面试官:高并发场景下,你们是怎么保证数据的一致性的?
Posted 程序员小濠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:高并发场景下,你们是怎么保证数据的一致性的?相关的知识,希望对你有一定的参考价值。
面试的时候,总会遇到这么一个场景。
1. 场景分析
面试官:你们的服务的QPS是多少?
我:我们的服务高峰期访问量还挺大的,大约是3万吧。
面试官:这么大的访问量,你们的服务器能撑住吗?有加缓存吗?
我:有的,我们使用了Redis做缓存,接口优先查询缓存,缓存不存在,才访问数据库。这样可以减少数据库访问压力,加快查询效率。
面试官:一份数据存储在两个地方,更新数据的时候,你们是怎么保证数据的一致性的?
看到了吧,好的面试官一般不直接问你数据一致性的解决方案,而是循循善诱,结合具体的使用场景,再问你解决方法。如果你没做过这方面,没有线上的实战经验,一般很难回答的有条理性、有思考性。
保证数据一致性,一般有这4种方法:
- 先更新缓存,再更新数据库。
- 先更新数据库,再更新缓存。
- 先删除缓存,再更新数据库。
- 先更新数据库,再删除缓存。
每种方案都详细的讨论一下:
2. 解决方案
2.1 先更新缓存,再更新数据库
如果同时来了两个并发写请求,执行过程是这样的:
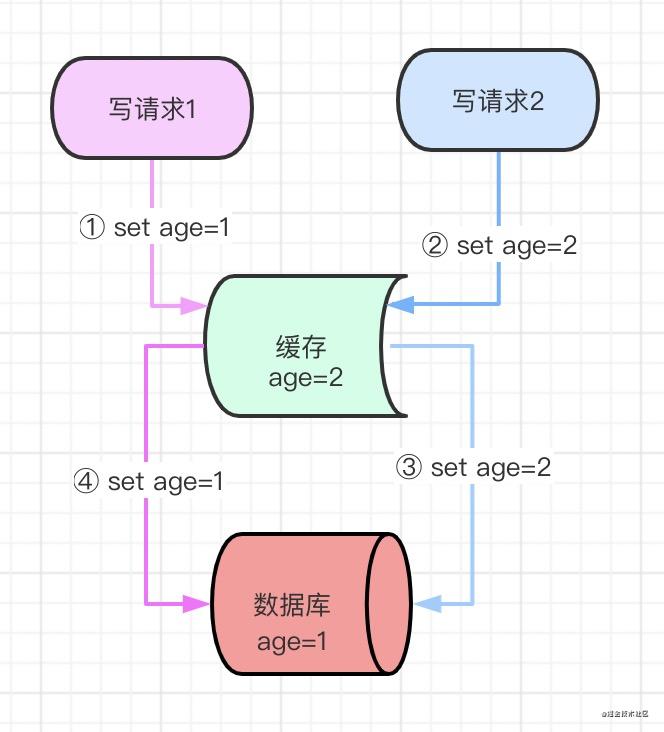
- 写请求1更新缓存,设置age为1
- 写请求2更新缓存,设置age为2
- 写请求2更新数据库,设置age为2
- 写请求1更新数据库,设置age为1
执行结果就是,缓存里age被设置2,数据库里的age被设置成1,导致数据不一致,此方案不可行。
2.2 先更新数据库,再更新缓存
如果同时来了两个并发写请求,执行过程是这样的:
- 写请求1更新数据库,设置age为1
- 写请求2更新数据库,设置age为2
- 写请求2更新缓存,设置age为2
- 写请求1更新缓存,设置age为1
执行结果就是,数据库里age被设置2,缓存里的age被设置成1,导致数据不一致,此方案不可行。
2.3 先删除缓存,再更新数据库
如果同时来了两个并发读写请求,执行过程是这样的:
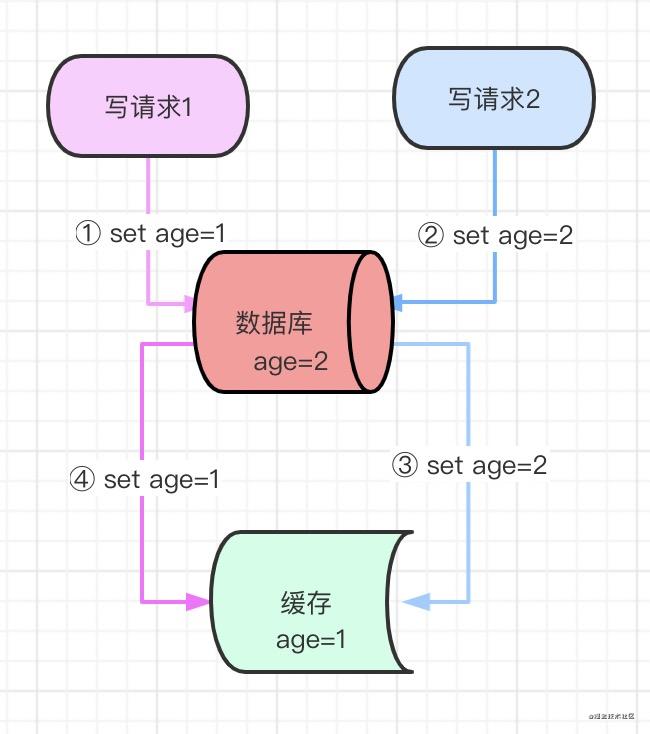
- 写请求删除了缓存
- 读请求查询缓存没数据,然后查询数据库,再把数据写到缓存中
- 写请求更新数据库
执行结果是,缓存中是旧数据,而数据库里是新数据,导致数据不一致,此方案不可行。
2.4 先更新数据库,再删除缓存
这种方案,在并发写的时候,不会出问题。因为都是先更新数据库再删除缓存,不会出现不一致的情况。
但是在并发读写的时候,还是有可能出现数据不一致。
- 读请求查询缓存没数据,然后查询数据库
- 写请求更新数据库,删除缓存
- 读请求回写缓存
执行结果是,缓存中是旧数据,而数据库里是新数据,导致数据不一致。
其实这种情况出现的概率很低,写缓存比写数据库快出几个量级,读写缓存都是内存操作,速度非常快。
遇到了这种极端场景,我们也需要做一下兜底方案,缓存都要设置过期时间。这种方案属于数据的弱一致性和最终一致性,而不是强一致性。
3. 总结与思考
有读者可能会好奇,为什么不在更新缓存和数据库方法上加上事务注解,实现强一致性,这么哪种方案都不会有问题。
是的,当我们的服务只在一台机器上,加本地事务是可行的。但是工作中,我们会把一个服务部署到几十台、上百台机器上,有时候为了应对更极端的查询请求,又在Redis缓存加一层本地缓存,这时候我们再用本地事务是不起作用的。
一份数据在多台机器上,存在多个副本,为了实现强一致性,我们也可以使用分布式事务。这样一来更新缓存操作将会变得非常复杂,得不偿失。
但是在另外的一些场景,比如更新订单状态、更新用户资产,这种场景,我们无论付出多大代价也要实现数据的强一致性,具体实现方案一般有以下几种:
- 二阶段提交
- TCC
- 本地消息表
- MQ事务消息
- 分布式事务中间件
最后:【可能给予你帮助】然后下面分享一些我的自学资料,希望可以帮到大家。
这份资料整体是围绕着【软件测试】来进行整理的,主体内容包含:python自动化测试专属视频、Python自动化详细资料、全套面试题等知识内容。对于软件测试的的朋友来说应该是最全面和完整的备战仓库了,这个仓库也陪伴我走过了很多坎坷的路,希望也能帮助到你
关注我的微信公众号:【 程序员小濠】免费获取~
送上一句话:
世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。
我的软件测试交流群:175317069,群里有测试大牛分享经验~
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!
以上是关于面试官:高并发场景下,你们是怎么保证数据的一致性的?的主要内容,如果未能解决你的问题,请参考以下文章