论文泛读161低资源神经机器翻译调查
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读161低资源神经机器翻译调查相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《A Survey on Low-Resource Neural Machine Translation》
一、摘要
神经方法在机器翻译方面已经达到了最先进的准确性,但由于收集大规模并行数据的成本很高。因此,针对并行数据非常有限的神经机器翻译 (NMT) 进行了大量研究,即低资源设置。在本文中,我们对低资源 NMT 进行了调查,并根据它们使用的辅助数据将相关作品分为三类:(1)利用源语言和/或目标语言的单语数据,(2)利用辅助语言的数据,以及(3)利用多模态数据。我们希望我们的调查能够帮助研究人员更好地理解这个领域,启发他们设计更好的算法,帮助行业从业者为他们的应用选择合适的算法。
二、结论
在本文中,我们提供了低资源NMT的文献综述。不同的技术根据辅助数据的类型进行分类:来自源/目标语言的单语数据、来自其他语言的数据和多模态数据。我们希望这项调查能够帮助读者了解该领域,并为他们的应用选择合适的技术。
尽管在调查的低资源NMT上已经做了很多努力,但仍然存在一些悬而未决的问题:
- 在多语言和迁移学习中,使用多少辅助语言和哪些辅助语言尚不清楚。LANGRANK [Lin等,2019]训练模型选择一种辅助语言。直观来看,使用多种辅助语言可能优于只使用一种,值得探索。
- 培训包含多种richresource语言的多语言模型成本很高。将多语言模型转换为看不见的低资源语言是一种有效的方法,挑战在于如何处理看不见的语言的新词汇。
- 如何有效地选择中枢语言很重要,但还没有得到很好的研究。
- 双语词典既有用又容易得到。目前的工作主要集中在利用双语词典对源语言和目标语言进行分析。在多语言和迁移培训中,也可以在低资源语言和辅助语言之间使用双语词典。
- 就多模态而言,语音数据有潜力提升NMT,但这样的研究是有限的。例如,有些语言在语音上相近,但在文字上不同(如塔吉克语和波斯语)。
- 当前的方法已经对低资源语言做出了显著的改进,这些语言要么具有足够的单语数据,要么与一些资源丰富的语言相关。不幸的是,一些低资源语言(例如,Adyghe和Xibe)的单语数据非常有限,并且远离资源丰富的语言。如何处理这类语言具有挑战性,值得进一步研究。
三、概述
利用辅助语言数据的工作概述:
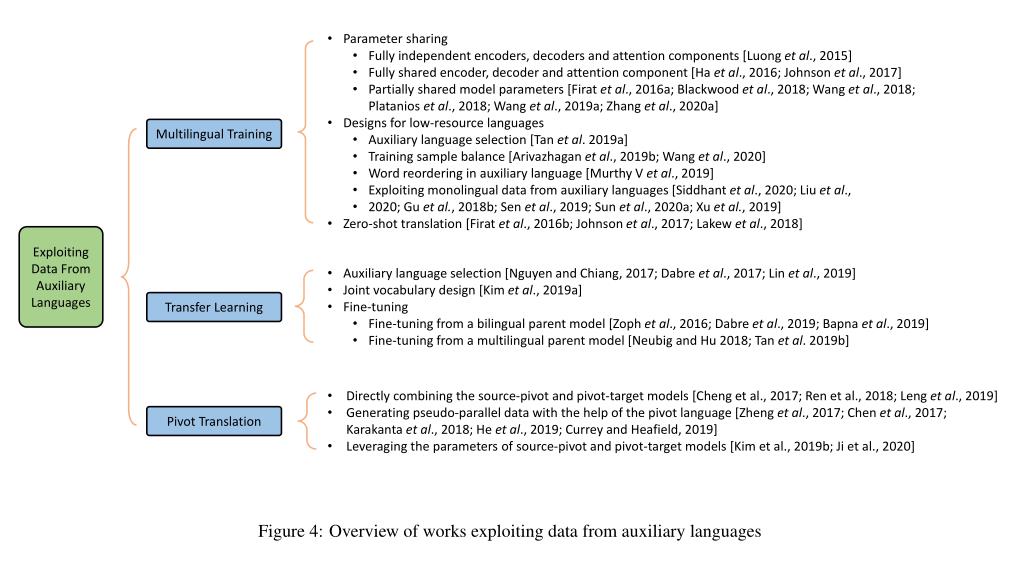
人类语言在几个方面有相似之处;
- (1)同一/相似语系或类型的语言可能有相似的书写文字、单词词汇、词序和语法
- (2)语言可以相互影响,来自另一种语言的外来词可以照原样融入一种语言(称为外来词)。
多语言数据利用到低资源NMT的方法可以分为几种类型:
- (1)多语言训练,其中低资源语言对在一个模型中与其他语言对联合训练
- (2)迁移学习[Zoph等人,2016],其中通常包含丰富资源语言对的父NMT模型首先被训练,然后在低资源语言对上被微调
- (3)枢轴翻译
以上是关于论文泛读161低资源神经机器翻译调查的主要内容,如果未能解决你的问题,请参考以下文章