案例分享 | TensorFlow 助力 OpenX 实现每秒处理百万查询
Posted TensorFlow 社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了案例分享 | TensorFlow 助力 OpenX 实现每秒处理百万查询相关的知识,希望对你有一定的参考价值。

客座博文 / Larry Price,来自 OpenX 团队
编辑 / Robert Crowe、Anusha Ramesh,TensorFlow 团队
概述
Adtech(广告技术)是一个基于大规模延迟的行业。在 OpenX,这意味着我们的交易平台在流量高峰期每秒处理超过一百万个广告请求,其中的大部分请求需要在 300 毫秒内响应。在如此高的流量和严格的时间预算下,我们必须确定流量优先级,从而确保既能帮助发布商获得最高的广告库存价格,又能确保买家实现其广告系列的目标。

为此,我们利用 TensorFlow 生态系统和 Google Cloud 中的多种产品(包括 TensorFlow Extended (TFX)、TF Serving 和 Kubeflow Pipelines)构建了一项服务,该服务会优先考虑我们买家的流量(广告技术术语为需求方平台或 DSP),更具体地说是这些 DSP 内品牌和代理商的流量。
OpenX 简介
OpenX (https://www.openx.com/) 经营着全球最大的独立广告交易平台。从基本层面来看,这个交易平台是一个通过访问量最大的网站和移动应用将成千上万的顶级品牌与消费者连接起来的市场。
交易的基本方式是拍卖,拍卖中代表品牌的买家对发布商库存(即网站和移动应用上的广告展示次数)进行出价。拍卖本身非常简单,但有两个因素让这个系统变得异常复杂:
-
规模:在流量高峰期,我们的系统每秒处理超过一百万个广告请求。通常情况下,每天会有超过 1.5 万亿次出价交易,从而产生 PB 级的原始数据。
-
延迟时间:保持用户的网络和移动应用体验对发布商至关重要,因此我们处理大多数请求的时间都严格限制在 300 毫秒或更短时间内,其中的大部分时间用于询问和接收买方的出价。这意味着在拍卖时由机器学习模型引入的任何开销都必须限制在最多 15 毫秒左右,否则我们就可能无法给买家提供足够的时间提交报价。
对机器学习系统而言,这种对低延迟和高吞吐量的需求为非典型情况。在详细介绍如何构建能够满足这两个需求的机器学习基础架构之前,我们将更深入地探讨我们确定这一目标的过程以及要解决的问题。
云转型:难得的机遇
2019 年,OpenX 承担了将本地计算资源转移到 Google Cloud Platform (GCP) 的艰巨任务。我们用七个月的时间完成了这一过程。作为一家公司,我们有权在转换期间使用托管服务以及修改我们的堆栈,因此这不只是一个简单的“直接迁移”。我们的数据科学团队对这一点深有感触。
-
将本地计算资源转移到 Google Cloud Platform
https://cloud.google.com/customers/openx -
我们用七个月的时间完成了这一过程
https://www.openx.com/company/press-releases/openx-completes-technology-migration-onto-google-cloud-platform
迁移到 GCP 之前,我们的旧版机器学习基础架构遵循的模式是,经过科学家训练的模型必须由工程师在执行模型所需的组件中重新实现。此方案满足了规模和延迟时间要求,但也带来了许多其他问题:
-
将模型投入生产需要很长时间,因为工程师现在必须使用调用该模型的组件的本地语言,来重现科学家的工作(通常使用 Python)。
-
更改模型架构甚至执行数据转换的方式也是如此。
-
本质上会导致训练应用偏差。
-
质量检查 (QA) 具有挑战性。
由于这些原因以及一些其他原因,我们决定从头开始。与此同时,我们正在研究一个新问题,并决定将这两项工作结合起来,将开发新框架纳入到新项目中。
我们的问题
OpenX 市场并非与股票市场或证券交易所完全不同。这个市场很像交易量大的金融市场。要确保购买者实现其广告活动目标,同时帮助发布商通过广告库存适当盈利,就需要对流量进行优先排序。从根本上讲,这意味着我们需要一个能够准确评估价值的模型,从而对每个命中交易平台的请求进行排名。
为什么选择 TensorFlow
在为下一代平台寻找解决方案时,我们制定了几个目标。我们的主要目的是大幅减少将模型投入生产的时间和精力。为了实现此目标,我们尽可能尝试使用托管服务。
在我们迁移到 GCP 之前,OpenX 已经使用了一段时间的 TensorFlow,但我们的旧版基础架构涉及许多用于数据转换和流水线的自定义脚本。在我们研究备选项的同时,TensorFlow Extended (TFX) 和 Kubeflow Pipelines (KFP) 都达到了对实现我们的目标来说十分有利的成熟阶段。在我们的堆栈中采用这些技术非常容易。
我们如何解决这个问题
每天训练 TB 级的数据
我们的流水线如下所示:![]()
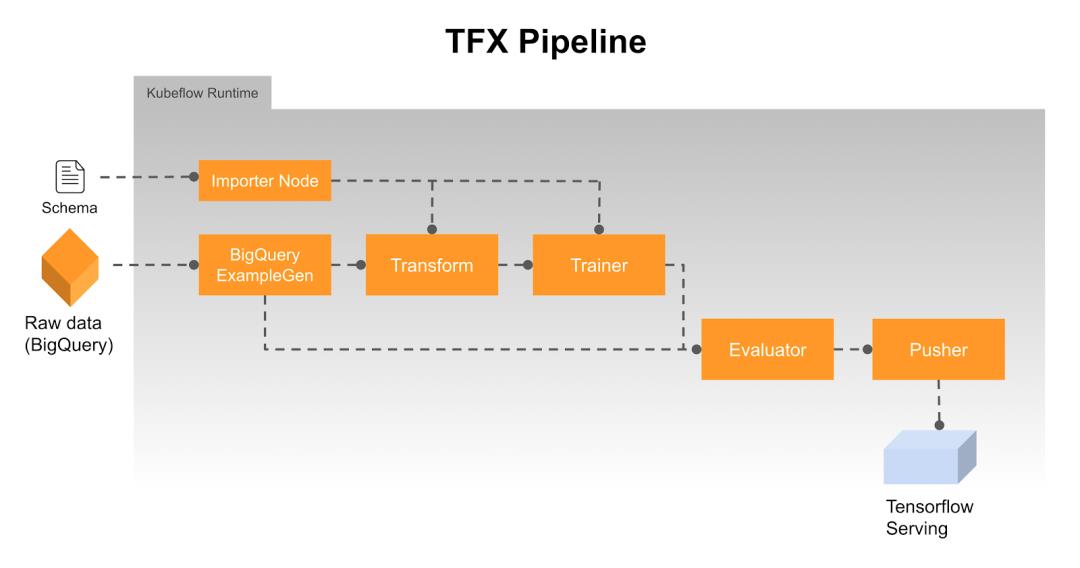
花点时间来拆分流水线的拓扑结构非常有用:
-
原始数据 - 我们的数据由事务日志组成,这些事务日志在到达时直接从 StackDriver 流式传输到 BigQuery 接收器。为了避免我们的模型出现偏差,我们对优先级系统提供的全部数据中的一小部分进行训练,每天生成约 50TB 的新数据。这是一种简单的设计选择,因为实现起来非常简单,其最大的优势在于我们可以直接使用 BigQuery 处理数据,而无需执行其他 ETL 流程。
-
BigQueryExampleGen - 我们首先用到 BigQuery 的地方是使用内置函数预处理数据。通过将我们自己的特定流程嵌入到 ExampleGen 组件执行的查询调用中,我们能够避免构建一个不在 TFX 流水线范围内的单独 ETL。最终结果证实,这是将模型更快投入生产的好方法。这些预处理后的数据随后会通过 ExampleGen 组件拆分为训练集和测试集,并转换为 tf.Examples。
-
Transform - 此组件执行对于处理字符串、标准化值、设置嵌入向量等操作必需的特征工程和转换。其主要好处在于,最终的转换最后会附加到计算图的前面,以便使用完全相同的代码进行训练和处理。
-
Trainer - Trainer 组件的作用正如其名。我们利用 AI 平台上的并行训练来加快处理速度。
-
Evaluator - Evaluator 将现有的生产模型与 Trainer 收到的模型进行比较,从而推荐“更出色”的模型来用于生产。决策标准基于与业务需求相符的自定义指标(而不是精度和召回率等因素)。由于 Evaluator 组件具有可扩展性,因此很容易实现符合业务需求的自定义指标。
-
Pusher - Pusher 的主要功能是将推荐的模型发送到我们部署的 TFServing 以用于生产。但是,我们添加了一些功能,可以使用在 Evaluator 中生成的自定义指标来确定要在处理时使用的决策标准,并将其附加到计算图上。TFX 组件提供多个抽象级别,因此可轻松执行这种自定义修改。总之,通过修改,TFX 流水线可以在没有人工参与的情况下运行,从而使我们能够频繁更新模型,同时在对我们的业务至关重要的指标上继续提供稳定的性能。
总的来说,开箱即用的 TFX 组件提供了我们所需的大多数功能。我们必须解决的最大挑战是我们的市场在不断变化,因此需要频繁更新模型。如前所述,TFX 的设计可以让实现这些增强功能变得简单。
但这实际上只能解决我们模型训练部分的问题。每秒处理多达一百万个查询,并在 15 毫秒以内响应每个查询,这是一项巨大的挑战。为此,我们转而采用了 TensorFlow Serving。
每秒处理超过一百万个查询 (QPS)
借助 TensorFlow Serving,我们能够快速采用 TensorFlow 模型,并以高性能和可扩展的方式在生产中提供这些模型。
使用 TensorFlow Serving 为我们带来了许多好处。首先,该产品本身就支持将 Google Cloud Storage 作为模型仓库,因此我们只需将用于处理请求的模型上传到 GCS 存储分区,即可自动更新这些模型。这样,我们就能用最新的数据快速更新我们的模型,然后立即投入生产。其次,TensorFlow Serving 支持批处理模式。这种模式可将多个请求排入队列,并在运行的单个图中同时处理这些请求,大大提高了吞吐量。这是一项必不可少的功能,只需设置一个选项,就可以在很大程度上帮助我们实现吞吐量目标。最后,TensorFlow Serving 公开了现有的指标,让我们能够监控请求的吞吐量和延迟时间,并观察任何扩展瓶颈和效率低下问题。
TensorFlow Serving 中所有这些开箱即用的功能对我们来说是巨大的优势,并帮助我们实现了目标,但将其扩展到每秒处理数百万个请求并非没有挑战。通过使用带有多个 CPU 的大型虚拟机,我们可以达到 15 毫秒的预测目标,但这无法以经济高效的方式实现扩展,在这方面我们还有进步的空间。
幸运的是 TensorFlow Serving 有一些调整旋钮和参数,我们用这些旋钮和参数调整了生产虚拟机,提高了效率和可扩展性。通过设置批处理线程数、操作间和操作内并行性以及批处理超时等参数,我们能够在自定义大小的虚拟机上高效地自动扩展,同时仍保持我们的吞吐量和延迟时间目标。
最终结果是,在 Google Kubernetes Engine 上部署运行的 TensorFlow Serving 每秒可处理 250 万个预测请求,每个请求的响应时间不到 15 毫秒。该部署跨越分布在 10 个不同 GCP 区域的 25 个 Kubernetes 集群中,能够无缝扩展和缩减以响应流量高峰,并在流量较低的时期缩减规模来节省成本。高峰期全球大概有 500 个 TensorFlow Serving 实例同时运行,每个 8 CPU 的部署每秒能够处理 5000 个请求。
立足成功
在使用 TensorFlow Serving 后的几个月里,我们对模型做出了数十处改进(包括更改原始模型的架构、某些功能的处理方式等),且未向其他任何工程团队寻求支持。在我们的旧版架构中,以这种速度进行更改几乎是不可能的。此外,相较于过去,其中的每一项改进都能更快地为我们的客户(我们市场中的买卖双方)带来新价值。
自我们最初使用该参考架构以来,我们就将其用作了新项目和现有模型迁移的模板。我们已转移到新项目中的现有 TFX 组件的数量惊人,我们也同样大幅缩短了将模型投入生产的时间。正因如此,数据科学家才能将更多时间用于优化所生成模型的参数和架构、了解其对业务的影响,最终为我们的客户提供更多价值。
致谢
感谢 Michal Brys、Andy Gooden、Junbo Park 和 Paul Selden 的辛勤工作,以及 OpenX 数据科学和工程团队的其他成员和 Paul Ryan 的支持,如果没有他们的付出,这一切都不可能实现。我们还要感谢战略云工程师 Will Beebe、Leonid Kuligin 以及 GCP 客户管理团队的 Dillon Do、Iman Kafarah 和 Kyle Winn 的大力支持。非常感谢 TensorFlow(TFX、TF Serving)和 Kubeflow 团队,特别是 Robert Crowe 和 Anusha Ramesh,感谢他们帮助我们完成这个案例研究。
想了解更多 TFX 使用案例,欢迎访问 TensorFlow 中国官网:tensorflow.google.cn
或扫描下方二维码,关注 TensorFlow 官方微信公众号。
以上是关于案例分享 | TensorFlow 助力 OpenX 实现每秒处理百万查询的主要内容,如果未能解决你的问题,请参考以下文章