NLP情感分析和可视化|python实现评论内容的文本清洗语料库分词去除停用词建立TF-IDF矩阵获取主题词和主题词团
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP情感分析和可视化|python实现评论内容的文本清洗语料库分词去除停用词建立TF-IDF矩阵获取主题词和主题词团相关的知识,希望对你有一定的参考价值。
1 文本数据准备
首先文本数据准备,爬取李佳琦下的评论,如下:
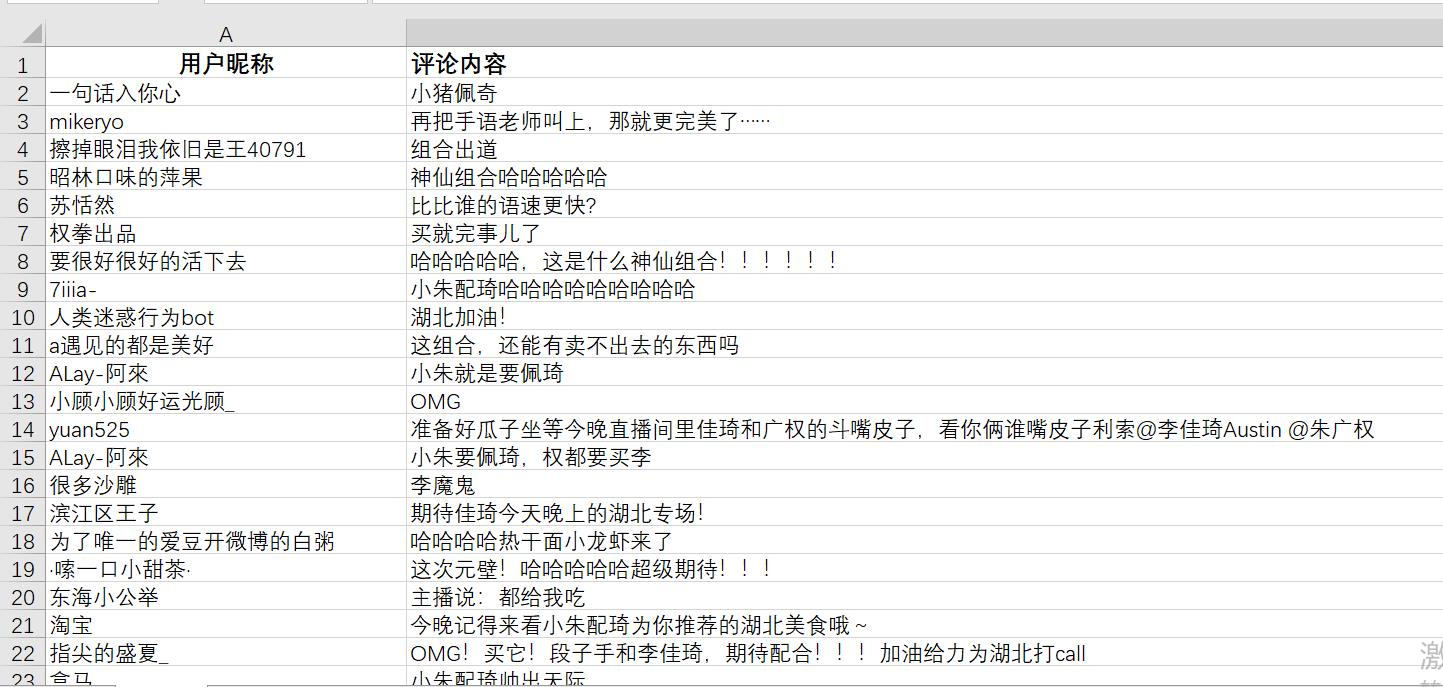
2 提出文本数据、获得评论内容
#内容读取
import xlrd
import pandas as pd
wb=xlrd.open_workbook("评论数据.xlsx")
sh=wb.sheet_by_index(0)
col=sh.ncols
row=sh.nrows
Text=[]
for i in range(row):
Text_Context=sh.row_values(i,1,2)[0]
Text.append(Text_Context)
del Text[0]
print(Text)2 进行结巴分词、去除停用词,得到词料
#结巴分词
import jieba
import gensim
#停用词处理
import spacy
from spacy.lang.zh.stop_words import STOP_WORDS
sent_words = []
for sent0 in Text:
try:
l=list(jieba.cut(sent0))
# print(l)
filtered_sentence = []
for word in l:
if word not in STOP_WORDS:
filtered_sentence.append(word)
sent_words.append(filtered_sentence)
# print( filtered_sentence)
except:
pass
print(sent_words)
document = [" "3 生成TF-IDF矩阵:获取逆文档高频词
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
tfidf_model = TfidfVectorizer().fit(document)
# 得到语料库所有不重复的词
feature = tfidf_model.get_feature_names()
print(feature)
# 得到每个特征对应的id值:即上面数组的下标
print(tfidf_model.vocabulary_)
# 每一行中的指定特征的tf-idf值:
sparse_result = tfidf_model.transform(document)
# 每一个语料中包含的各个特征值的tf-idf值:
# 每一行代表一个预料,每一列代表这一行代表的语料中包含这个词的tf-idf值,不包含则为空
weight = sparse_result.toarray()
# 构建词与tf-idf的字典:
feature_TFIDF = {}
for i in range(len(weight)):
for j in range(len(feature)):
# print(feature[j], weight[i][j])
if feature[j] not in feature_TFIDF:
feature_TFIDF[feature[j]] = weight[i][j]
else:
feature_TFIDF[feature[j]] = max(feature_TFIDF[feature[j]], weight[i][j])
# print(feature_TFIDF)
# 按值排序:
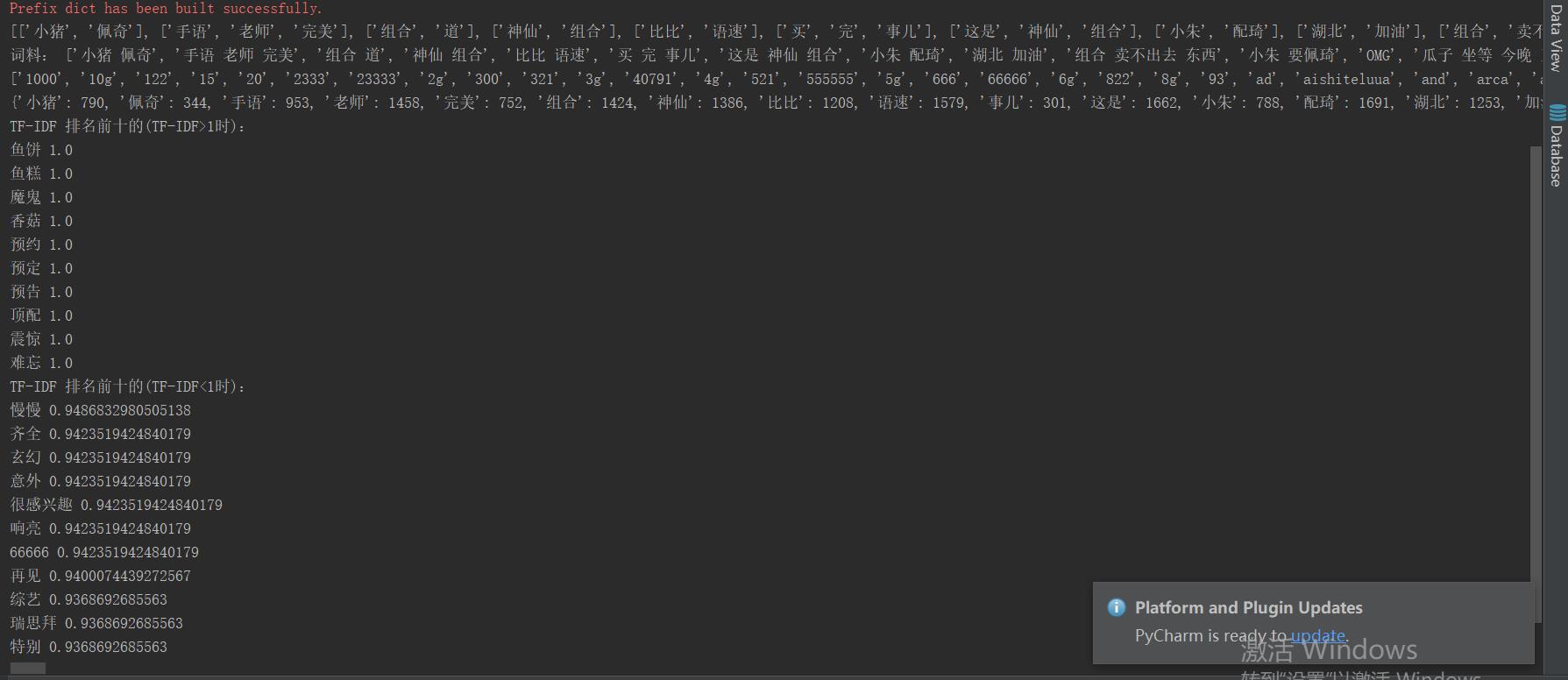
print('TF-IDF 排名前十的(TF-IDF>1时):')
featureList = sorted(feature_TFIDF.items(), key=lambda kv: (kv[1], kv[0]), reverse=True)
for i in range(10):
print(featureList[i][0], featureList[i][1])
k=0
m=0
print('TF-IDF 排名前十的(TF-IDF<1时):')
while k<=10:
if featureList[m][1]<1:
k+=1
print(featureList[m][0], featureList[m][1])
m+=1
4 结果:
5 画图
#!/usr/bin/python
# -*- coding:utf-8 -*-
from gensim import corpora
from gensim.models import LdaModel
from gensim.corpora import Dictionary
#内容读取
import xlrd
import pandas as pd
from gensim import corpora
from collections import defaultdict
import spacy
from spacy.lang.zh.stop_words import STOP_WORDS
#结巴分词
import jieba
import gensim
#停用词处理
wb=xlrd.open_workbook("评论数据.xlsx")
sh=wb.sheet_by_index(0)
col=sh.ncols
row=sh.nrows
Text=[]
for i in range(row):
Text_Context=sh.row_values(i,1,2)[0]
Text.append(Text_Context)
del Text[0]
print(Text)
file1 = open('结巴分词结果.txt','w')
sent_word = []
for sent0 in Text:
try:
l=list(jieba.cut(sent0))
sent_word.append(l)
# print( filtered_sentence)
except:
pass
for s in sent_word:
try:
for w in s:
file1.write(str(w))
file1.write('\\n')
except:
pass
file1.close()
sent_words=[]
for l in sent_word:
filtered_sentence=[]
for word in l:
if word not in STOP_WORDS:
filtered_sentence.append(word)
sent_words.append(filtered_sentence)
file2 = open('去除停用词后的结果.txt','w')
for s in sent_word:
for w in s:
file1.write(w)
file2.write('\\n')
file2.close()
dictionary = corpora.Dictionary(sent_words)
corpus = [dictionary.doc2bow(text) for text in sent_words]
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=20, passes=60)
# num_topics:主题数目
# passes:训练伦次
# num_words:每个主题下输出的term的数目
file3=open("tf-idf值.txt",'w')
for topic in lda.print_topics(num_words = 20):
try:
termNumber = topic[0]
print(topic[0], ':', sep='')
file3.write(str(topic[0])+':'+''+'\\n')
listOfTerms = topic[1].split('+')
for term in listOfTerms:
listItems = term.split('*')
print(' ', listItems[1], '(', listItems[0], ')', sep='')
file3.write(' '+str(listItems[1])+ '('+str(listItems[0])+ ')',+''+ '\\n')
except:
pass
import pyLDAvis.gensim
d=pyLDAvis.gensim.prepare(lda, corpus, dictionary)
'''
lda: 计算好的话题模型
corpus: 文档词频矩阵
dictionary: 词语空间
'''
pyLDAvis.save_html(d, 'lda_pass10.html')
# pyLDAvis.displace(d) #展示在notebook的output cell中
6 结果展示
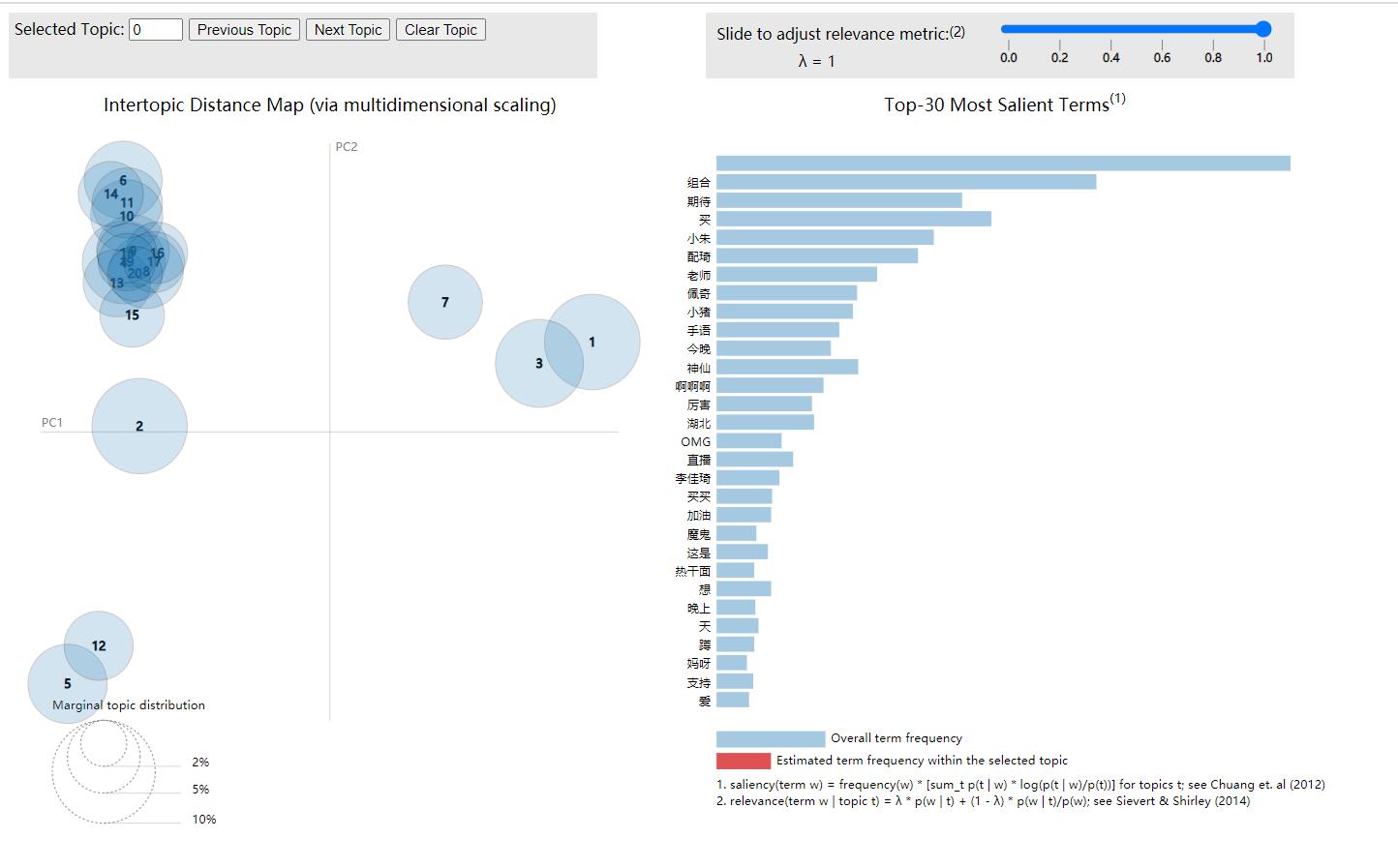
以上是关于NLP情感分析和可视化|python实现评论内容的文本清洗语料库分词去除停用词建立TF-IDF矩阵获取主题词和主题词团的主要内容,如果未能解决你的问题,请参考以下文章