机器学习-西瓜书第一二章
Posted GoAl的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-西瓜书第一二章相关的知识,希望对你有一定的参考价值。
第一章:绪论
基本概念
数据集:所有数据的集合
训练集:训练样本的集合
属性(特征):某事物或对象在某方面表现的性质
属性值:属性的取值
属性空间/样本空间/输入空间:属性张成的空间
泛化能力:学得模型适用于新样本的能力(泛化能力强更好地适用于样本空间)
机器学习算法的类型
1. 有监督学习
有监督学习通常是利用带有专家标注的标签的训练数据,学习一个从输入变量X到输入变量Y的函数映射。 Y = f (X)
训练数据通常是(n×x,y)的形式,其中n代表训练样本的大小,x和y分别是变量X和Y的样本值。
利用有监督学习解决的问题大致上可以被分为两类:
分类问题:预测某一样本所属的类别(离散的)。比如给定一个人(从数据的角度来说,是给出一个人的数据结构,包括:身高,年龄,体重等信息),然后判断是性别,或者是否健康。
回归问题:预测某一样本的所对应的实数输出(连续的)。比如预测某一地区人的平均身高。
下面所介绍的前五个算法(线性回归,逻辑回归,分类回归树,朴素贝叶斯,K最近邻算法)均是有监督学习的例子。
除此之外,集成学习也是一种有监督学习。它是将多个不同的相对较弱的机器学习模型的预测组合起来,用来预测新的样本。本文中所介绍的第九个和第十个算法(随机森林装袋法,和XGBoost算法)便是集成技术的例子。
2. 无监督学习
无监督学习问题处理的是,只有输入变量X没有相应输出变量的训练数据。它利用没有专家标注训练数据,对数据的结构建模。
可以利用无监督学习解决的问题,大致分为两类:
关联分析:发现不同事物之间同时出现的概率。在购物篮分析中被广泛地应用。如果发现买面包的客户有百分之八十的概率买鸡蛋,那么商家就会把鸡蛋和面包放在相邻的货架上。
聚类问题:将相似的样本划分为一个簇(cluster)。与分类问题不同,聚类问题预先并不知道类别,自然训练数据也没有类别的标签。
维度约减:顾名思义,维度约减是指减少数据的维度同时保证不丢失有意义的信息。利用特征提取方法和特征选择方法,可以达到维度约减的效果。特征选择是指选择原始变量的子集。特征提取是将数据从高纬度转换到低纬度。广为熟知的主成分分析算法就是特征提取的方法。
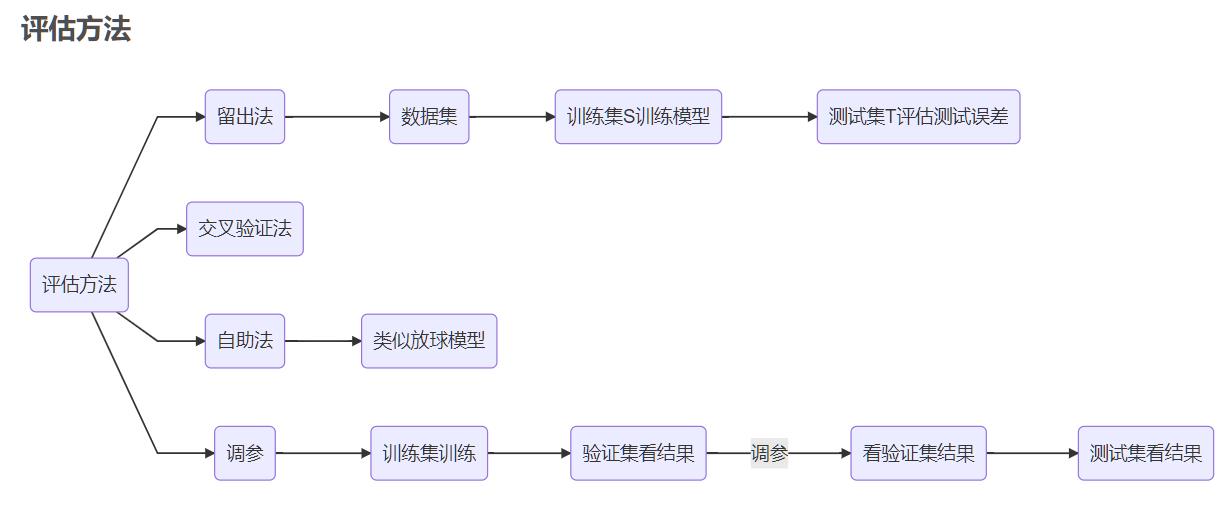
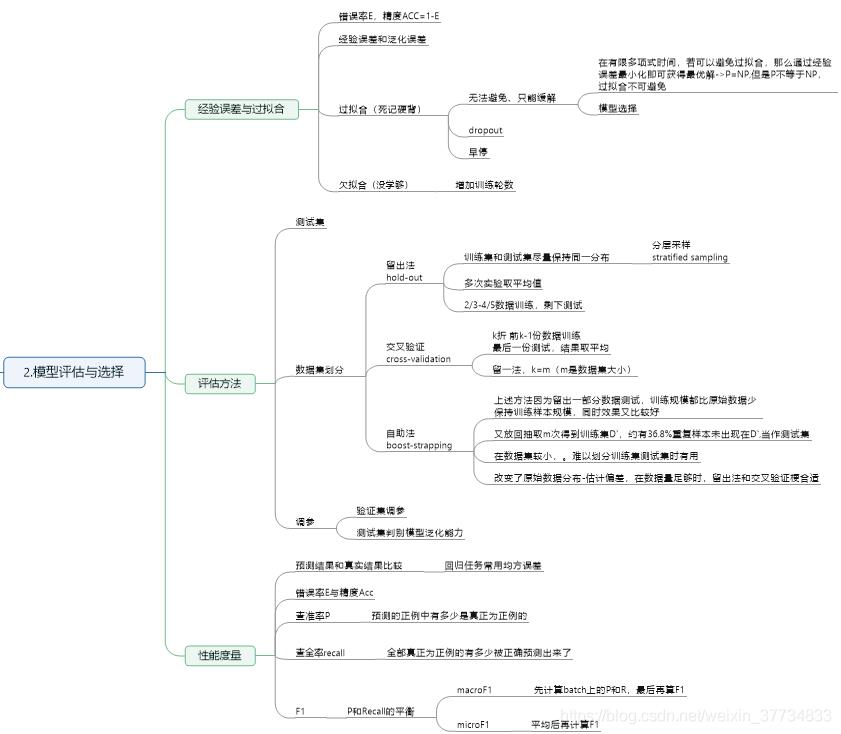
第2章 模型评估与选择
评估方法
以上是关于机器学习-西瓜书第一二章的主要内容,如果未能解决你的问题,请参考以下文章