面试被问到线段树,已经这么卷了吗?
Posted 懂你的大海
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试被问到线段树,已经这么卷了吗?相关的知识,希望对你有一定的参考价值。
在这篇文章里,我将介绍一种高效的区间查询数据结构 —— 线段树(Segment Tree)。如果能帮上忙,请务必点赞加关注,这真的对我非常重要。
目录
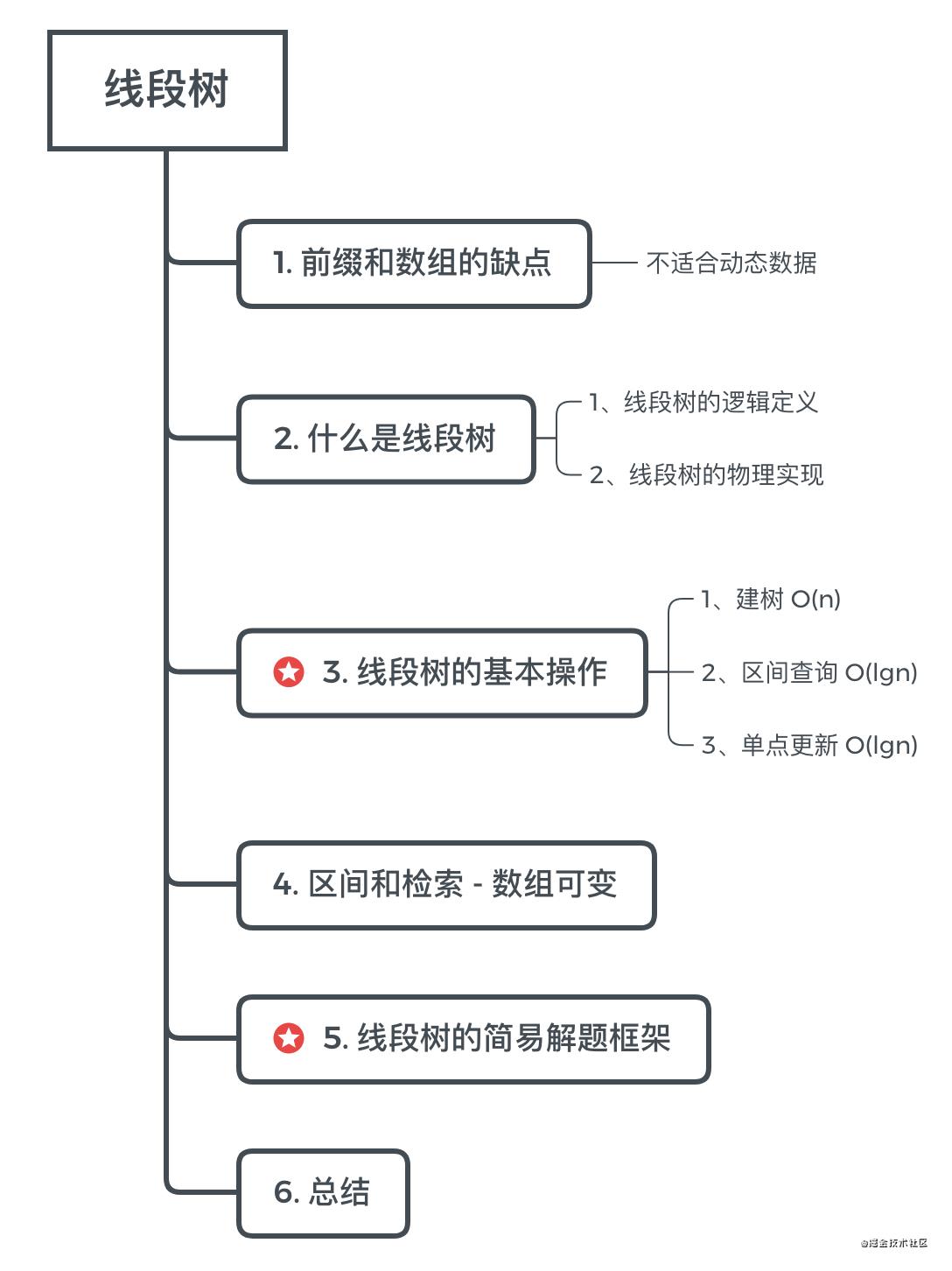
前置知识
这篇文章的内容会涉及以下前置 / 相关知识,贴心的我都帮你准备好了,请享用~
=
1. 前缀和数组的缺点
上一篇文章,我们使用了「前缀和 + 差分」技巧解决了 303. 区域和检索 - 数组不可变 【题解】 。简单来说,我们开辟了一个前缀和数组,存储「元素所有前驱节点的和」。利用这个前缀和数组,可以很快计算出区间 [i, j] 的和: nums[i,j]=preSum[j+1]−preSum[i]nums[i, j] = preSum[j + 1] - preSum[i]nums[i,j]=preSum[j+1]−preSum[i]
参考代码:
class NumArray(nums: IntArray) {
private val sum = IntArray(nums.size + 1) { 0 }
init {
for (index in nums.indices) {
sum[index + 1] = sum[index] + nums[index]
}
}
fun sumRange(i: Int, j: Int): Int {
return sum[j + 1] - sum[i] // 注意加一
}
}
复制代码此时,区间查询的时间复杂度是O(1)O(1)O(1),空间复杂度是O(n)O(n)O(n),总体不错。但是,正如前言提到的,目前我们只考虑了静态数据的场景,如果数据是可修改的会怎么样?
我们需要修正前缀和数组了,例如:将num[2]num[2]num[2]更新为 10,那么preSum[3,...,7]preSum[3,...,7]preSum[3,...,7] 都需要更新,这个更新操作的时间复杂度为O(n)O(n)O(n)。要是一次更新操作影响倒是不大,但如果更新操作很频繁,算法的均摊时间复杂度就劣化了。为了解决动态数据的场景,就出现了 “线段树” 这种数据结构,它和其他数据结构的复杂度对比如下表:
| 数据结构 | 构建结构 | 区间更新 | 区间查询 | 空间复杂度 |
|---|---|---|---|---|
| 遍历,不使用数据结构 | O(1) | O(1) | O(n) | O(1) |
| 前缀和数组 | O(n) | O(n) | O(1) | O(n) |
| 线段树 | O(n) | O(lgn) | O(lgn) | O(4*n)或O(2*n) |
| 树状数组 | O(n) | O(lgn) | O(lgn) | O(n) |
可以看到「前缀和数组」的优势是O(1)O(1)O(1)查询,但不适合动态数据的场景,而线段树似乎学会了中庸之道,线段树平衡了「区间查询」和「单点更新」两种操作的时间复杂度。它是怎么做到的呢?
2. 什么是线段树?
这是因为前缀和数组是线性逻辑结构,修改操作一定需要花费线性时间。为了使得修改操作优于线性时间,那么一定需要构建非线性逻辑结构。
2.1 线段树的逻辑定义
一般的二叉树节点上存储的是一个值,而线段树上的节点存储的是一个区间[L,R][L, R][L,R] 上的聚合信息(例如最大值 / 最小值 / 和),并且子节点的区间合并后正好等同于父节点的区间。例如,对于父节点的区间是 [L,R][L, R][L,R],那么左子节点的区间是 [L,(L+R)/2][L, (L+R)/2][L,(L+R)/2],右子节点的区间是 [(L+R)/2,R][(L+R)/2, R][(L+R)/2,R]。叶子节点也是一个区间,不过区间端点 L==RL == RL==R,是一个单点区间。
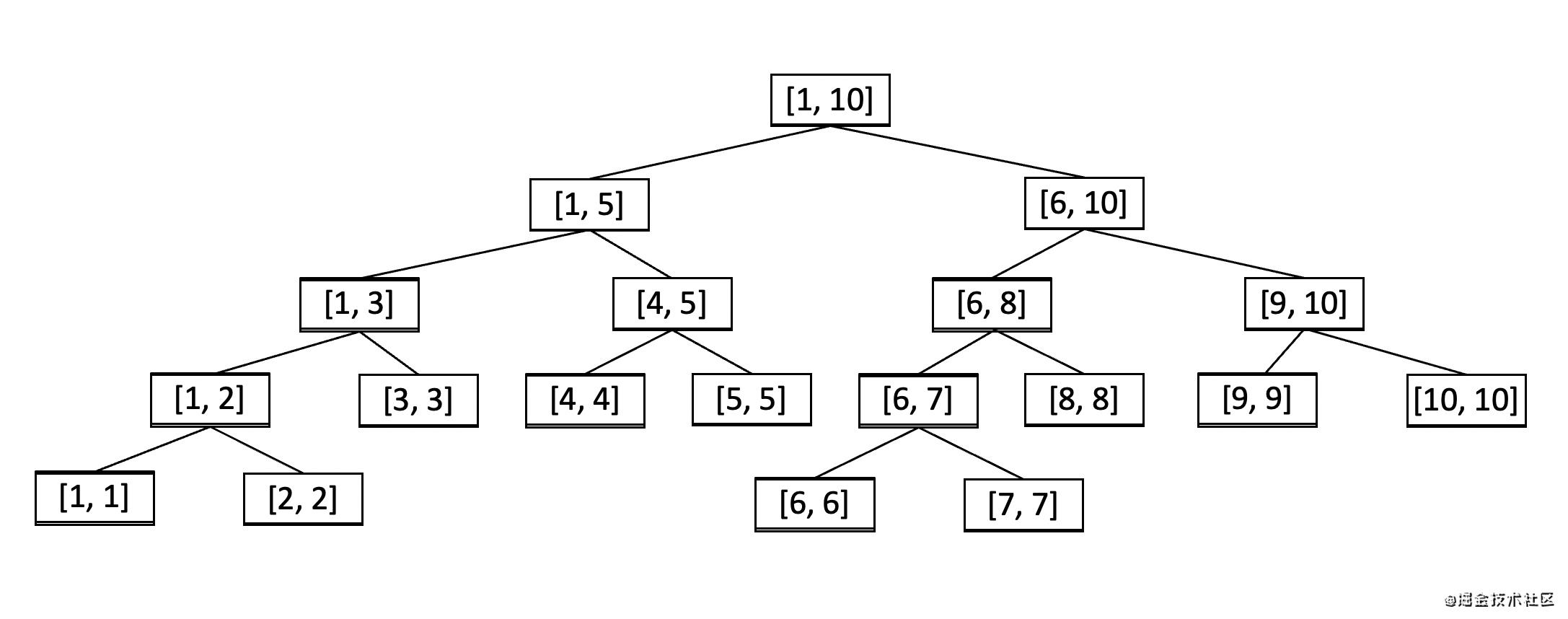
—— 图片引用自 www.jianshu.com/p/4d9da6745… —— yo1ooo 著
从线段树的逻辑定义可以看出:线段树(Segment Tree)本质上是一棵平衡二叉搜索树,也就是说它同时具备二叉搜索树和平衡二叉树的性质:
-
二叉搜索树:任意节点的左子树上的节点值都小于根节点的值,右子树上的节点值都大于根节点的值;
-
平衡二叉树(Balance Tree):任意节点的左右子树高度差不大于 1。
2.2 线段树的物理实现
通常,一个二叉树的物理实现可以基于数组,也可以基于链表。不过,因为线段树本身也是平衡二叉树,除了二叉树最后一层节点外,线段树的其它层是满的,所以采用数组的实现空间利用率更高。
那么,怎么实现一个基于数组的线段树呢?其实都是固定套路了:采用数组存储方式时,树的根节点可以分配在数组第 [0] 位,也可以分配在第 [1] 位,两种方式没有明显的区别,主要是计算子节点 / 父节点下标的公式有所不同:
根节点存储在第[0][0][0]位:
- 对于第[i][i][i]位上的节点,第[2∗i+1][2 * i +1][2∗i+1]位是左节点,第[2∗i+2][2 * i + 2][2∗i+2]位是右节点
- 对于第[i][i][i]位上的节点,第[(i−1)/2][(i-1) / 2][(i−1)/2]位是父节点
根节点存储在第[1][1][1]位(建议采用,在计算父节点时比较简洁):
- 第[0][0][0]位不存储,根节点存储在第[1][1][1]位
- 对于第[i][i][i]位上的节点,第[2∗i][2 * i][2∗i]位是左节点,第[2∗i+1][2 * i + 1][2∗i+1]位是右节点
- 对于第[i][i][i]位上的节点,第[i/2][i / 2][i/2]位是父节点
通用实现参考代码:
class SegmentTree<E>(
private val data: Array<E>,
private val merge: (e1: E?, e2: E?) -> E
) {
private val tree: Array<E?>
init {
// 开辟 4 * n 空间
tree = Array<Any?>(4 * data.size) { null } as Array<E?>
buildSegmentTree(0, 0, data.size - 1)
}
/**
* 左子节点的索引
*/
fun leftChildIndex(treeIndex: Int) = 2 * treeIndex + 1
/**
* 右子节点的索引
*/
fun rightChildIndex(treeIndex: Int) = 2 * treeIndex + 2
/**
* 建树
* @param treeIndex 当前线段树索引
* @param left 区间左端点
* @param right 区间右端点
*/
private fun buildSegmentTree(treeIndex: Int, left: Int, right: Int) {
// 见第 3 节
}
/**
* 取原始数据第 index 位元素
*/
fun get(index: Int): E {
if (index < 0 || index > data.size) {
throw IllegalArgumentException("Index is illegal.")
}
return data[index]
}
/**
* 区间查询
* @param left 区间左端点
* @param right 区间右端点
*/
fun query(left: Int, right: Int): E {
if (left < 0 || left >= data.size || right < 0 || right >= data.size || left > right) {
throw IllegalArgumentException("Index is illegal.");
}
// 见第 3 节
}
/**
* 单点更新
* @param index 数据索引
* @param value 新值
*/
fun set(index: Int, value: E) {
if (index < 0 || index >= data.size) {
throw IllegalArgumentException("Index is illegal.");
}
// 见第 3 节
}
}
复制代码其中 buildSegmentTree()、query()、update() 三个方法的实现我们在下一节讲。这里我们着重分析下 为什么线段树需要分配 4n4n4n 的空间?
todo
3. 线段树的基本操作
理解了线段树的逻辑定义和实现,这一节,我带你一步步实现线段树的三个基本操作 —— 建树 & 区间查询 & 更新。
3.1 建树
建树是利用原始数据构建出线段树的数据结构,我们采用的是 自顶向下 的构建方式,对于线段树上的每一个节点,我们先构建出它的左右子树,然后再根据左右两个子节点来构建当前节点。对于叶子节点(单点区间),只根据当前节点来构建。
参考代码:
init {
tree = Array<Any?>(4 * data.size) { null } as Array<E?>
buildSegmentTree(0, 0, data.size - 1)
}
/**
* 建树
* @param treeIndex 当前线段树索引
* @param treeLeft 节点区间左端点
* @param right treeRight 节点区间右端点
*/
private fun buildSegmentTree(treeIndex: Int, treeLeft: Int, treeRight: Int) {
if (treeLeft == treeRight) {
// 叶子节点
tree[treeIndex] = merge(data[treeLeft], null)
return
}
val mid = (treeLeft + treeRight) ushr 1
val leftChild = leftChildIndex(treeIndex)
val rightChild = rightChildIndex(treeIndex)
// 构建左子树
buildSegmentTree(leftChild, treeLeft, mid)
// 构建右子树
buildSegmentTree(rightChild, mid + 1, treeRight)
tree[treeIndex] = merge(tree[leftChild], tree[rightChild])
}
复制代码建树复杂度分析:
- 时间复杂度:O(n)O(n)O(n)
- 空间复杂度:O(4∗n)O(4 * n)O(4∗n) = O(n)O(n)O(n)
3.2 区间查询
区间查询是查询一段期望区间的结果,基本思路是递归查询子区间的结果,再通过合并子区间的结果来得到期望区间的结果。逻辑如下:
- 0、从根节点开始查找(根节点是整个区间),递归执行以下步骤:
- 1、如果查找范围正好等于节点区间范围,直接返回节点聚合数据;
- 2、如果查找范围正好落在左子树区间范围,那么递归地在左子树查找;
- 3、如果查找范围正好落在右子树区间范围,那么递归地在右子树查找;
- 4、如果查找范围横跨两棵子树,那么拆分为两次递归查找,查找完成后 合并 结果。
/**
* 区间查询
*
* @param left 区间左端点
* @param right 区间右端点
*/
fun query(left: Int, right: Int): E {
if (left < 0 || left >= data.size || right < 0 || right >= data.size || left > right) {
throw IllegalArgumentException("Index is illegal.");
}
return query(0, 0, data.size - 1, left, right) // 注意:取数据长度
}
/**
* 区间查询
*
* @param treeIndex 当前节点索引
* @param dataLeft 当前节点左区间
* @param dataRight 当前节点右区间
* @param left 区间左端点
* @param right 区间右端点
*/
private fun query(treeIndex: Int, dataLeft: Int, dataRight: Int, left: Int, right: Int): E {
if (dataLeft == left && dataRight == right) {
// 查询范围正好是线段树节点区间范围
return tree[treeIndex]!!
}
val mid = (dataLeft + dataRight) ushr 1
val leftChild = leftChildIndex(treeIndex)
val rightChild = rightChildIndex(treeIndex)
// 查询区间都在左子树
if (right <= mid) {
return query(leftChild, dataLeft, mid, left, right)
}
// 查询区间都在右子树
if (left >= mid + 1) {
return query(rightChild, mid + 1, dataRight, left, right)
}
// 查询区间横跨两棵子树
val leftResult = query(leftChild, dataLeft, mid, left, mid)
val rightResult = query(rightChild, mid + 1, dataRight, mid + 1, right)
return merge(leftResult, rightResult)
}
复制代码查询复杂度分析:
- 时间复杂度:取决于树的高度,为 O(lgn)O(lgn)O(lgn)
- 空间复杂度:O(1)O(1)O(1)
3.3 单点更新
单点更新就是在数据变化之后适当调整线段树的结构,基本思路是递归地修改子区间的结果,再通过合并子区间的结果来更新期望当前节点的结果。逻辑如下:
- 0、更新原数据(data 数组),然后从根节点开始更新值(根节点是整个区间),递归执行以下步骤:
- 1、如果是叶子节点(left = right),直接更新;
- 2、如果更新节点正好落在左子树区间范围,那么递归地在左子树更新;
- 3、如果更新节点正好落在右子树区间范围,那么递归地在右子树更新;
- 4、更新左右子树之后,再通过合并子树信息来更新当前节点。
/**
* 单点更新
*
* @param index 数据索引
* @param value 新值
*/
fun set(index: Int, value: E) {
if (index < 0 || index >= data.size) {
throw IllegalArgumentException("Index is illegal.");
}
data[index] = value
set(0, 0, data.size - 1, index, value) // 注意:取数据长度
}
private fun set(treeIndex: Int, dataLeft: Int, dataRight: Int, index: Int, value: E) {
if (dataLeft == dataRight) {
// 叶子节点
tree[treeIndex] = value
return
}
// 先更新左右子树,再更新当前节点
val mid = (dataLeft + dataRight) ushr 1
val leftChild = leftChildIndex(treeIndex)
val rightChild = rightChildIndex(treeIndex)
if (index <= mid) {
set(leftChild, dataLeft, mid, index, value)
} else if (index >= mid + 1) {
set(rightChild, mid + 1, dataRight, index, value)
}
tree[treeIndex] = merge(tree[leftChild], tree[rightChild])
}
复制代码更新复杂度分析:
- 时间复杂度:取决于树的高度,为 O(lgn)O(lgn)O(lgn)
- 空间复杂度:O(1)O(1)O(1)
到这里,我们的线段树数据结构就实现完成了,完整代码如下:SegmentTree
4. 典型例题 · 区域和检索 - 数组可变
给你一个数组 nums ,请你完成两类查询,其中一类查询要求更新数组下标对应的值,另一类查询要求返回数组中某个范围内元素的总和。
class NumArray(nums: IntArray) {
fun update(index: Int, `val`: Int) {
}
fun sumRange(left: Int, right: Int): Int {
}
}
这道题与 【题 303】 是差不多的,区别在于数组是否可变,属于 动态数据 的场景。上一节,我们已经实现了一个通用的线段树数据结构,我们直接使用就好啦。
参考代码:
class NumArray(nums: IntArray) {
private val segmentTree = SegmentTree<Int>(nums.toTypedArray()) { e1: Int?, e2: Int? ->
if (null == e1)
e2!!
else if (null == e2)
e1
else
e1 + e2
}
fun update(index: Int, `val`: Int) {
segmentTree.set(index, `val`)
}
fun sumRange(left: Int, right: Int): Int {
return segmentTree.query(left, right)
}
}有点东西~~没几行代码就搞定了,运行结果也比采用前缀树的方法优秀更多。但是单纯从做题的角度,如果每做一道题都要编写这么一大串 SegmentTree 代码,似乎就太蛋疼了。有没有别的变通方法呢?
5. 线段树的解题框架
定义 SegmentTree 数据结构太花力气,这一节,我们来讨论一种不需要定义 SegmentTree 的通用解题框架。这个解法还是很巧妙的,它虽然不严格满足线段树的定义(不是二叉搜索树,但依然是平衡二叉树),但是实现更简单。
参考代码:
class NumArray(nums: IntArray) {
private val n = nums.size
private val tree = IntArray(2 * n) { 0 } // 注意:线段树大小为 2 * n
init {
// 构建叶子节点
for (index in n until 2 * n) {
tree[index] = nums[index - n]
}
// 依次构建父节点
for (index in n - 1 downTo 0) {
tree[index] = tree[index * 2] + tree[index * 2 + 1]
}
}
fun update(index: Int, `val`: Int) {
// 1、先直接更新对应的叶子节点
var treeIndex = index + n
tree[treeIndex] = `val`
while (treeIndex > 0) {
// 2、循环更新父节点,根据当前节点是偶数还是奇数,判断选择哪两个节点来合并为父节点
val left = if (0 == treeIndex % 2) treeIndex else treeIndex - 1
val right = if (0 == treeIndex % 2) treeIndex + 1 else treeIndex
tree[treeIndex / 2] = tree[left] + tree[right]
treeIndex /= 2
}
}
fun sumRange(i: Int, j: Int): Int {
var sum = 0
var left = i + n
var right = j + n
while (left <= right) {
if (1 == left % 2) {
sum += tree[left]
left++
}
if (0 == right % 2) {
sum += tree[right]
right--
}
left /= 2
right /= 2
}
return sum
}
}这种实现的优点是只需要 2 * n 空间,而不需要 4 * n 空间下面解释下代码。代码主要由三个部分组成:
5.1 建树
构建线段树需要初始化一个 2∗n2*n2∗n 空间的数组,采用 自底向上 的方式来构建整棵线段树。首先,构建叶子节点,叶子节点的位于数组区间 [n,2n−1][n,2n -1][n,2n−1],随后再根据子节点的结果来构建父节点(下标为indexindexindex的节点,左子节点下标:2∗index2*index2∗index,右子节点下标:2∗index+12*index+12∗index+1)。参考以下示意图:

5.2 区间查询
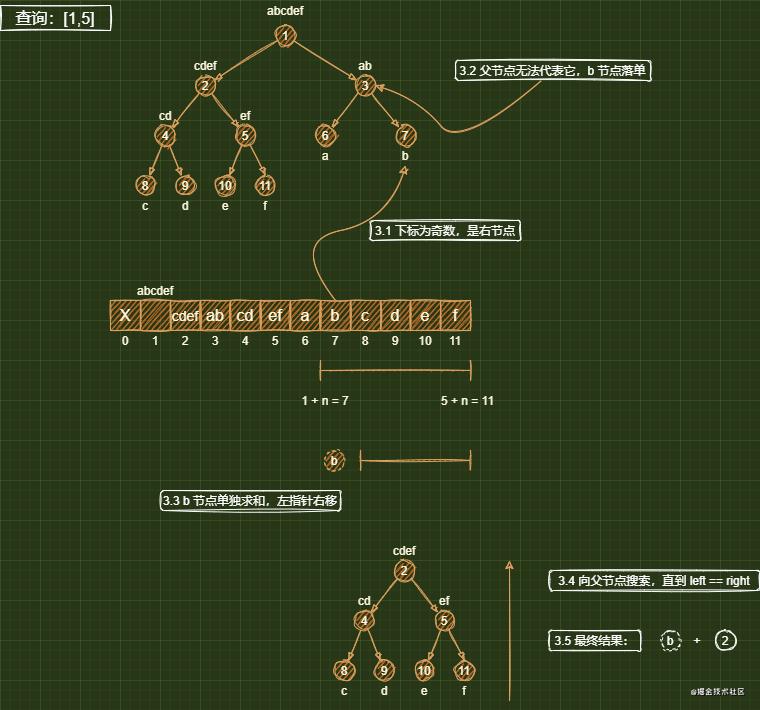
区间查询是查询一段期望区间的结果,相对于常规方法构造的线段树,这种线段树的区间查询过程相对较难理解。基本思路是递归地寻找能够代表该区间的节点。逻辑如下:
-
1、一开始的区间查询等同于线段树数组 [n,2n−1][n,2n-1][n,2n−1] 之间的若干个叶子节点 [left,right][left,right][left,right] 的合并,我们需要向上一层寻找能够代表这些节点的父节点;
-
2、对于节点 indexindexindex,它的左子节点下标:2∗index2*index2∗index,右子节点下标:2∗index+12*index+12∗index+1,这意味着所有左子节点下标是偶数,所有右子节点下标是奇数;
-
3、left/=2left /= 2left/=2和right/=2right /= 2right/=2则是寻找父节点,如果 leftleftleft 指针是奇数,那么 leftleftleft 指针节点一定是一个右节点,此时 left/2left/2left/2 节点就无法直接代表 leftleftleft 指针节点,于是只能单独加上这个 “落单” 的节点。同理,如果 rightrightright 指针是偶数,那么 righttrighttrightt 指针节点一定是一个左节点,,此时 right/2right /2right/2 节点就无法直接代表 rightright right 指针节点,于是只能单独加上这个 “落单” 的节点;
-
4、最后循环退出前left==rightleft == rightleft==right,说明当前节点的区间(去除 “落单” 的节点)正好是所求的区间,直接加上。并且下一躺循环leftleftleft一定大于rightrightright,跳出循环。
5.3 单点更新
单点更新就是在数据变化之后适当调整线段树的结构,基本思路是:先更新目标位置对应的节点,递归地更新父节点。需要注意根据当前节点的索引是偶数或奇数,来确定选择哪两个节点来合并为父节点。
例如,更新的节点是 “a” 节点,它在线段树数组索引 index 是偶数(下标为 6),那么它的父节点是 “ab” 节点需要通过合并 tree[index] + tree[index+1] 来获得的。

6. 总结
- 前缀和数组与线段树都适用与区间查询问题,前者在数据更新频繁时整体性能会下降,后者平衡了更新与查询两者的时间复杂度,复杂度都是O(lgn)O(lgn)O(lgn);
- 从解题的角度,常规的构建线段树的方法太复杂,可以采用反常规的线段树构建方式,代码会更加简洁,空间复杂度也更优秀;
- 除了线段树,你还知道什么类似的数据结构擅长于区间查询和单点更新吗?
7. 最后
关于面试题,我整理了一份包含初中高三个等级的面试题PDF文档,里面较为详细地总结了一些面试知识点,以及相关面试题的答案,需要的同学可以点击:免费获得!!!

同时除开这份面试题,以前整理的文档也全部分享给大家

以上面试文档全部免费分享给大家:点击这里免费获得!!!
以上是关于面试被问到线段树,已经这么卷了吗?的主要内容,如果未能解决你的问题,请参考以下文章
面试腾讯,字节跳动,华为90%会被问到的HashMap!你会了吗?
面试腾讯,字节跳动,华为90%会被问到的HashMap!你会了吗?