火爆 GitHub!这个图像分割神器开源了
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了火爆 GitHub!这个图像分割神器开源了相关的知识,希望对你有一定的参考价值。
最近全球各大新势力造车公司简直不能再火!小编看着蹭蹭飙升的股价实在是眼红的不要不要的。而懂行的人都知道,以特斯拉为首,各大公司都采用计算机视觉作为自动驾驶的技术底座,而其中正是通过图像分割技术,汽车才能分清楚哪里是路,哪里是人。
那图像分割重不重要还需要我强调么?而今天我要给大家介绍的这个开源套件,就涵盖业界最前沿的图像分割算法,并效果超群,这就是 PaddleSeg!!OMG,还在等什么?!盘他!盘他!盘他!

在如期举行的全球计算机视觉顶会 CVPR2021 上,PaddleSeg 再次绽放高光。其中 AutoNUE 挑战赛是近年来自动驾驶场景理解领域极具影响力的一场赛事,非常考验参赛者在非结构化环境中的语义分割算法能力。百度 PaddleSeg 团队最终击败其余参赛队伍,在 Level 1, Level 2, Level 3 三项测试指标上均以第一名的成绩摘获冠军。

着急的小伙伴可以直接去看比赛详情:
https://bj.bcebos.com/paddleseg/docs/autonue21_presentation_PaddleSeg.pdf
那么 PaddleSeg 到底是个啥呢?小编去GitHub 上去扒了一下官方的解释:
PaddleSeg 是基于飞桨开发的端到端图像分割开发套件,涵盖了高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,帮助开发者完成从训练到部署的全流程图像分割应用。下面就给大家讲讲 PaddleSeg 的特点和近期更新的内容:
- 全新升级了人像分割功能,提供了 web 端超轻量模型部署方案;
- 推出了精细化的分割解决方案 PaddleSeg-Matting;
- 开源了全景分割算法 Panoptic-DeepLab,丰富了模型种类;
- 发布了交互式分割的智能标注工具 EISeg。极大的提升了标注效率。

Web 视频会议

Matting
全景分割
交互式分割
提供了产业级的部署方式。如今又增加了这么多的新功能。可以说 PaddleSeg 已经可以全方位、立体式地满足开发者各个维度的需求。不得不大说一声:、

这么好的产品,还不快上车?
上车地址:
https://github.com/PaddlePaddle/PaddleSeg
产业级人像分割方案PPSeg
人像分割是图像分割领域非常常见的应用,在实际应用过程中人像的数据集来源多种多样,数据可能来源于手机、相机、监控等,图片尺寸可能是横屏、竖屏或者方屏。部署场景多种多样,有的应用在服务器端,有的应用在移动端,还有的应用在网页端。为此 PaddleSeg 团队推出了在大规模人像数据上训练的人像分割 PPSeg 模型,满足在服务端、移动端、Web 端(Paddle.js)多种使用场景的需求。
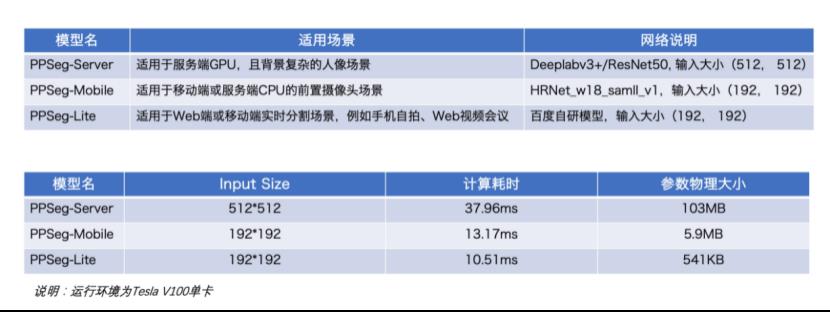
PPSeg 模型在产业中得到了广泛的应用。近期“百度视频会议”也上线了虚拟背景功能,支持用户在视频会议时进行背景切换。其中人像换背景模型采用 PaddleSeg 团队开发的 PPSeg 系列模型中的超轻量级模型。通过 Padddle.js 实现了在 web 端部署,直接利用浏览器的算力进行图像分割,分割效果受到一致好评。

产业级解决方案详解:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.2/contrib/HumanSeg
小伙伴们也可前去百度首页体验百度视频会议,直观体验一下 PaddleSeg 和 Paddle.js 为大家提供的人像分割功能。
精细化的分割解决方案 PaddleSeg-Matting
随着分割技术的发展,人们对分割的精细化的要求也越来越高。比如在一些影视行业,绿幕作为拍摄的换背景常用的工作,但目标不在绿幕前拍摄,是否还能达到很好的背景分割功能呢?
答案是:能!
最近 PaddleSeg 团队开源的精细化分割解决方案 PaddleSeg-Matting 就很好的解决了这个问题。将目标的发丝实现了精准的分割。

PaddleSeg 通过内建 trimap 生成机制实现 alpha 预测,无需任何辅助信息的输入即可完成预测,极大减少了人工成本。通过共享 encoder 权重减少网络的参数量,并在 decoder 阶段利用 attention module 实现 trimap 信息流对 alpha 预测的指导。然后利用 error map 提取错估区域的 patch,通过 refinement 子网络进行 refine 得到最终的 alpha。

交互式分割智能标注工具
业界对于人工智能有这么一句话:“深度学习有多智能、背后就有多少人工”。这句话直接说出了深度学习从业者心中的痛处,毕竟模型的好坏数据占据着很大的因素,但是数据的标注成本却让很多从业的小伙伴们感到头疼。
为此 PaddleSeg 团队重磅推出的交互式分割智能标注软件EISeg 那具体什么是交互式分割呢?通过下面的动态图来了解一下。


不难发现,交互式分割通过一系列的绿色点(正点)和红色点(负点)实现了对目标对象的边缘分割,交互式分割主要的应用方向是图像编辑和半自动标注,可以应用于精细化标注,抠图,辅助图像后期处理(例如 PS)等场景。
PaddleSeg 团队联合 PaddleCV-SIG 成员基于 RITM 算法,推出了业界首个高性能的交互式分割工具 EISeg,我们支持对 RITM 模型的训练、预测及交互的全流程。PaddleSeg 交互式分割模型不仅仅支持从头训练强大的通用场景模型,还支持对特定场景数据进行 Finetune。我们利用百度自建人像数据集对模型 Finetune,得到预测速度快,精度高,交互点少的人像交互式分割模型。

软件提供多种安装方式,支持用户使用 pip 和 conda 安装,另外 windows 下提供了可执行的 exe 文件,双击.exe 即可运行程序。
全景分割 Panoptic-DeepLab
全景分割是图像分割领域在近年来兴起的一个新领域,由 FAIR 与海德堡大学在2018年首次提出。
什么是全景分割呢?
图像的信息可以分为 thing 和 stuff,其中 thing 表示可数对象,例如车、动物等等,stuff 表示不可数对象,例如沙滩、天空等等。语义分割任务不关注图像中的是 stuff 还是 thing,只关注每个像素所属的语义类别,因此无法实现实例对象的区分。而实例分割关注的是 thing 的分割,将图像中的 thing 识别出来,区分出不同的实例个体以及相应的语义信息,对于 stuff 区域,则统一表示为背景。全景分割是融合了语义分割和实例分割的技术,对于 thing,识别出不同的实例个体以及对应的语义信息,对于 stuff,识别出对应的语义信息。

Panoptic DeepLab 首次以 bottem-up 和 single-shot 算法形式达到 state-of-the-art 性能,相比于 top-down 算法 Panoptic DeepLab 以简单的网络结构实现了精度、速度双超越,开创了全景分割算法新方向,目前 Cityscape 全景分割榜首即基于该算法。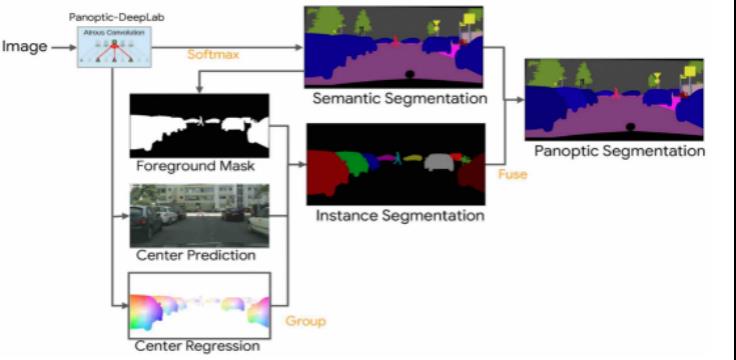
PaddleSeg 全貌
- 全明星算法阵容
20+全面领先同类框架的高精度语义分割算法,50+预训练模型新增全景分割算法,丰富了应用场景。提供了高精度的人像分割算法 HumanSeg,满足多端部署。
- 全产业链部署
不仅全面支持动态图开发,可以顺畅的完成动静转化;还从数据预处理、算法训练调优、压缩、多端部署等全流程、各环节顺畅打通,极大程度地提升了用户开发的易用性,加速了算法产业应用落地的速度。尤其是通过 Paddle.js 支持在 web 端部署,赋予了网页端部署的更多可能性。
你还在等什么?!如此用心研发的高水准产品,还不赶紧 Star 收藏上车!
以上是关于火爆 GitHub!这个图像分割神器开源了的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch图像分割模型——segmentation_models_pytorch库的使用
不用写代码神器!教你用4行命令轻松使用nnUNet训练自己的医学图像分割模型