从0到1Flink的成长之路(二十一)-Flink+Kafka实现End-to-End Exactly-Once代码示例
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路(二十一)-Flink+Kafka实现End-to-End Exactly-Once代码示例相关的知识,希望对你有一定的参考价值。
Flink+Kafka实现End-to-End Exactly-Once
https://ververica.cn/developers/flink-kafka-end-to-end-exactly-once-analysis/
package xx.xxxxxx.flink.exactly;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
/**
* 1. Kafka Producer的容错-Kafka 0.9 and 0.10
* 如果Flink开启了checkpoint,针对FlinkKafkaProducer09 和FlinkKafkaProducer010 可以提供 at-least-once的语义,配置如下参数
* setLogFailuresOnly(false)
* setFlushOnCheckpoint(true)
* retries【这个参数的值默认是0】 //注意:建议修改kafka 生产者的重试次数
*
* 2. Kafka Producer的容错-Kafka 0.11+
* 如果Flink开启了checkpoint,针对FlinkKafkaProducer011+ 就可以提供 exactly-once的语义
* 但是需要选择具体的语义
* Semantic.NONE
* Semantic.AT_LEAST_ONCE【默认】
* Semantic.EXACTLY_ONCE
*/
public class StreamExactlyOnceKafkaDemo {
/*
/export/server/kafka/bin/kafka-topics.sh --list --bootstrap-server node1.itcast.cn:9092
Source Kafka:
/export/server/kafka/bin/kafka-topics.sh --create \\
--bootstrap-server node1.itcast.cn:9092 --replication-factor 1 --partitions 3 --topic flink-topic-source
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1.itcast.cn:9092 \\
--topic flink-topic-source
Sink Kafka:
/export/server/kafka/bin/kafka-topics.sh --create --bootstrap-server node1.itcast.cn:9092 \\
--replication-factor 1 --partitions 3 --topic flink-topic-sink
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1.itcast.cn:9092 \\
--topic flink-topic-sink --from-beginning
*/
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 设置Checkpoint
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);
// 2. 数据源-source
// 2.1. Kafka Consumer 消费数据属性设置
Properties sourceProps = new Properties();
sourceProps.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, "node1.itcast.cn:9092");
sourceProps.setProperty("group.id","flink-1001");
//如果有记录偏移量从记录的位置开始消费,如果没有从最新的数据开始消费
sourceProps.setProperty("auto.offset.reset","latest");
//开一个后台线程每隔5s检查Kafka的分区状态
sourceProps.setProperty("flink.partition-discovery.interval-millis","5000");
// 2.2. 实例化FlinkKafkaConsumer对象
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"flink-topic-source", new SimpleStringSchema(), sourceProps
);
// 从group offset记录的位置位置开始消费,如果没有该group信息,会根据"auto.offset.reset"的设置来决定从哪开始消费
kafkaSource.setStartFromGroupOffsets();
// Flink执行Checkpoint的时候提交偏移量(一份在Checkpoint中, 一份在Kafka主题中__comsumer_offsets(方便外部监控工具去看))
kafkaSource.setCommitOffsetsOnCheckpoints(true) ;
// 2.3. 添加数据源
DataStreamSource<String> kafkaDataStream = env.addSource(kafkaSource);
// 3. 数据转换-transformation
// 4. 数据终端-sink
// 4.1. Kafka Producer 生成者属性配置
Properties sinkProps = new Properties();
sinkProps.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");
//设置事务超时时间,也可在kafka配置中设置
sinkProps.setProperty("transaction.timeout.ms", 60000 * 15 + "");
// 4.2. 创建序列化实例对象
KafkaSerializationSchema<String> kafkaSchema = new KafkaSerializationSchema<String>(){
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) {
ProducerRecord<byte[], byte[]> record = new ProducerRecord<>(
"flink-topic-sink", element.getBytes(StandardCharsets.UTF_8)
);
return record;
}
} ;
// 4.3. 实例化FlinkKafkaProducer对象
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>(
"flink-topic-sink",
kafkaSchema,
sinkProps,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
// 4.4. 添加sink
kafkaDataStream.addSink(kafkaSink) ;
// 5. 触发执行-execute
env.execute(StreamExactlyOnceKafkaDemo.class.getSimpleName());
}
}
Flink+mysql实现End-to-End Exactly-Once
https://www.jianshu.com/p/5bdd9a0d7d02
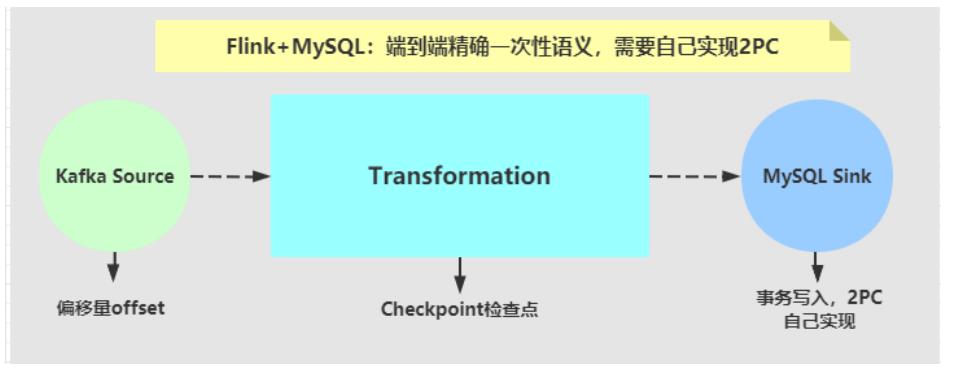
需求
1、checkpoint每10s进行一次,此时用FlinkKafkaConsumer实时消费kafka中的消息
2、消费并处理完消息后,进行一次预提交数据库的操作
3、如果预提交没有问题,10s后进行真正的插入数据库操作,如果插入成功,进行一次
checkpoint,flink会自动记录消费的offset,可以将checkpoint保存的数据放到hdfs中
4、如果预提交出错,比如在5s的时候出错了,此时Flink程序就会进入不断的重启中,重
启的策略可以在配置中设置,checkpoint记录的还是上一次成功消费的offset,因为本次
消费的数据在checkpoint期间,消费成功,但是预提交过程中失败了
5、注意此时数据并没有真正的执行插入操作,因为预提交(preCommit)失败,提交(commit)过程也不会发生。等将异常数据处理完成之后,再重新启动这个Flink程序,
它会自动从上一次成功的checkpoint中继续消费数据,以此来达到Kafka到Mysql的
Exactly-Once。
1)、代码:Kafka Producer
package xx.xxxxxx.exactly_once;
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class DataProducer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "node1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new
org.apache.kafka.clients.producer.KafkaProducer<>(props);
try {
for (int i = 1; i <= 20; i++) {
DataBean data = new DataBean(String.valueOf(i));
ProducerRecord record = new ProducerRecord<String, String>("flink_kafka", null, null,
JSON.toJSONString(data));
producer.send(record);
System.out.println("发送数据: " + JSON.toJSONString(data));
Thread.sleep(1000);
}
}catch (Exception e){
System.out.println(e);
}
producer.flush();
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
class DataBean {
private String value;
}
2)、代码:Flink Streaming
package xx.xxxxxx.exactly_once;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.typeutils.base.VoidSerializer;
import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema;
import org.apache.kafka.clients.CommonClientConfigs;
import java.sql.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
public class ExactlyOnceDemo_FlinkMysql {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//方便测试
env.enableCheckpointing(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
//env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointClea
nup.RETAIN_ON_CANCELLATION);
env.setStateBackend(new FsStateBackend("file:///D:/data/ckp"));
//2.Source
String topic = "flink_kafka";
Properties props = new Properties();
props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG,"node1:9092");
props.setProperty("group.id","flink");
props.setProperty("auto.offset.reset","latest");//如果有记录偏移量从记录的位置开始消费,如果没有从最
新的数据开始消费
props.setProperty("flink.partition-discovery.interval-millis","5000");//开一个后台线程每隔5s检查
Kafka的分区状态
FlinkKafkaConsumer<ObjectNode> kafkaSource = new FlinkKafkaConsumer<>("topic_in", new
JSONKeyValueDeserializationSchema(true), props);
kafkaSource.setStartFromGroupOffsets();//从group offset记录的位置位置开始消费,如果kafka broker 端
没有该group信息,会根据"auto.offset.reset"的设置来决定从哪开始消费
kafkaSource.setCommitOffsetsOnCheckpoints(true);//Flink 执 行 Checkpoint 的时候提交偏移量 ( 一份在
Checkpoint中,一份在Kafka的默认主题中__comsumer_offsets(方便外部监控工具去看))
DataStreamSource<ObjectNode> kafkaDS = env.addSource(kafkaSource);
//3.transformation
//4.Sink
kafkaDS.addSink(new MySqlTwoPhaseCommitSink()).name("MySqlTwoPhaseCommitSink");
//5.execute
env.execute(ExactlyOnceDemo_FlinkMysql.class.getName());
}
}
/**
自定义kafka to mysql,继承TwoPhaseCommitSinkFunction,实现两阶段提交。
功能:保证kafak to mysql 的Exactly-Once
CREATE TABLE `t_test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`value` varchar(255) DEFAULT NULL,
`insert_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
*/
class MySqlTwoPhaseCommitSink extends TwoPhaseCommitSinkFunction<ObjectNode, Connection, Void> {
public MySqlTwoPhaseCommitSink() {
super(new KryoSerializer<>(Connection.class, new ExecutionConfig()), VoidSerializer.INSTANCE);
}
/**
* 执行数据入库操作
*/
@Override
protected void invoke(Connection connection, ObjectNode objectNode, Context context) throws
Exception {
System.err.println("start invoke.......");
String date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());
System.err.println("===>date:" + date + " " + objectNode);
String value = objectNode.get("value").toString();
String sql = "insert into `t_test` (`value`,`insert_time`) values (?,?)";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1, value);
ps.setTimestamp(2, new Timestamp(System.currentTimeMillis()));
//执行insert语句
ps.execute();
//手动制造异常
if(Integer.parseInt(value) == 15) System.out.println(1/0);
}
/**
* 获取连接,开启手动提交事物(getConnection方法中)
*/
@Override
protected Connection beginTransaction() throws Exception {
String url = "jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false&autoReconnect=true";
Connection connection = DBConnectUtil.getConnection(url, "root", "root");
System.err.println("start beginTransaction......."+connection);
return connection;
}
/**
* 预提交,这里预提交的逻辑在invoke方法中
*/
@Override
protected void preCommit(Connection connection) throws Exception {
System.err.println("start preCommit......."+connection);
}
/**
* 如果invoke执行正常则提交事物
*/
@Override
protected void commit(Connection connection) {
System.err.println("start commit......."+connection);
DBConnectUtil.commit(connection);
}
@Override
protected void recoverAndCommit(Connection connection) {
System.err.println("start recoverAndCommit......."+connection);
}
@Override
protected void recoverAndAbort(Connection connection) {
System.err.println("start abort recoverAndAbort......."+connection);
}
/**
* 如果invoke执行异常则回滚事物,下一次的checkpoint操作也不会执行
*/
@Override
protected void abort(Connection connection) {
System.err.println("start abort rollback......."+connection);
DBConnectUtil.rollback(connection);
}
}
class DBConnectUtil {
/**
* 获取连接
* @throws SQLException
*/
public static Connection getConnection(String url, String user, String password) throws SQLException
{
Connection conn = null;
conn = DriverManager.getConnection(url, user, password);
//设置手动提交
conn.setAutoCommit(false);
return conn;
}
/**
* 提交事物
*/
public static void commit(Connection conn) {
if (conn != null) {
try {
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(conn);
}
}
}
/**
* 事物回滚
*/
public static void rollback(Connection conn) {
if (conn != null) {
try {
conn.rollback();
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(conn);
}
}
}
/**
* 关闭连接
*/
public static void close(Connection conn) {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
以上是关于从0到1Flink的成长之路(二十一)-Flink+Kafka实现End-to-End Exactly-Once代码示例的主要内容,如果未能解决你的问题,请参考以下文章