Datawhale7月组队学习task1数据加载及探索性数据分析
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Datawhale7月组队学习task1数据加载及探索性数据分析相关的知识,希望对你有一定的参考价值。
Datawhale7月task1数据加载及探索性数据分析
有幸了解到了Datawhale这样一个开源组织,欣然报名了2021年7月的组队学习的动手学数据分析系列课程
本系列目标:完成kaggle上泰坦尼克的任务,实战数据分析全流程
use machine learning to create a model that predicts which passengers survived the Titanic shipwreck
一.数据载入及初步观察
1.载入数据
①导入numpy和pandas
import numpy as np
import pandas as pd
②导入数据集
os 模块提供了非常丰富的方法用来处理文件和目录
os.getcwd() 方法可用于返回当前工作目录,可为路径的载入提供便捷的参考import os os.getcwd()
运行结果
查看当前路径还可用魔法方法
%pwd
关于魔法方法,后文
遇到的问题 3.那里有总结

(1)绝对路径载入
在文件右键属性那里复制过来的路径是
C:\\Users\\86171\\Desktop\\最近的都在这\\datawhale\\hands-on-data-analysis-master\\第一单元项目集合\\test_1.csv 然而直接用这个路径会报错
df = pd.read_csv('C:\\Users\\86171\\Desktop\\最近的都在这\\datawhale\\hands-on-data-analysis-master\\第一单元项目集合\\test_1.csv')
将
\\改为\\\\或/就🆗了,即:df =pd.read_csv('C:\\\\Users\\\\86171\\\\Desktop\\\\最近的都在这\\\\datawhale\\\\hands-on-data-analysis-master\\\\第一单元项目集合\\\\test_1.csv') #或 df =pd.read_csv('C:/Users/86171/Desktop/最近的都在这/datawhale/hands-on-data-analysis-master/第一单元项目集合/test_1.csv')

(2)相对路径载入
#相对路径
df = pd.read_csv('test_1.csv')
df是DataFrame的缩写,这里表示读取进来的数据
df.head()
df.head(3)
head()根据位置返回对象的前n行。如果你的对象中包含正确的数据类型, 则对于快速测试很有用。此方法用于返回数据帧或序列的前n行(默认值为5)
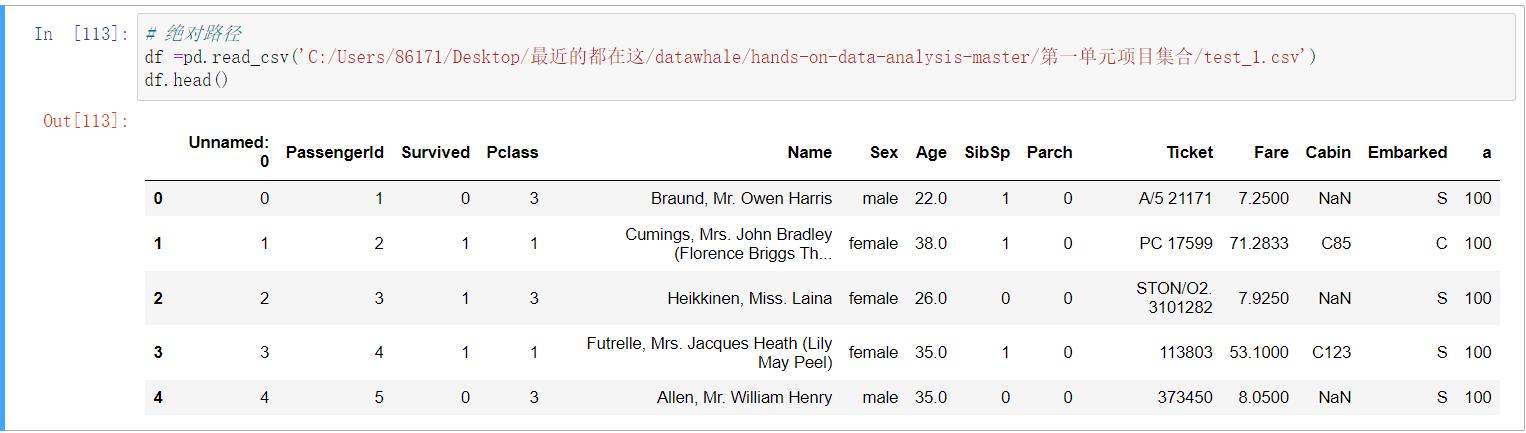

pd.read_csv()和pd.read_table()
pd.read_csv()的结果在上面
pd.read_table()结果如下:
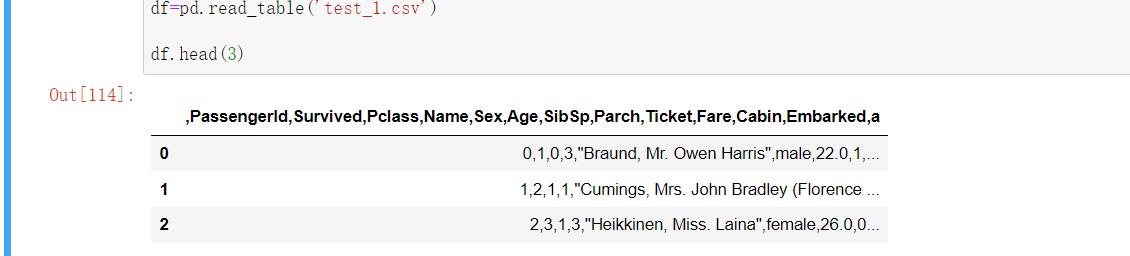
区别:

.tsv 与 .csv 唯一的不同之处在于,数据列之间的分隔符是制表符 (tab), 而不是逗号。 文件的扩展名通常是.tsv,但有时也用.csv 作为扩展名。从本质上来看,.tsv 文件与.csv 文件在 Python 中的作用是相同的
- TSV : Tab-separated values
- CSV : Comma-separated values
怎样使他们一样呢?指定分隔符,修改sep参数
对于pd.read_csv(),将sep参数改为'/t'
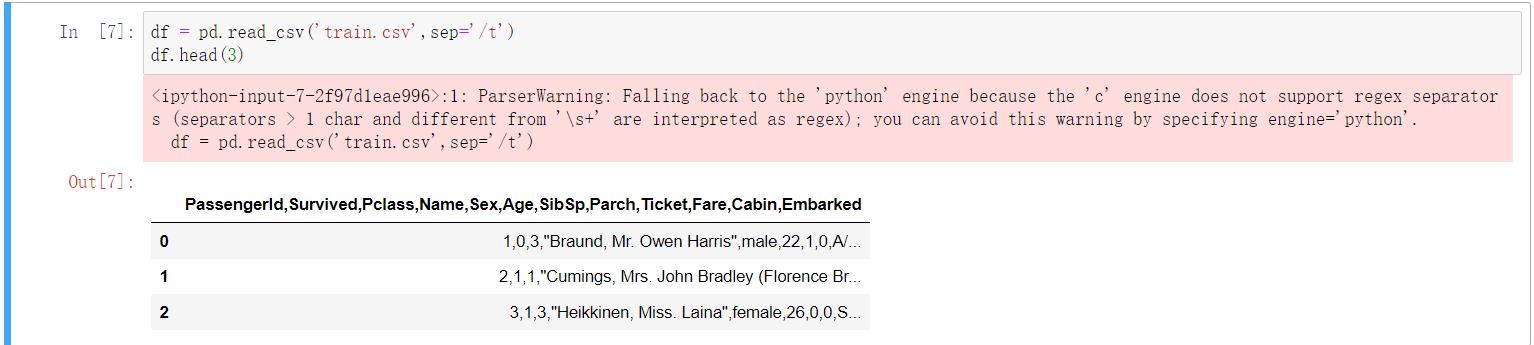
针对上面的报错提示,加上参数engine='python',即可

对于pd.read_table(),将sep参数改为',',同时engine='python'

sep=可以省略不写
③每1000行为一个数据模块,逐块读取
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部 分或逐块对文件进行迭代
所以逐块读取方便读取其中的一部分数据或对文件进行逐块处理,还可以减少资源消耗,提高效率
先来读取一下整个文件,
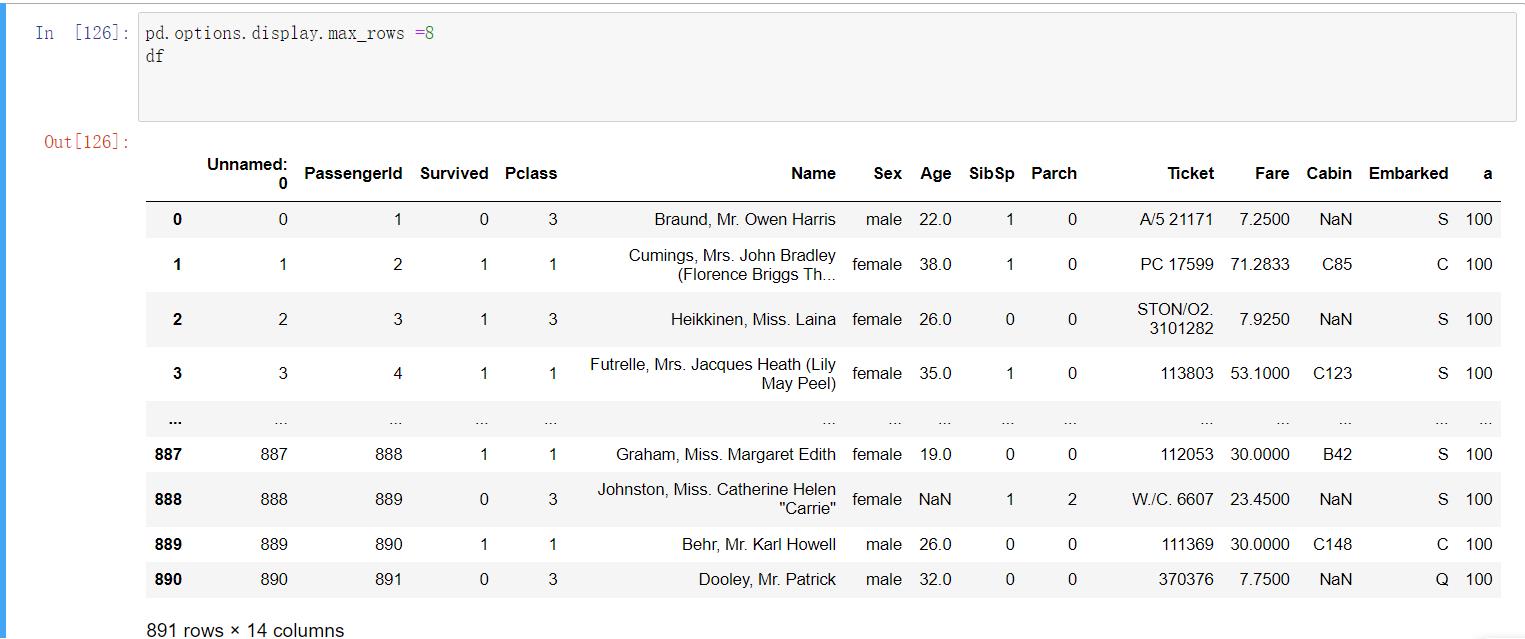
pd.options.display.max_rows =8
#设置显示最大行数,看起来紧凑一些
df
若只想读取几行,可通过nrows参数调整
df = pd.read_csv('test_1.csv',nrows=5)
df
nrows是用于选择记录的前n个元素的参数
逐块读取
设置行数chunksize,先以100行为一个数据块

read_csv所返回的这个TextParser对象使你可以根据chunksize对文件进行逐块迭代
chunker = pd.read_csv('test_1.csv',chunksize=1000)
chunker
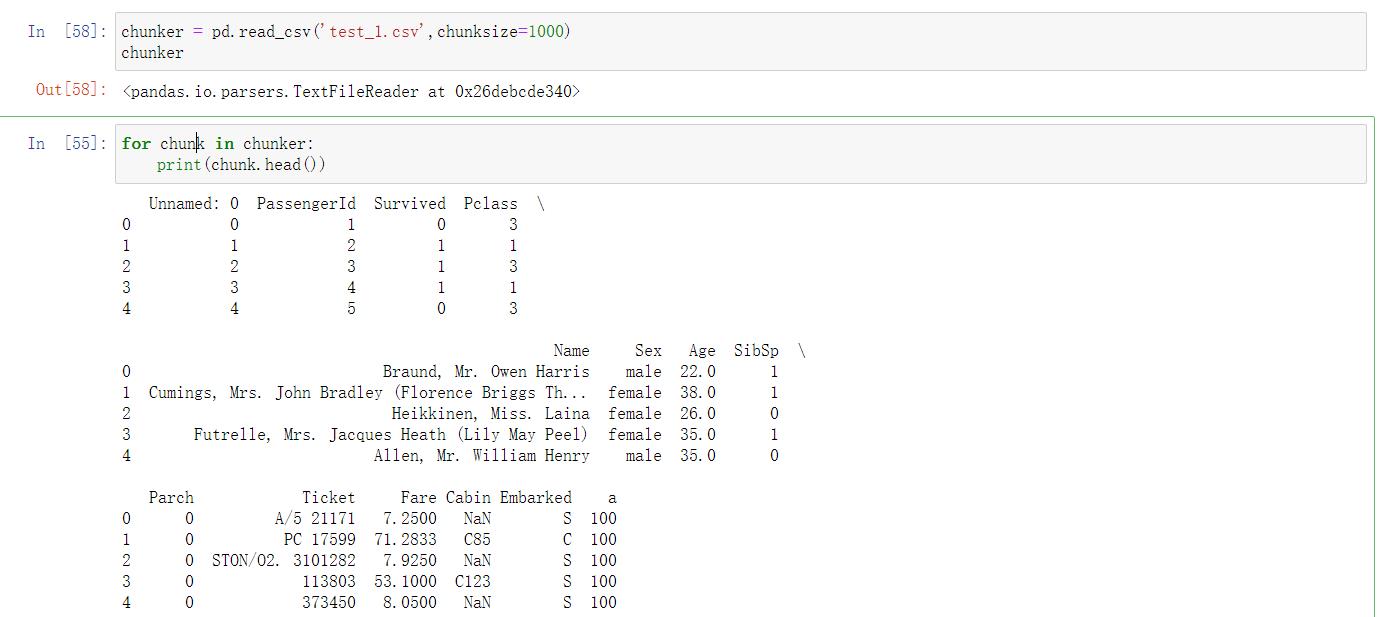
for chunk in chunker:
print(chunk.head())
运行结果:
#或
for chunk in chunker:
print(chunk)
运行结果:
④把表头改为中文,索引改为乘客ID
方法一
代码
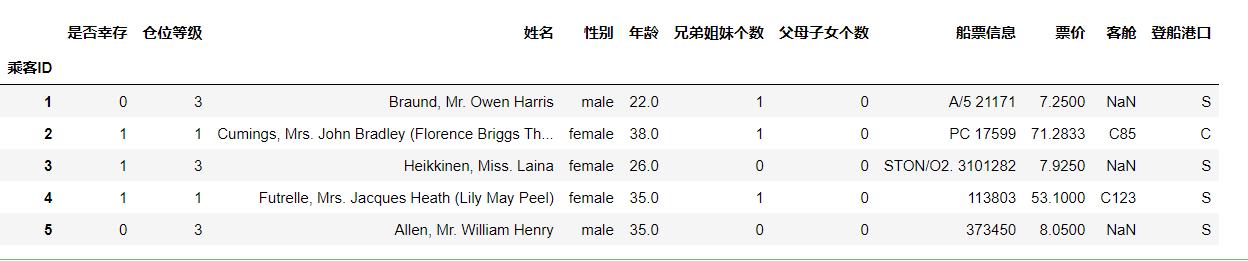
df = pd.read_csv("train.csv",names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
运行结果
注:上面用到的
names、index_col、header等参数

CSDN里面还有一个很好的☝️ 解释
方法二
设置列名
df=pd.read_csv("train.csv")
df.columns = ['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口']#必须一一对应
df = df.set_index('乘客ID') # 重新设 乘客ID 为索引,去掉默认会自动加上一列行号
df.head()
方法三
df.rename(columns={'PassengerId':'乘客ID','Survived':'是否幸存', 'Pclass':'仓位等级', 'Name':'姓名','Sex':'性别','Age':'年龄','SibSp': '堂兄弟/妹个数','Parch':'父母与小孩个数', 'Ticket':' 船票信息','Fare':'票价' ,'Cabin': '客舱','Embarked':'登船港口' }, inplace = True)#可以修改部分列名或者全部
df = df.set_index('乘客ID') # 重新设 乘客ID 为索引,去掉默认会自动加上一列行号
df.head()
方法二和方法三均学习自https://blog.csdn.net/miaochangq/article/details/108052553
2.初步观察
导入数据后,你可能要对数据的整体结构和样例进行概览,比如说,数据大小、有多少列,各列都是什么格式的,是否包含null等
①查看数据基本信息
方法一
df.info()

方法二
逐个打印Dataframe的基本属性
print(df.index) # 索引
print(df.shape) # 数据结构(几行几列)
print(df.size) #元素总个数
print(df.values) #元素值
print(df.ndim) #维度数
print(df.columns) # 列名
# 查看列类型
cols = df.columns
for col in cols:
print(col+' : '+ str(df[col].dtype))
运行结果

另:查看缺省值
print(df.apply(lambda x:np.sum(x.isnull())))
#或
df.isna().sum()
运行结果

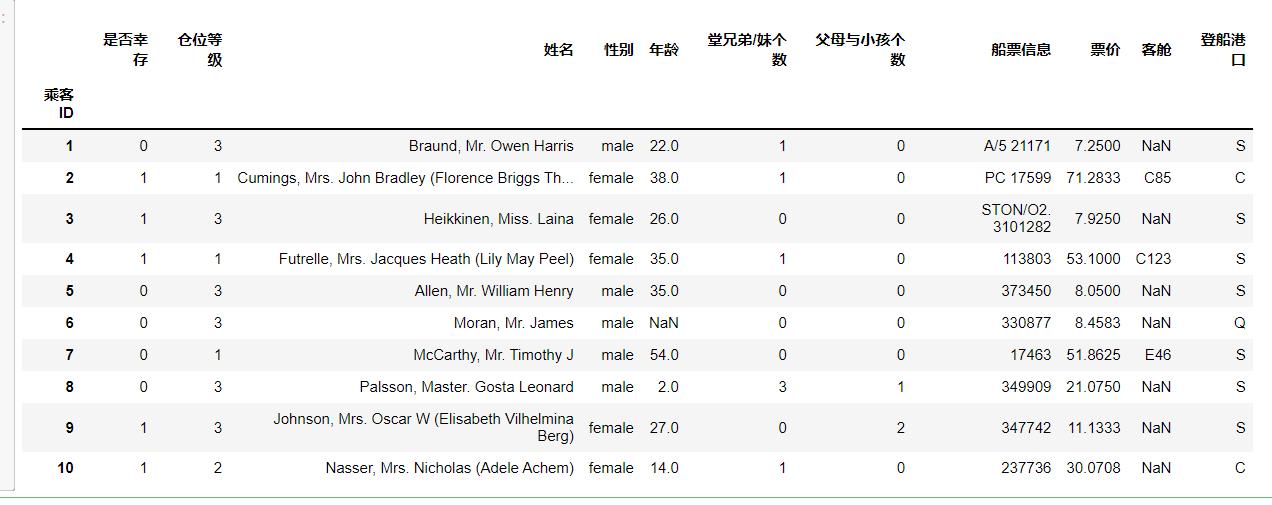
②观察表格前10行的数据和后15行的数据
#前十行
df.head(10)
#或
df.iloc[:10,:]
运行结果
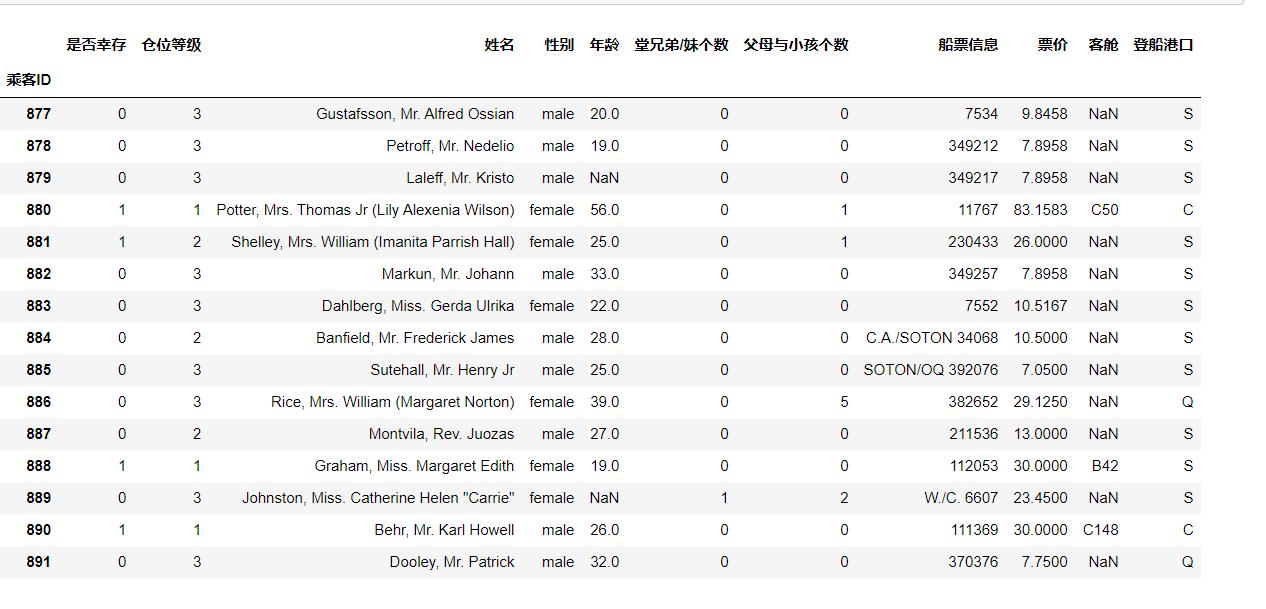
#后15行
df.tail(15)
#或
df.iloc[-15:,:]
运行结果
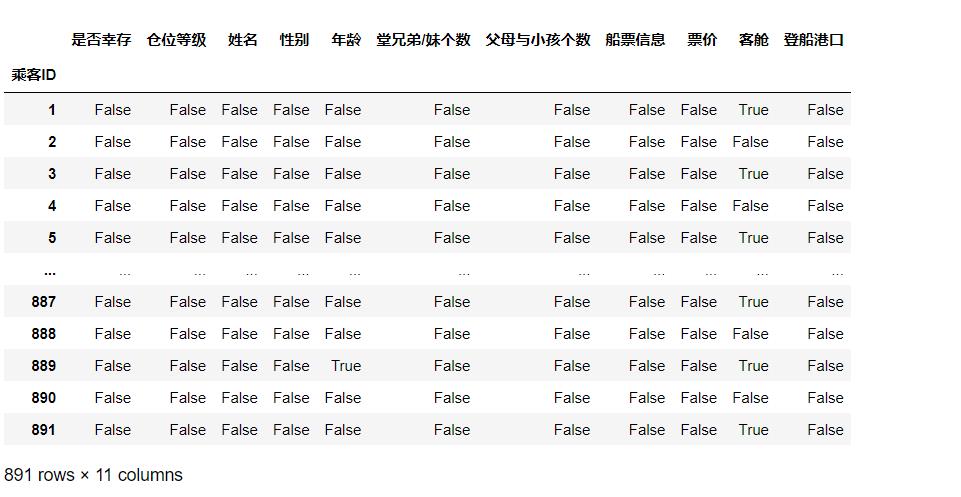
③判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull()
运行结果
3.保存数据
# 注意:不同的操作系统保存下来可能会有乱码。可以加入`encoding='GBK' 或者 ’encoding = ’utf-8‘‘`
df.to_csv("train_language_of_Chinese.csv",sep=',',encoding='utf-8')
二.pandas基础
数据分析的第一步,加载数据已经学习完毕了。当数据展现在我们面前的时候,我们所要做的第一步就是认识他,下面要学习的就是了解字段含义以及初步观察数据
1.基本数据类型:DataFrame和Series
①Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关 的数据标签(即索引)组成
仅由一组数据即可产生最简单的
Series:
import pandas as pd
import numpy as np
obj = pd.Series([4,7,-5,3])
print(obj)
运行结果

Series的字符串表现形式为:索引在左边,值在右边
可以通过
Series的values和index属性获取 其数组表示形式和索引对象:
print(obj.values)
print(obj.index)
运行结果
[ 4 7 -5 3]
RangeIndex(start=0, stop=4, step=1)
自创索引:
obj=pd.Series([4,7,-5,3],index=['h','z','s,s','p'])
print(obj)
运行结果
h 4
z 7
s,s -5
p 3
dtype: int64
与普通
NumPy数组相比,可以通过索引的方式选取Series中的单个或一组值:
obj=pd.Series([4,7,-5,3],index=['h','z','s,s','p'])
print(obj['h'])
obj['p']='a'
print(obj[['z','p','h']])#['Z','P','h']是索引列表
运行结果
4
z 7
p a
h 4
dtype: object
使用NumPy函数或类似NumPy的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数 等)都会保留索引值的链接
obj=pd.Series([4,7,-5,3],index=['h','z','s,s','p'])
print(obj[obj>0])
print(obj*2)
print(np.exp(obj))
h 4
z 7
p 3
dtype: int64
h 8
z 14
s,s -10
p 6
dtype: int64
h 54.598150
z 1096.633158
s,s 0.006738
p 20.085537
dtype: float64
可以将
Series看成是一个定长的有序字典,因为它是索引值到数据值的一个映射。它可以用在许 多原本需要字典参数的函数中:
print('h' in obj)
print('q'in obj)
运行结果
True
False
如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj = pd.Series(sdata)
print(obj)
运行结果
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。可以传入排好序的 字典的键以改变顺序:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
states =['California','Ohio','Oregon','Texas']
obj=pd.Series(sdata,index=states)
print(obj)
运行结果
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
在这个例子中,sdata中跟states索引相匹配的那3个值会被找出来并放到相应的位置上,但由 于"California"所对应的sdata值找不到,所以其结果就为NaN(即“非数字”(not a number),在 pandas中,它用于表示缺失或NA值)。因为‘Utah’不在states中,它被从结果中除去。 缺失(missing)或NA表示缺失数据。
pandas的isnull和notnull函数可用于检测缺失数 据:
print(pd.isnull(obj))
print(pd.notnull(obj))
运行结果
California True
Ohio False
Oregon False
Texas False
dtype: bool
California False
Ohio True
Oregon True
Texas True
dtype: bool
Series也有类似的实例方法:
print(obj.isnull())
print(obj.notnull())
运行结果
California True
Ohio False
Oregon False
Texas False
dtype: bool
California False
Ohio True
Oregon True
Texas True
dtype: bool
对于许多应用而言,Series最重要的一个功能是,它会根据运算的索引标签自动对齐数据
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
states =['California','Ohio','Oregon','Texas']
obj1=pd.Series(sdata)
obj2=pd.Series(sdata,states)
print(obj1+obj2)
运行结果
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
states =['California','Ohio','Oregon','Texas']
obj=pd.Series(sdata,states)
obj.name='population'
obj.index.name='state'
print(obj)
运行结果
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
Series的索引可以通过赋值的方式就地修改:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
states =['California','Ohio','Oregon','Texas']
obj=pd.Series(sdata,states)
print(obj)
obj.index= ['Bob', 'Steve', 'Jeff', 'Ryan']
print(obj)
运行结果
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
Bob NaN
Steve 35000.0
Jeff 16000.0
Ryan 71000.0
dtype: float64
②DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字 符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维 数据结构)
下面的解释都写在代码的注释里面
#建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
print(frame)
#结果DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列:
#对于特别大的DataFrame,head方法会选取前五行:
print(frame.head())
运行结果
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
5 Nevada 2003 3.2
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
#如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
print(pd.DataFrame(data,columns=['year','state','pop']).head(3))
#如果传入的列在数据中找不到,就会在结果中产生缺失值:
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
print(frame2)
#通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series:
print(frame2['state'])
#注意,返回的Series拥有原DataFrame相同的索引,且其name属性也已经被相应地设置好了,行也可以通过位置或名称的方式进行获取,比如用loc属性
print(frame2.loc['state'])
运行结果
year state pop
0 2000 Ohio 1.5
1 2001 Ohio 1.7
2 2002 Ohio 3.6
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN以上是关于Datawhale7月组队学习task1数据加载及探索性数据分析的主要内容,如果未能解决你的问题,请参考以下文章