将redis当做使用LRU算法的缓存来使用
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将redis当做使用LRU算法的缓存来使用相关的知识,希望对你有一定的参考价值。
http://www.redis.cn/topics/lru-cache.html
目录
当Redis被当做缓存来使用,当你新增数据时,让它自动地回收旧数据是件很方便的事情。这个行为在开发者社区非常有名,因为它是流行的memcached系统的默认行为。
LRU是Redis唯一支持的回收方法。本页面包括一些常规话题,Redis的maxmemory指令用于将可用内存限制成一个固定大小,还包括了Redis使用的LRU算法,这个实际上只是近似的LRU。
Maxmemory配置指令
maxmemory配置指令用于配置Redis存储数据时指定限制的内存大小。通过redis.conf可以设置该指令,或者之后使用CONFIG SET命令来进行运行时配置。
例如为了配置内存限制为100mb,以下的指令可以放在redis.conf文件中。
maxmemory 100mb
设置maxmemory为0代表没有内存限制。对于64位的系统这是个默认值,对于32位的系统默认内存限制为3GB。
当指定的内存限制大小达到时,需要选择不同的行为,也就是策略。 Redis可以仅仅对命令返回错误,这将使得内存被使用得更多,或者回收一些旧的数据来使得添加数据时可以避免内存限制。
回收策略
当maxmemory限制达到的时候Redis会使用的行为由 Redis的maxmemory-policy配置指令来进行配置。
以下的策略是可用的:
- noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略volatile-lru, volatile-random以及volatile-ttl就和noeviction 差不多了。
选择正确的回收策略是非常重要的,这取决于你的应用的访问模式,不过你可以在运行时进行相关的策略调整,并且监控缓存命中率和没命中的次数,通过RedisINFO命令输出以便调优。
一般的经验规则:
- 使用allkeys-lru策略:当你希望你的请求符合一个幂定律分布,也就是说,你希望部分的子集元素将比其它其它元素被访问的更多。如果你不确定选择什么,这是个很好的选择。.
- 使用allkeys-random:如果你是循环访问,所有的键被连续的扫描,或者你希望请求分布正常(所有元素被访问的概率都差不多)。
- 使用volatile-ttl:如果你想要通过创建缓存对象时设置TTL值,来决定哪些对象应该被过期。
allkeys-lru 和 volatile-random策略对于当你想要单一的实例实现缓存及持久化一些键时很有用。不过一般运行两个实例是解决这个问题的更好方法。
为了键设置过期时间也是需要消耗内存的,所以使用allkeys-lru这种策略更加高效,因为没有必要为键取设置过期时间当内存有压力时。
回收进程如何工作
理解回收进程如何工作是非常重要的:
- 一个客户端运行了新的命令,添加了新的数据。
- Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
- 一个新的命令被执行,等等。
- 所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
近似LRU算法
Redis的LRU算法并非完整的实现。这意味着Redis并没办法选择最佳候选来进行回收,也就是最久未被访问的键。相反它会尝试运行一个近似LRU的算法,通过对少量keys进行取样,然后回收其中一个最好的key(被访问时间较早的)。
不过从Redis 3.0算法已经改进为回收键的候选池子。这改善了算法的性能,使得更加近似真是的LRU算法的行为。
Redis LRU有个很重要的点,你通过调整每次回收时检查的采样数量,以实现调整算法的精度。这个参数可以通过以下的配置指令调整:
maxmemory-samples 5
Redis为什么不使用真实的LRU实现是因为这需要太多的内存。不过近似的LRU算法对于应用而言应该是等价的。使用真实的LRU算法与近似的算法可以通过下面的图像对比。
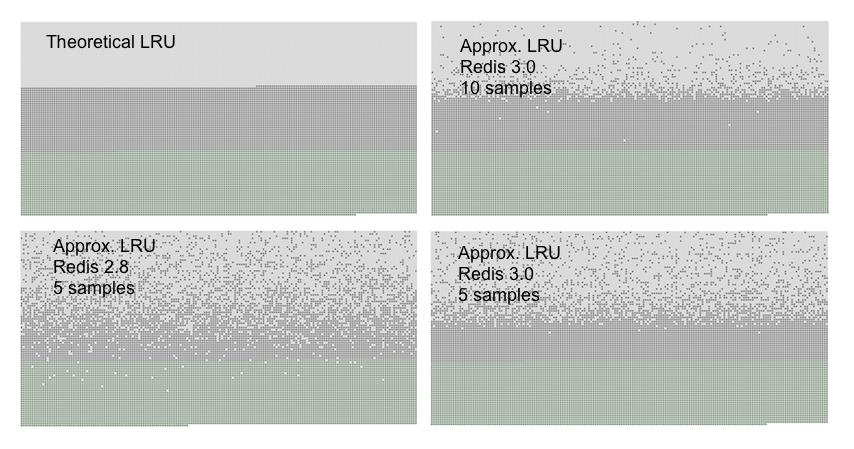
用于生成图像的Redis服务被填充了指定数量的键。这些键将被从头到尾访问,所以当使用LRU算法时第一个键是最佳的回收候选键。接着添加超过50%的键,用于强制旧键被回收。
你可以看到三种点在图片中, 形成了三种带.
- 浅灰色带是已经被回收的对象。
- 灰色带是没有被回收的对象。
- 绿色带是被添加的对象。
- 在LRU实现的理论中,我们希望的是,在旧键中的第一半将会过期。Redis的LRU算法则是概率的过期旧的键。
你可以看到,在都是五个采样的时候Redis 3.0比Redis 2.8要好,Redis2.8中在最后一次访问之间的大多数的对象依然保留着。使用10个采样大小的Redis 3.0的近似值已经非常接近理论的性能。
注意LRU只是个预测键将如何被访问的模型。另外,如果你的数据访问模式非常接近幂定律,大部分的访问将集中在一个键的集合中,LRU的近似算法将处理得很好。
在模拟实验的过程中,我们发现如果使用幂定律的访问模式,则真实的LRU算法和近似的Redis算法几乎没有差别。
当然你可以提升采样大小到10,消耗更多的CPU时间以实现更真实的LRU算法,同时查看下是否让你的缓存命中率有差别。
通过CONFIG SET maxmemory-samples 命令在生产环境上设置不同的采样大小是非常简单的。
以上是关于将redis当做使用LRU算法的缓存来使用的主要内容,如果未能解决你的问题,请参考以下文章