20行Python代码爬取2W多条音频文件素材内附源码+详细解析新媒体创作必备
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20行Python代码爬取2W多条音频文件素材内附源码+详细解析新媒体创作必备相关的知识,希望对你有一定的参考价值。
大家好,我是辣条。
今天的内容稍显简单,不过对于新媒体创作的朋友们还是很有帮助的,你能用上的话记得给辣条三连!
爬取目标
网站:站长素材
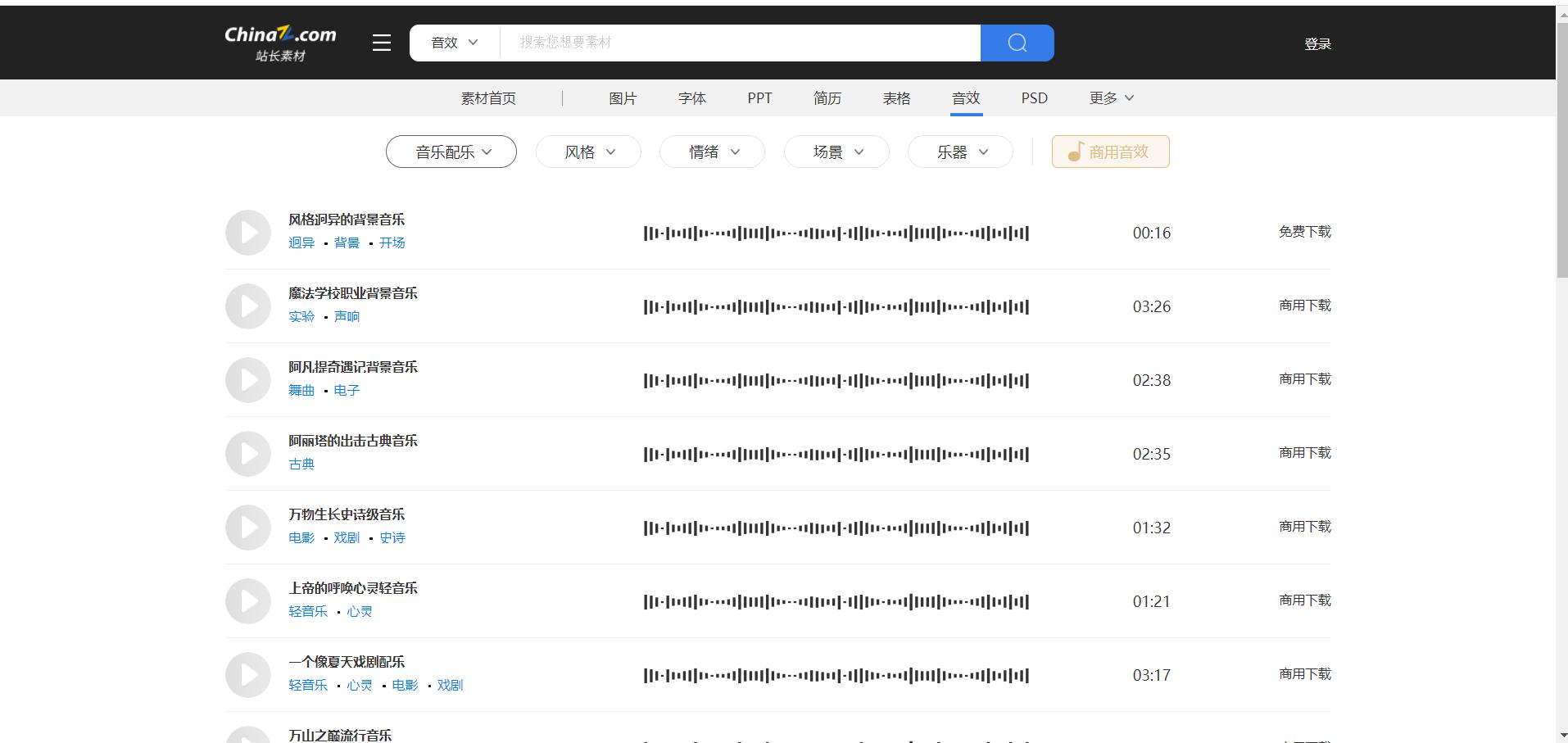
工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,lxml
重点学习内容
1.requests的网络请求应用
2.获取全部音频的网络地址
3.设置数据保存文件
项目思路解析
请求首页数据 通过修改url的值来改变数据 获取首页数据信息
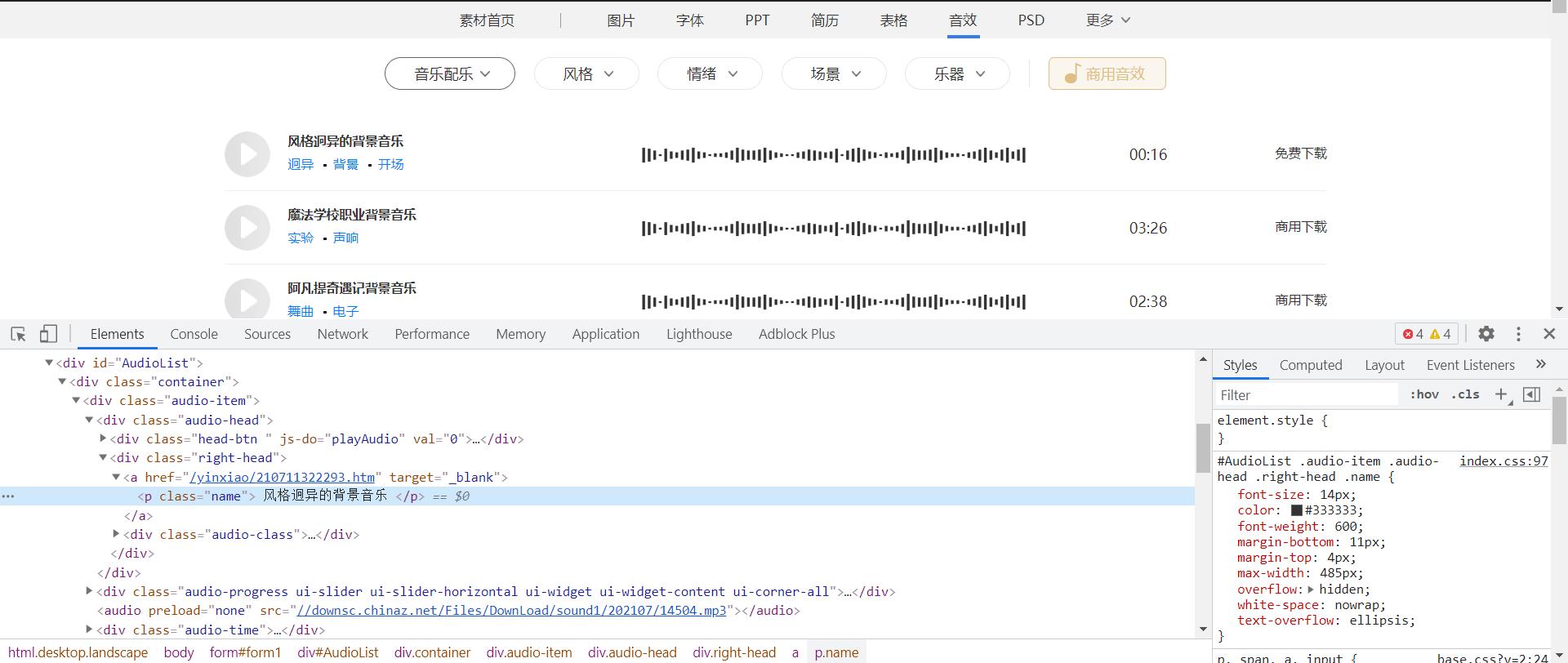
获取到网页源代码 通过xpath方式提取出对应的音乐播放地址 提取出对应音频标题
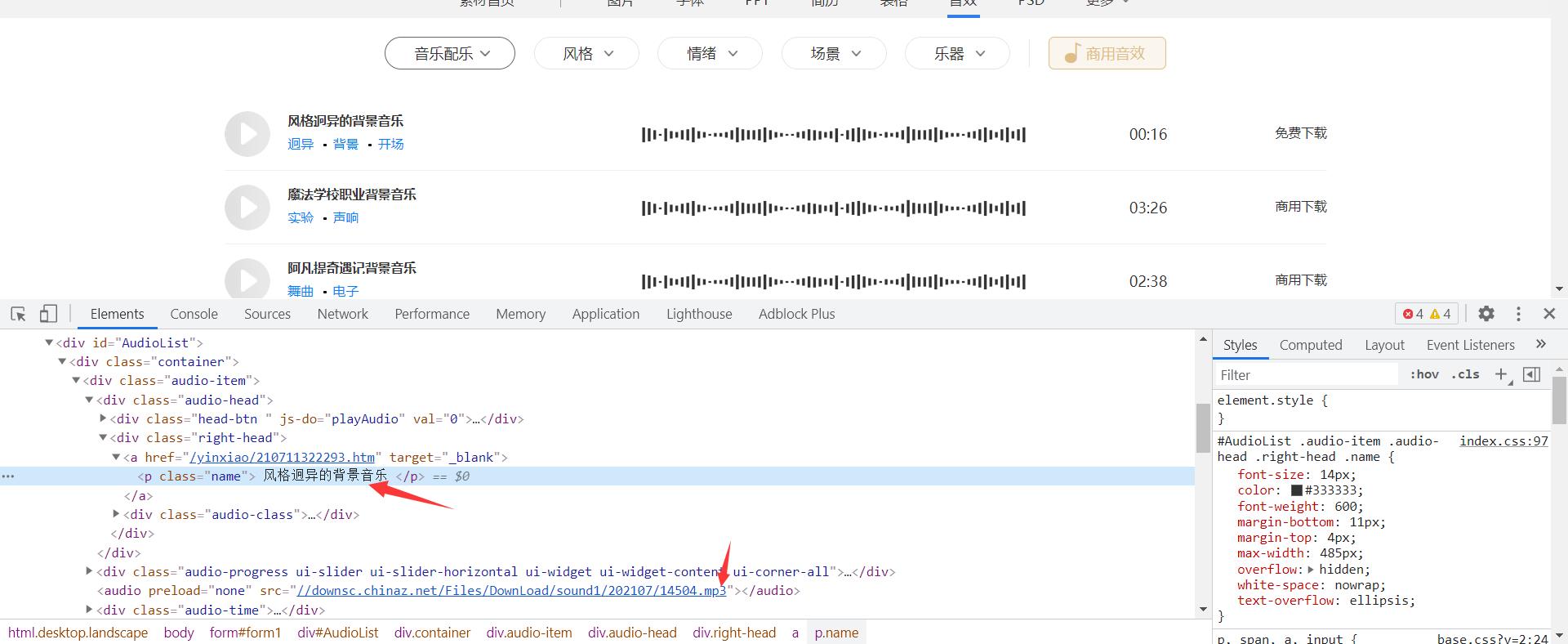
保存对应音频数据信息
简易源码分享
import requests
from lxml import etree
for page in range(1, 2):
url = 'http://sc.chinaz.com/yinxiao/index_{}.html'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers).text
html_data = etree.HTML(response)
div_list = html_data.xpath('//div[@class="audio-item"]')
for div in div_list:
new_url = div.xpath('./audio/@src')[0]
title = div.xpath('.//p[@class="name"]/text()')[0].strip()
print(new_url, title)
res = requests.get(url=new_url, headers=headers).content
filename = '音效/' + title + '.mp3'
with open(filename, 'wb') as f:
f.write(res)
print("下载完毕{}".format(title))
辣条建立了一个小白Python学习交流扣群383855172【广告、大佬勿扰】
以上是关于20行Python代码爬取2W多条音频文件素材内附源码+详细解析新媒体创作必备的主要内容,如果未能解决你的问题,请参考以下文章