干货|SQL请求行为识别新功能上线,帮助解决异常SQL检测之大海捞针问题
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货|SQL请求行为识别新功能上线,帮助解决异常SQL检测之大海捞针问题相关的知识,希望对你有一定的参考价值。
简介: 对于异常SQL中存在的业务属性的相似性以及错综复杂的影响与被影响的关系,理清楚问题SQL与各种资源的异常现象的传播关系是具有挑战的。DAS团队仍然在如何找到异常SQL这个课题上继续进行了研究和探索,在探索的过程中我们提供了一个新的分析功能SQL请求行为识别帮助用户更好的定位SQL问题。
业务背景:
DAS(Database autonomy service)为上百万数据库实例的稳定运行保驾护航,其中精准定位数据库运行过程中的异常SQL是DAS最基本的功能。数据库90%以上的问题都来源于数据库的异常请求,无论是双十一的集团海量交易请求行为,还是用户业务变化的请求行为,每时每刻都影响着数据库的性能。自动驾驶汽车通过感知路况图像变化的行为来掌握车的方向,而自动驾驶数据库通过感知和识别用户请求行为来不断修复优化数据库的各种问题,为云数据库保驾护航。如何从海量数据库中的海量请求定位出不同数据库引擎不同场景的问题是多年以来困扰DBA的难题。在推荐领域,通过分析用户的行为习惯代替了机械式网页展示精准推荐给用户期望的文字/视频/产品,提升用户体验和产品转化率,同样下一代数据库自动驾驶平台也需要分析用户请求行为,用户开发业务行为,推荐出相应优化修复扩容等操作,提升自动驾驶数据库的效率,让数据库更快更稳更安全。所以从用户请求行为和业务行为出发,在海量数据库实例的海量请求中进行数据挖掘是一个非常值得深入研究的课题,同时也是数据库自动驾驶平台非常依赖的底层技术能力, 向上支撑DAS数据库自治服务各个场景的自治能力。
DAS这这些年提供了多个对SQL数据进行分析的L2功能包括:专业版SQL洞察,全量SQL,慢日志, 一键诊断, 锁分析,会话等。每一个功能沉淀了DBA在不同角度分析不同问题的方法,不同实例,不同业务诊断问题的方法略有不同。对于并不是很熟悉DB运维的用户来说,DAS在提供一个统一高效简单的方式去帮助用户去定位问题。我们结合SQL变慢的多指标特征,提出一种基于特征相似度匹配的方法 VLDB 2020 沉淀到自治中心功能当中, 但对于异常SQL中存在的业务属性的相似性以及错综复杂的影响与被影响的关系,理清楚问题SQL与各种资源的异常现象的传播关系是具有挑战的问题,DAS团队仍然在如何找到异常SQL这个课题上继续进行了研究和探索,在探索的过程中我们提供了一个新的分析功能SQL请求行为识别帮助用户更好的定位SQL问题。
问题描述:
以下图为例,实例CPU出现尖刺突增的现象,数据库有cpu打满潜在风险,当用户的请求量较少或者请求的SQL模式较少的时候,通过指标的排序筛选是很容易找到问题SQL的,但当用户的全量SQL模板超过上万甚至上亿条,用户通过当前DAS页面无法快速定位异常SQL,我们需要通过更多数据提供更高效的方式,来定位异常请求。
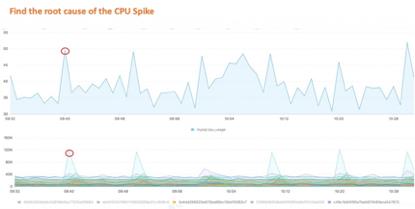
当用户使用DAS专业版SQL洞察的功能的时候,即使我们将全量SQL流水,压缩聚合成模板,模板的数量也是惊人的,我们可以看到大量特征趋势相近的模板。所以如果我们根据SQL的请求行为将模板进一步压缩,这样用户可以更好的定位异常SQL的问题
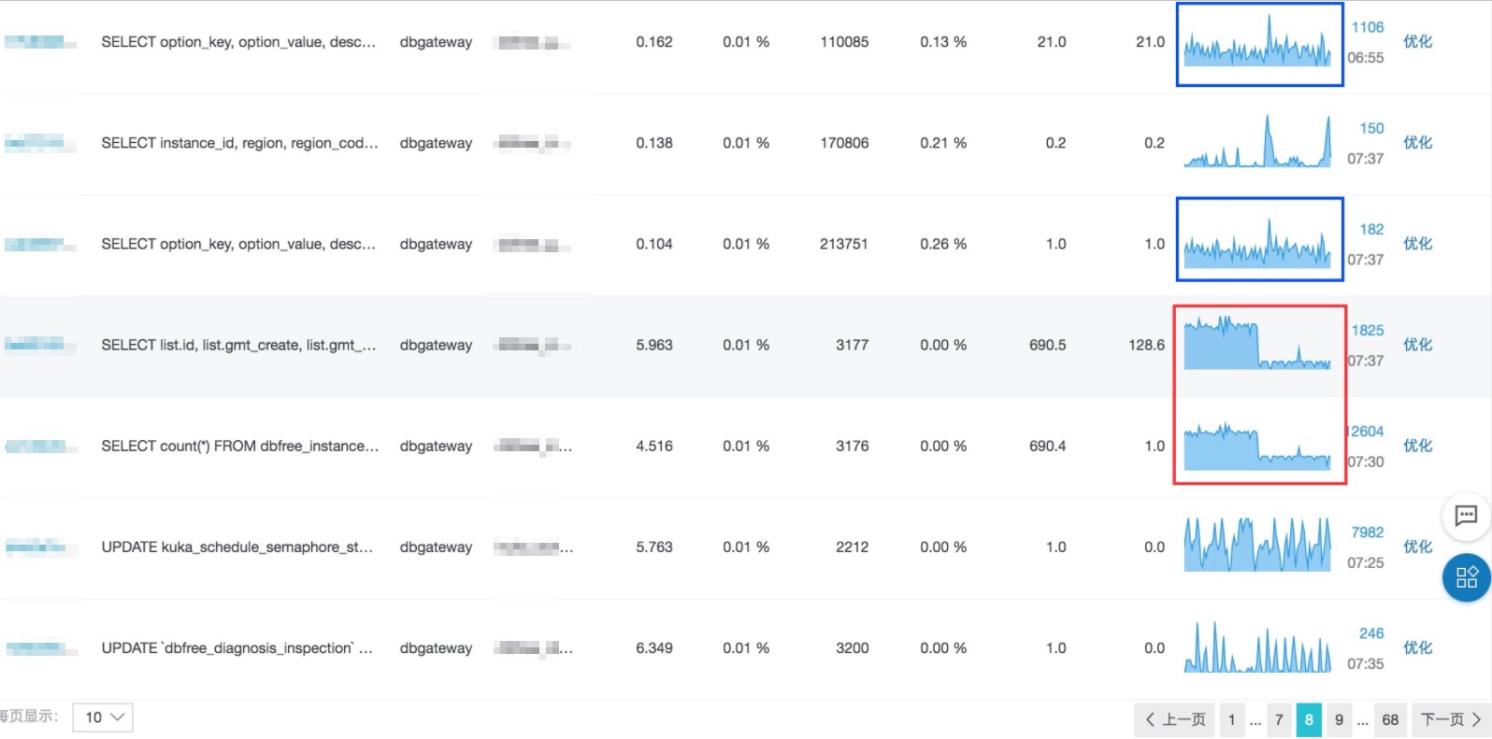
目前DAS产品功能和业界AWS Azure等其他产品都有初步的异常SQL定位能力,通过对采集的SQL数据在各个维度的排序,让用户自己定位数据库问题,这种方式对于80%以上简单的数据库问题是有效的,但是在复杂业务场景和DBA都很难定位的数据库问题效果是很差的。以阿里云内部管控的元数据库集群实例为例,今年平均每月发生10多次的CPU打满问题,全年发生数次性能相关的故障问题,但是每次的问题都不同,有时候DBA只能找到现象,难以快速定位问题根因。所以通过对用户请求行为的分析,会更好的迭代DAS数据库自治服务产品,解决我们复杂场景的数据库性能问题,提高整个数据库各个引擎的稳定性,易用性,效率。
业界产品:
AWS: RDS: Performance Insight
和目前DAS产品功能一样,采集的数据维度类似,通过Top N ranking的方式进行异常SQL定位,没有SQL请求行为分析功能
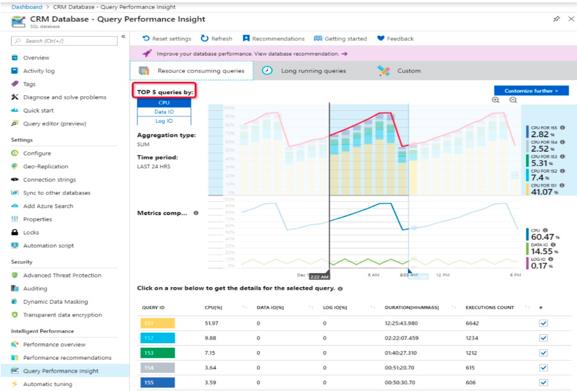
Azure: Query Performance Insight
通过取Top N的方式对SQL请求进行定位,可以定位到60%的明显问题,但是无法定位SQL请求复杂业务的数据库问题,没有SQL请求行为分析功能
腾讯云:DB Brain功能,和目前DAS现有功能类似,没有SQL请求行为分析功能
华为云:Database Admin Service,和目前DAS现有功能类似,没有SQL请求行为分析功能
挑战&难点
Challenges:
规模化挑战:
The sea of performance issues in the sea of queries from the sea of the databases
用户的业务请求丰富,如何从海量数据库实例中的海量请求中定位多种数据库引擎的性能问题。
监控诊断挑战:
7*24 real time anomaly detection => 7*24 root cause analysis in near real time
针对潜在的SQL请求导致的数据库性能问题,根因定位需要做到近实时问题定位。
繁杂的数据库异常现象:
异常指标通常与多条SQL请求有关,无法用单条SQL来解释异常原因且多个业务的SQL请求之间相互影响,关联的问题包括全表扫描/索引/锁问题/缓存击穿/内核问题等。多个问题在指标现象存在相似性和不同Motivations:
人工根因定位:
帮助DBA或用户解决性能问题,工单问题
帮助后端开发人员合理安排请求查询的流程,尽量让资源密集型请求从业务角度打散
帮助DBA找到不同请求之间在业务层面直接和间接的关系。
赋能自治服务:
更加精细化的限流: Limit anomalous SQL more meticulous
更加准确对workload预测: Forecast workload more accurate
更好的划分workload: Workload can be well-partitioned
更好的预估自治操作的资源收益: Estimate the SQL Resource Cost for autonomous actions
在第一时间解决潜在的性能问题:Crack the potential performance issue at the first place
DAS解决方案:
启发思路:
在很多后端应用开发的过程中,后端架构设计往往会保证接口的幂等性,例如项目中为了解决timeout问题,通常会引入重试机制,有时候会请求重复数据,消费消息有时候读重复数据之类的幂等性问题。例如多次insert或update可能会造成数据错误。
为了解决这些幂等性的方法,后端通常会使用这些方式例如 先select再insert,加悲观锁/乐观锁/分布式锁,或者根据状态机来管理有状态的业务。
支付场景状态机示例:
......
update `bill` set status=1 where id=520 and status=0;
下单行为 SQL A
update `bill` set status=2 where id=520 and status=1;
支付行为 SQL B
update `bill` set status=3 where id=520 and status=2;
取消订单行为 SQL C
.....
所以同一个业务流程会伴随这多个SQL请求,串行或并行,这就意味着这些SQL在执行趋势上存在这关联性,这种关联性和业务有关。当我们发现业务异常的时候,同时伴随这指标异常,所以当我们定位异常SQL的时候,同一业务下的SQL都会有异常现象,所以通过这些SQL的趋势特征我们可以将海量SQL数据进行通过算法进行聚类。所以我们想到通过分析SQL的同源性,站在业务视角来定位异常SQL,可以更有效率的定位异常SQL
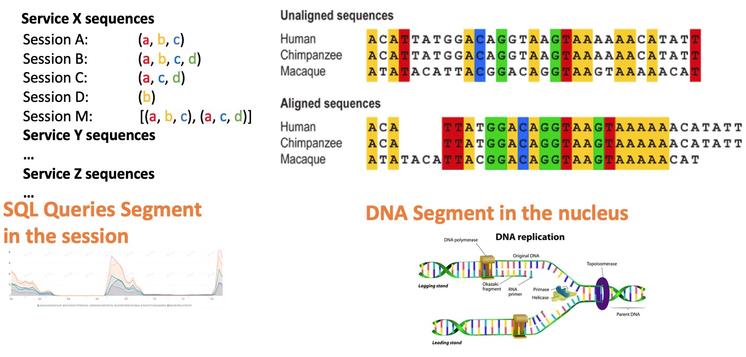
流程框架:
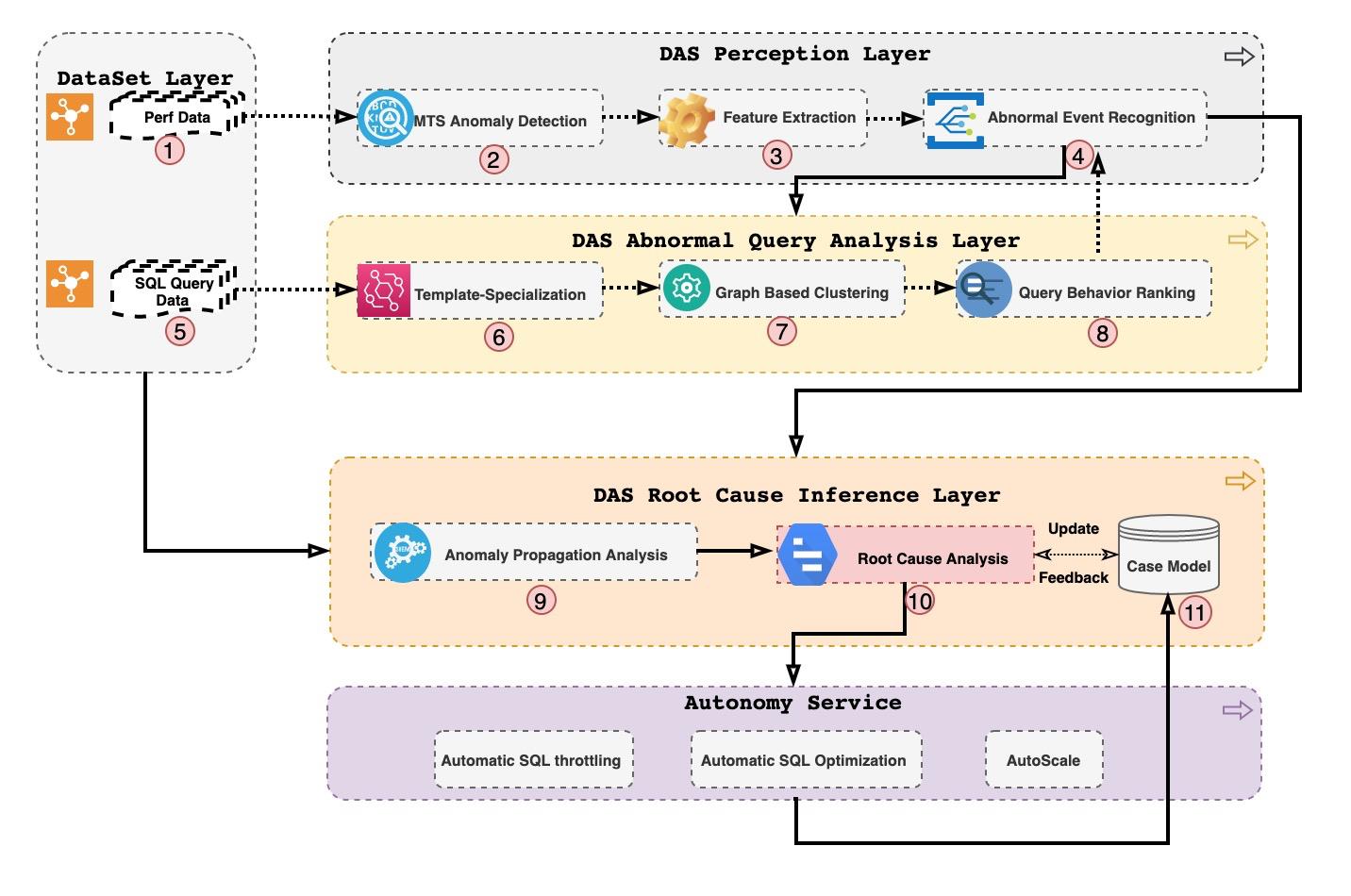
感知过程:
在诊断的过程中,DAS后端首先从统一数据层(DataSet Layer)请求,性能数据(Perf Data)和SQL请求数据(SQL Query Data),性能数据通过多指标异常检测(MTS Anomaly Detection)/特征提取(Feature Extraction)
异常请求定位过程:
示例:
模板集合X:{sql_a , sql_b, sql_c} ==> 影响了 mysql.cpu_usage 指标变化
==>sql 集合的影响程度 (推算cpu_time占比)
模板集合Y: {sql_i , sql_j, sql_k } ==> 影响了 mysql.active_session 指标变化
==> sql 集合的影响程度 (推算session占比)
感知层感知到时序指标异常后,通过全量SQL经过模板化处理后的数据,运用Graph Based的聚类方法,将海量的SQL按照请求行为的特征进行划分,最后根据聚合后请求行为的贡献度评分进行排序(Query Behavior Ranking),检测异常请求及其作用于性能指标的现象.
根因分析过程:
示例:
烂SQL模板 sql_i --> 造成了锁等待现象---> 影响了mysql.rows_lock_wait_time指标
--> 造成模板Y集合的SQL被阻塞 --> 造成session的突增
--> 被阻塞的Y集合中X集合中的CPU密集型SQL被阻塞 --> 造成了CPU突增
通过SQL解释了指标异常现象之后,还有很多故障问题我们无法精确定位,例如主备延迟,锁问题,OOM,内核问题等,这些问题可能导致了执行SQL的耗时增加,反过来,SQL也有可能产生这些问题的现象。
(Anomaly Propagation Analysis )帮助我们对这些现象之间,进行传播关系的分析。这里的分析我们通过时间先后关系结合我们历史案例数据综合进行比对, 最后将得出的异常传播链和整个DAS分析过程和建议并添加到后端的case库并更细case model。Case Model会根据反馈不断叠加调整匹配参数,给出更精准的建议。
基于请求行为识别的异常SQL定位案例:
定位会话(active_session)突增尖刺问题:
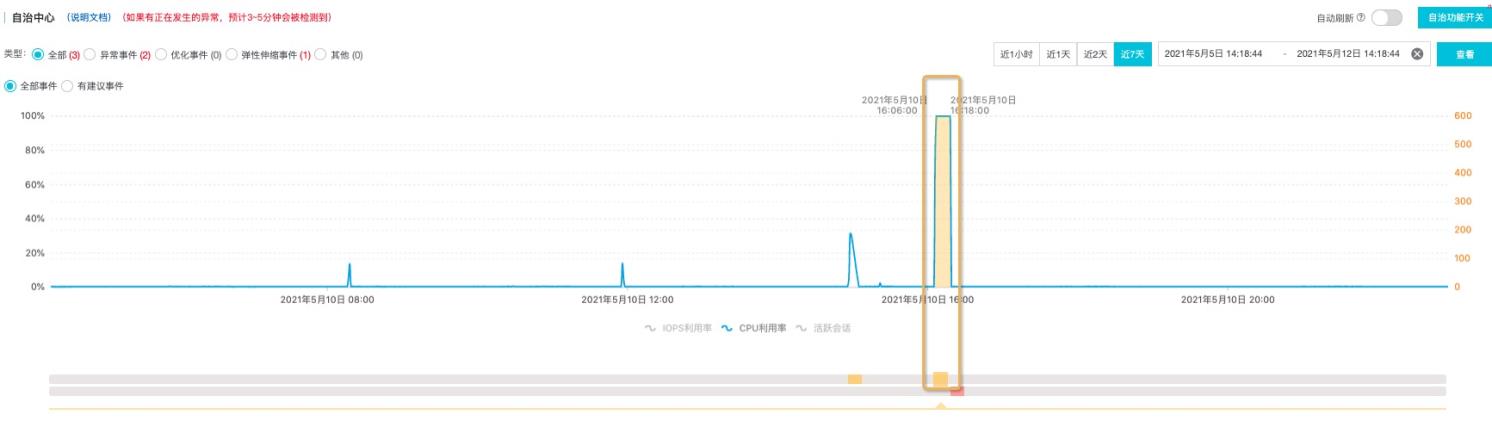
下图数据库实例活跃会话有异常的尖刺,这种尖刺持续时间过长,对一些敏感业务会有造成潜在的问题,我们想要定位尖刺的原因,首先DAS的实时异常检测可以检测出多指标的异常时间段。对于CPU,活跃会话异常的检测会透传出黄色异常事件的提示。
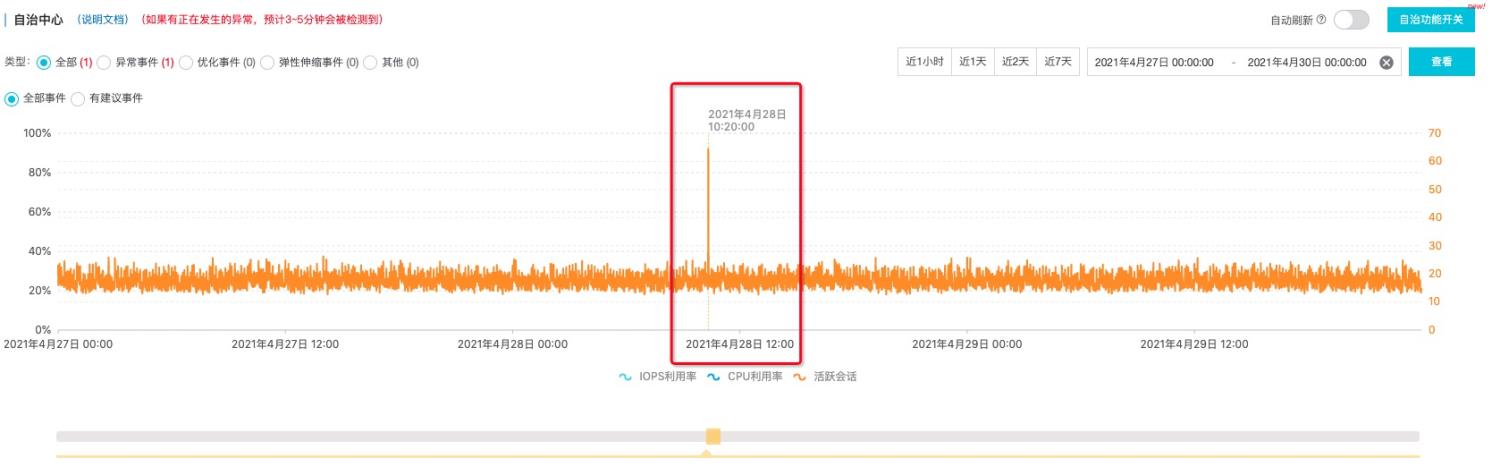
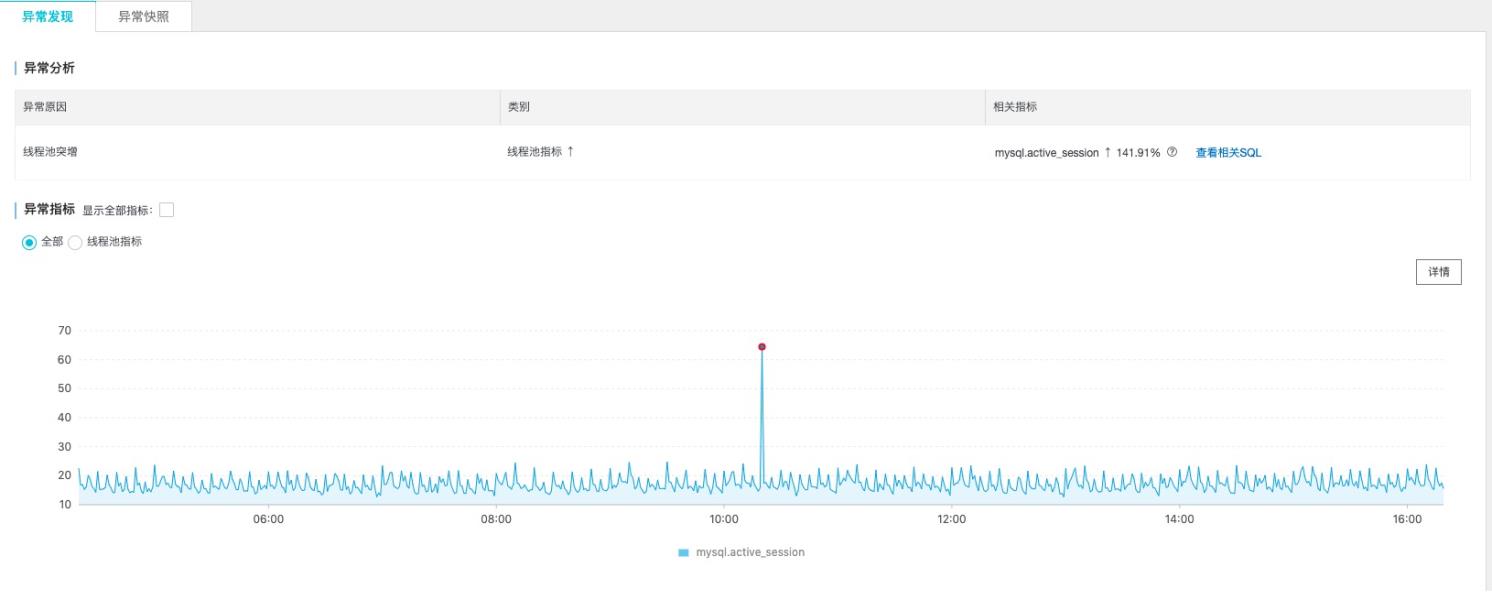
活跃会话通常和总执行耗时强相关,通过SQL请求行为分析选择对应指标,并点击分析
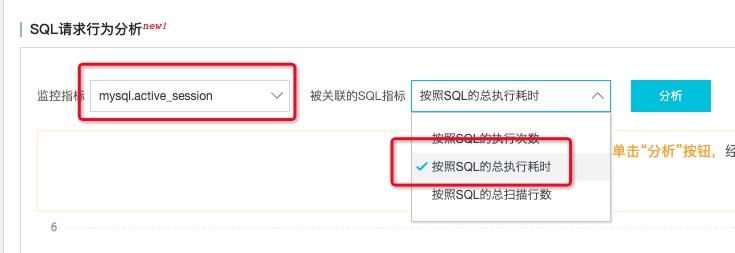
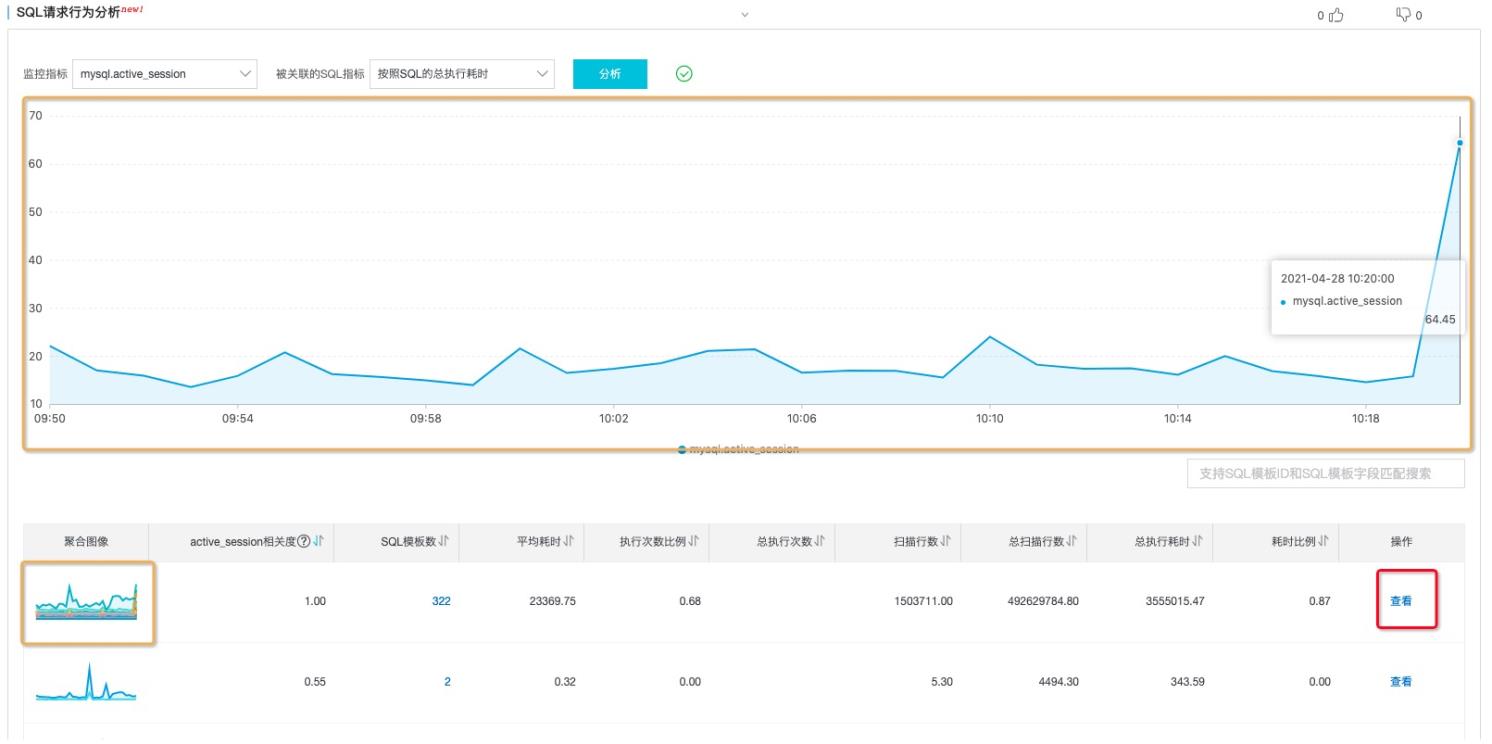
找到和会话相似的指标,并点击查看,按照总耗时排序,可以找到对会话异常"贡献"最大的异常SQL,
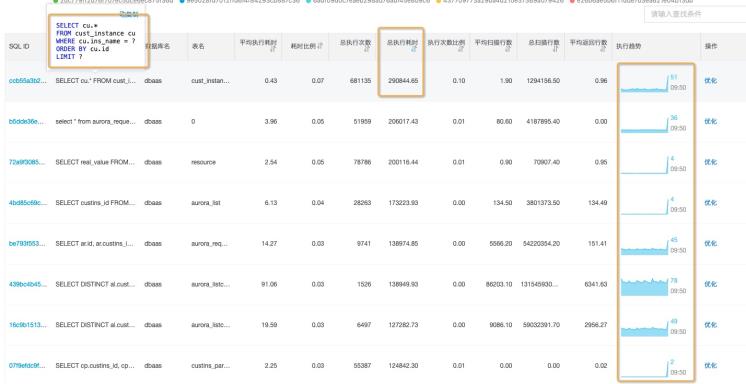
点击对应SQL_ID 查看详情,通过趋势行为ranking的结果,可以清楚的看到这个SQL变慢了和历史趋势相比变慢了。通过执行趋势可以看到异常趋势和历史趋势完全不同,且与活跃会话异常的趋势相吻合
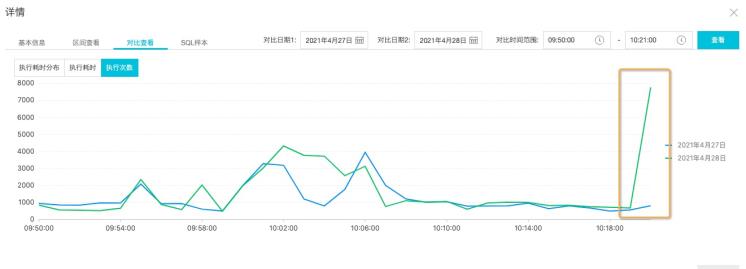

最终定位:这条SQL执行次数突增(从1000次执行超过8000多次),导致其他SQL执行耗时变慢,造成了活跃会话堆积产生了active_session指标突增现象
CPU打满(cpu_usage)突增问题:
下图数据库实例CPU被打满,
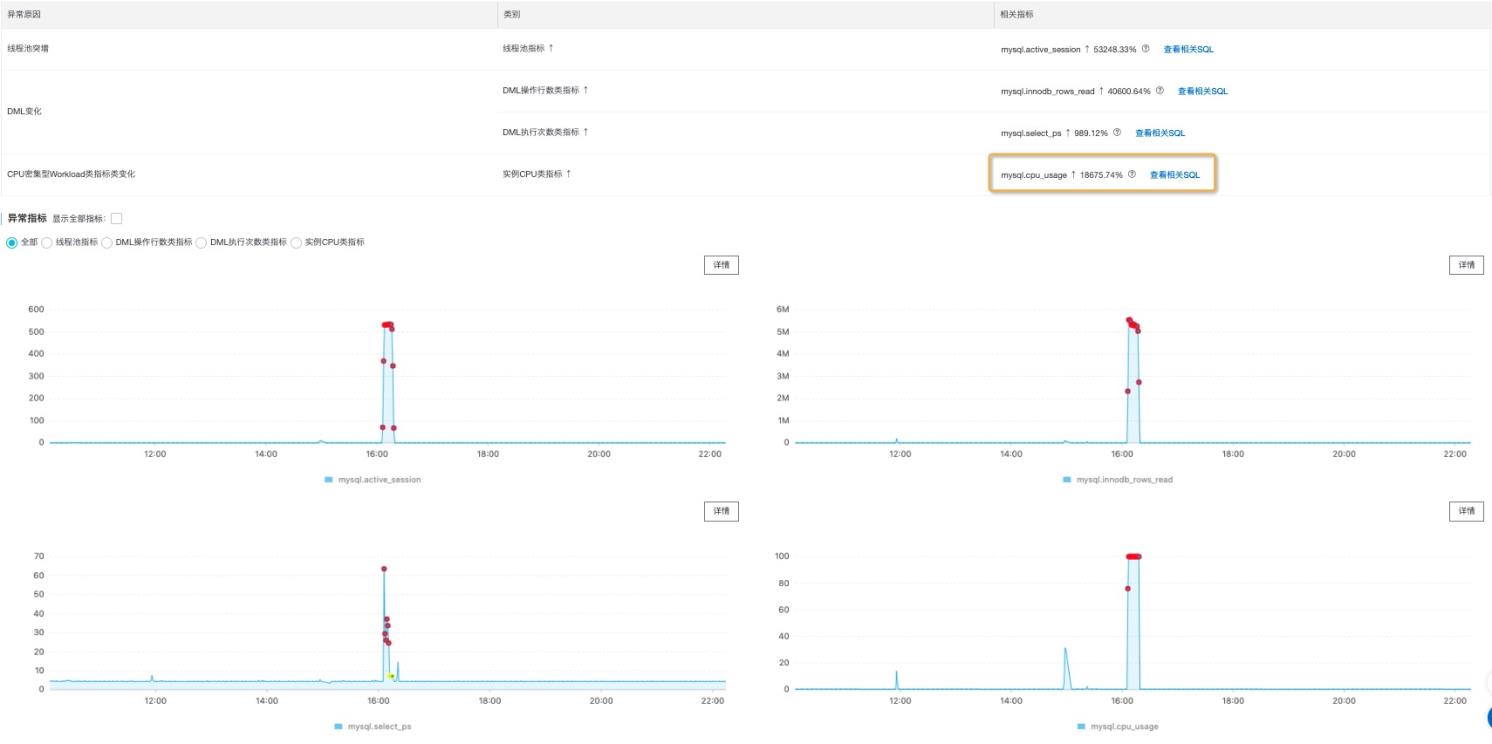
除了SQL设计CPU密集型计算诸如join,等比较昂贵的操作外,绝大部分情况,CPU和扫描行数成正相关,在SQL请求行为分析选择,cpu_usage和总扫描行数,

我们比较容易定位到和CPU关联的指标
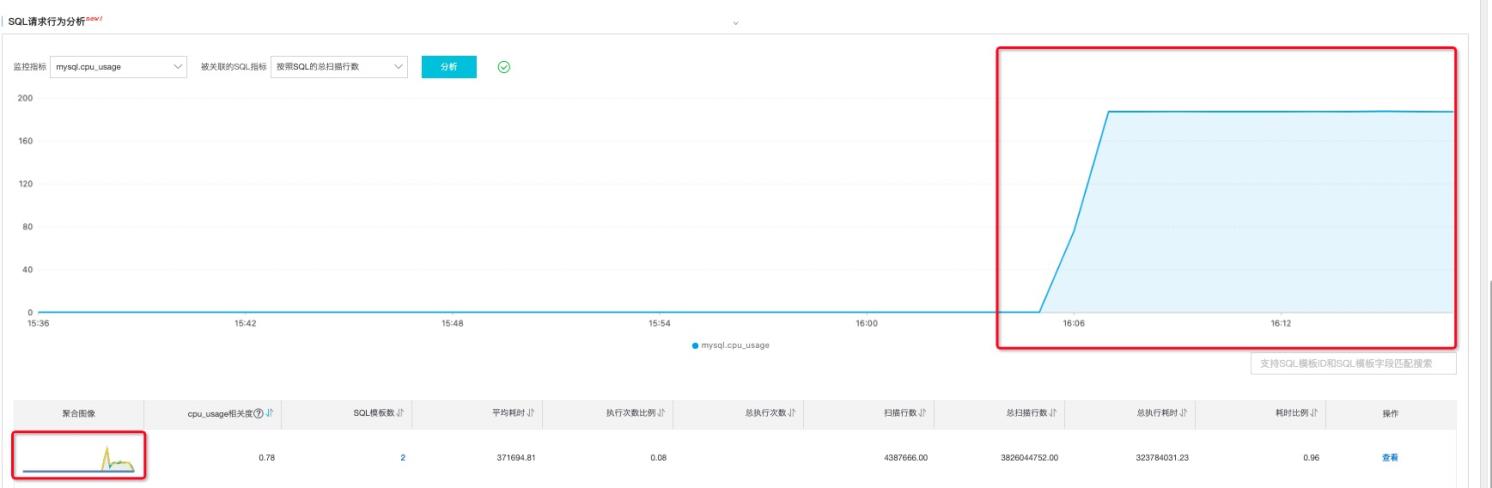
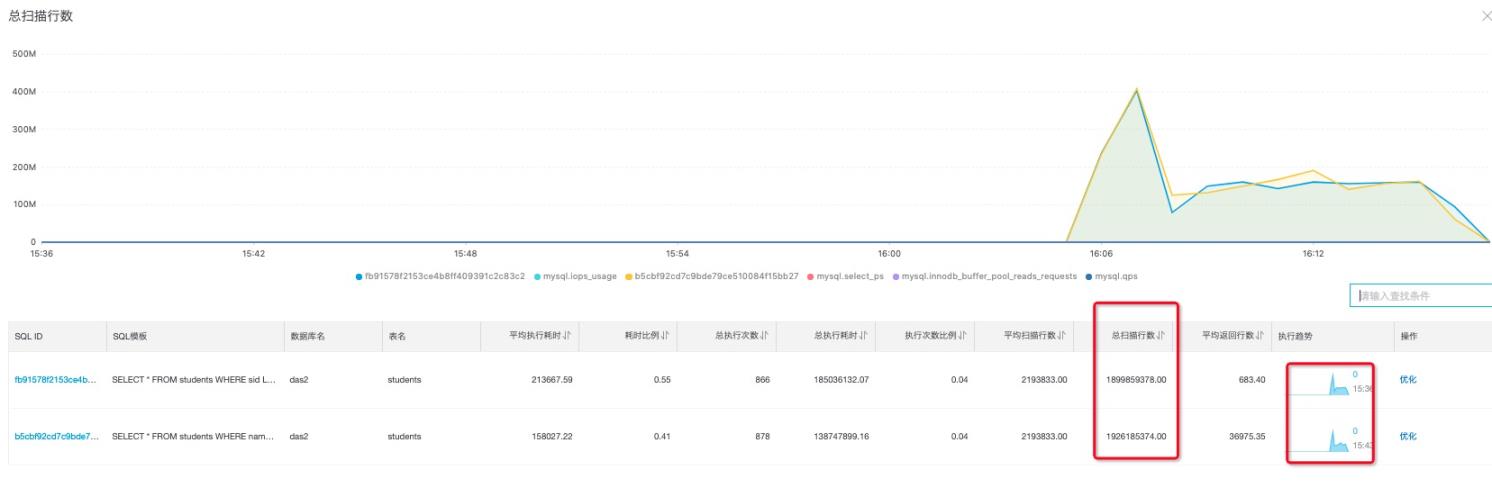
最终定位:这条全表扫描的SQL,造成了CPU被打满从而导致了会话的堆积
未来计划
DAS会支持更多引擎的实时检测和异常定位,专业版结合用户的全量SQL帮助更多用户定位更多类型的数据库实例问题。不仅让专业DBA更好的使用DAS管控数据库实例,也让数据库领域的初学者无门槛的管控数据库,真正保证数据库实例自感知,自优化,自修复。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于干货|SQL请求行为识别新功能上线,帮助解决异常SQL检测之大海捞针问题的主要内容,如果未能解决你的问题,请参考以下文章
12306模拟登录验证码识别,Python资深大牛深度分析,纯干货!
新媒体周报:今日头条“灵犬”上线短视频识别功能;视频号测试直播打通跳转小程序 ;市场监管总局:正依法审查虎牙斗鱼合并等案件