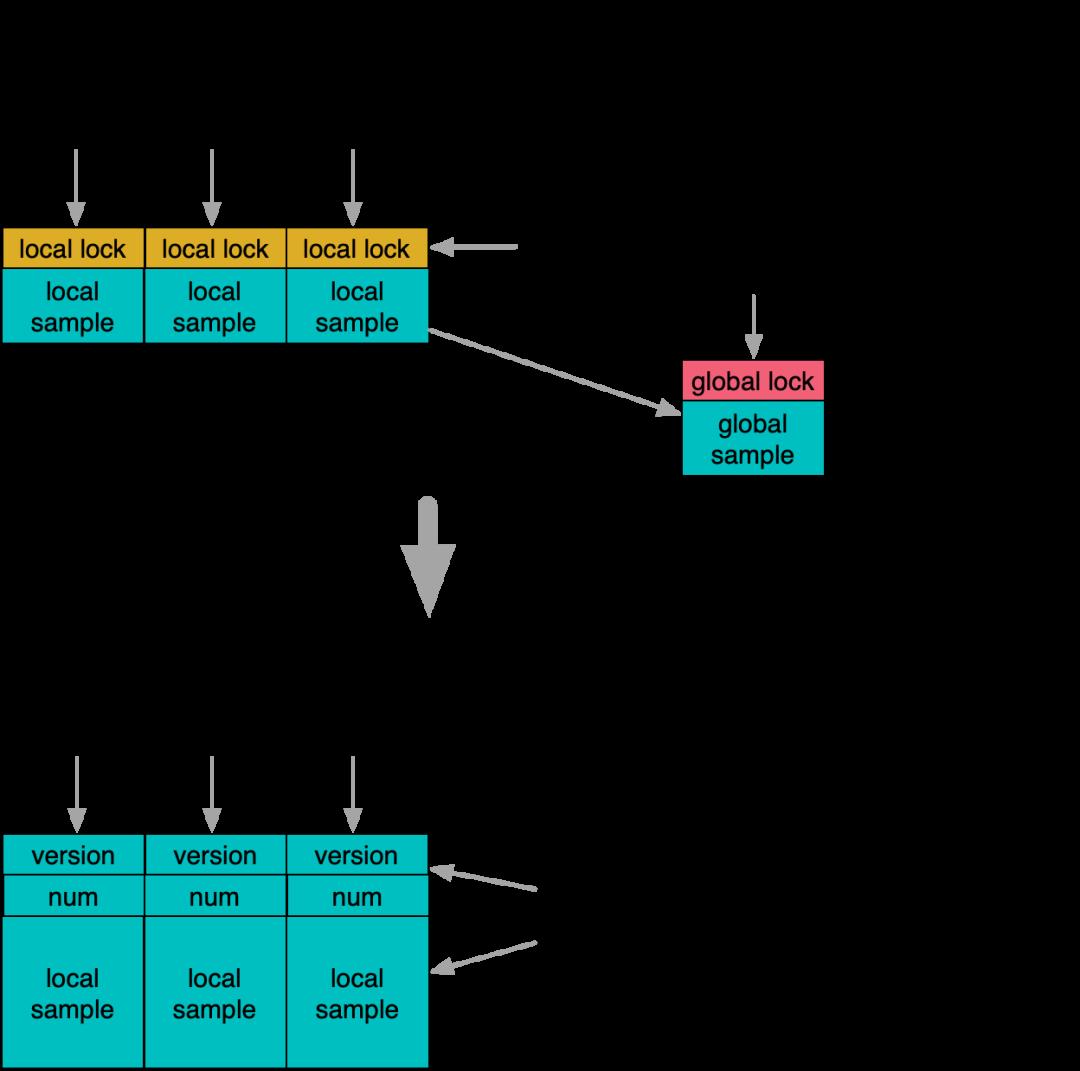
另一个例子是Percentile分位值统计,由于抽样数据是一个多元素容器,而且分位值统计需要周期清空重算,因此常规也是采用了互斥保护的方法。不过如果引入版本号机制,将清空操作转交给计数线程自己完成,将sample区域的读写完全分离。在这个基础上,就可以比较简单的做到线程安全,而且也不用引入原子修改。严格意义上,异步清空存在边界样本收集丢失的可能性,不过因为核心的蓄水池抽样算发本身也具有随机性,在监控指标统计领域已经拥有足够精度。
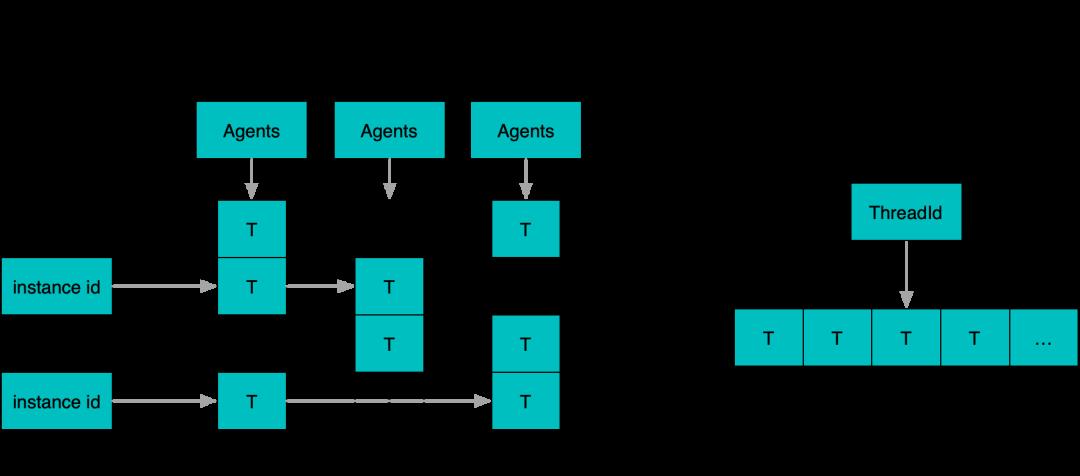
除了运行时操作,线程局部变量的组织方式原先采用锁保护的链表进行管理,采用分段数据结合线程编号的方法替换后,做到空间连续化。最终整体进一步改善了计数器的性能。
local count | get value | |
bvar::IntRecorder | 16 | 7 |
babylon::IntRecorder | 1377 | 14 |
bvar::Percentile | 938 | 28 |
babylon::Percentile | 66 | 14 |
4.4 并发队列优化案例
另一个在多线程编程中经常出现的数据结构就是队列,为了保证可以安全地处理并发的入队和出队操作,最基础的算法是整个队列用锁来保护起来。
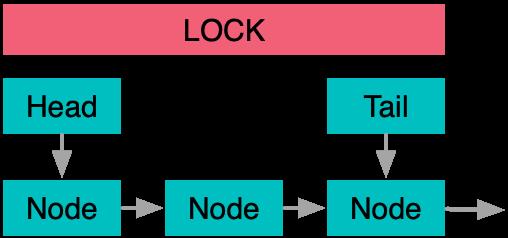
这个方法的缺点是显而易见的,因为队列往往作为多线程驱动的数据中枢位置,大量的竞争下,队列操作被串行很容易影响整体计算的并行度。因此一个自然的改进点是,将队列头尾分开保护,先将生产者和消费者解耦开,只追加必要的同步操作来保证不会过度入队和出队。这也是Jave中LinkedBlockingQueue所使用的做法。
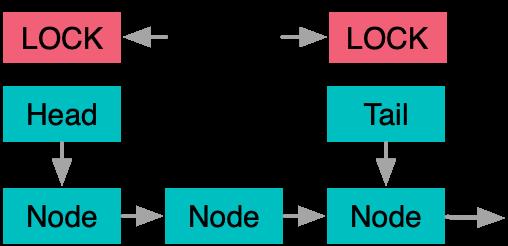
在头尾分离之后,进一步的优化进入了两个方向。首先是因为单节点的操作具备了Lock Free化的可能,因此产生了对应的Michael & Scott无锁队列算法。业界的典型实现有Java的ConcurrentLinkedQueue,以及boost中的boost::lockfree::queue。
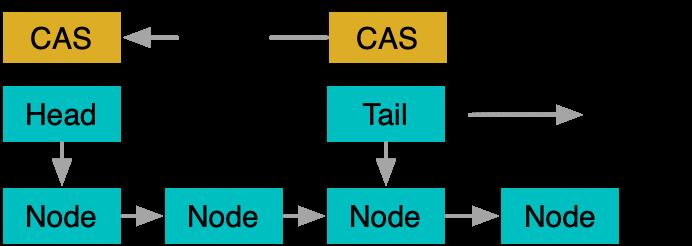
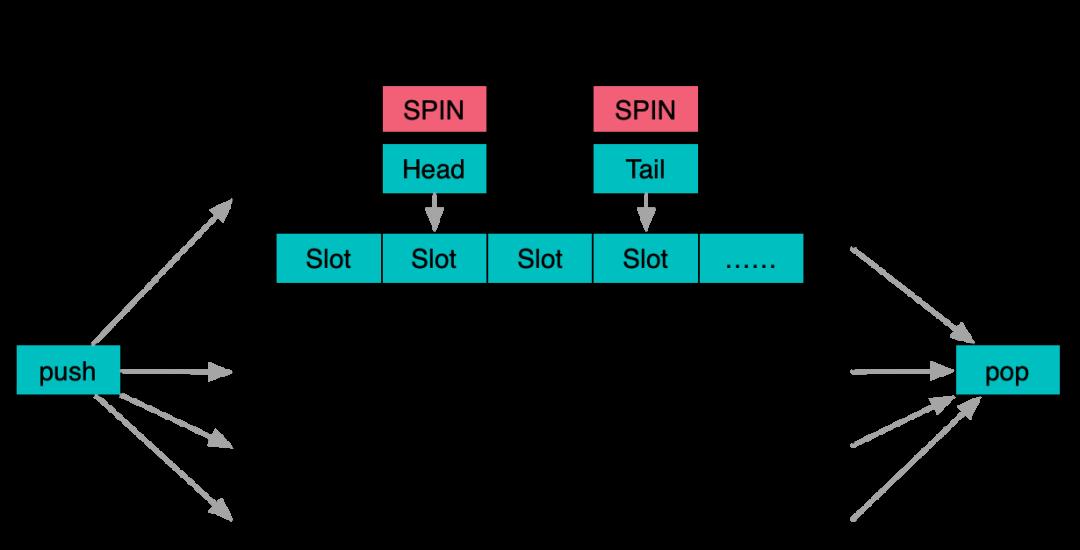
而另一个方向是队列分片,即将队列拆解成多个子队列,通过领取token的方式选择子队列,而子队列内部使用传统队列算法,例如tbb:: concurrent_queue就是分片队列的典型实现。
latency | |
boost::lockfree::queue | 35075 |
tbb::concurrent_queue | 4614 |
对两种方式进行对比,可以发现,在强竞争下,分片队列的效果其实显著胜过单纯的无锁处理,这也是前文对于无锁技术真实效果分析的一个体现。
除了这类通用队列,还有一个强化竞争发布,串行消费的队列也就是bthread::ExecutionQueue,它在是brpc中主要用于解决多线程竞争fd写入的问题。利用一些有趣的技巧,对多线程生产侧做到了Wait Free级别。
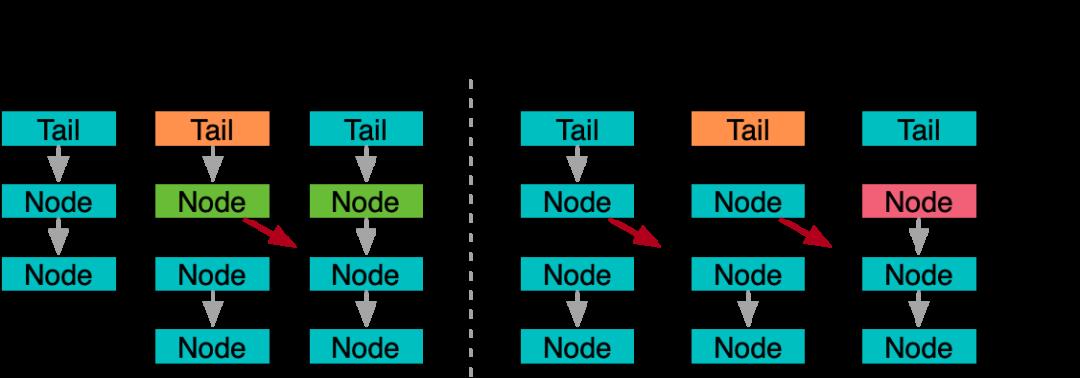
整个队列只持有队尾,而无队头。在生产侧,第一步直接将新节点和当前尾指针进行原子交换,之后再将之前的队尾衔接到新节点之后。因为无论是否存在竞争,入队操作都能通过固定的两步完成,因此入队算法是Wait Free的。不过这给消费侧带来的麻烦,消费同样从一个原子交换开始,将队尾置换成nullptr,之后的消费动作就是遍历取到的单链表。但是因为生产操作分了两部完成,此时可能发现部分节点尚处于『断链』状态,由于消费者无从知晓后续节点信息,只能轮询等待生产者最终完成第二步。所以理论上,生产/消费算法其实甚至不是Lock Free的,因为如果生产者在两阶段中间被换出,那么消费者会被这个阻塞传播影响,整个消费也只能先阻塞住。但是在排队写入fd的场景下,专项优化生产并发是合理,也因此可以获得更好的执行效率。
latency | |
tbb::concurrent_queue | 4614 |
bthread::ExecutionQueue | 2390 |
不过为了能利用原子操作完成算法,bthread::ExecutionQueue引入了链表作为数据组织方式,而链表天然存在访存跳跃的问题。那么是否可以用数组来同样实现Wait Free的生产甚至消费并发呢?
这就是babylon::ConcurrentBoundedQueue所希望解决的问题了。
不过介绍这个队列并发原理之前,先插入一个勘误信息。其实这个队列在《内存篇》最后也简单提到过,不过当时粗略的评测显示了acquire- release等级下,即使不做cache line隔离性能也可以保障。文章发表后收到业界同好反馈,讨论发现当时的测试用例命中了Intel Write Combining 优化技术,即当仅存在唯一一个处于等待加载的缓存行时,只写动作可以无阻塞提前完成,等缓存行真实加载完毕后,再统一提交生效。但是由于内存序问题,一旦触发了第二个待加载的缓存行后,对于第一个缓存行的Write Combine就无法继续生效,只能等待第二个缓存行的写完成后,才能继续提交。原理上,Write Combine技术确实缓解了只写场景下的False Sharing,但是只能等待一个缓存行的限制在真实场景下想要针对性利用起来限制相当大。例如在队列这个典型场景下,往往会同时两路操作数据和完成标记,很可能同时处于穿透加载中,此时是无法应用Write Combine技术的。此外,能够在缓存行加载周期内,有如此充分的同行写入,可能也只有并无真实意义的评测程序才能做到。所以从结论上讲,通常意义上的多线程cache line隔离还是很有必要的。
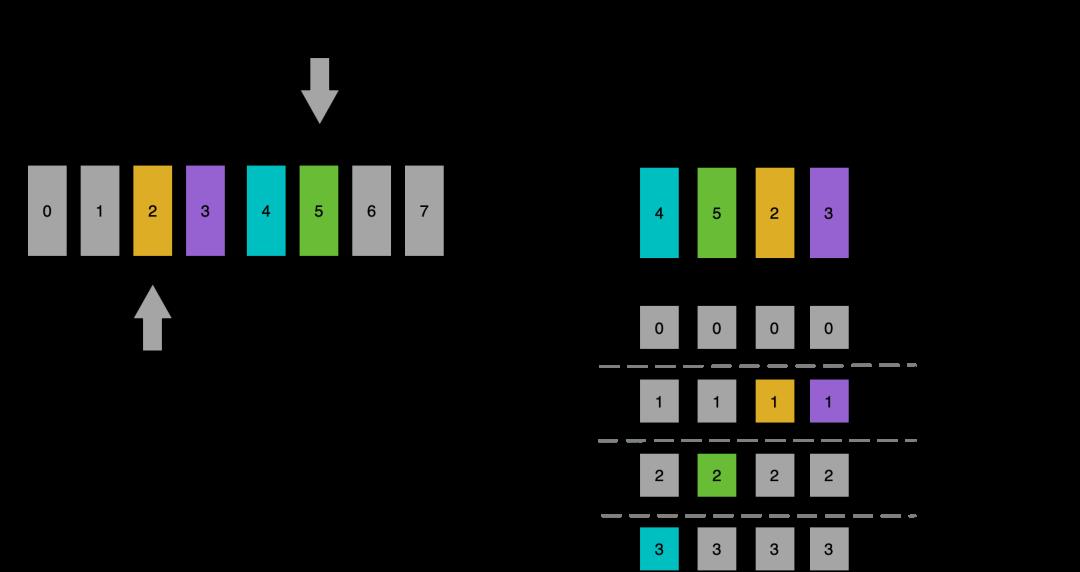
回到babylon::ConcurrentBoundedQueue的设计思路上,其实是将子队列拆分做到极致,将同步量粒度降低到每个数据槽位上。每个入队和出队 请求,首先利用原子自增领取一个递增的序号,之后利用循环数组的存储方式,就可以映射到一个具体的数据槽位上。根据操作是入队还是出队, 在循环数组上发生了多少次折叠,就可以在一个数据槽位上形成一个连续的版本序列。例如1号入队和5号出队都对应了1号数据槽位,而1号入队预期的版本转移是0到1,而5号出队的版本转移是2到3。这样针对同一个槽位的入队和出队也可以形成一个连续的版本变更序列,一个领到序号的具体操作,只需要明确检测版本即可确认自己当前是否可以开始操作,并通过自己的版本变更和后续的操作进行同步。
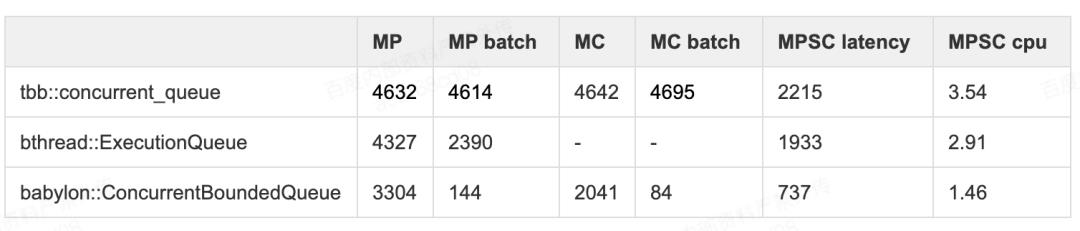
通过同步量下放到每个元素的方式,入队和出队操作在可以除了最开始的序号领取存在原子操作级别的同步,后续都可以无干扰并行开展。而更连续的数据组织,也解决了链表存储的访存跳跃问题。生产消费双端可并发的特点,也提供了更强的泛用性,实际在MPMC(Multiple Producer Mult iple Consumer)和MPSC(Multiple Producer Single Consumer)场景下都有不错的性能表现,在具备一定小批量处理的场景下尤其显著。
---------- END ----------

一键三连,好运连连,bug不见????
以上是关于百度C++工程师的那些极限优化(并发篇)的主要内容,如果未能解决你的问题,请参考以下文章