一个问题让我直接闭门思过!!!拼多多面试必问项之List实现类:LinkedList
Posted Java架构没有996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个问题让我直接闭门思过!!!拼多多面试必问项之List实现类:LinkedList相关的知识,希望对你有一定的参考价值。
一、LinkedList概述
1、对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高。
2、LinkedList是一个实现了List接口和Deque接口的双端链表。
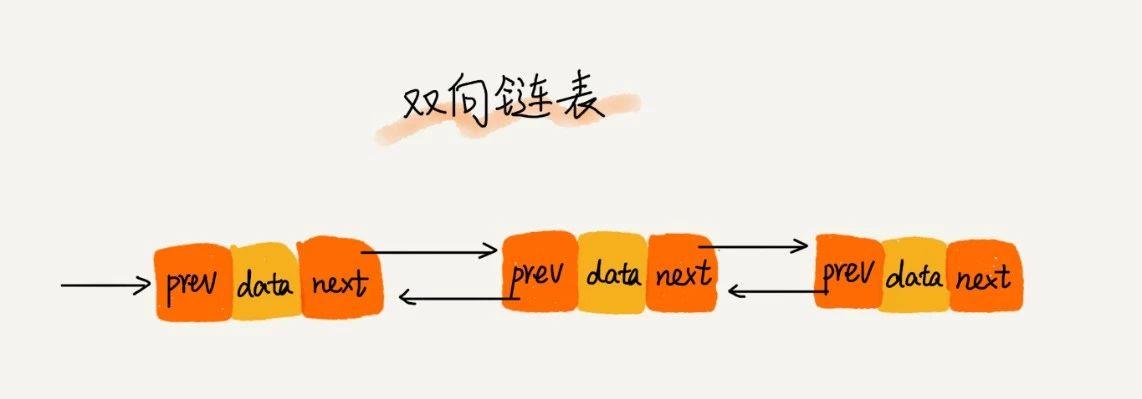
3、LinkedList底层的链表结构使它支持高效的插入和删除操作,另外它实现了Deque接口,使得LinkedList类也具有 List 的操作以及双端队列和栈的性质。
4、LinkedList不是线程安全的,如果想使LinkedList变成线程安全的,可以调用静态类Collections类中的synchronizedList方法:
List list=Collections.synchronizedList(``new` `LinkedList(...));
5、LinkedList 的继承结构如下:
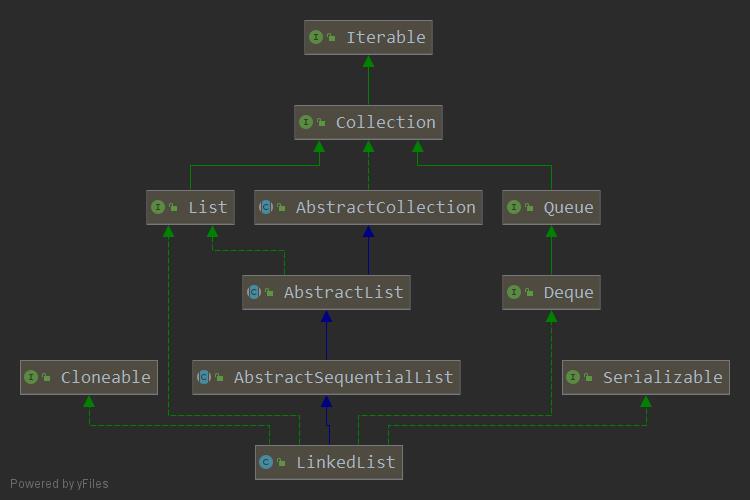
二、实现的接口
源码:
1 public class LinkedList<E>
2 extends AbstractSequentialList<E>
3 implements List<E>, Deque<E>, Cloneable, java.io.Serializable
(1)实现了 List 接口,具有List的操作方法;
(2)实现了 Deque 接口,具有双端队列和栈的特性;
(3)实现了 Cloneable 接口,支持克隆;
(4)实现了 Serializable 接口,支持序列化;
三、内部结构
1、双向链表
ArrayList是通过数组实现存储,而LinkedList则是通过链表来存储数据,而且他实现的是一个双向链表,简单的说一下什么是双向链表。
双向链表是数据结构的一种形式,他的每个节点维护两个指针,prev指向上一个节点,next指向下一个节点。
这种结构有什么特点呢?他可以实现双向遍历,这使得在链表中的数据读取变得非常灵活自由。
同时,LinkedList中维护了两个指针,一个指向头部,一个指向尾部。维护这两个指针后,可以使得元素从头部插入,也可以使元素从尾部插入。
基于方式,用户很容易就能实现FIFO(队列),LIFO(栈)等效果。那么下面我们来看一下源码中的具体实现。
2、内部结构分析
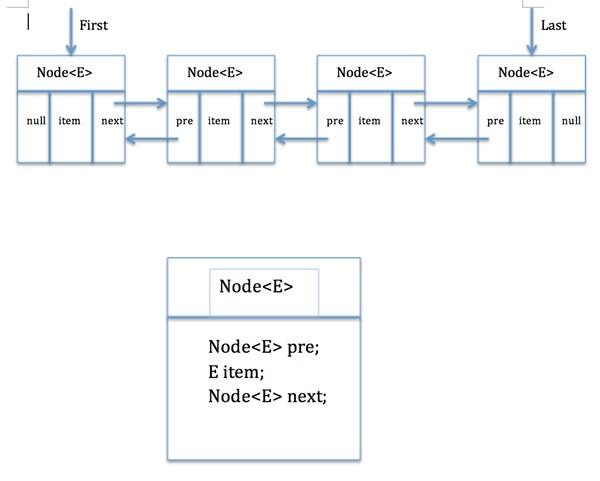
如图所示:
**
 **
**
LinkedList:双向链表,内部没有声明数组,而是定义了Node类型的first和last,用于记录首末元素。同时,定义内部类Node,作为LinkedList中保存数据的基
本结构。
Node除了保存数据,还定义了两个变量:
① prev变量记录前一个元素的位置
② next变量记录下一个元素的位置
看完了图之后,我们再看LinkedList类中的一个内部私有类Node就很好理解了:
1 private static class Node<E> {
2 E item; //本节点的值
3 Node<E> next; //后继节点
4 Node<E> prev; //前驱节点
5
6 Node(Node<E> prev, E element, Node<E> next) {
7 this.item = element;
8 this.next = next;
9 this.prev = prev;
10 }
11 }
这个类就代表双端链表的节点Node。这个类有三个属性,分别是前驱节点,本节点的值,后继结点。
四、成员变量
在 LinkedList 类中,还有几个成员变量如下:
1 // list 的长度
2 transient int size = 0;
3
4 // 链表头结点
5 transient Node<E> first;
6
7 // 链表尾结点
8 transient Node<E> last;
9
10 //序列化标记
11 private static final long serialVersionUID = 876323262645176354L;
五、构造器
LinkedList 有两个构造器,如下:
(1)无参构造:
1 public LinkedList() {
2 }
2)用已有的集合创建链表的构造方法:
1 public LinkedList(Collection<? extends E> c) {
2 this();
3 addAll(c);
4 }
注意:由于链表的容量可以一直增加,因此没有指定容量的构造器。
第一个为无参构造器。
第二个为使用指定集合的集合构造,并调用 addAll() 方法,继续跟进该方法,代码如下:
1 public boolean addAll(Collection<? extends E> c) {
2 return addAll(size, c);
3 }
4
5 public boolean addAll(int index, Collection<? extends E> c) {
6 //1:检查index范围是否在size之内
7 checkPositionIndex(index);
8
9 //2:toArray()方法把集合的数据存到对象数组中
10 Object[] a = c.toArray();
11 int numNew = a.length;
12 if (numNew == 0)
13 return false;
14
15
16 //3:获取当前链表的前驱和后继结点,得到插入位置的前驱节点和后继节点
17 Node<E> pred, succ;
18 //如果插入位置为尾部,前驱节点为last,后继节点为null
19 if (index == size) {
20 succ = null;
21 pred = last;
22 }
23 //若非尾结点,获取指定位置的结点,调用node()方法得到后继节点,再得到前驱节点,
24 else {
25 succ = node(index); //获取当前节点
26 pred = succ.prev; //获取当前节点前驱节点
27 }
28
29 // 4:循环将数组中的元素插入到链表
30 for (Object o : a) {
31 @SuppressWarnings("unchecked") E e = (E) o;
32 //创建新节点
33 Node<E> newNode = new Node<>(pred, e, null);
34 //如果插入位置在链表头部
35 if (pred == null)
36 first = newNode;
37 else
38 pred.next = newNode;
39 pred = newNode;
40 }
41
42 //如果插入位置在尾部,重置last节点
43 // 若插入到末尾,则数组中的最后一个元素就是尾结点
44 if (succ == null) {
45 last = pred;
46 }
47
48 //否则,将插入的链表与先前链表连接起来
49 else {
50 // 若插入到指定位置,将数组中最后一个元素与下一个位置关联起来
51 pred.next = succ;
52 succ.prev = pred;
53 }
54 size += numNew;
55 modCount++;
56 return true;
57 }
58
59 private void checkPositionIndex(int index) {
60 if (!isPositionIndex(index))
61 throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
62 }
63
64 private boolean isPositionIndex(int index) {
65 return index >= 0 && index <= size;
66 }
上面可以看出addAll方法通常包括下面四个步骤:
-
检查index范围是否在size之内;
-
toArray()方法把集合的数据存到对象数组中;
-
得到插入位置的前驱和后继节点;
-
遍历数据,将数据插入到指定位置,如果没有在尾部,把原来数据链起来;
其中 node(index) 方法为获取指定位置的结点,代码如下:
1 Node<E> node(int index) {
2 // assert isElementIndex(index);
3 // 判断下标在哪里,若下标在前一半,则从前往后遍历;否则从后往前遍历
4 if (index < (size >> 1)) {
5 Node<E> x = first;
6 for (int i = 0; i < index; i++)
7 x = x.next;
8 return x;
9 } else {
10 Node<E> x = last;
11 for (int i = size - 1; i > index; i--)
12 x = x.prev;
13 return x;
14 }
15 }
该方法通过遍历链表获取指定的元素。
值得注意的是,该方法并非直接从头到尾遍历整个链表,而是先判断下标的位置,若在前一半则从前往后遍历;否则就从后往前遍历。这样能减少遍历结点的个数。
因为链表的内存空间是非连续的,所以不支持随机访问(下标访问)。所以,查询某个结点是通过遍历整个链表来实现的。
六、常用方法
1、新增结点方法【尾插法】:add(),addLast(),offer(),offerLast()
源码分析:
1 public boolean add(E e) {
2 linkLast(e);
3 return true;
4 }
5 public void addLast(E e) {
6 linkLast(e);
7 }
8 public boolean offer(E e) {
9 return add(e);
10 }
11 public boolean offerLast(E e) {
12 addLast(e);
13 return true;
14 }
可以看到他们都是调用了同一个方法 linkLast(e) 实现的,如下:
1 /**
2 * Links e as last element.
3 */
4 void linkLast(E e) {
5 final Node<E> l = last;
6 // 创建一个节点,将prev指针指向链表的尾节点。
7 final Node<E> newNode = new Node<>(l, e, null);
8
9 // 将last指针指向新创建的这个节点。
10 last = newNode;
11
12 if (l == null)
13 // 如果当前链表为空,那么将头指针也指向这个节点。
14 first = newNode;
15
16 else
17 // 若链表不为空,将新结点插入到链表尾部
18 // 将链表的尾节点的next指针指向新建的节点,这样就完整的实现了在链表尾部添加一个元素的功能。
19 l.next = newNode;
20 size++;
21 modCount++;
22 }
该操作就是将指定的结点添加到链表末尾。
2、新增节点【头插法】:addFirst(),offerFirst()
源码:
1 public void addFirst(E e) {
2 linkFirst(e);
3 }
4 public boolean offerFirst(E e) {
5 addFirst(e);
6 return true;
7 }
可以看到他们都是调用了同一个方法 linkFirst(e) 实现的,如下:
1 /**
2 * Links e as first element.
3 */
4 private void linkFirst(E e) {
5 final Node<E> f = first;
6 // 创建一个新元素,将元素的next指针指向当前的头结点
7 final Node<E> newNode = new Node<>(null, e, f);
8 // 将头指针指向这个节点。
9 first = newNode;
10 if (f == null)
11 // 如果当前节点为空,则把尾指针指向这个节点。
12 last = newNode;
13 else
14 // 将当前头结点的prev指针指向此结点。
15 f.prev = newNode;
16 size++;
17 modCount++;
18 }
这段代码就是实现将元素添加的链表头部。
3、新增节点【指定位置插入】:add(int index, E element)
源码:
1 public void add(int index, E element) {
2 checkPositionIndex(index);
3
4 if (index == size)
5 linkLast(element);
6 else
7 linkBefore(element, node(index));
8 }
在这里分了两种情况:
① 如果刚好到尾部,直接在尾部插入;
② 如果没有在尾部,在非null节点之前插入元素e。
源码:
1 void linkLast(E e) {
2 final Node<E> l = last;
3 final Node<E> newNode = new Node<>(l, e, null);
4 last = newNode;
5 if (l == null)
6 first = newNode;
7 else
8 l.next = newNode;
9 size++;
10 modCount++;
11 }
12
13 void linkBefore(E e, Node<E> succ) {
14 // assert succ != null;
15 final Node<E> pred = succ.prev;
16 final Node<E> newNode = new Node<>(pred, e, succ);
17 succ.prev = newNode;
18 if (pred == null)
19 first = newNode;
20 else
21 pred.next = newNode;
22 size++;
23 modCount++;
24 }
4、设置值:set(int index, E element)
源码:
1 public E set(int index, E element) {
2 //索引检查
3 checkElementIndex(index);
4
5 //获取该索引的元素
6 Node<E> x = node(index);
7 E oldVal = x.item;
8 x.item = element;
9 return oldVal;
10 }
5、查找值:get(int index)
源码:
1 public E get(int index) {
2 checkElementIndex(index);
3 return node(index).item;
4 }
5 private void checkElementIndex(int index) {
6 if (!isElementIndex(index))
7 throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
8 }
9 private boolean isElementIndex(int index) {
10 return index >= 0 && index < size;
11 }
可以看到,这里还是调用了上面的 node() 方法进行查找的。
6、获取头节点:
源码:
1 public E getFirst() {
2 final Node<E> f = first;
3 if (f == null)
4 throw new NoSuchElementException();
5 return f.item;
6 }
7 public E element() {
8 return getFirst();
9 }
10 public E peek() {
11 final Node<E> f = first;
12 return (f == null) ? null : f.item;
13 }
14 public E peekFirst() {
15 final Node<E> f = first;
16 return (f == null) ? null : f.item;
17 }
区别:
getFirst(),element(),peek(),peekFirst() 这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,
其中getFirst() 和element() 方法将会在链表为空时,抛出异常;element()方法的内部就是使用getFirst()实现的。它们会在链表为空时,抛出NoSuchElementException;
而 peek() 和 peekFirst() 方法在链表为空时会返回空;
7、获取尾结点
1 public E getLast() {
2 final Node<E> l = last;
3 if (l == null)
4 throw new NoSuchElementException();
5 return l.item;
6 }
7 public E peekLast() {
8 final Node<E> l = last;
9 return (l == null) ? null : l.item;
10 }
两者区别: getLast() 方法在链表为空时,会抛出NoSuchElementException,而peekLast() 则不会,只是会返回 null。
8、根据对象得到索引的方法
int indexOf(Object o): 从头遍历找
1 public int indexOf(Object o) {
2 int index = 0;
3 if (o == null) {
4 //从头遍历
5 for (Node<E> x = first; x != null; x = x.next) {
6 if (x.item == null)
7 return index;
8 index++;
9 }
10 } else {
11 //从头遍历
12 for (Node<E> x = first; x != null; x = x.next) {
13 if (o.equals(x.item))
14 return index;
15 index++;
16 }
17 }
18 return -1;
19 }
int lastIndexOf(Object o): 从尾遍历找
1 public int lastIndexOf(Object o) {
2 int index = size;
3 if (o == null) {
4 //从尾遍历
5 for (Node<E> x = last; x != null; x = x.prev) {
6 index--;
7 if (x.item == null)
8 return index;
9 }
10 } else {
11 //从尾遍历
12 for (Node<E> x = last; x != null; x = x.prev) {
13 index--;
14 if (o.equals(x.item))
15 return index;
16 }
17 }
18 return -1;
19 }
9、检查链表是否包含某对象的方法:contains()
源码:
1 public boolean contains(Object o) {
2 return indexOf(o) != -1;
3 }
10、删除头节点方法:remove() ,removeFirst(),pop(),poll(),pollFirst()
源码:
1 public E remove() {
2 return removeFirst();
3 }
4
5 public E pop() {
6 return removeFirst();
7 }
8
9 public E removeFirst() {
10 final Node<E> f = first;
11 if (f == null)
12 throw new NoSuchElementException();
13 return unlinkFirst(f);
14 }
15
16 public E poll() {
17 final Node<E> f = first;
18 return (f == null) ? null : unlinkFirst(f);
19 }
20 public E pollFirst() {
21 final Node<E> f = first;
22 return (f == null) ? null : unlinkFirst(f);
23 }
本质上都是调用了 unlinkFirst()方法
源码:
1 private E unlinkFirst(Node<E> f) {
2 // assert f == first && f != null;
3 final E element = f.item;
4 final Node<E> next = f.next;
5 f.item = null;
6 f.next = null; // help GC
7 first = next;
8 if (next == null)
9 last = null;
10 else
11 next.prev = null;
12 size--;
13 modCount++;
14 return element;
15 }
11、删除尾节点方法:removeLast(),pollLast()
源码:
1 public E removeLast() {
2 final Node<E> l = last;
3 if (l == null)
4 throw new NoSuchElementException();
5 return unlinkLast(l);
6 }
7
8 public E pollLast() {
9 final Node<E> l = last;
10 return (l == null) ? null : unlinkLast(l);
11 }
区别: removeLast()在链表为空时将抛出NoSuchElementException,而pollLast()方法返回null。
本质上都是调用了 unlinkLast()方法。
源码:
1 private E unlinkLast(Node<E> l) {
2 // assert l == last && l != null;
3 final E element = l.item;
4 final Node<E> prev = l.prev;
5 l.item = null;
6 l.prev = null; // help GC
7 last = prev;
8 if (prev == null)
9 first = null;
10 else
11 prev.next = null;
12 size--;
13 modCount++;
14 return element;
15 }
12、删除指定元素:remove(Object o) & 删除指定位置的元素:remove(int index)
1 public boolean remove(Object o) {
2 if (o == null) {
3 for (Node<E> x = first; x != null; x = x.next) {
4 if (x.item == null) {
5 unlink(x);
6 return true;
7 }
8 }
9 } else {
10 for (Node<E> x = first; x != null; x = x.next) {
11 if (o.equals(x.item)) {
12 unlink(x);
13 return true;
14 }
15 }
16 }
17 return false;
18 }
19
20 public E remove(int index) {
21 checkElementIndex(index);
22 return unlink(node(index));
23 }
当删除指定对象时,只需调用remove(Object o)即可,不过该方法一次只会删除一个匹配的对象,如果删除了匹配对象,返回true,否则false。
本质上还是调用了 unlink(Node x) 方法:
1 E unlink(Node<E> x) {
2 // assert x != null;
3 final E element = x.item;
4 final Node<E> next = x.next;//得到后继节点
5 final Node<E> prev = x.prev;//得到前驱节点
6
7 //删除前驱指针
8 if (prev == null) {
9 first = next;//如果删除的节点是头节点,令头节点指向该节点的后继节点
10 } else {
11 prev.next = next;//将前驱节点的后继节点指向后继节点
12 x.prev = null;
13 }
14
15 //删除后继指针
16 if (next == null) {
17 last = prev;//如果删除的节点是尾节点,令尾节点指向该节点的前驱节点
18 } else {
19 next.prev = prev;
20 x.next = null;
21 }
22
23 x.item = null;
24 size--;
25 modCount++;
26 return element;
27 }
13、序列化方法:writeObject(java.io.ObjectOutputStream s)
源码:
1 private void writeObject(java.io.ObjectOutputStream s)
2 throws java.io.IOException {
3 // Write out any hidden serialization magic
4 s.defaultWriteObject();
5
6 // Write out size
7 s.writeInt(size);
8
9 // Write out all elements in the proper order.
10 for (Node<E> x = first; x != null; x = x.next)
11 s.writeObject(x.item);
12 }
14、反序列化方法:readObject(java.io.ObjectInputStream s)
源码:
1 private void readObject(java.io.ObjectInputStream s)
2 throws java.io.IOException, ClassNotFoundException {
3 // Read in any hidden serialization magic
4 s.defaultReadObject();
5
6 // Read in size
7 int size = s.readInt();
8
9 // Read in all elements in the proper order.
10 for (int i = 0; i < size; i++)
11 linkLast((E)s.readObject());
12 }
七、作为其他数据结构
1、FIFO(队列)实现原理
队列的原理就是每次都从链表尾部添加元素,从链表头部获取元素,就像生活中的排队叫号,总是有个先来后到。
源码:
1 // 队列尾部添加一个元素,建议使用这个,约定俗成吧。
2 publicboolean offer(E e){
3 return add(e); 4 }
5
6 // 队列尾部添加一个元素
7 publicboolean offerLast(E e){
8 addLast(e);
9 return true;
10 }
11
12 // offer和offerLast底层调用的都是linkLast这个方法,顾名思义就是将元素添加到链表尾部。
13 void linkLast(E e){
14 finalNode<E> l =last;
15
16 // 创建一个节点,将prev指针指向链表的尾节点。
17 finalNode<E> newNode =newNode<>(l, e,null);
18
19 // 将last指针指向新创建的这个节点。
20 last= newNode;
21
22 if(l ==null)
23 // 如果当前链表为空,那么将头指针也指向这个节点。
24 first = newNode;
25 else
26 // 将链表的尾节点的next指针指向新建的节点,这样就完整的实现了在链表尾部添加一个元素的功能。
27 l.next= newNode;
28
29 size++;
30 modCount++;
31 }
32
33 // 在链表头部删除一个元素,建议用这个
34 public E poll(){
35 final Node<E> f = first;
36 return(f ==null)?null: unlinkFirst(f);
37 }
38 // 在链表头部删除一个元素
39 public E pollFirst(){
40 final Node<E> f = first;
41 return(f ==null)?null: unlinkFirst(f);
42 }
43
44 // poll和pollFirst底层调用的就是这个方法,将链表的头元素删除。
45 private E unlinkFirst(Node<E> f){
46 // assert f == first && f != null;
47 final E element = f.item;
48 final Node<E>next= f.next;
49 f.item =null;
50 f.next=null;// help GC
51 first =next;
52 if(next==null)
53 last=null;
54 else
55 next.prev =null;
56 size--;
57 modCount++;
58 return element;
59 }
60
61 // 获取头元素,但是不会删除他。
62 public E peek(){
63 final Node<E> f = first;
64 return(f ==null)?null: f.item;
65 }
更准确来说,链表是一个双端链表的结构,可以在头尾都进行操作节点。
2、LIFO(栈)实现原理:
栈的原理是每次从头部添加元素,也从头部获取元素,那么后进入的元素反而最先出来。就像我们平时叠盘子,洗好了就一个一个往上放,然后要用了就从上往下一个一个拿。
源码:
1 // 在链表的头部添加一个元素
2 publicvoid push(E e){
3 addFirst(e);
4 }
5
6 // addFirst调用的就是linkFirst,这段代码就是实现将元素添加的链表头部。
7 private void linkFirst(E e){
8 final Node<E> f = first;
9 // 创建一个新元素,将元素的next指针指向当前的头结点
10 final Node<E> newNode =newNode<>(null, e, f);
11 // 将头指针指向这个节点。
12 first = newNode;
13 if(f ==null)
14 // 如果当前节点为空,则把尾指针指向这个节点。
15 last= newNode;
16 else
17 // 将当前头结点的prev指针指向此结点。
18 f.prev = newNode;
19 size++;
20 modCount++;
21 }
22
23 // 弹出顶部结点。
24 public E pop(){
25 return removeFirst();
26 }
27
28 // removeFirst调用的就是unlinkFirst,unlinkFirst实现将链表顶部元素删除
29 private E unlinkFirst(Node<E> f){
30 // assert f == first && f != null;
31 final E element = f.item;
32 final Node<E>next= f.next;
33 f.item =null;
34 f.next=null;// help GC
35 first =next;
36 if(next==null)
37 last=null;
38 else
39 next.prev =null;
40 size--;
41 modCount++;
42 return element;
43 }
44
45 // 获取顶部结点,但是不删除
46 public E peek(){
47 final Node<E> f = first;
48 return(f ==null)?null: f.item;
49 }
八、迭代器相关
LinkedList的迭代器实现有两个,一个是实现了Iterator接口的DescendingIterator,另一个则是实现了ListIterator接口的ListItr。
1、ListItr
源码:
1 public ListIterator<E> listIterator(int index) {
2 checkPositionIndex(index);
3 return new ListItr(index);
4 }
5
6 private class ListItr implements ListIterator<E> {
7 private Node<E> lastReturned;
8 private Node<E> next;
9 private int nextIndex;
10 private int expectedModCount = modCount;
11
12 // 实例化的时候,将next指针指向指定位置的元素
13 ListItr(int index) {
14 // assert isPositionIndex(index);
15 next = (index == size) ? null : node(index);
16 nextIndex = index;
17 }
18
19 public boolean hasNext() {
20 return nextIndex < size;
21 }
22
23 // 向后遍历
24 public E next() {
25 checkForComodification();
26 if (!hasNext())
27 throw new NoSuchElementException();
28
29 lastReturned = next;
30 next = next.next;
31 nextIndex++;
32 return lastReturned.item;
33 }
34
35 public boolean hasPrevious() {
36 return nextIndex > 0;
37 }
38
39 // 向前遍历
40 public E previous() {
41 checkForComodification();
42 if (!hasPrevious())
43 throw new NoSuchElementException();
44
45 lastReturned = next = (next == null) ? last : next.prev;
46 nextIndex--;
47 return lastReturned.item;
48 }
49
50 public int nextIndex() {
51 return nextIndex;
52 }
53
54 public int previousIndex() {
55 return nextIndex - 1;
56 }
57
58 public void remove() {
59 checkForComodification();
60 if (lastReturned == null)
61 throw new IllegalStateException();
62
63 Node<E> lastNext = lastReturned.next;
64 unlink(lastReturned);
65 if (next == lastReturned)
66 next = lastNext;
67 else
68 nextIndex--;
69 lastReturned = null;
70 expectedModCount++;
71 }
72
73 public void set(E e) {
74 if (lastReturned == null)
75 throw new IllegalStateException();
76 checkForComodification();
77 lastReturned.item = e;
78 }
79
80 public void add(E e) {
81 checkForComodification();
82 lastReturned = null;
83 if (next == null)
84 linkLast(e);
85 else
86 linkBefore(e, next);
87 nextIndex++;
88 expectedModCount++;
89 }
90
91 public void forEachRemaining(Consumer<? super E> action) {
92 Objects.requireNonNull(action);
93 while (modCount == expectedModCount && nextIndex < size) {
94 action.accept(next.item);
95 lastReturned = next;
96 next = next.next;
97 nextIndex++;
98 }
99 checkForComodification();
100 }
101
102 final void checkForComodification() {
103 if (modCount != expectedModCount)
104 throw new ConcurrentModificationException();
105 }
106 }
2、DescendingIterator
DescendingIterator迭代器实现的是对链表从尾部向头部遍历的功能,他复用里ListItr中的previous方法,将当前位置指向链表尾部,然后逐个向前遍历。
源码:
1 private class DescendingIterator implements Iterator<E> {
2 private final ListItr itr = new ListItr(size());
3 public boolean hasNext() {
4 return itr.hasPrevious();
5 }
6 public E next() {
7 return itr.previous();
8 }
9 public void remove() {
10 itr.remove();
11 }
12 }
九、不同版本的 LinkedList
在LinkedList 中 JDK1.6 之前为双向循环链表,JDK1.7 取消了循环,采用双向链表。
1、双向链表
双向链表属于链表的一种,也叫双链表双向即是说它的链接方向是双向的,它由若干个节点组成,每个节点都包含下一个节点和上一个节点的指针,所以从双向链表的任意节点开始,都能很方便访问他的前驱结点和后继节点。
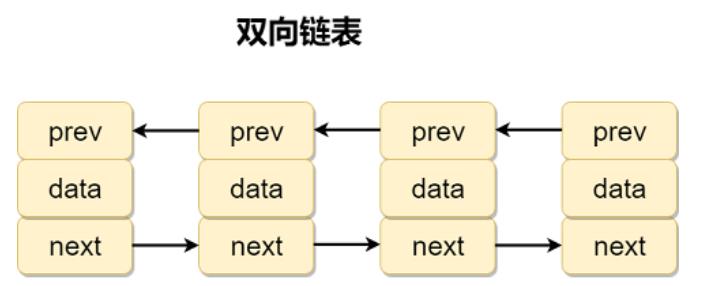
2、双向链表特点
-
- 创建双链表时无需指定链表的长度。
- 比起单链表,双链表需要多一个指针用于指向前驱节点,所以需要存储空间比单链表多一点。
- 双链表的插入和删除需要同时维护 next 和 prev 两个指针。
- 双链表中的元素访问需要通过顺序访问,即要通过遍历的方式来寻找元素。
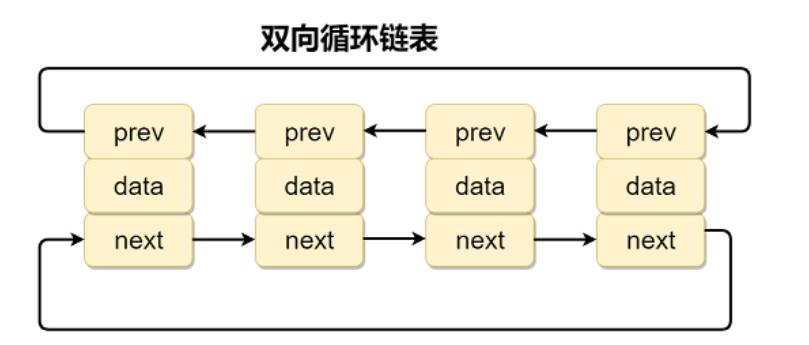
3、双向循环链表
前面的双向链表的 head 节点和链尾没有连接关系,所以如果要访问最后一个节点的话需要从头开始遍历,直到最后一个节点。在双向链表基础上改进一下,把 header 节点的 prev 指针指向最后一个节点,而最后一个节点的 next 指针指向 header 节点,于是便构成双向循环链表。
更多链表操作:https://juejin.cn/post/6844903648154271757#heading-0
4、JDK6
在JDK 1.7之前(此处使用JDK1.6来举例),LinkedList是通过headerEntry实现的一个循环链表的。先初始化一个空的Entry,用来做header,然后首尾相连,形成一个循环链表:
1 privatetransient Entry<E>header =new Entry<E>(null,null,null);
2
3 public LinkedList() {header.next =header.previous =header; }
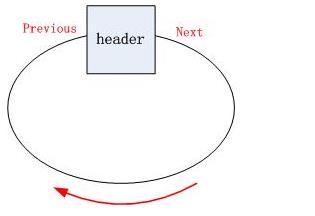
在LinkedList中提供了两个基本属性size、header。
1 private transient Entry<E> header = new Entry<E>(null, null, null);
2 private transient int size = 0;
- 其中size表示的LinkedList的大小,header表示链表的表头,Entry为节点对象。
1 private static class Entry<E> {
2 E element; //元素节点
3 Entry<E> next; //下一个元素
4 Entry<E> previous; //上一个元素
5
6 Entry(E element, Entry<E> next, Entry<E> previous) {
7 this.element = element;
8 this.next = next;
9 this.previous = previous;
10 }
11 }
- 上面为Entry对象的源代码,Entry为LinkedList的内部类,它定义了存储的元素。该元素的前一个元素、后一个元素,这是典型的双向链表定义方式。
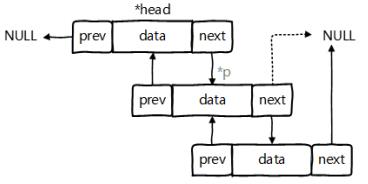
每次添加/删除元素都是默认在链尾操作。对应此处,就是在header前面操作,因为遍历是next方向的,所以在header前面操作,就相当于在链表尾操作。
如下面的插入操作addBefore以及图示,如果插入obj_3,只需要修改header.previous和obj_2.next指向obj_3即可。`
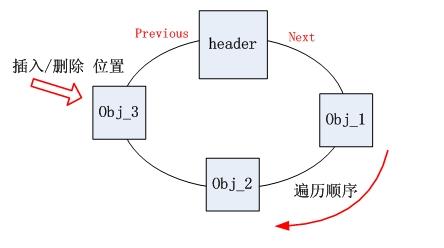
1 private Entry<E> addBefore(E e, Entry<E> entry) {
2 //利用Entry构造函数构建一个新节点 newEntry,
3 Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
4 //修改newEntry的前后节点的引用,确保其链表的引用关系是正确的
5 newEntry.previous.next = newEntry;
6 newEntry.next.previous = newEntry;
7 //容量+1
8 size++;
9 //修改次数+1
10 modCount++;
11 return newEntry;
12 }
- 在addBefore方法中无非就是做了这件事:构建一个新节点newEntry,然后修改其前后的引用。
5、JDK7
在JDK 1.7,1.6的headerEntry循环链表被替换成了first和last组成的非循环链表。
1 transient int size = 0;
2
3 /**
4 * Pointer to first node.
5 * Invariant: (first == null && last == null) ||
6 * (first.prev == null && first.item != null)
7 */
8 transient Node<E> first;
9
10 /**
11 * Pointer to last node.
12 * Invariant: (first == null && last == null) ||
13 * (last.next == null && last.item != null)
14 */
15 transient Node<E> last;
[
- 在初始化的时候,不用去new一个Entry。
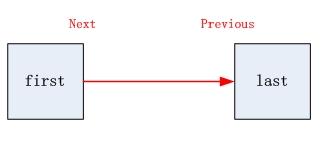
1 /**
2 * Constructs an empty list.
3 */
4 public LinkedList() {
5 }
- 在插入/删除的时候,也是默认在链尾操作。把插入的obj当成newLast,挂在oldLast的后面。另外还要先判断first是否为空,如果为空则first = obj。
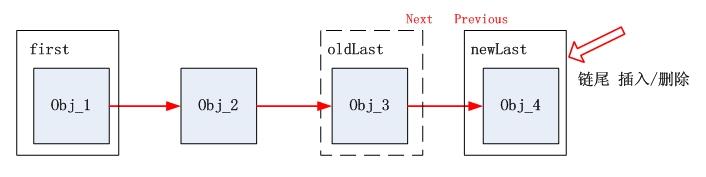
如下面的插入方法linkLast,在尾部操作,只需要把obj_3.next指向obj_4即可。
1 void linkLast(E e) {
2 final Node<E> l = last;
3 final Node<E> newNode = new Node<>(l, e, null);
4 last = newNode;
5 if (l == null)
6 first = newNode;
7 else
8 l.next = newNode;
9 size++;
10 modCount++;
11 }
其中
1 private static class Node<E> {
2 E item;
3 Node<E> next;
4 Node<E> prev;
5
6 Node(Node<E> prev, E element, Node<E> next) {
7 this.item = element;
8 this.next = next;
9 this.prev = prev;
10 }
11 }
6、【1.6-header循环链表】 V.S 【1.7-first/last非循环链表】
JDK 1.7中的first/last对比以前的header有下面几个好处:
-
(1) first / last有更清晰的链头、链尾概念,代码看起来更容易明白。
-
(2)first / last方式能节省new一个headerEntry。(实例化headerEntry是为了让后面的方法更加统一,否则会多很多header的空校验)
-
(3)在链头/尾进行插入/删除操作,first /last方式更加快捷。
插入/删除操作按照位置,分为两种情况:中间 和 两头。
在中间插入/删除,两者都是一样,先遍历找到index,然后修改链表index处两头的指针。
在两头,对于循环链表来说,由于首尾相连,还是需要处理两头的指针。而非循环链表只需要处理一边first.previous/last.next,所以理论上非循环链表更高效。 恰恰在两头(链头/链尾) 操作是最普遍的
(对于遍历来说,两者都是链表指针循环,所以遍历效率是一样的。)
十、线程安全性
线程安全的概念不再赘述。分析以下场景:
若有线程 T1 对 LinkedList 进行遍历,同时线程 T2 对其进行结构性修改。
对 LinkedList 的遍历是通过 listIterator(index) 方法实现的,如下:
1 public ListIterator<E> listIterator(int index) {
2 checkPositionIndex(index);
3 return new ListItr(index);
4 }
5
6
7 private class ListItr implements ListIterator<E> {
8 private Node<E> lastReturned;
9 private Node<E> next;
10 private int nextIndex;
11 // 初始化时二者是相等的
12 private int expectedModCount = modCount;
13
14
15 ListItr(int index) {
16 // assert isPositionIndex(index);
17 next = (index == size) ? null : node(index);
18 nextIndex = index;
19 }
20
21
22 public E next() {
23 checkForComodification();
24 if (!hasNext())
25 throw new NoSuchElementException();
26
27
28 lastReturned = next;
29 next = next.next;
30 nextIndex++;
31 return lastReturned.item;
32 }
33
34
35 public void remove() {
36 checkForComodification();
37 if (lastReturned == null)
38 throw new IllegalStateException();
39
40
41 Node<E> lastNext = lastReturned.next;
42 unlink(lastReturned);
43 if (next == lastReturned)
44 next = lastNext;
45 else
46 nextIndex--;
47 lastReturned = null;
48 expectedModCount++;
49 }
50
51
52 // ...
53
54 // 是否有其他线程对当前对象进行结构修改
55 final void checkForComodification() {
56 if (modCount != expectedModCount)
57 throw new ConcurrentModificationException();
58 }
59 }
该类的 next(), add(e) 等方法在执行时会检测 modCount 与创建时是否一致(checkForComodification() 方法),从而判断是否有其他线程对该对象进行了结构修改,若有则抛出 ConcurrentModificationException 异常。
因此,LinkedList 是线程不安全的。
十一、总结
1、LinkedList 内部是【双向链表】,同时实现了 List 接口 和 Deque 接口,因此也具备 List、双端队列和栈的性质。
2、线程不安全。
以上是关于一个问题让我直接闭门思过!!!拼多多面试必问项之List实现类:LinkedList的主要内容,如果未能解决你的问题,请参考以下文章