淘宝分布式文件系统 (淘宝网为什么不用普通文件存储海量小数据?)
Posted Respect@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了淘宝分布式文件系统 (淘宝网为什么不用普通文件存储海量小数据?)相关的知识,希望对你有一定的参考价值。
背景介绍

根据淘宝2016年的数据分析,淘宝卖家已经达到900多万,有上十亿的商品。每一个商品有包括大量的图片和文字(平均:15k),粗略估计下,数据所占的存储空间在1PB 以上,如果使用单块容量为1T容量的磁盘来保存数据,那么也需要1024 x 1024 块磁盘来保存.
1 PB = 1024 TB = 1024 * 1024 GB
思考? 这么大的数据量,应该怎么保存呢?就保存在普通的单个文件中或单台服务器中吗?显然是不可行的。
淘宝针对海量非结构化数据存储设计出了的一款分布式系统,叫TFS,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。
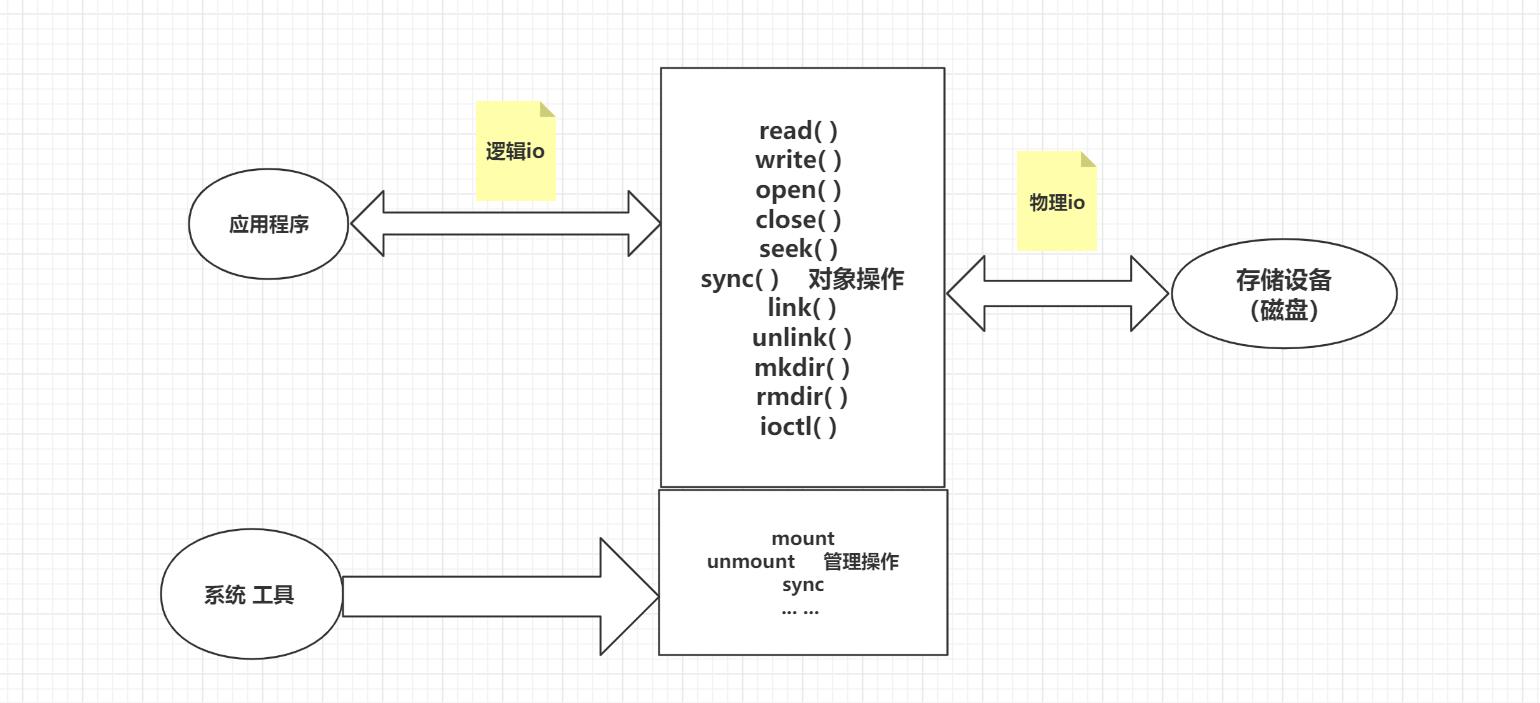
文件系统接口
文件系统 -一种把数据组织成文件和目录的存储方式,提供了基于文件的存取接口,并通过文件权限控制访问。

存储的基本单位
位(bit):二进制数中的一个数位,可以是0或者1,是计算机中数据的最小单位。
字节(Byte,B):计算机中数据的基本单位,每8位组成一个字节。各种信息在计算机中存储、处理至少需要一个字节。例如,一个ASCII码用一个字节表示,一个汉字用两个字节表示。
字(Word):两个字节称为一个字。汉字的存储单位都是一个字。
扩展的存储单位
在计算机各种存储介质(例如内存、硬盘、光盘等)的存储容量表示中,用户所接触到的存储单位不是位、字节和字,而是KB、MB、GB等,但这不是新的存储单位,而是基于字节换算的。
KB: 。早期用的软盘有360KB和720KB的,不过软盘已经很少使用。
MB: 。早期微型机的内存有128MB、256MB、512MB,目前内存都是1GB、2GB甚至更大。
GB: 。早期微型机的硬盘有60GB、80GB,目前都是500GB、1TB甚至更大。
TB: 。目前个人用的微型机存储容量也都能达到这个级别了,而作为服务器或者专门的计算机,不可缺少这么大的存储容量。
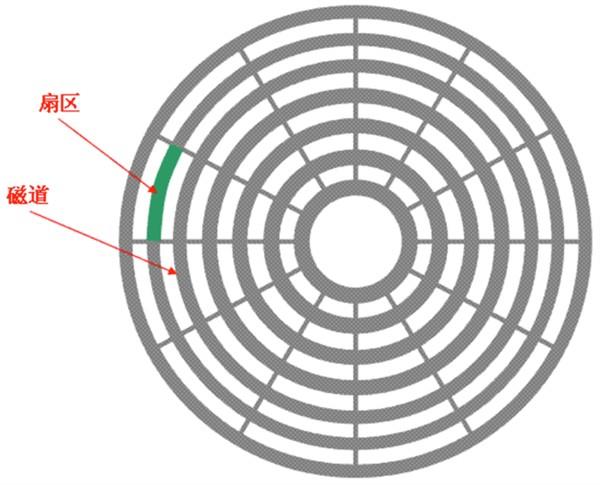

磁盘的每一面被分为很多条磁道,即表面上的一些同心圆,越接近中心,圆就越小。
而每一个磁道又按512个字节为单位划分为等分,叫做扇区
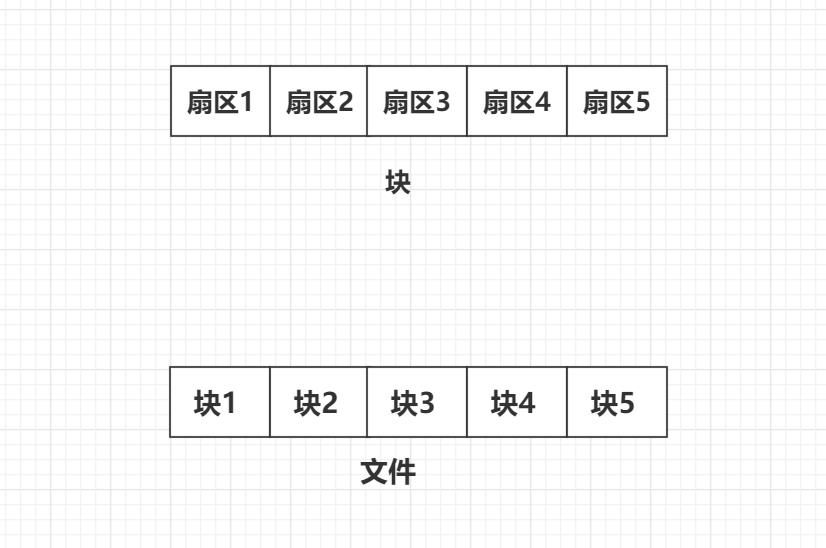
文件存储单位
块 - 文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
存储单位是一种计量单位。指在某一领域以一个特定量,或标准做为一个记录(计数)点。再以此点的某个倍数再去定义另一个点,而这个点的代名词就是计数单位或存储单位。
文件结构
Ext*格式化分区 - 操作系统自动将硬盘分成三个区域。
目录项区 - 存放目录下文件的列表信息
数据区 - 存放文件数据
inode区(inode table) - 存放inode所包含的信息

是通过inode元信息来查找的
-
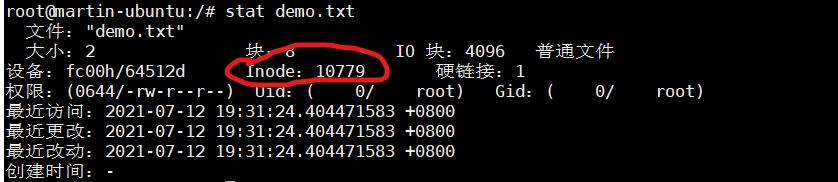
inode - “索引节点”,储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。每个inode都有一个号码,操作系统用inode号码来识别不同的文件。ls -i 查看inode 号
-
inode节点大小 - 一般是128字节或256字节。inode节点的总数,格式化时就给定,一般是每1KB或每2KB就设置一个inode。一块1GB的硬盘中,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
系统读取文件三步曲
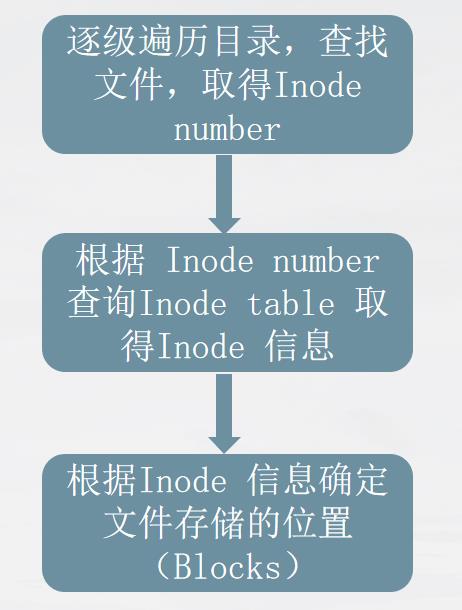
找到根目录下的编号

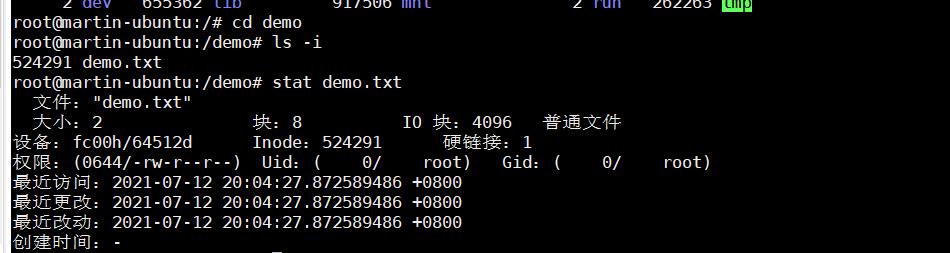
淘宝网为什么不用普通文件存储海量小数据?
- 大规模的小文件存取,磁头需要频繁的寻道和换道,因此在读取上容易带来
较长的延时。
| 千兆网络发送 1MB 数据 | 10ms |
|---|---|
| 机房内网络来回 | 0.5ms |
| SATA 磁盘寻道 | 10ms |
| 从SATA磁盘顺序读取 1MB 数据 | 20ms |
-
频繁的新增删除操作导致磁盘碎片,降低磁盘利用率和IO读写效率
-
Inode 占用大量磁盘空间,降低了缓存的效果。
淘宝文件系统大文件结构
设计思路
-
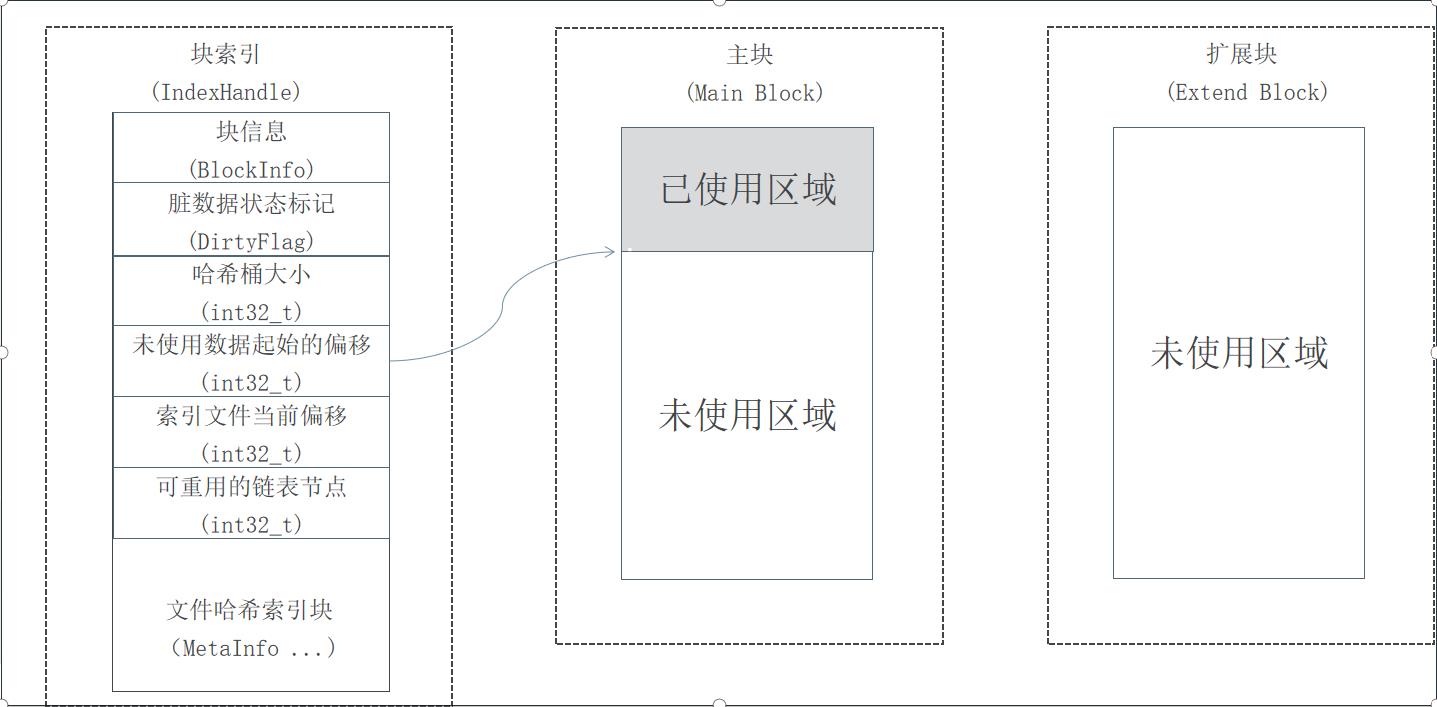
以block文件的形式存放数据文件(一般64M一个block),以下简称为“块”,每个块都有唯一的一个整数编号,块在使用之前所用到的存储空间都会预先分配和初始化。
-
每一个块由一个索引文件、一个主块文件和若干个扩展块组成,“小文件”主要存放在主块中,扩展块主要用来存放溢出的数据。
-
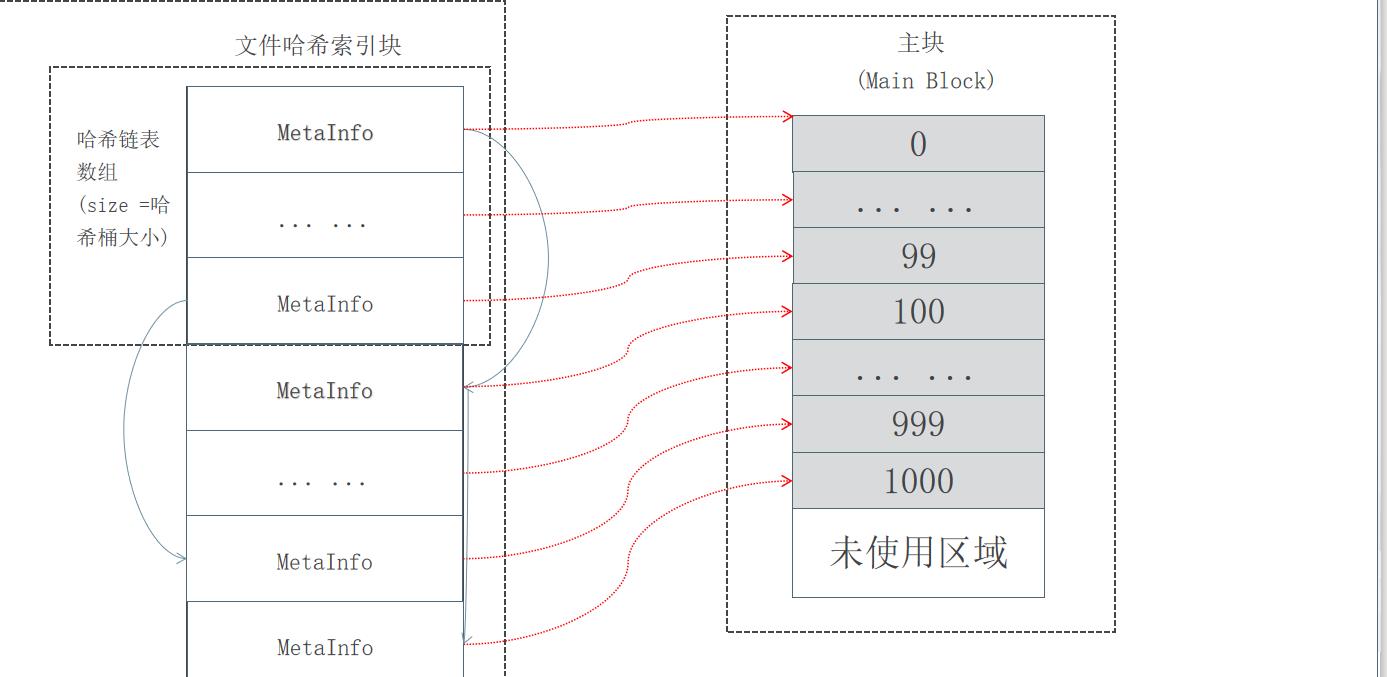
每个索引文件存放对应的块信息和“小文件”索引信息,索引文件会在服务启动是映射(mmap)到内存,以便极大的提高文件检索速度。“小文件”索引信息采用在索引文件中的数据结构哈希链表来实现。
-
每个文件有对应的文件编号,文件编号从1开始编号,依次递增,同时作为哈希查找算法的Key 来定位“小文件”在主块和扩展块中的偏移量。文件编号+块编号按某种算法可得到“小文件”对应的文件名。
哈希表 - 散列表,它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法
| 键(key): | 文件的编号 如, 1 、 5 、 19 。 。 。 |
|---|---|
| 值(value): | 文件的索引信息(包含 文件大小、位置) |
| 索引: | 数组的下标(0,1,2,3,4) ,用以快速定位和检索数据 |
| 哈希桶: | 保存索引的数组,数组成员为每一个索引值相同的多个元素(以链表的形式链接)的首节点 |
| 哈希函数: | 将文件编号映射到索引上,采用求余法 ,如: 文件编号 19 |
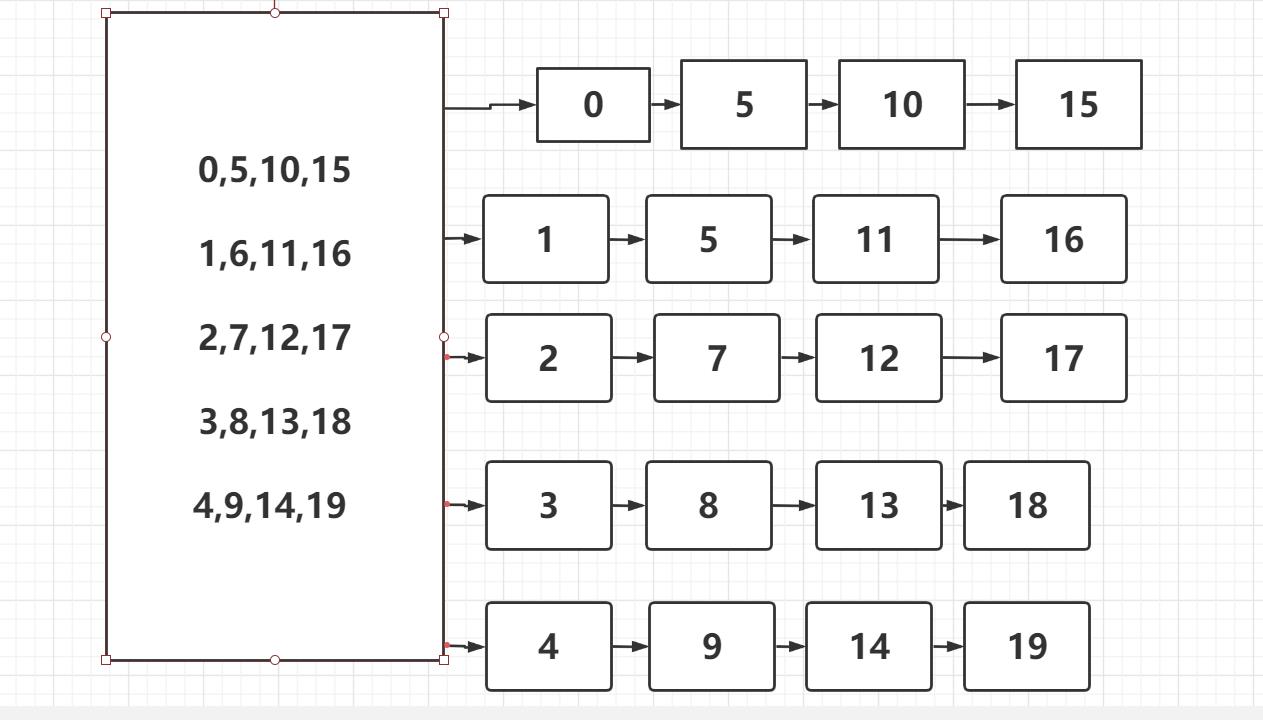
大文件存储结构图
文件哈希链表实现图

关键数据结构
struct BlockInfo
{
uint32_t block_id_; //块编号 1 ......2^32-1 TFS = NameServer + DataServer
int32_t version_; //块当前版本号
int32_t file_count_; //当前已保存文件总数
int32_t size_; //当前已保存文件数据总大小
int32_t del_file_count_; //已删除的文件数量
int32_t del_size_; //已删除的文件数据总大小
uint32_t seq_no_; //下一个可分配的文件编号 1 ...2^64-1
}
struct RawMeta {
uint64_t fileid_; //文件编号
struct
{
int32_t inner_offset_; //文件在块内部的偏移量
int32_t size_; //文件大小
} location_;
};
struct MetaInfo{
RawMeta raw_meta_; //文件元数据
int32_t next_meta_offset_; //当前哈希链下一个节点在索引文件中的偏移量
}
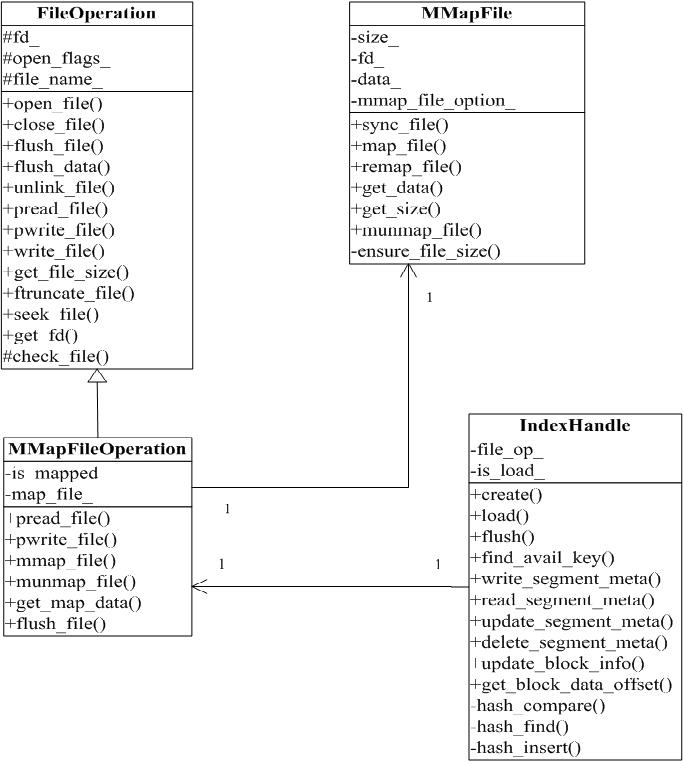
**设计类图 **
以上是关于淘宝分布式文件系统 (淘宝网为什么不用普通文件存储海量小数据?)的主要内容,如果未能解决你的问题,请参考以下文章