《AutoFlow:Learning a Better Training Set for Optical Flow》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《AutoFlow:Learning a Better Training Set for Optical Flow》论文笔记相关的知识,希望对你有一定的参考价值。
主页:home page
1. 概述
导读:在光流监督训练网络中,其需要的真实光流数据是很难获取的,因而合成数据在基于CNN的光流估计任务中扮演了很重要的角色。但是在合成数据上进行训练就很大限制了其在其它类型数据场景的适应性(像FlyingChairs这样的数据本身就具有局限性),也就是泛化能力比较低(或由于预训练的原因未收敛到更优值)。对此文章将target domain的数据与光流训练数据的生成组合起来,在数据生成中使用可训练的参数(不同参数采样表示了不同的数据处理,如仿射变换/模糊等)来变化数据,再用变换之后的数据去预训练光流网络,这里数据生成的参数选择是在target domain上做度量(average end-point error,AEPE)来决定的。这样使得预训练的网络在其训练过程中就兼容了target domain中的数据特性,从而提升了网络在target domain数据集上的性能表现。文章的使用比较新颖的方式提出了数据增广的策略,目前(2021.07.12)代码还没有开源。
将文章提出的光流网络训练策略与传统方法(在FlyingChairs/FlyingThings等数据集上预训练,之后再在target domain数据上finetune)进行对比,见下图所示:
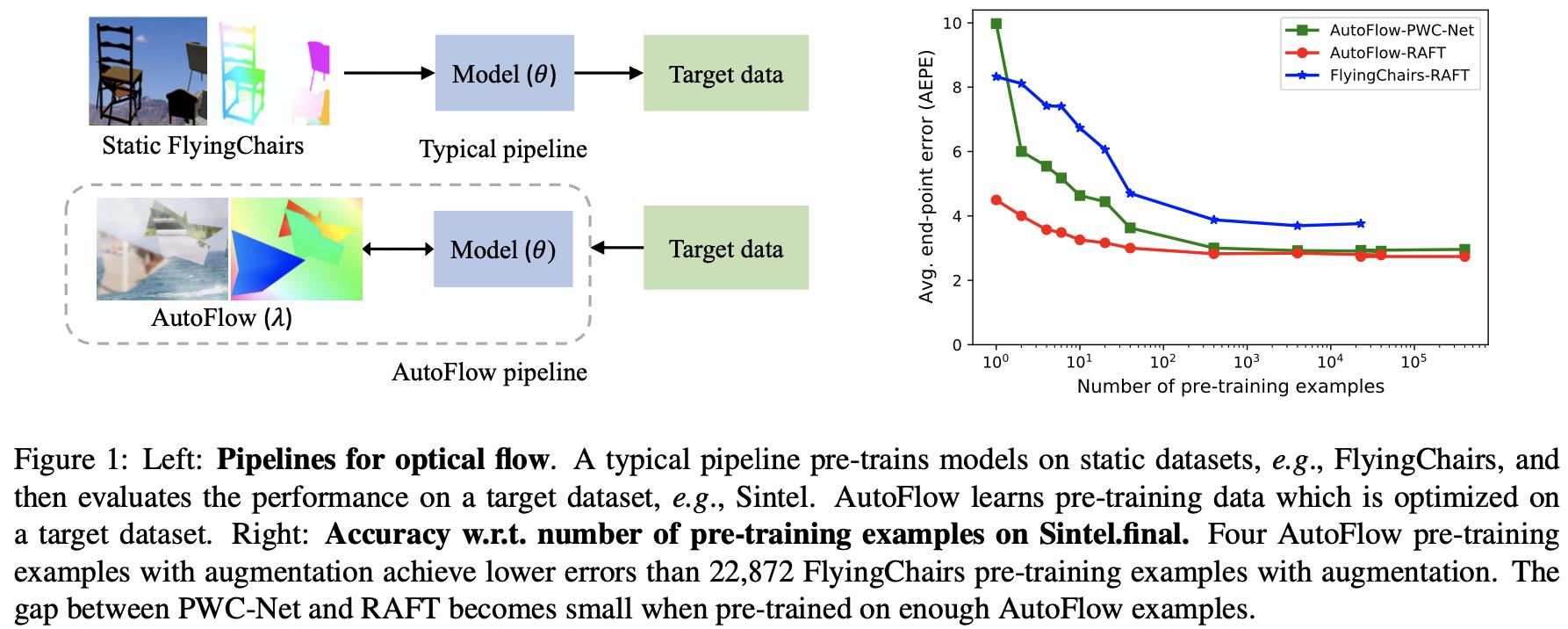
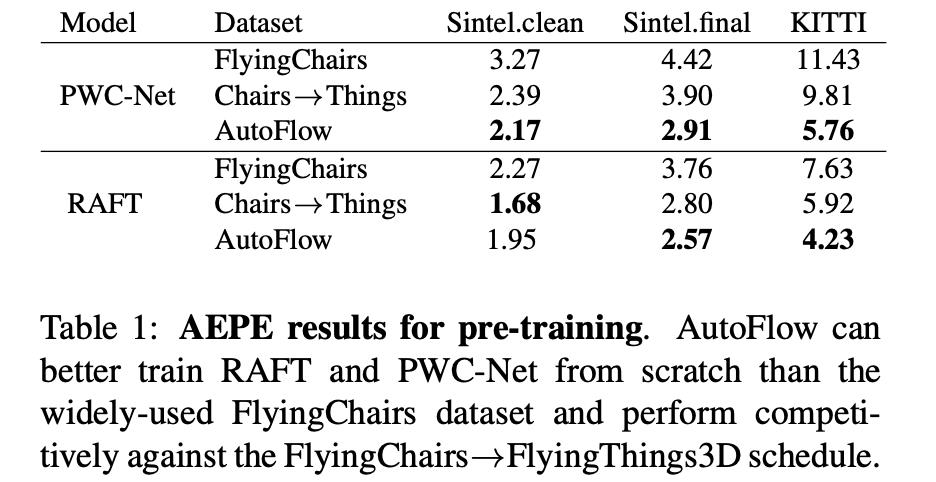
可以从图中看到文章是对预训练的数据部分进行了改动,通过一组可学习的参数(如仿射变换参数)去变换输入的sample从而产生预训练数据集,从而实现合成光流数据监督训练。那么怎么使得产生的数据去契合target domain呢?这里需要通过一个度量函数(average end-point error,AEPE)去判别那个可学习的数据变换参数是最好的,从而完成光流网络预训练任务。预训练完成之后在对应的数据集(Sintel/KITTIes)上进行finetune,将得到的结果与传统方法得到结果进行比较见下表所示:
2. 数据pipline
2.1 总体流程
文章提出的合成光流数据的流程见下图2所示:

在开始进行数据合成之前会先选择1张背景图片,以及
K
K
K个前景图片
I
1
k
I_1^k
I1k(后面会使用mask在其中进行扣取像素),那么接下来合成的步骤被描述为以下的几个步骤:
- 1)step1:在给定的图像 I 1 k I_1^k I1k上使用随机多边形或是instance mask的形式选择前景mask,得到的mask标记为 M 1 k M_1^k M1k;
- 2)step2:使用刚性变换/仿射变换/双线性网格变换方式去对上面一步中产生的mask区域进行扭曲得到对应的光流信息
W
k
W^k
Wk,得到光流信息之后就可以将其变换到对应另一对图像中去
I 2 k = f ( I 1 k , W k ) I_2^k=f(I_1^k,W^k) I2k=f(I1k,Wk)
M 2 k = f ( M 1 k , W k ) M_2^k=f(M_1^k,W^k) M2k=f(M1k,Wk)
其中, f f f是依据光流的变换函数; - 3)step3:将多个图像按照从后往前的方式进行叠加,得到最后的结果:
I k = M k ⊙ I k + ( 1 − M k ) ⊙ I k − 1 I^k=M^k\\odot I^k+(1-M^k)\\odot I^{k-1} Ik=Mk⊙Ik+(1−Mk)⊙Ik−1
W k = M ˉ k ⊙ W k + ( 1 − M ˉ k ) ⊙ W k − 1 W^k=\\bar{M}^k\\odot W^k+(1-\\bar{M}^k)\\odot W^{k-1} Wk=Mˉk⊙Wk+(1−Mˉk)⊙Wk−1
这里文章为了简洁并没有给出具体的角标符号等迭代信息,给理解融合的过程带来难度,理解这部分还需后面代码开源之后对比考证;
2.2 数据处理内容与模型建立
目标mask的生成:
这里的目标mask也就是前景区域,其获取的方式有两种:使用任意的多边形,以及实例分割的mask。
- 1)对于多边形mask,其
M
1
k
∈
[
0
,
1
]
M_1^k\\in[0,1]
M1k∈[0,1]的alpha,它是由随机生成的多边形区域,其内部是可以有孔洞的;多边形的形状也可以经过平滑,使得其表面光滑;同时也可以对其添加高斯模糊使得边缘羽化,其效果图见下图所示:

- 2)对于实例分割mask,文章主要是从符合以及丰富语义的角度出发在OpenImages数据上选择实例分割mask作为前景;
前景运动及形变:
为了丰富数据多样性,文章结合刚性变换(尺度/旋转/平移变换)/仿射变换/双线性网格变换操作对前景区域进行变换。通过采样得到前景区域的采样结果之后便可以得到前景区域的光流信息,下图展示了三种变换产生的数据:

真实效果逼近:
为了逼近实际场景下的数据分布,文章引入了运动模糊和雾化效果作为数据增广的形式(文章的对比实验结果也展示了其对运动场景具有更强的适应能力),在进行这些变换的时候对应的光流GT是不发生变化的。
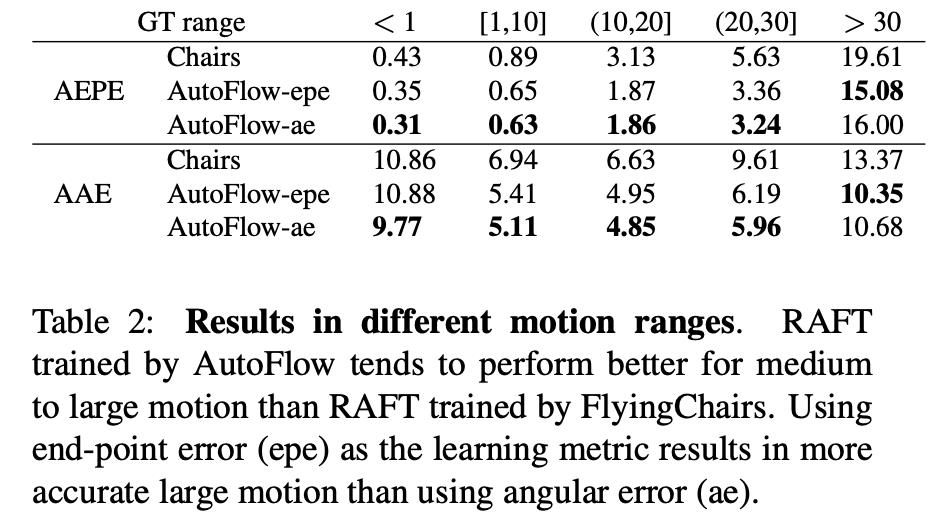
- 1)运动模糊:这里对前景和前景对应的mask进行操作,其使用运动模糊滤波器的参数是与前景对应光流的绝对值成对应的比例的,进而使得更加合理。需要注意的是这里会对输入模型的图像对都采用同样的参数进行模糊。运动模糊力度对性能的影响;
- 2)雾化效果:这里是通过一张全白图片和一个半透明alpha进行确定的。其是通过在几个分辨率上生成与分辨率成反比例的随机图像,之后将其采样到相同分辨率相加。最后通过需要学习的变换参数进行变换得到最后结果;
上面两种数据处理的效果见下图所示:

数据增广策略:
除了上述的前景变换信息之外,文章还引入了整体旋转/尺度/squeeze/平移/噪声添加等操作到每次迭代的图像中去。这里操作的数量和强度等级也是可以通过参数化的。
变换参数的模型化(参数化):
对于这部分的内容,可以参考文章的A. Rendering Hyperparameters章节查看。
下图展示文章提出方法得到的数据示例:

2.3 优化模型
数据生成使用的采样参数空间描述为
Λ
\\Lambda
Λ,那么在采样空间进行采样与判断最优组合可以描述为:
λ
∗
=
arg min
λ
∈
Λ
Ω
(
θ
(
λ
)
)
\\lambda^{*}=\\argmin_{\\lambda\\in\\Lambda}\\Omega(\\theta(\\lambda))
λ∗=λ∈ΛargminΩ(θ(λ))
这里
θ
,
Ω
\\theta,\\Omega
θ,Ω是光流估计网络的参数以及在target domain的度量函数(AEPE)。在更新采样参数之后,则更新光流估计网络的参数:
θ
(
λ
)
=
arg min
θ
L
(
W
(
λ
)
,
ϕ
θ
(
I
1
(
λ
)
,
I
2
(
λ
)
)
)
\\theta(\\lambda)=\\argmin_{\\theta}L(W(\\lambda),\\phi_{\\theta}(I_1(\\lambda),I_2({\\lambda})))
θ(λ)=θargminL(W(λ),ϕθ(I1(λ),I2(λ)))
对于具体采样参数的优化过程文章提到其是使用PBT(population-based trainning)训练以及CMA-ES(Matrix Adaptation Evolution Strategy)构成启发式优化算法。其中CMA-ES在迭代过程中在搜索空间中构建采样分布。
3. 实验结果
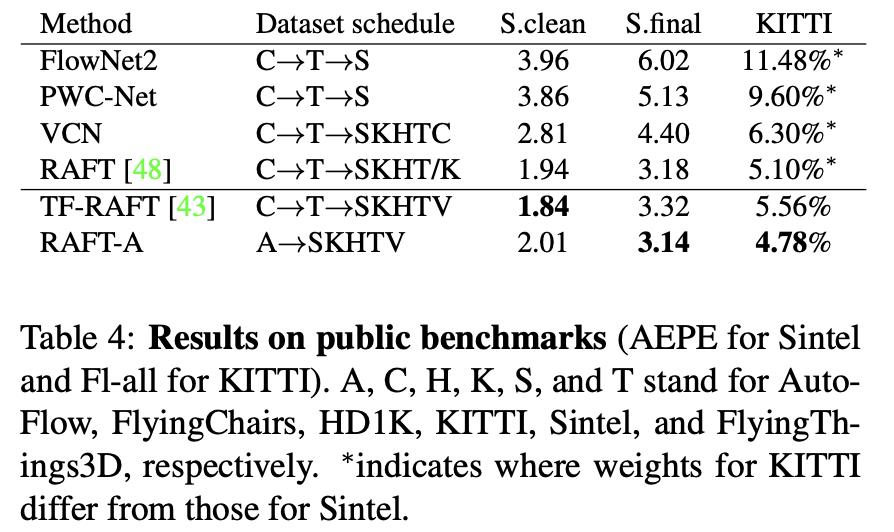
文章的方法(预训练)对性能的影响:
消融实验:
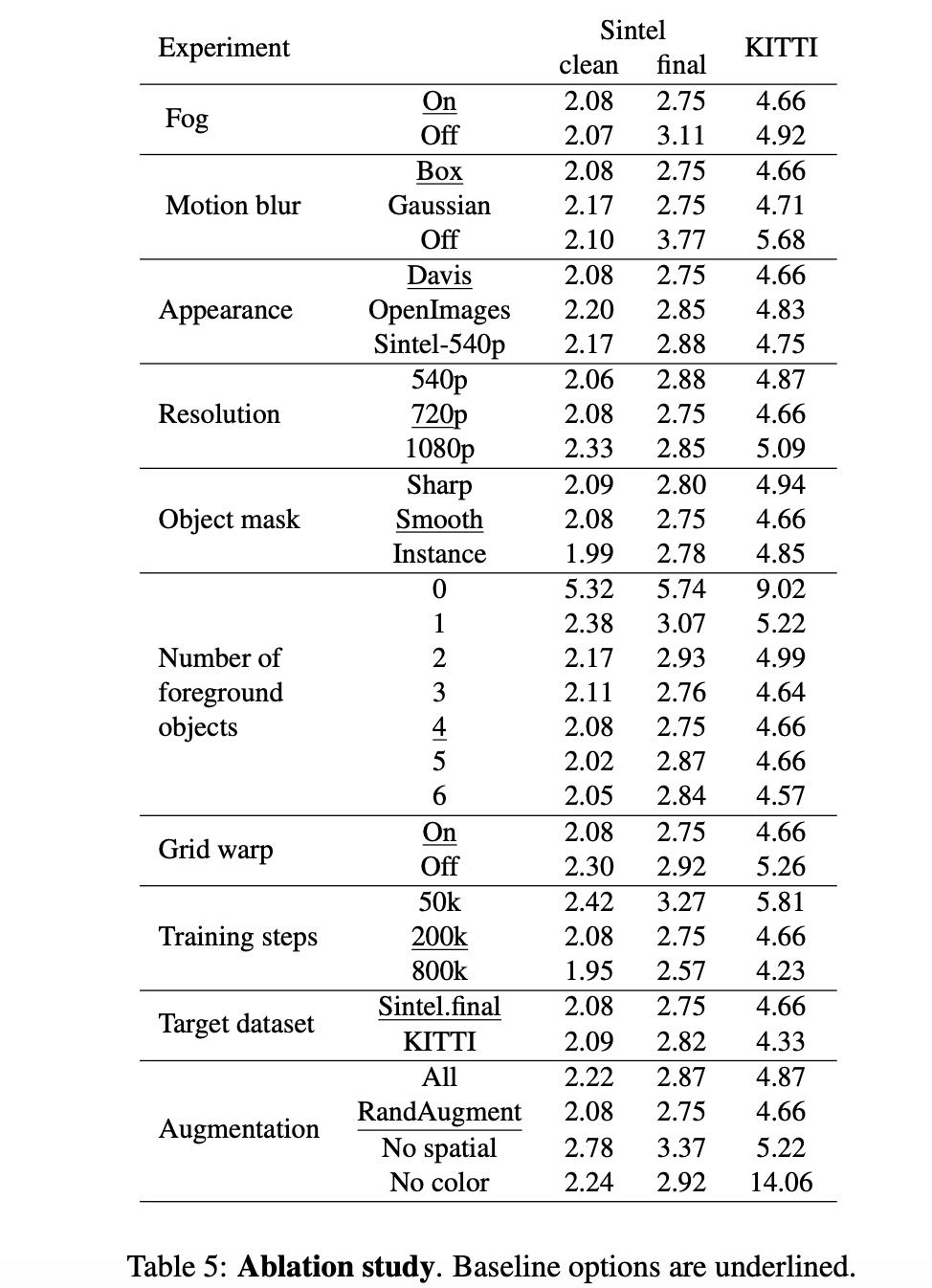
以上是关于《AutoFlow:Learning a Better Training Set for Optical Flow》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章